APScheduler
最近想写个任务调度程序,于是研究了下 Python 中的任务调度工具,比较有名的是:Celery,RQ,APScheduler。
Celery:非常强大的分布式任务调度框架
RQ:基于Redis的作业队列工具
APScheduler:一款强大的任务调度工具
RQ 参考 Celery,据说要比 Celery 轻量级。在我看来 Celery 和 RQ 太重量级了,需要单独启动进程,并且依赖第三方数据库或者缓存,适合嵌入到较大型的 python 项目中。其次是 Celery 和 RQ 目前的最新版本都不支持动态的添加定时任务(celery 官方不支持,可以使用第三方的 redisbeat 或者 redbeat 实现),所以对于一般的项目推荐用 APScheduler,简单高效。
Apscheduler是一个基于Quartz的python定时任务框架,相关的 api 接口调用起来比较方便,目前其提供了基于日期、固定时间间隔以及corntab类型的任务,并且可持久化任务;同时它提供了多种不同的调用器,方便开发者根据自己的需求进行使用,也方便与数据库等第三方的外部持久化储存机制进行协同工作,非常强大。
安装
最简单的方法是使用 pip 安装:
$ pip install apscheduler
或者下载源码安装 APScheduler:
$ python setup.py install
目前版本:3.6.3
基本概念
APScheduler 具有四种组件:
- triggers(触发器)
- jobstores (job 存储)
- executors (执行器)
- schedulers (调度器)
triggers:触发器管理着 job 的调度方式。
jobstores: 用于 job 数据的持久化。默认 job 存储在内存中,还可以存储在各种数据库中。除了内存方式不需要序列化之外(一个例外是使用 ProcessPoolExecutor),其余都需要 job 函数参数可序列化。另外多个调度器之间绝对不能共享 job 存储(APScheduler 原作者的意思是不支持分布式,但是我们可以通过重写部分函数实现,具体方法后面再介绍)。
executors:负责处理 job。通常使用线程池(默认)或者进程池来运行 job。当 job 完成时,会通知调度器并发出合适的事件。
schedulers: 将 job 与以上组件绑定在一起。通常在程序中仅运行一个调度器,并且不直接处理 jobstores ,executors 或 triggers,而是通过调度器提供的接口,比如添加,修改和删除 job。
选择正确的调度器,job 存储,执行器和触发器
调度器的选择主要取决于编程环境以及 APScheduler 的用途。主要有以下几种跳度器:
- apscheduler.schedulers.blocking.BlockingScheduler:当调度器是程序中唯一运行的东西时使用,阻塞式。
- apscheduler.schedulers.background.BackgroundScheduler:当调度器需要后台运行时使用。
- apscheduler.schedulers.asyncio.AsyncIOScheduler:当程序使用 asyncio 框架时使用。
- apscheduler.schedulers.gevent.GeventScheduler:当程序使用 gevent 框架时使用。
- apscheduler.schedulers.tornado.TornadoScheduler:当构建 Tornado 程序时使用
- apscheduler.schedulers.twisted.TwistedScheduler:当构建 Twisted 程序时使用
- apscheduler.schedulers.qt.QtScheduler:当构建 Qt 程序时使用
要选择适当的 job 存储,需要看 job 是否需要持久化。如果程序启动会重新创建作业,则可以使用默认的内存方式(MemoryJobStore)。如果需要 job 在程序重新启动或崩溃后继续存在,那么建议使用其他 job 存储方式。系统内置主要有以下几种 job 存储:
- apscheduler.jobstores.memory.MemoryJobStore:使用内存存储
- apscheduler.jobstores.mongodb.MongoDBJobStore:使用 MongoDB 存储
- apscheduler.jobstores.redis.RedisJobStore:使用 redis 存储
- apscheduler.jobstores.rethinkdb.RethinkDBJobStore:使用 rethinkdb 存储
- apscheduler.jobstores.sqlalchemy.SQLAlchemyJobStore:使用 ORM 框架 SQLAlchemy,后端可以是 sqlite、mysql、PoatgreSQL 等数据库
- apscheduler.jobstores.zookeeper.ZooKeeperJobStore:使用 zookeeper 存储
执行器的选择要根据 job 的类型。默认的线程池执行器 apscheduler.executors.pool.ThreadPoolExecutor 可以满足大多数情况。如果 job 属于 CPU 密集型操作则建议使用进程池执行器 apscheduler.executors.pool.ProcessPoolExecutor。当然也可以同时使用两者,将进程池执行器添加为辅助执行器。
当添加 job 时,可以选择一个触发器,它管理着 job 的调度方式。APScheduler 内置三种触发器:
- apscheduler.triggers.date:在某个特定时间仅运行一次 job 时使用
- apscheduler.triggers.interval:当以固定的时间间隔运行 job 时使用
- apscheduler.triggers.cron:当在特定时间定期运行 job 时使用
配置调度器
APScheduler 提供了多种不同的方式来配置调度器。
假设使用默认 job 存储和默认执行器运行 BackgroundScheduler:
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
以上创建了一个 BackgroundScheduler 调度器,job 存储使用默认的 MemoryJobStore,执行器使用默认的 ThreadPoolExecutor,最大线程数 10 个。
假如想做以下设置:
- 一个名为 mongo 的 job 存储,后端使用 MongoDB
- 一个名为 default 的 job 存储,后端使用数据库(使用 Sqlite)
- 一个名为 default 的线程池执行器,最大线程数 20 个
- 一个名为 processpool 的进程池执行器,最大进程数 5 个
- 调度器使用 UTC 时区
- 开启 job 合并
- job 最大实例限制为 3 个
方法一:有时候这个方式不太行,我亲测这个没有把配置加载进去,换成了第三种才成功
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
jobstores = {
'mongo': MongoDBJobStore(),
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
方法二:
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler({
'apscheduler.jobstores.mongo': {
'type': 'mongodb'
},
'apscheduler.jobstores.default': {
'type': 'sqlalchemy',
'url': 'sqlite:///jobs.sqlite'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false',
'apscheduler.job_defaults.max_instances': '3',
'apscheduler.timezone': 'UTC',
})
方法三:
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutor
jobstores = {
'mongo': {'type': 'mongodb'},
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': {'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
我用的下面这种,是没有问题,上面第一种有问题
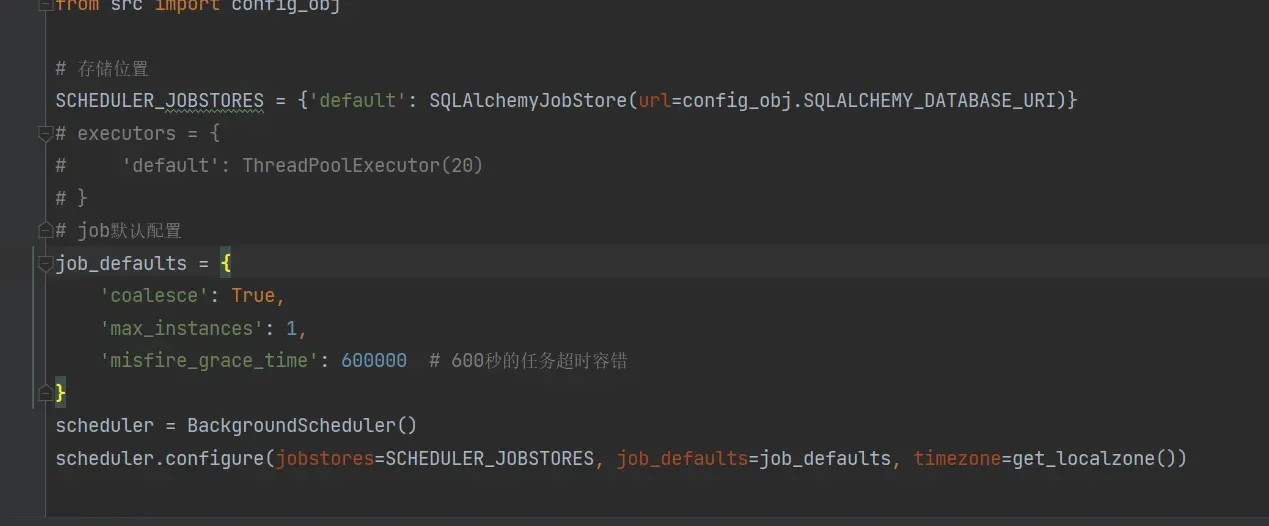
启动调度器
只需调用 start() 即可启动调度器。对于 BlockingScheduler 以外的调度器,都会直接返回,返回后可以继续其他工作,比如添加 job;对于 BlockingScheduler ,必须在完成所有初始化已经添加好 job 后才能调用 start()。
注意:调度器启动后就无法更改配置了。
添加 job
两种方式:
- 使用方法 add_job()
- 使用装饰器 scheduled_job()
第一种是最常用方法,第二种方法适合程序运行后不需要更改的作业。 add_job() 会返回一个 apscheduler.job.Job 实例,可以用于修改或者删除 job 等。如果添加 job 时,调度器尚未启动,则会暂停调度 job,并且仅在调度器启动时才计算其首次运行时间
添加 job 时第二个参数是 trigger,正如前面所说,可以指定三种类型的触发器:cron、interval 和 date。
cron:在特定时间定期运行 job
兼容 unix/linux 系统 crontab 格式,但是比其多了秒(second)、年(year)、第多少周(week)以及限定开始时间(start_date)和结束时间(end_date)的功能,并且天(day)的设置更加灵活,支持类似 last fri 的格式,具体见以下的详解。
主要参数:
year(int|str) – 年,4位数
month(int|str) – 月,1-12
day(int|str) – 日,1-31
week(int|str) – 一年中的第多少周,1-53
day_of_week(int|str) – 星期,0-6 或者 mon,tue,wed,thu,fri,sat,sun
hour(int|str) – 小时,0-23
minute(int|str) – 分,0-59
second(int|str) – 秒,0-59
start_date(date|datetime|str) – 开始时间
end_date(date|datetime|str) – 结束时间
不同于 unix/linux 系统 crond 格式,添加 job 时可以忽略不必要的字段。
大于最小有效值的字段默认为*,而较小的字段默认为其最小值,除了 week 和 day_of_week 默认为 *。
可能这种表述不是太理解,举几个例子:day=1, minute=20 最小有效值字段为 minute 故等价于 year='*', month='*', day=1, week='*', day_of_week='*', hour='*', minute=20, second=0,意思是在每年每月 1 号每小时的 20 分 0 秒运行;hour=1 最小有效值字段为 hour 故等价于 year='*', month='*', day=*, week='*', day_of_week='*', hour=1, minute=0, second=0,意思是在每年每月每天 1 点的 0 分 0 秒运行;month=6, hour=1 最小有效值字段也为 hour 故等价于 year='*', month=6, day=*, week='*', day_of_week='*', hour=1, minute=0, second=0,意思是在每年 6 月每天 0 点 0 分 0 秒运行;month=6 最小有效值字段也为 month 故等价于 year='*', month=6, day=1, week='*', day_of_week='*', hour=0, minute=0, second=0,意思是在每年 6 月 1号 0 点 0 分 0 秒运行;year=2020 最小有效值字段也为 year 故等价于 year=2020, month=1, day=1, week='*', day_of_week='*', hour=0, minute=0, second=0,意思是在 2020 年 1 月 1 号 0 点 0 分 0 秒运行;
参数还支持表达式,下表列出了从 year 到 second 字段可用的表达式。一个字段中可以给出多个表达式,用 , 分隔。
| 序号 | 表达式 | 可用字段 | 描述 |
|---|---|---|---|
| 1 | * | 所有 | 匹配字段所有取值 |
| 2 | */a | 所有 | 匹配字段每递增 a 后的值, 从字段最小值开始,包括最小值,比如小时(hour)的 */5,则匹配0,5,10,15,20 |
| 3 | a/b | 所有 | 匹配字段每递增 b 后的值, 从字段值 a 开始,包括 a,比如小时(hour)的 2/9,则匹配2,11,20 |
| 4 | a-b | 所有 | 匹配字段 a 到 b 之间的取值,a 必须小于 b,包括 a 与 b,比如2-5,则匹配2,3,4,5 |
| 5 | a-b/c | 所有 | 匹配 a 到 b 之间每递增 c 后的值,包括 a,不一定包括 b,比如1-20/5,则匹配1,6,11,16 |
| 6 | xth y | day | 匹配 y 在当月的第 x 次,比如 3rd fri 指当月的第三个周五 |
| 7 | last x | day | 匹配 x 在当月的最后一次,比如 last fri 指当月的最后一个周五 |
| 8 | last | day | 匹配当月的最后一天 |
| 9 | x,y,z | 所有 | 匹配以 , 分割的多个表达式的组合 |
例:
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job1():
print('job1')
def job2(x, y):
print('job2', x, y)
scheduler = BackgroundScheduler()
scheduler.start()
# 每天 2 点运行,指定 jobstore 与 executor,默认都为 default
scheduler.add_job(
job1,
trigger='cron',
hour=2,
jobstore='mem',
executor='processpool'
)
# 每天 2 点 30 分 5 秒运行
scheduler.add_job(
job2,
trigger='cron',
second=5,
minute=30,
hour=2,
args=['hello', 'world']
)
# 每 10 秒运行一次
scheduler.add_job(
job1,
trigger='cron',
second='*/10'
)
# 每天 1:00,2:00,3:00 运行
scheduler.add_job(
job1,
trigger='cron',
hour='1-3'
)
# 在 6,7,8,11,12 月的第三个周五 的 1:00,2:00,3:00 运行
scheduler.add_job(
job1,
trigger='cron',
month='6-8,11-12',
day='3rd fri',
hour='1-3'
)
# 在 2019-12-31 号之前的周一到周五 5 点 30 分运行
scheduler.add_job(
job1,
trigger='cron',
day_of_week='mon-fri',
hour=5,
minute=30,
end_date='2019-12-31'
)
interval:以固定的时间间隔运行 job
主要参数:
weeks(int) – 表示等待时间的周数
days(int) – 表示等待时间天数
hours(int) – 表示等待时间小时数
minutes(int) – 表示等待时间分钟数
seconds(int) – 表示等待时间秒数
start_date(date|datetime|str) – 开始时间
end_date(date|datetime|str) – 结束时间
例:
from apscheduler.schedulers.background import BackgroundScheduler
def job():
print('job')
scheduler = BackgroundScheduler()
scheduler.start()
# 每 2 小时运行一次
scheduler.add_job(
job,
trigger='interval',
hours=2
)
# 2019-10-01 00:00:00 到 2019-10-31 23:59:59 之间每 2 小时运行一次
scheduler.add_job(
job,
trigger='interval',
hours=2,
start_date='2019-10-01 00:00:00',
end_date='2019-10-31 23:59:59',
)
# 每 2 天 3 小时 4 分钟 5 秒 运行一次
scheduler.add_job(
job,
trigger='interval',
days=2,
hours=3,
minutes=4,
seconds=5
)
date:某个特定时间仅运行一次 job
例:
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job():
print('job')
scheduler = BackgroundScheduler()
scheduler.start()
# 3 秒后运行
scheduler.add_job(
job,
trigger='date',
run_date=datetime.datetime.now() + datetime.timedelta(seconds=3)
)
# 2019.11.22 00:00:00 运行
scheduler.add_job(
job,
trigger='date',
run_date=datetime.date(2019, 11, 22),
)
# 2019.11.22 16:30:01 运行
scheduler.add_job(
job,
trigger='date',
run_date=datetime.datetime(2019, 11, 22, 16, 30, 1),
)
# 2019.11.31 16:30:01 运行
scheduler.add_job(
job,
trigger='date',
run_date='2019-11-31 16:30:01',
)
# 立即运行
scheduler.add_job(
job,
trigger='date'
)
小提示:
如果想立即运行 job ,则可以在添加 job 时省略trigger参数;
添加 job 时的日期设置参数 start_date、end_date 以及 run_date 都支持字符串格式(’2019-12-31′ 或者 ‘2019-12-31 12:01:30’)、datetime.date(datetime.date(2019, 12, 31)) 或者 datetime.datetime(datetime.datetime(2019, 12, 31, 16, 30, 1));
删除 job
当调度器中删除 job 时,该 job 也将从其关联的 job 存储中删除,并且将不再执行。有两种方法可以实现此目的:
- 通过调用方法 remove_job() ,指定 job ID 和 job 存储别名
- 通过调用 add_job() 时 返回的 apscheduler.job.Job 实例的 remove() 方法
例:
job = scheduler.add_job(myfunc, 'interval', minutes=2)
job.remove()
或者:
scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
scheduler.remove_job('my_job_id')
注意: 如果任务已经调度完毕,并且之后也不会再被执行的情况下,会被自动删除。
暂停和恢复 job
暂停和恢复 job 与 删除 job 方法类似:
暂停:
job = scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
job.pause() # or
scheduler.pause_job('my_job_id')
恢复:
job = scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
job.resume() # or
scheduler.resume_job('my_job_id')
获取 job 列表
使用 get_jobs() 方法获取一个列表,或者使用 print_jobs() 方法打印一个格式化的列表。
jobs = scheduler.get_jobs() # or
scheduler.print_jobs()
提示:可以使用 get_job(id) 获取单个 job 信息
修改 job
修改 job 依然与 删除 job 方法类似,可以修改除 job id 以外的其他属性。
例:
job.modify(max_instances=6, name='Alternate name')
如果想修改触发器,可以使用 apscheduler.job.Job.reschedule 或者 apscheduler.schedulers.base.BaseScheduler.reschedule_job 。
例:
scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')
其实修改 job 也可以使用 add_job() 方法,只需要指定参数 replace_existing=True 以及相同的 job_id 即可。
关闭调度器
关闭调度器方法:
scheduler.shutdown()
默认情况下,会关闭 job 存储和执行器,并等待所有正在执行的 job 完成。如果不想等待则可以使用以下方法关闭:
scheduler.shutdown(wait=False)
暂停/恢复调度器
暂停调度器:
scheduler.pause()
恢复调度器:
scheduler.resume()
启动调度器的时候可以指定 paused=True,以这种方式启动的调度器直接就是暂停状态。
scheduler.start(paused=True)
限制 job 并发执行实例数量
默认情况下,每个 job 仅允许 1 个实例同时运行。这意味着,如果该 job 将要运行,但是前一个实例尚未完成,则最新的 job 不会调度。可以在添加 job 时指定 max_instances 参数解除限制。
- max_instances 可以在初始化调度器的时候设置一个全局默认值,添加任务时可以再单独指定
job 合并
当由于某种原因导致某个 job 积攒了好几次没有实际运行(比如说系统挂了 5 分钟后恢复,有一个任务是每分钟跑一次的,按道理说这 5 分钟内本来是“计划”运行 5 次的,但实际没有执行),如果 coalesce 为 True,下次这个 job 被 submit 给 executor 时,只会执行 1 次,也就是最后这次,如果为 False,那么会执行 5 次(不一定,因为还有其他条件,看后面misfire_grace_time)。misfire_grace_time:单位为秒,假设有这么一种情况,当某一 job 被调度时刚好线程池都被占满,调度器会选择将该 job 排队不运行,misfire_grace_time 参数则是在线程池有可用线程时会比对该 job 的应调度时间跟当前时间的差值,如果差值小于 misfire_grace_time 时,调度器会再次调度该 job;反之该 job 的执行状态为 EVENTJOBMISSED 了,即错过运行。
- coalesce 与 misfire_grace_time 可以在初始化调度器的时候设置一个全局默认值,添加任务时可以再单独指定
调度器事件
调度器事件只有在某些情况下才会被触发,并且可以携带某些有用的信息。通过 add_listener() 传递适当参数,可以实现监听不同是事件,比如 job 运行成功、运行失败等。具体支持的事件类型见官方文档
。
例:
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
def my_listener(event):
if event.exception:
print('The job crashed :(')
else:
print('The job worked :)')
scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
日志调试
如果 APScheduler 工作不正常,可以开启日志 DEBUG 模式
import logging
logging.basicConfig()
logging.getLogger('apscheduler').setLevel(logging.DEBUG)
扩展 APScheduler
APScheduler 的四种组件都可以自定义扩展:
- triggers(触发器)
- jobstores (job 存储)
- executors (执行器)
- schedulers (调度器)
具体方法参考官方文档。
分布式 APScheduler
APScheduler 默认是不支持分布式运行的,详见官方 FAQ。当将其集成到 flask 或者 django 项目后,如果用 gunicorn 部署,gunicorn 可能会启动多个 worker 从而导致 job 重复执行。gunicorn 配置参数 –preload 和 worker=1 后,只启动一个 worker,可以适当缓解这个问题(这个方法有个问题:当自动重启 worker 的时候,如果这时后台刚好有一个耗时任务正常执行,比如需要执行 30s,而系统中还有一个每秒执行的任务,这时就会丢失部分每秒执行的任务)。
那有没有好的方法解决呢?肯定是有的,首先我们看看其基本原理:总的来说,其主要是利用 python threading Event 和 Lock 锁来写的。scheduler 在主循环 (_main_loop)中,反复检查是否有需要执行的任务,完成任务的检查函数为 _process_jobs,这个函数主要有以下几个步骤:
1、 询问储存的每个 jobStore,是否有到期要执行的任务。
...
due_jobs = jobstore.get_due_jobs(now)
...
2、due_jobs 不为空,则计算这些 jobs 中每个 job 需要运行的时间点,时间一到就 submit 给任务调度。
...
run_times = job._get_run_times(now)
run_times = run_times[-1:] if run_times and job.coalesce else run_times
if run_times:
try:
executor.submit_job(job, run_times)
except MaxInstancesReachedError:
...
3、在主循环中,如果不间断地调用,而实际上没有要执行的 job,这会造成资源浪费。因此在程序中,如果每次掉用 _process_jobs 后,进行了预先判断,判断下一次要执行的 job(离现在最近的)还要多长时间,作为返回值告诉 main_loop, 这时主循环就可以去睡一觉,等大约这么长时间后再唤醒,执行下一次 _process_jobs。
...
# Determine the delay until this method should be called again
if self.state == STATE_PAUSED:
wait_seconds = None
self._logger.debug('Scheduler is paused; waiting until resume() is called')
elif next_wakeup_time is None:
wait_seconds = None
self._logger.debug('No jobs; waiting until a job is added')
else:
wait_seconds = min(max(timedelta_seconds(next_wakeup_time - now), 0), TIMEOUT_MAX)
self._logger.debug('Next wakeup is due at %s (in %f seconds)', next_wakeup_time,
wait_seconds)
return wait_seconds
根据以上基本原理,其实可以发现重写 _process_jobs 函数就能解决。主要思路是文件锁,当 worker 准备获取要执行的 job 时必须先获取到文件锁,获取文件锁后分配 job 到执行器后,再释放文件锁。具体代码如下:
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.executors.base import MaxInstancesReachedError
from apscheduler.events import (
JobSubmissionEvent, EVENT_JOB_SUBMITTED, EVENT_JOB_MAX_INSTANCES,
)
from apscheduler.util import (
timedelta_seconds, TIMEOUT_MAX
)
from datetime import datetime, timedelta
import six
import fcntl
import os
#: constant indicating a scheduler's stopped state
STATE_STOPPED = 0
#: constant indicating a scheduler's running state (started and processing jobs)
STATE_RUNNING = 1
#: constant indicating a scheduler's paused state (started but not processing jobs)
STATE_PAUSED = 2
class DistributedBackgroundScheduler(BackgroundScheduler):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def _process_jobs(self):
"""
Iterates through jobs in every jobstore, starts jobs that are due and figures out how long
to wait for the next round.
If the ``get_due_jobs()`` call raises an exception, a new wakeup is scheduled in at least
``jobstore_retry_interval`` seconds.
"""
if self.state == STATE_PAUSED:
self._logger.debug('pid: %s Scheduler is paused -- not processing jobs' % os.getpid())
return None
f = None
try:
f = open("scheduler.lock", "wb")
# 这里必须使用 lockf, 因为 gunicorn 的 worker 进程都是 master 进程 fork 出来的
# flock 会使子进程拥有父进程的锁
# fcntl.flock(flock, fcntl.LOCK_EX | fcntl.LOCK_NB)
fcntl.lockf(f, fcntl.LOCK_EX | fcntl.LOCK_NB)
self._logger.info("pid: %s get Scheduler file lock success" % os.getpid())
except BaseException as exc:
self._logger.warning("pid: %s get Scheduler file lock error: %s" % (os.getpid(), str(exc)))
try:
if f:
f.close()
except BaseException:
pass
return None
else:
self._logger.debug('pid: %s Looking for jobs to run' % os.getpid())
now = datetime.now(self.timezone)
next_wakeup_time = None
events = []
with self._jobstores_lock:
for jobstore_alias, jobstore in six.iteritems(self._jobstores):
try:
due_jobs = jobstore.get_due_jobs(now)
except Exception as e:
# Schedule a wakeup at least in jobstore_retry_interval seconds
self._logger.warning('pid: %s Error getting due jobs from job store %r: %s',
os.getpid(), jobstore_alias, e)
retry_wakeup_time = now + timedelta(seconds=self.jobstore_retry_interval)
if not next_wakeup_time or next_wakeup_time > retry_wakeup_time:
next_wakeup_time = retry_wakeup_time
continue
for job in due_jobs:
# Look up the job's executor
try:
executor = self._lookup_executor(job.executor)
except BaseException:
self._logger.error(
'pid: %s Executor lookup ("%s") failed for job "%s" -- removing it from the '
'job store', os.getpid(), job.executor, job)
self.remove_job(job.id, jobstore_alias)
continue
run_times = job._get_run_times(now)
run_times = run_times[-1:] if run_times and job.coalesce else run_times
if run_times:
try:
executor.submit_job(job, run_times)
except MaxInstancesReachedError:
self._logger.warning(
'pid: %s Execution of job "%s" skipped: maximum number of running '
'instances reached (%d)', os.getpid(), job, job.max_instances)
event = JobSubmissionEvent(EVENT_JOB_MAX_INSTANCES, job.id,
jobstore_alias, run_times)
events.append(event)
except BaseException:
# 分配任务错误后马上释放文件锁,让其他 worker 抢占
try:
fcntl.flock(f, fcntl.LOCK_UN)
f.close()
self._logger.info("pid: %s unlocked Scheduler file success" % os.getpid())
except:
pass
self._logger.exception('pid: %s Error submitting job "%s" to executor "%s"',
os.getpid(), job, job.executor)
break
else:
event = JobSubmissionEvent(EVENT_JOB_SUBMITTED, job.id, jobstore_alias,
run_times)
events.append(event)
# Update the job if it has a next execution time.
# Otherwise remove it from the job store.
job_next_run = job.trigger.get_next_fire_time(run_times[-1], now)
if job_next_run:
job._modify(next_run_time=job_next_run)
jobstore.update_job(job)
else:
self.remove_job(job.id, jobstore_alias)
# Set a new next wakeup time if there isn't one yet or
# the jobstore has an even earlier one
jobstore_next_run_time = jobstore.get_next_run_time()
if jobstore_next_run_time and (next_wakeup_time is None or
jobstore_next_run_time < next_wakeup_time):
next_wakeup_time = jobstore_next_run_time.astimezone(self.timezone)
# Dispatch collected events
for event in events:
self._dispatch_event(event)
# Determine the delay until this method should be called again
if next_wakeup_time is None:
wait_seconds = None
self._logger.debug('pid: %s No jobs; waiting until a job is added', os.getpid())
else:
wait_seconds = min(max(timedelta_seconds(next_wakeup_time - now), 0), TIMEOUT_MAX)
self._logger.debug('pid: %s Next wakeup is due at %s (in %f seconds)', os.getpid(), next_wakeup_time,
wait_seconds)
try:
fcntl.flock(f, fcntl.LOCK_UN)
f.close()
self._logger.info("pid: %s unlocked Scheduler file success" % os.getpid())
except:
pass
return wait_seconds
文件锁只支持 unix/linux 系统,并且只能实现本机的分布式。如果想实现多台主机的的分布式,需要借助 redis 或者 zookeeper 实现分布锁,原理和文件锁一样的,都是重写 _process_jobs 函数实现,代码就不再赘述,有兴趣的朋友可以自己研究一下。
文章出处登录后可见!