文章目录
- 1. 安装
- 自动安装
- 手动安装
- 2. 启用 Controlnet
- 3. 配置 Controlnet
- 4. 预训练模型区别
- 5. 多 ControlNet 组合应用
- 6. 参数介绍
- 7. 版本对比
- Reference
Controlnet 允许通过线稿、动作识别、深度信息等对生成的图像进行控制。
1. 安装
自动安装
- 在
stable-diffusion-webui页面上找到Extensions->Install from URL,输入插件的 git 地址,然后点击 Install 即可, URL 如下:
https://github.com/Mikubill/sd-webui-controlnet.git
- 等待 loading 结束后,页面底部会出现
Installed into xxx. Use Installed tab to restart.提示
手动安装
- 进入扩展文件夹
cd ./stable-diffusion-webui/extensions
- 将项目文件下载至
extensions文件夹
git clone https://github.com/Mikubill/sd-webui-controlnet.git
2. 启用 Controlnet
- 依次找到
Extensions->Installed->Apply and restart UI - 待
webui重启后,可以在txt2img和img2img中看到会多出来一个ControlNet选项 - 安装完成
3. 配置 Controlnet
用户提供一张参考图(
),
ControlNet根据指定的模式对参考图进行预处理,得到一张新图(),作为另一张参考图;
根据提示词(Prompt),结合前面的参考图,进行图像绘制,即
- 上述流程的两个阶段,对应用到的模型有两种:
ControlNet官方下载地址
预处理器模型(annotator)
预训练模型(models)
ControlNet官方存放在 huggingface 上的 预训练模型文件(models) 内部包含了SD的v1-5-pruned-emaonly模型,这在stable-diffusion-webui环境下是没必要的,而且也造成了很多硬盘空间浪费,可以仅下载裁剪版本
- 裁剪版本
预训练模型(models)
-
模型存放位置
- 插件的
models存放目录:./stable-diffusion-webui/extensions/sd-webui-controlnet/models - 插件的
annotator存放目录:./stable-diffusion-webui/extensions/sd-webui-controlnet/annotator
- 插件的
-
注意: 预处理器模型(annotator)需按分类目录存放,例如:
body_pose_model.pth和hand_pose_model.pth应保存到openpose目录;network-bsds500.pth保存到hed目录;upernet_global_small.pth则是保存到uniformer目录;- 其他模型文件可根据关键字,找到对应存放目录
-
在下载并存放好预处理器模型和预训练模型后,重启
webui即可使用
4. 预训练模型区别
详见 Github 仓库
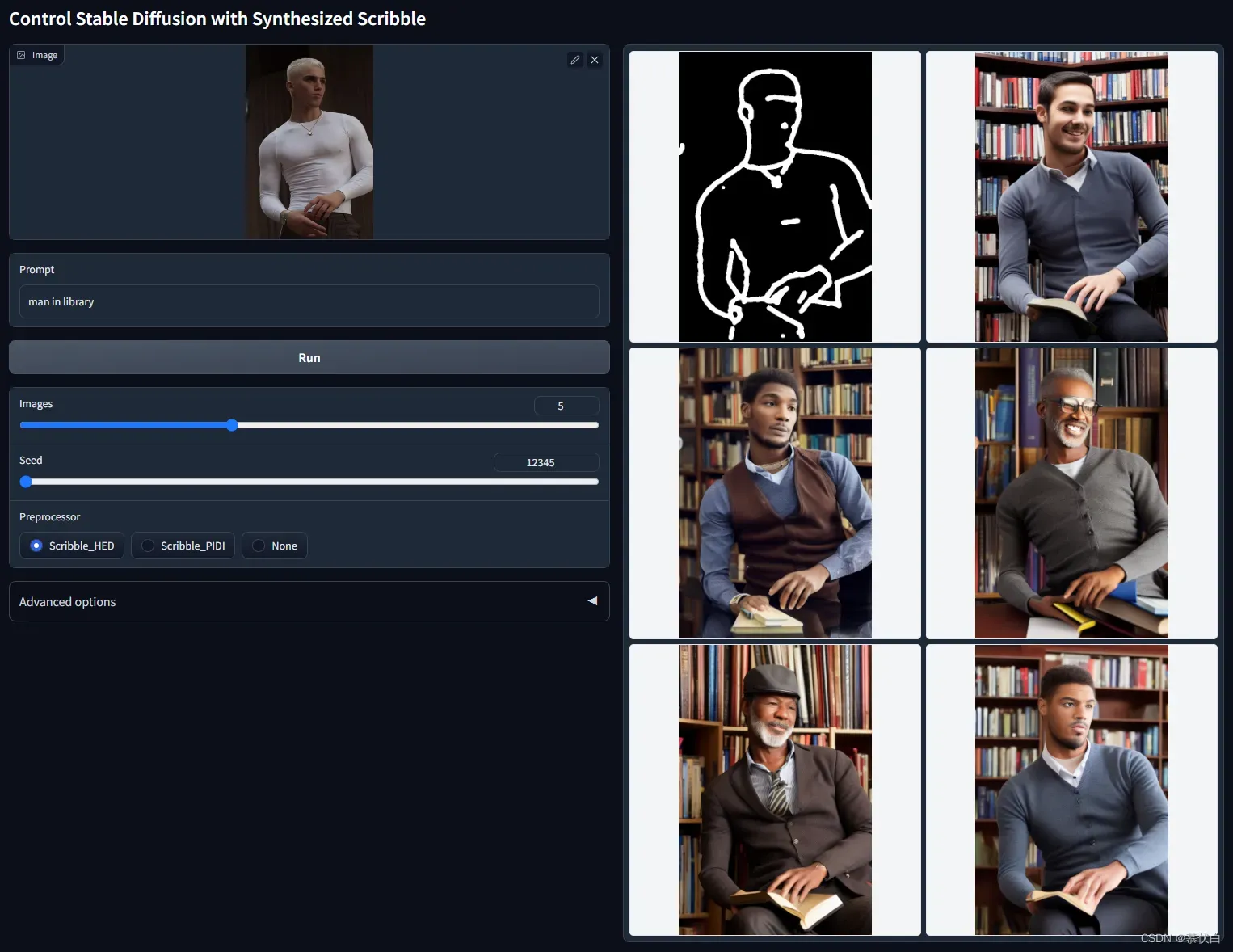
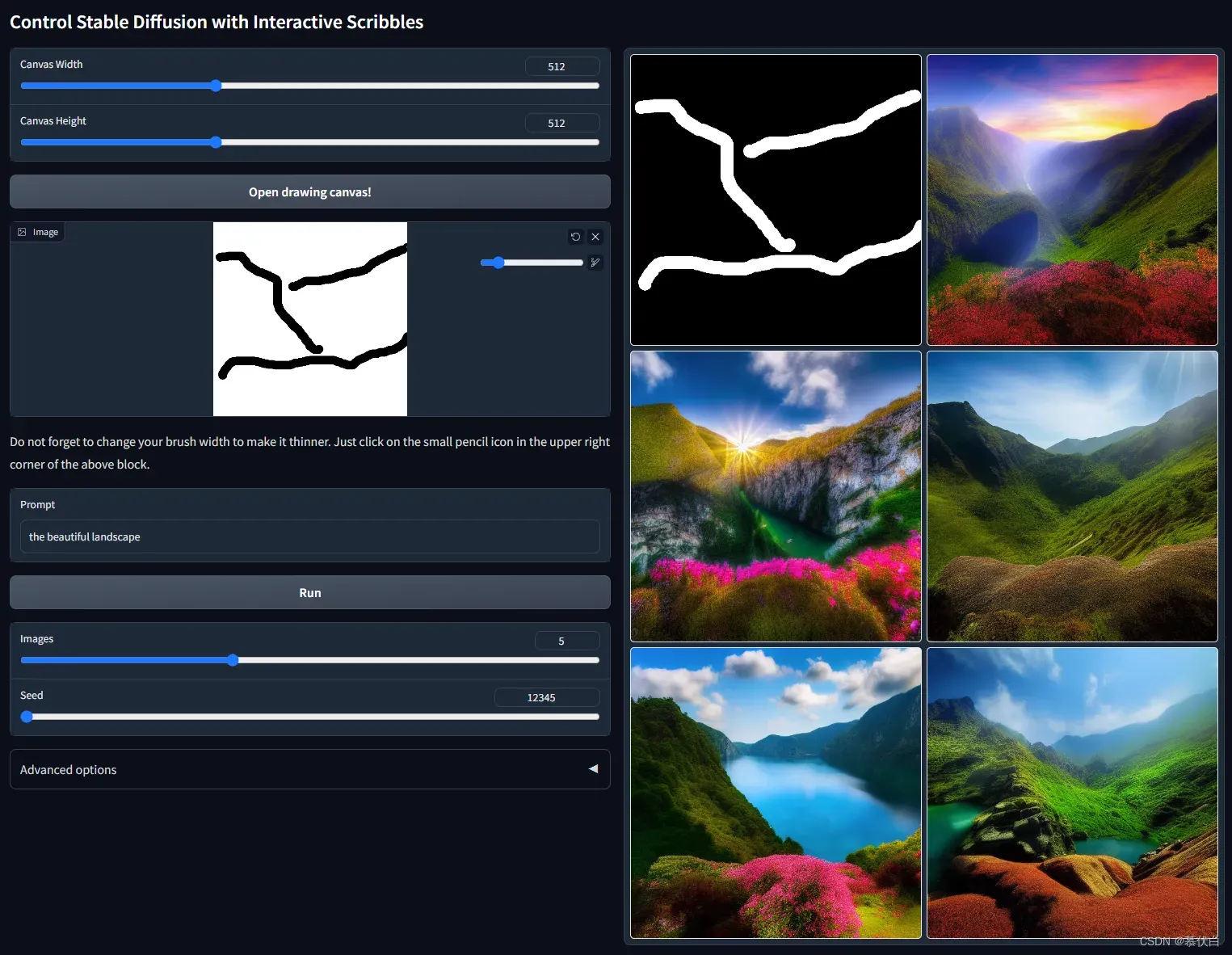
- ControlNet with User Scribbles
control_scribble-fp16支持新建白画布,在上边画线条。模型将所画作为输入,并获得对应的输出,使用人类涂鸦控制SD。该模型使用边界边缘进行训练,具有非常强大的数据增强功能,以模拟类似于人类绘制的边界线。 - 例图:
- ControlNet with Canny Edge
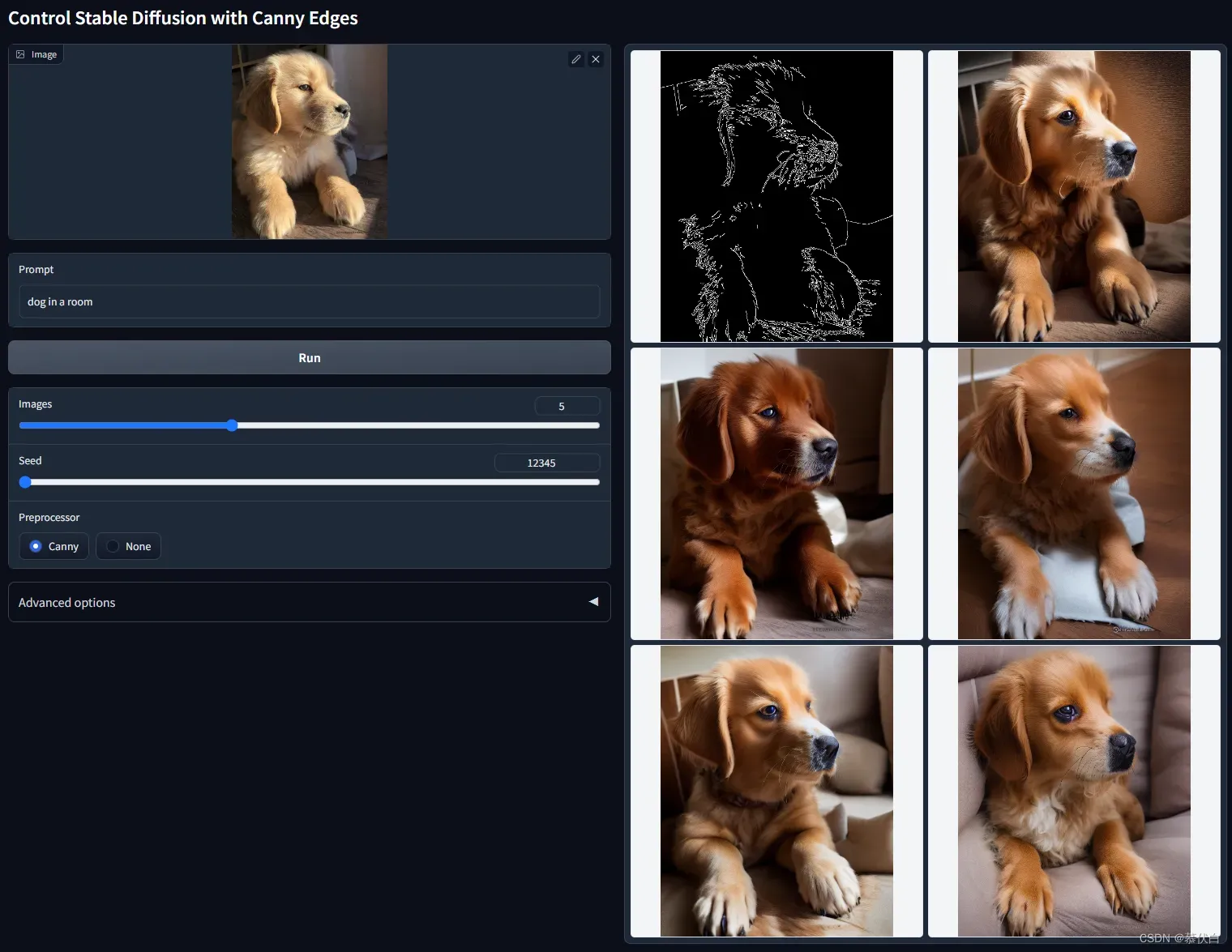
control_canny-fp16需要提供一张图片,预处理器使用 Canny 边缘检测 提取出边缘线,模型使用这个边缘线作为输入,控制生成对应的输出,适用于给线稿上色,或将图片转化为线搞后重新上色,比较适合人物。 - 例图:
- ControlNet with HED Maps
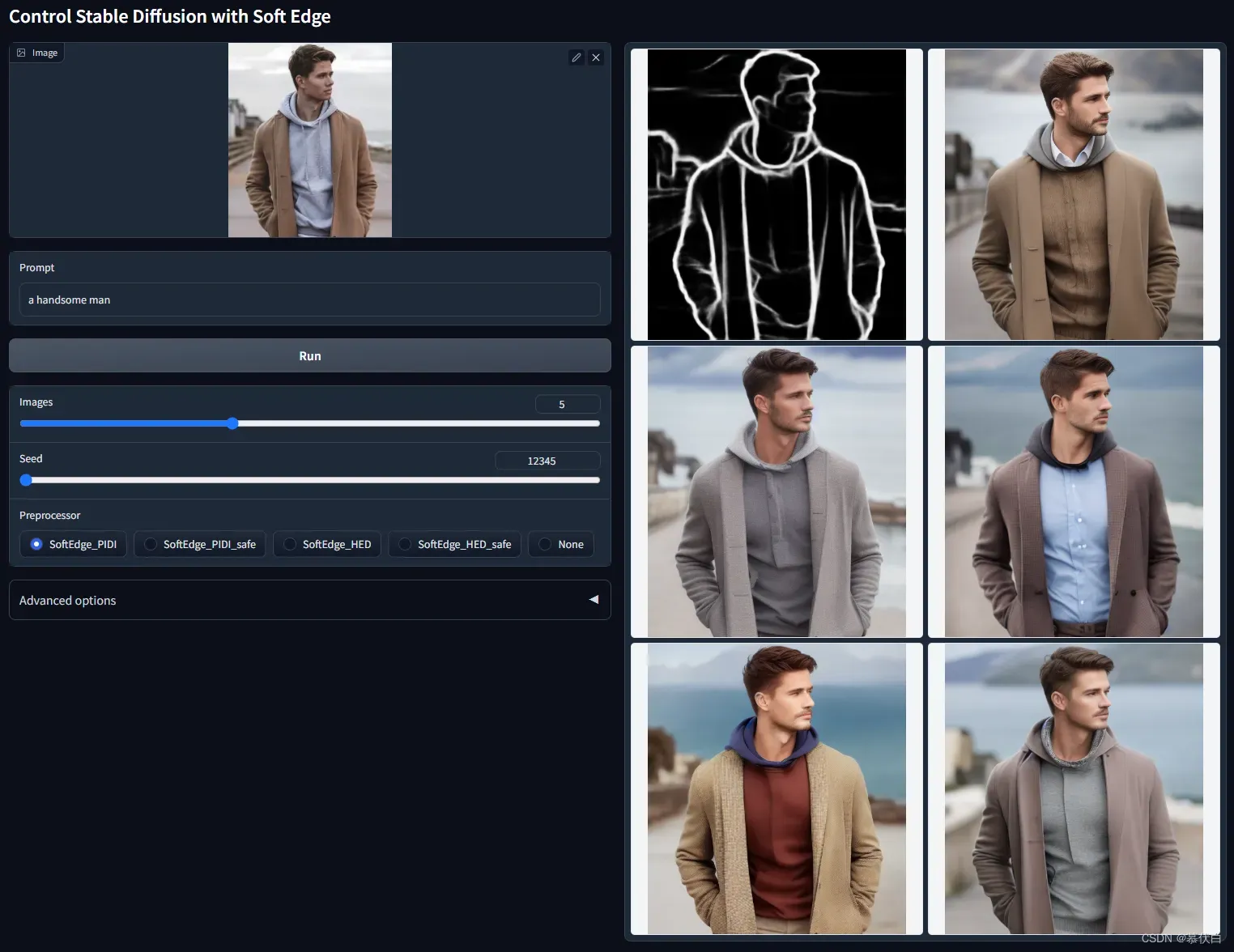
control_hed-fp16需要提供一张图片,预处理器使用 HED 边缘检测 提取软边缘,使用这个边缘线作为输入,控制生成对应的输出,提取的图像目标边界将保留更多细节,此模型适合重新着色和风格化。 - 例图:
- ControlNet with M-LSD Lines
control_mlsd-fp16需要提供一张图片,预处理器使用 M-LSD 边缘检测 ,使用这个边缘线作为输入,控制生成对应的输出,该模型基本不能识别人物的,但非常适合建筑生成,根据底图或自行手绘的线稿去生成中间图,然后再生成图片。 - 例图:
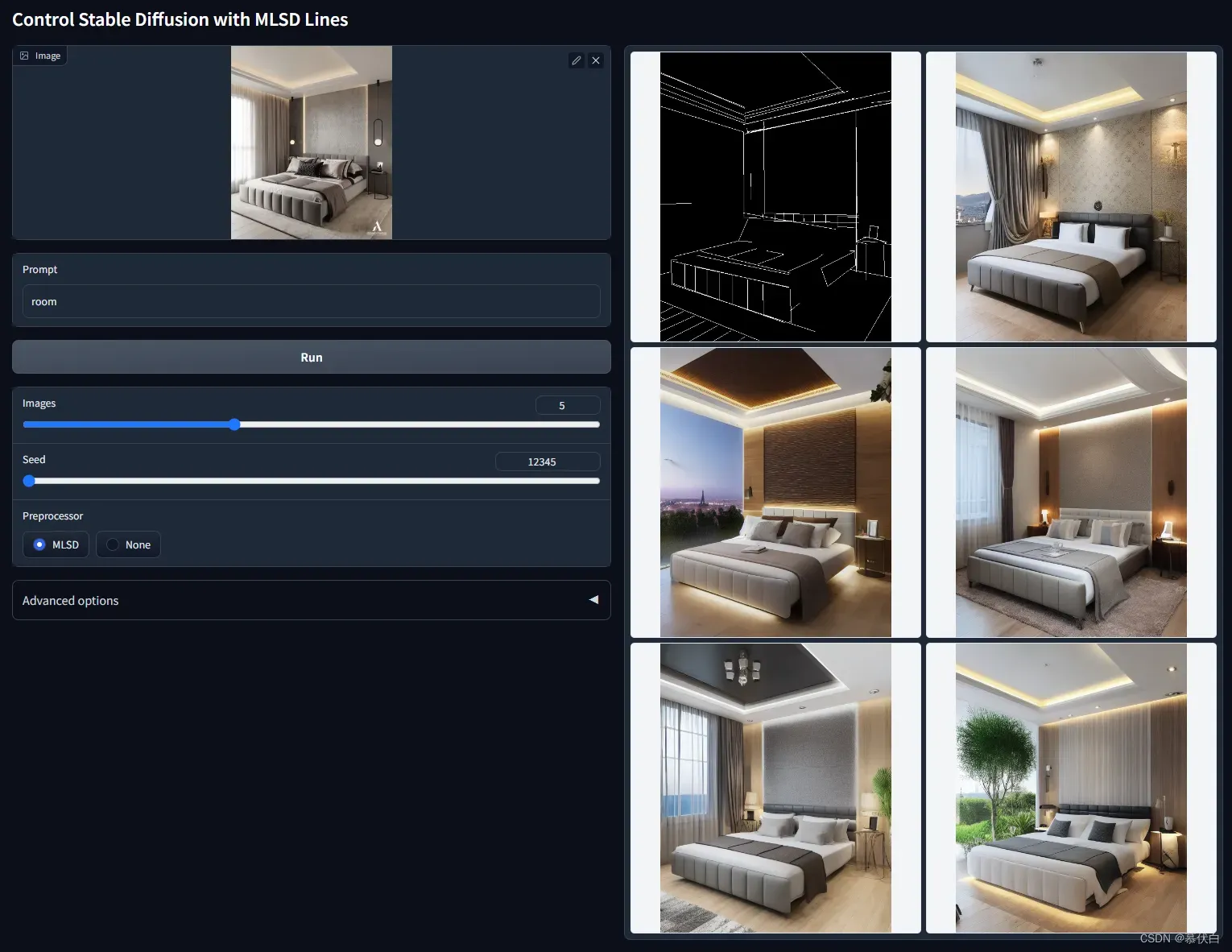
- ControlNet with Human Pose
control_openpose-fp16根据提供的图片,获得对应的姿势骨架图作为输入并生成对应的结果,根据图片生成动作骨骼中间图,然后生成图片,使用真人图片是最合适的,因为模型库使用的真人素材。 - 例图:
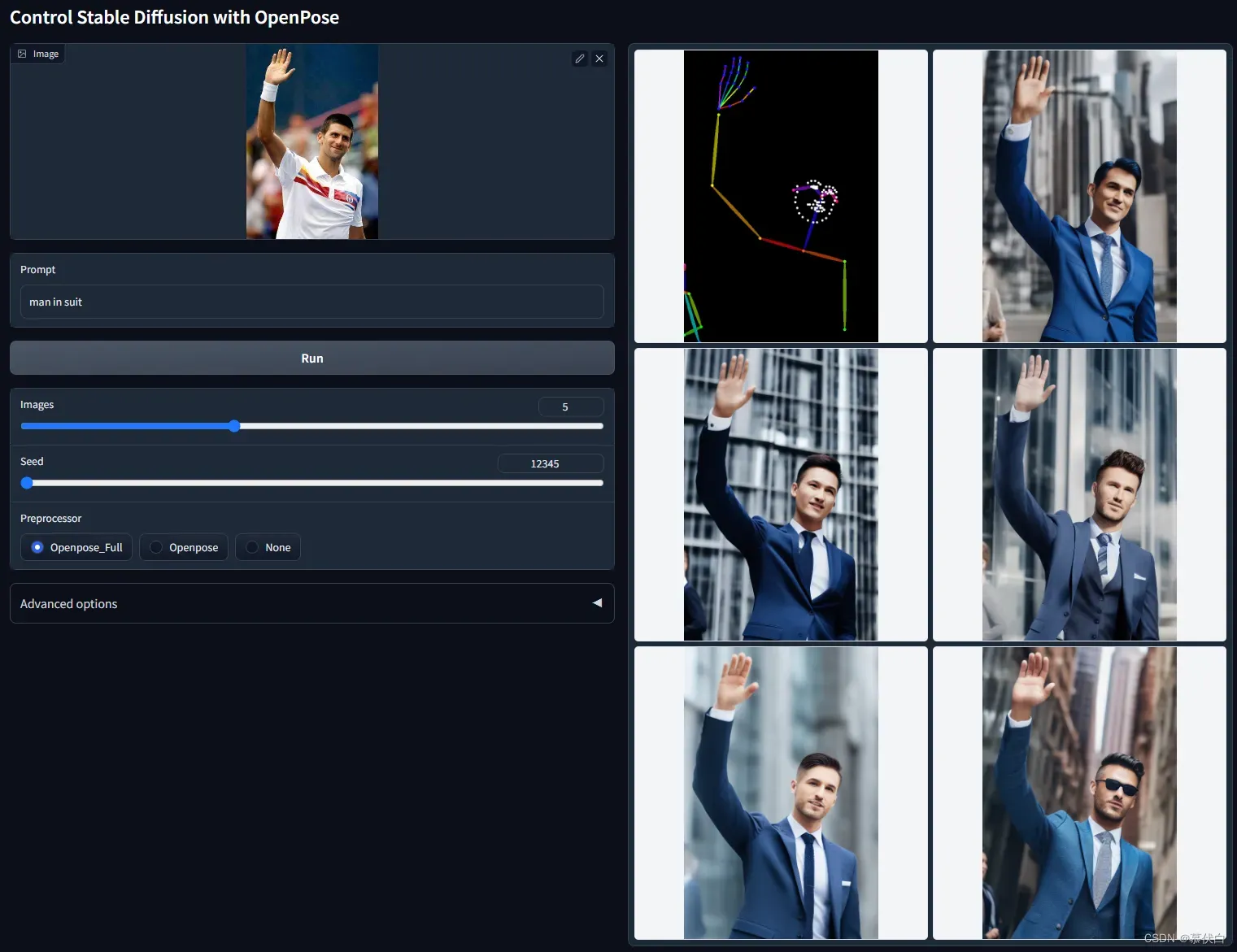
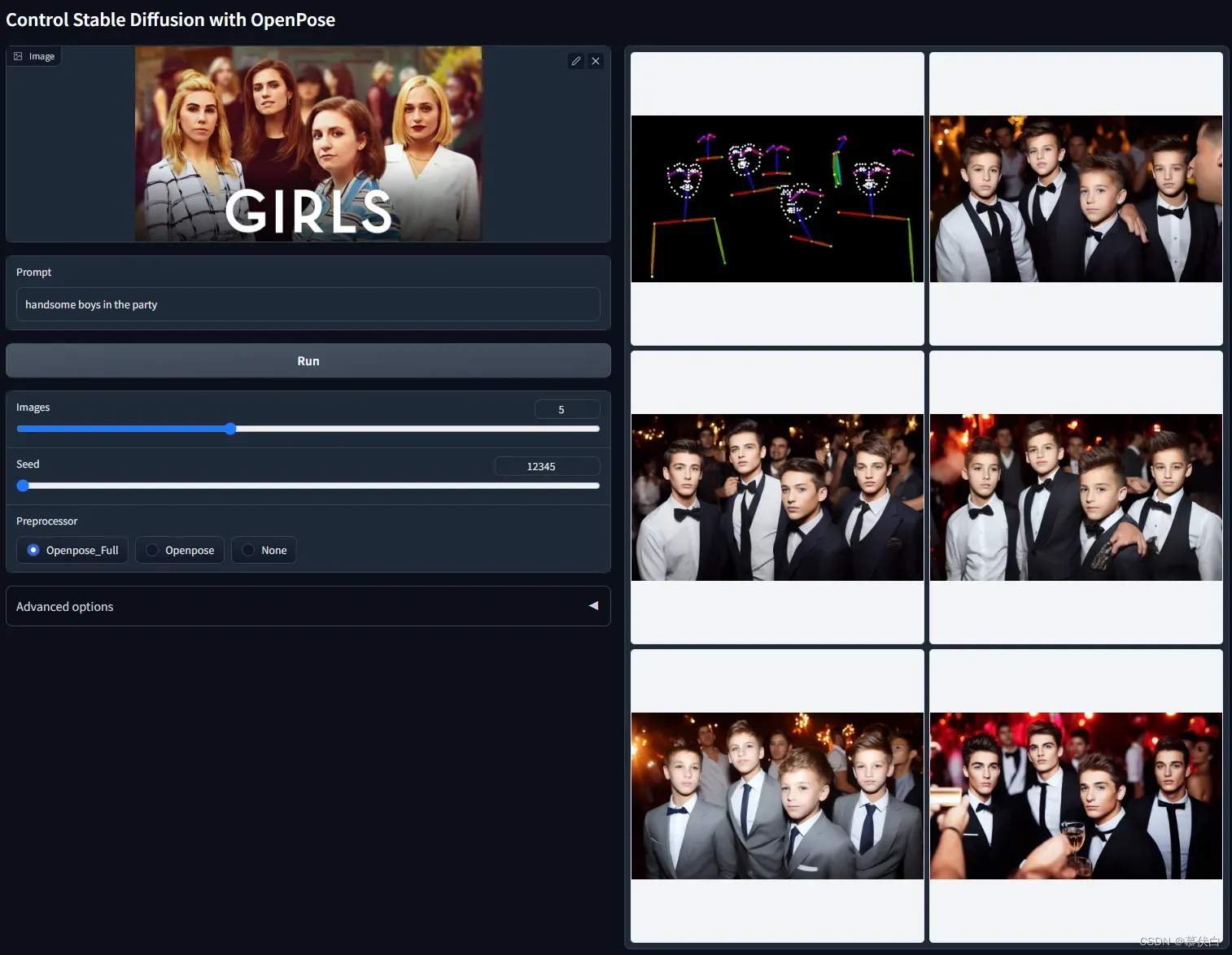
- ControlNet with Depth
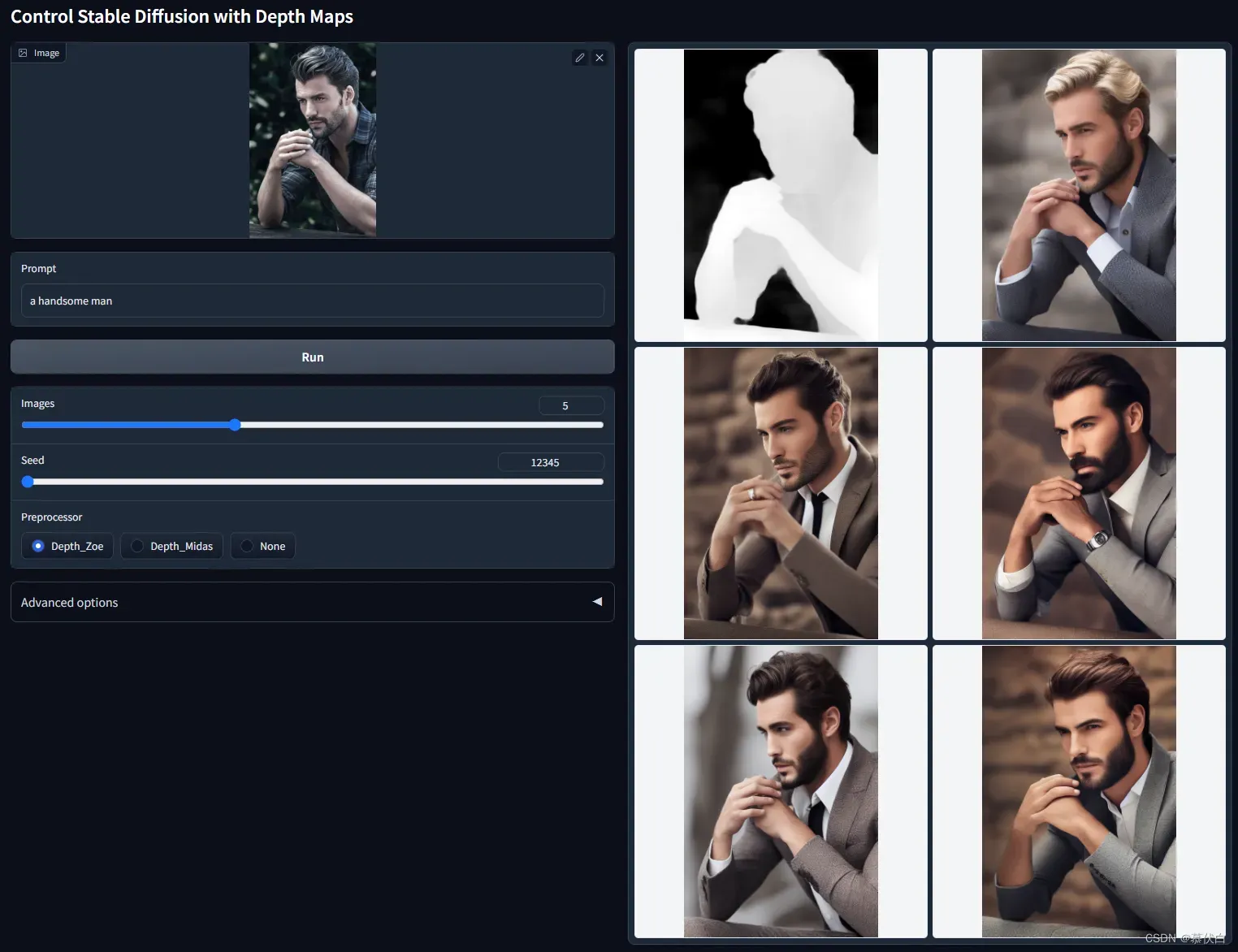
control_depth-fp16需要提供一张图片,预处理器会使用 Midas 深度估计 获取估计图作为输入,并根据深度估计图生成输出图片,创造具有景深的中间图,建筑人物皆可使用,Stability的模型 64×64 深度,ControlNet模型可生成 512×512 深度图。 - 例图:
- ControlNet with Normal Map
control_normal-fp16根据提供的图片,生成对应的法线贴图作为输入。法线贴图是一种模拟凹凸处光照效果的技术,是凸凹贴图的一种实现,相比于深度 Depth Map 模型,法线贴图模型在保留细节方面似乎更好一些。根据底图生成类似法线贴图的中间图,并用此中间图生成建模效果图。此方法适用于人物建模和建筑建模,但更适合人物建模。 - 例图:
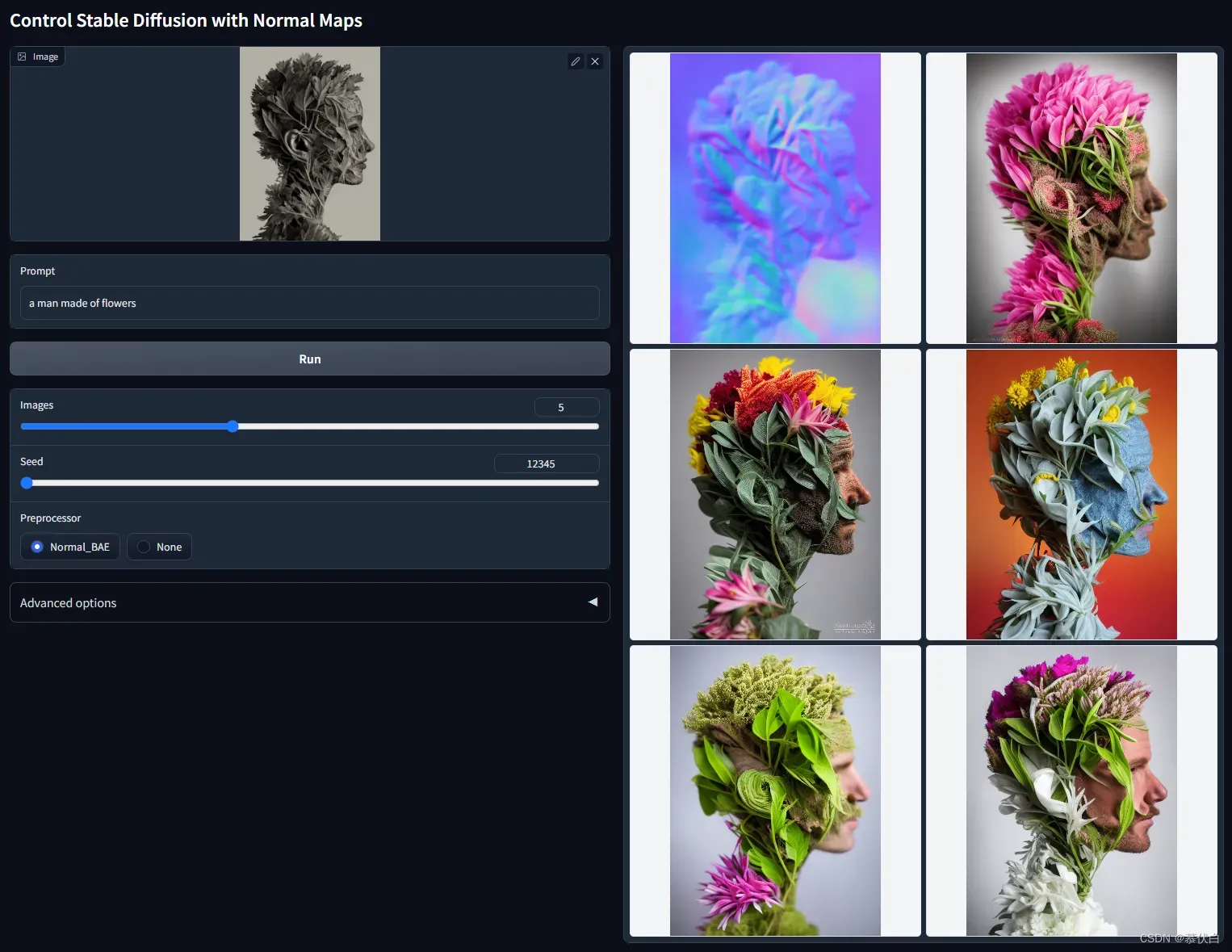
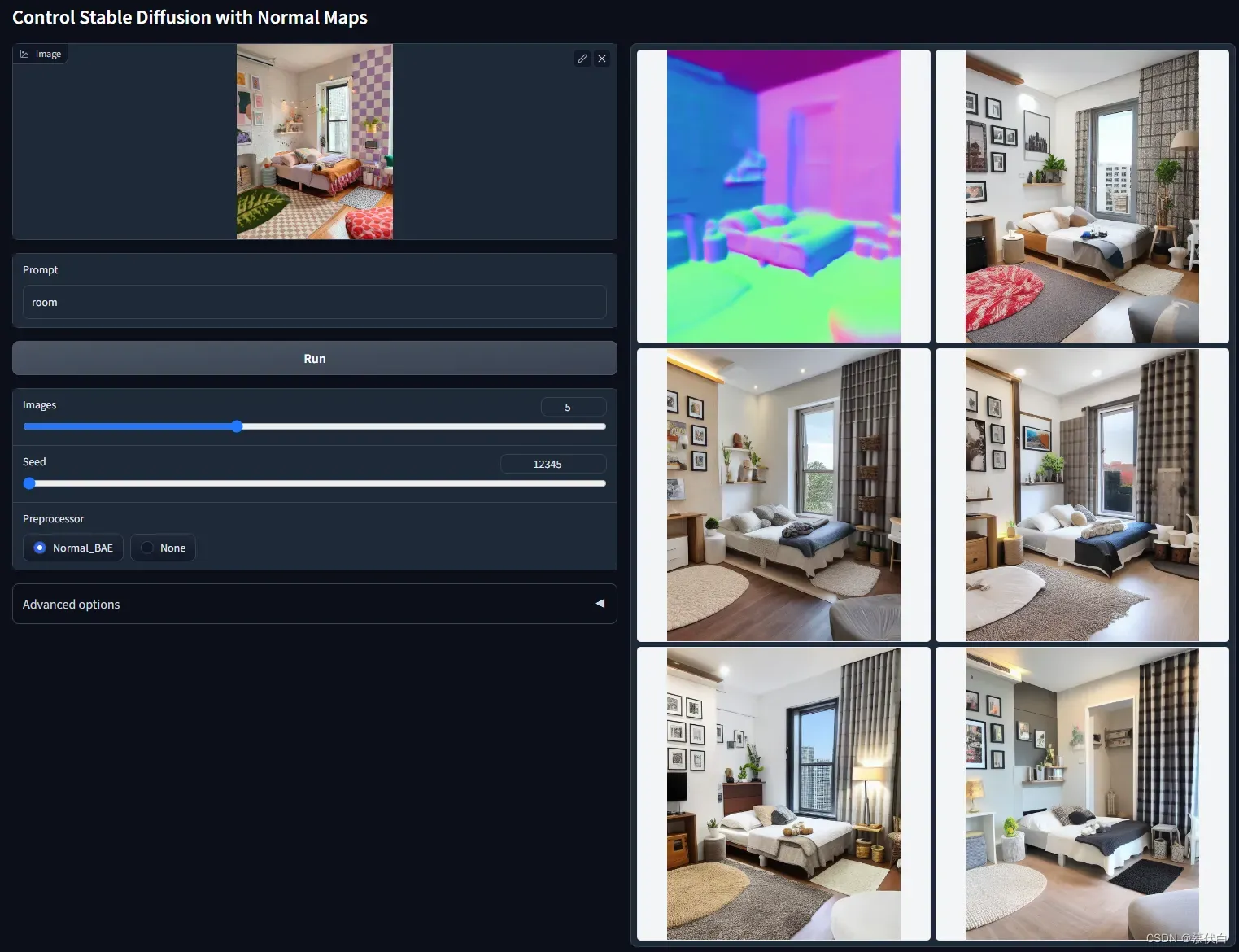
- ControlNet with Segmentation
control_seg-fp16可以对图像种的多个物体,比如建筑、天空、花草树木等,进行区块分割,能够很好的识别主体和背景,使用语义分割来控制SD。现在您需要输入图像,然后一个名为 Uniformer 的模型将为您检测分割。 - 例图:
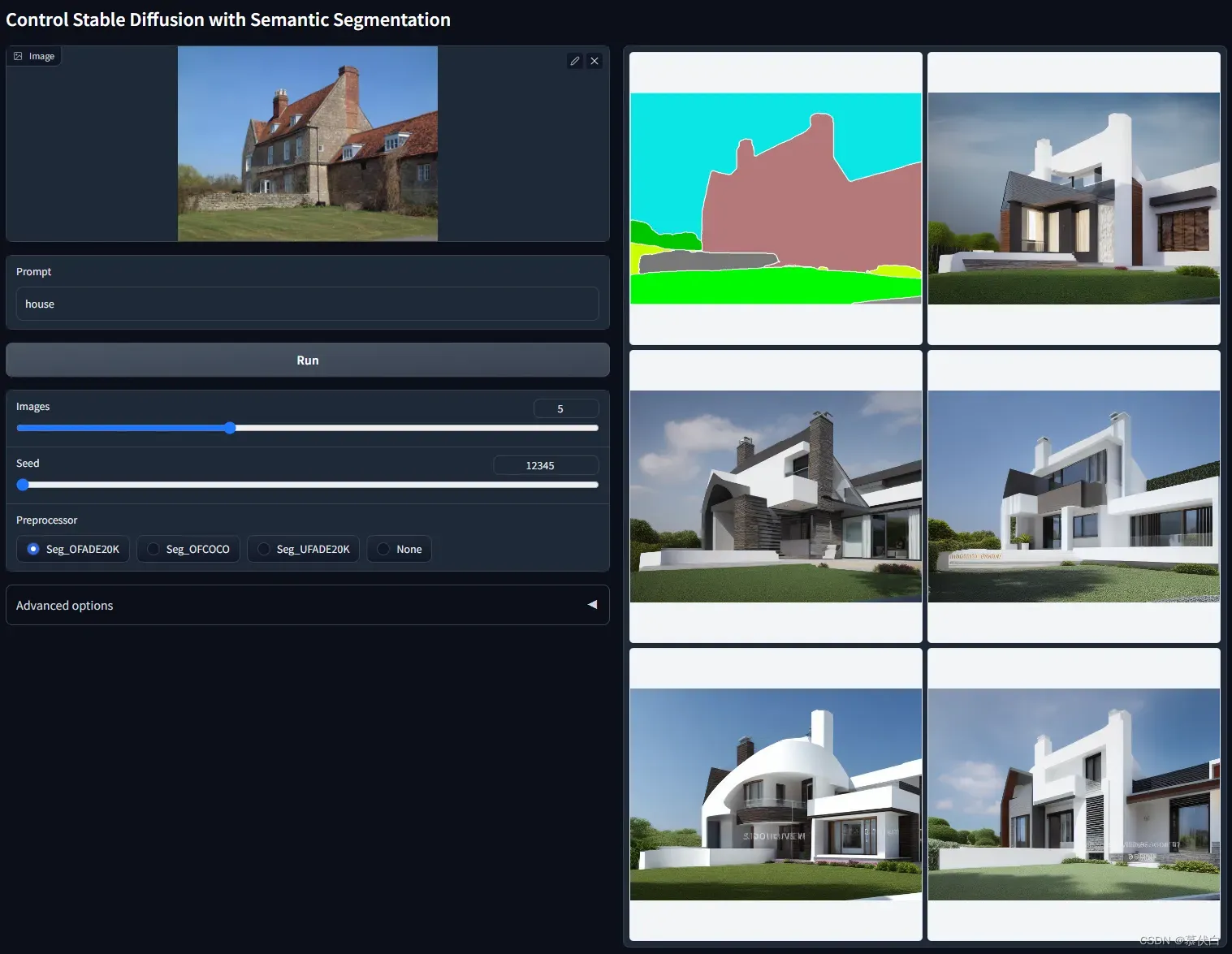
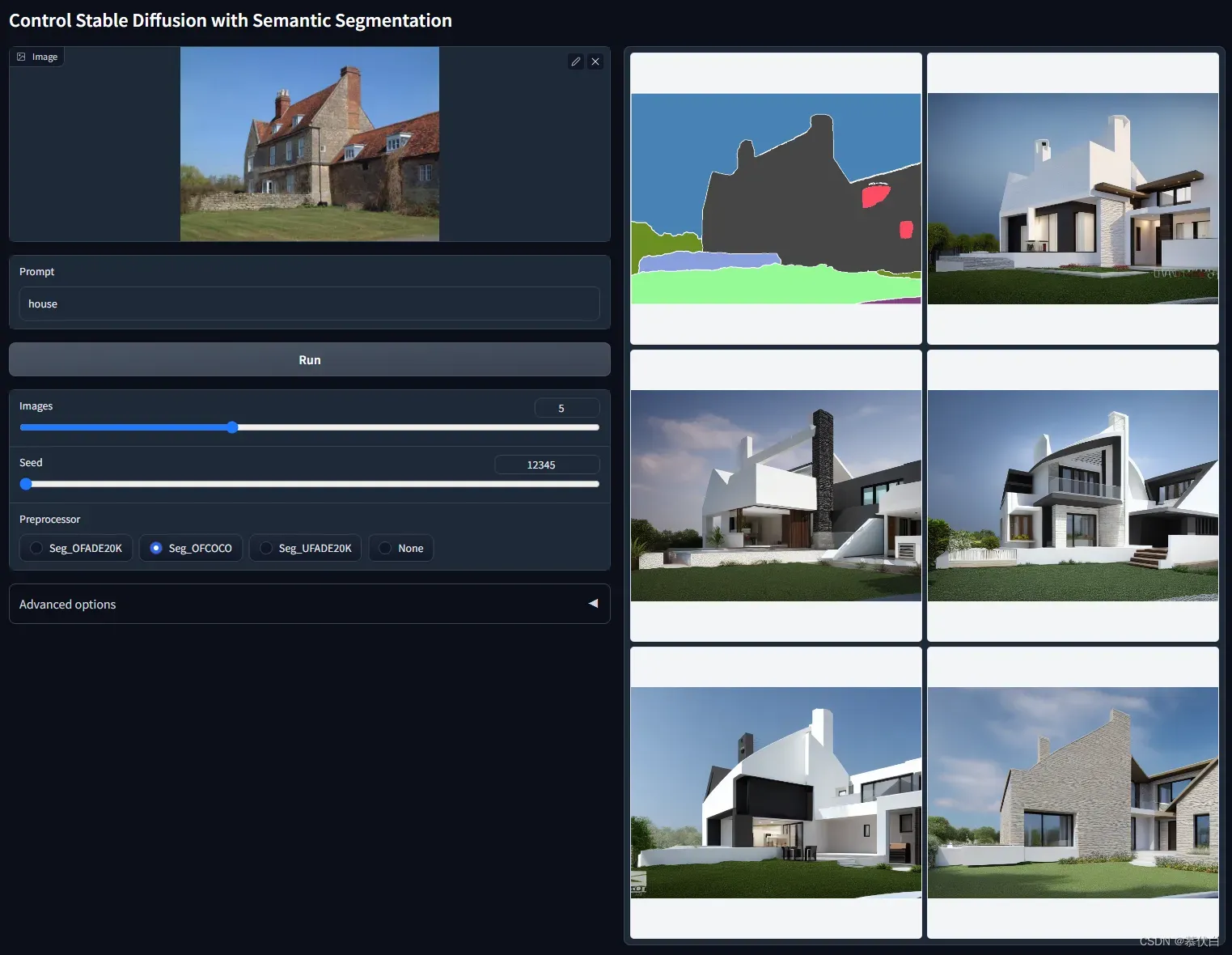
Segmentation使用 注意: 如果语义分割图没有生成出来,请查看控制台是否有报错,另外,检查一下upernet_global_small.pth是否有保存到extensions\sd-webui-controlnet\annotator\uniformer目录。因为SD自己也有一个models\uniformer目录,如果前面没有手动放置好upernet_global_small.pth模型文件,那么在用到Semantic Segmentation模型时,SD会自动下载一个默认文件到它自己的models\uniformer目录,这种情况控制台会报错,可以排查到这个问题。- 可以看到,预处理阶段生成了一张花花绿绿的图片,这就是语义分割图,这图中的每一种颜色都代表了一类物品,比如紫色(
#cc05ff)代表床(bed),橙黄色(#ffc207)代表垫子(cushion),金黄色(#e0ff08)代表台灯(lamp),ControlNet的Semantic Segmentation模型使用的是ADE20K和COCO协议,这些颜色值都可以在下面网址中找到对应的含义:
https://docs.google.com/spreadsheets/d/1se8YEtb2detS7OuPE86fXGyD269pMycAWe2mtKUj2W8/edit#gid=0
https://github.com/CSAILVision/sceneparsing/tree/master/visualizationCode/color150 - 进阶: 修改某个物品的颜色,最终替换生成出来的图中的物品,比如把台灯(
#e0ff08)换成花(#ff0000)
5. 多 ControlNet 组合应用
- 默认情况下只能使用 ControlNet 操纵一种引导生成方式,通过更改设置,使 ControlNet 可以同时经过多个模型引导输出:
Settings—ControlNet—Multi ControlNet 的最大网络数量 - 需要保存设置并重启,启用后可同时设置多个 ControlNet,允许不同模型联合控制与相同模型叠加控制,可用于约束多人动作,也可用于多维度约束
- 若将其值调整为 3 ,就可以使用三个 ControlNet 模型来影响最终图像的生成,建议按需调整
- 使用实例:
完美照片(无限换装法) – 知乎
ai绘画怎么能画出好图? — 更好的图生图效果
6. 参数介绍
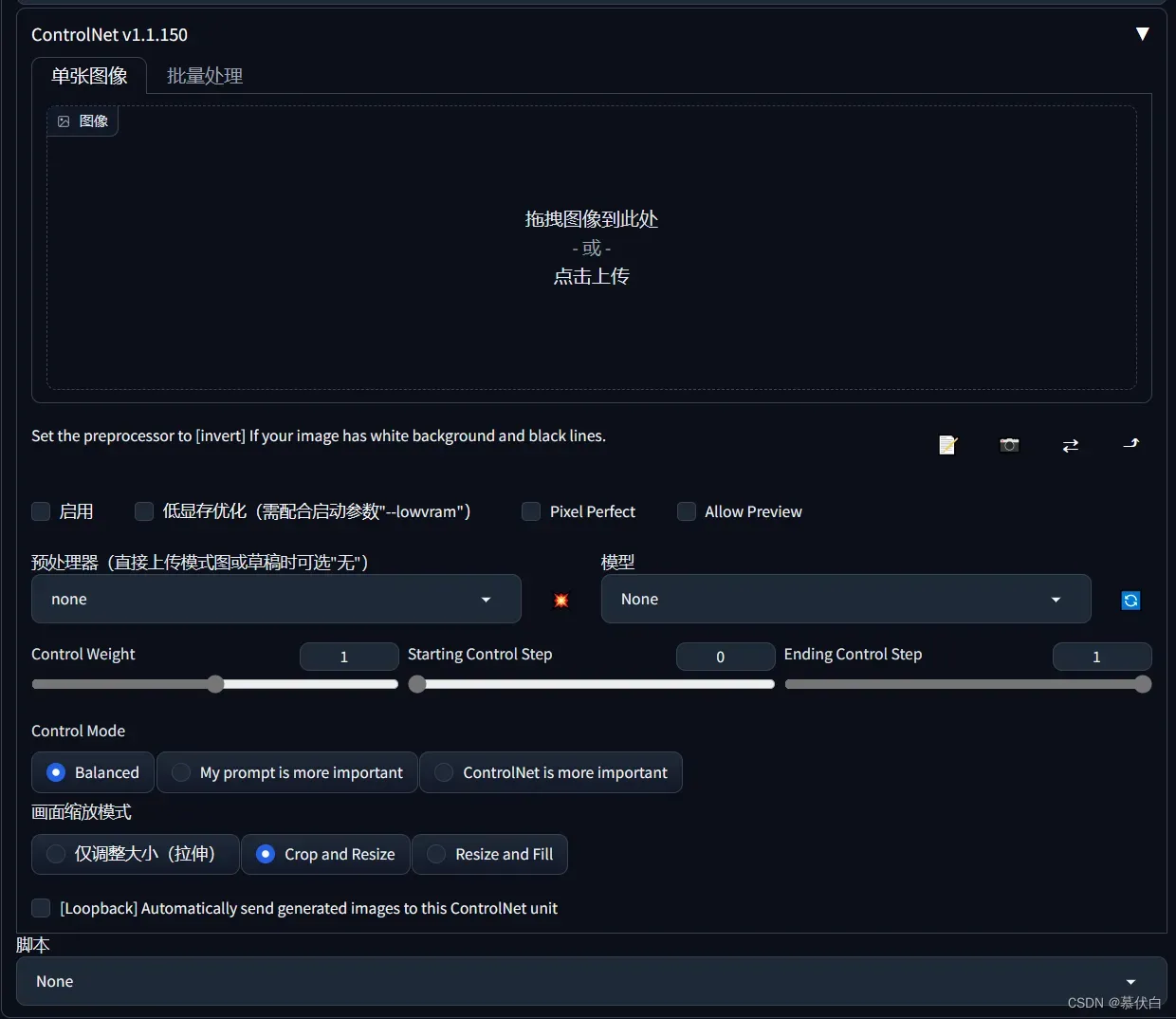
- 启用(Enable)
- 勾选后,点击生成按钮时,将会实时通过
ControlNet引导图像生成,否则不生效。
- 低显存优化(Low VRAM)
- 低显存模式如果你的显卡内存小于4GB,建议勾选此选项,需配合启动参数
--lowvram使用
- 像素完美模式(Pixel Perfect)
- 如果启用像素完美模式,就不需要手动设置预处理器(annotator)的分辨率。
ControlNet将自动为您计算最佳分辨率,使每个像素都与稳定扩散完美匹配。
- Allow Preview
- 允许预览图像
- 预处理器(Preprocessor)
- 该列表是预处理器模型选择,每个
ControlNet的模型都有不同的功能,后续将会单独介绍。
- 模型(Model)
- 该列表的模型选择必须与预处理选项框内的模型名称一致,如果预处理与模型不致也可以出图,但效果无法预料,且并不理想。
- 权重(Weight)
- 权重代表使用
ControlNet生成图片的权重占比影响。
- Starting Control Step
- 开始介入的步数,以百分比表示,设置为 0 表示开始时就介入,设置为 0.2 表示从 20% 的步数开始参与作图
- Ending Control Step
- 结束介入的步数,以百分比表示,设置为 1 表示第 1 步就停止介入,设置为 0.9 表示到 90% 的步数结束参与作图
- Control Mode
- 选择权重的重要强度,相当于从前版本的
Guess Mode

- 画面缩放模式(Resize Mode)
- 调整图像大小模式:默认使用缩放至合适即可,将会自动适配图片。
7. 版本对比
- 原版 canny 算法能主观感受到模型的加载时间,压缩版加载时间较快,1秒左右,生成的图像在质量上肉眼看不出差别,比如人物轮廓,五官位置等(背景有变化不算,这和模型特点有关系,canny 是提取轮廓,轮廓没有大的变化那就不算)
- 腾讯t2i模型在速度上完胜压缩版(因为模型文件比较小),在生成的结果上没有明显差异,但是有细微差异,比如脸型
- 下面参考其他博主的文章,对比下两者的差异,如果想要快请使用压缩版模型,如果要更快请使用腾讯t2i模型,就效果而言,孰优孰劣请自行判断,个人更倾向使用压缩版模型
- 精确控制 AI 图像生成的破冰方案,ControlNet 和 T2I-Adapter
ControlNet和T2I-Adapter有什么区别?
ControlNet在论文里提到,Canny Edge detector模型的训练用了 300 万张边缘-图像-标注对的语料,A100 80G 的 600 个 GPU 小时。Human Pose(人体姿态骨架)模型用了 8 万张 姿态-图像-标注 对的语料, A100 80G 的 400 个 GPU 时。
而T2I-Adapter的训练是在 4 块 Tesla 32G-V100 上只花了 2 天就完成,包括 3 种 condition,sketch(15 万张图片语料),Semantic segmentation map(16 万张)和Keypose(15 万张)。
两者的差异:ControlNet目前提供的预训模型,可用性完成度更高,支持更多种的condition detector(9 大类)。
而T2I-Adapter在工程上设计和实现得更简洁和灵活,更容易集成和扩展(by 读过其代码的 virushuo)此外,T2I-Adapter支持一种以上的condition model引导,比如可以同时使用sketch和segmentation map作为输入条件,或在一个蒙版区域 (也就是inpaint) 里使用sketch引导。
Reference
- 5分钟学会Stable Diffusion强大的ControlNet插件
文章出处登录后可见!