AutoML 是机器学习中一个相对较新的领域,它主要将机器学习中所有耗时过程自动化,如数据预处理、最佳算法选择、超参数调整等,这样可节约大量时间在建立机器学习模型过程中。
今天我将用一个简单的示例来全面讲解 AutoML 工具:Auto-Sklearn,相信你会爱上这个这么省心的工具。文中涉及的数据、代码文末将给出,方便实战练习。
Auto-Sklearn 简介
熟悉机器学习的人都知道 scikit-learn,这是著名的 python 包,由不同的分类和回归算法组成,用于构建机器学习模型。
Auto-Sklearn 是一个基于 Python 的开源工具包,用于执行 AutoML,它采用著名的 Scikit-Learn 机器学习包进行数据处理和机器学习算法。在本文中,我们将了解如何利用 Auto-Sklearn 进行分类和回归任务。
让我们先安装 Auto-Sklearn 包
pip install auto-sklearn
现在我们已经安装了 AutoML 工具,我们将导入用于预处理数据集和可视化的基本包。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
分类任务
我们将使用 UCI 存储库中提供的心脏病预测数据集。为方便起见,让我们使用来自 Kaggle 的数据的.csv 版本。你还可以使用其他分类数据集。
数据集详细信息:该数据集包含 303 个样本和 14 个属性(原始数据集有76个特征,而.csv 版本有原始数据集的14个子集)。
导入数据集
df=pd.read_csv('/content/heart.csv')
df.head()

让我们检查数据集中的目标变量”target”
df['target'].value_counts()

只有两类(0=健康,1=心脏病),所以这是一个二元分类问题。此外,还表明这是一个不平衡的数据集。因此,该模型的准确度得分将不太可靠。
但是,我们将首先通过将不平衡数据集直接馈送到 autosklearn 分类器来测试它。稍后我们将调整这两个类的样本数量并测试准确率,看看分类器的表现如何。
#creating X and y
X=df.drop(['target'],axis=1)
y=df['target']
#split into train and test sets
X_train, X_test, y_train, y_test= train_test_split(X,y, test_size=0.2, random_state=42)
X_train.shape, X_test.shape,y_train.shape, y_test.shape

接下来,我们将使用以下命令从 autosklearn 导入分类模型。
import autosklearn.classification
然后我们将为分类任务创建一个 AutoSklearnClassifier 的实例。
automl = autosklearn.classification.AutoSklearnClassifier( time_left_for_this_task=5*60,per_run_time_limit=30,tmp_folder='/temp/autosklearn_classification_example_tmp')
说明一下,在这里我们使用time_left_for_this_task参数设置此任务的最长时间,并为其分配5分钟。如果没有为此参数指定任何内容,则该过程将运行一个小时,即60分钟。使用per_run_time_limit参数将分配给每个模型评估的时间设置为 30 秒。
此外,还有其他参数,如n_jobs(并行作业数)、ensemble_size、initial_configurations_via_metalearning,可用于微调分类器。默认情况下,上述搜索命令会创建一组表现最佳的模型。为了避免过度拟合,我们可以通过更改设置ensemble_size = 1和initial_configurations_via_metalearning = 0来禁用它。我们在设置分类器时排除了这些以保持方法的简单。
我们还将提供一个临时日志保存路径,稍后我们可以使用它来打印运行详细信息。
现在,我们将拟合分类器
automl.fit(X_train, y_train)
sprint_statistics()函数总结了上述搜索和选择的最佳模型的性能。
pprint(automl.sprint_statistics())

我们还可以使用以下命令打印搜索所考虑的所有模型的排行榜
print(automl.leaderboard())
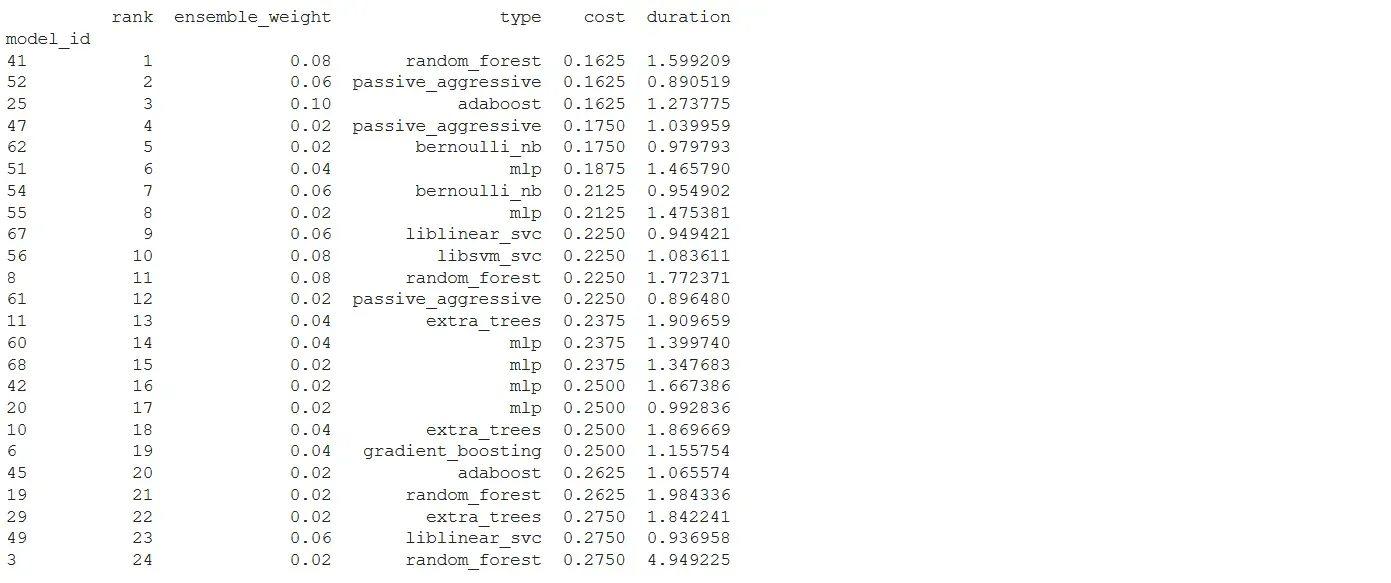
分类器选择的前两个模型分别是随机森林和 Passive_aggressive。
此外,我们可以通过以下方式打印有关正在考虑的模型的信息:
pprint(automl.show_models())
我们还可以打印集成的最终分数和混淆矩阵。
# Score of the final ensemble
from sklearn.metrics import accuracy_score
m1_acc_score= accuracy_score(y_test, y_pred)
m1_acc_score
from sklearn.metrics import confusion_matrix, accuracy_score
y_pred= automl.predict(X_test)
conf_matrix= confusion_matrix(y_pred, y_test)
sns.heatmap(conf_matrix, annot=True)
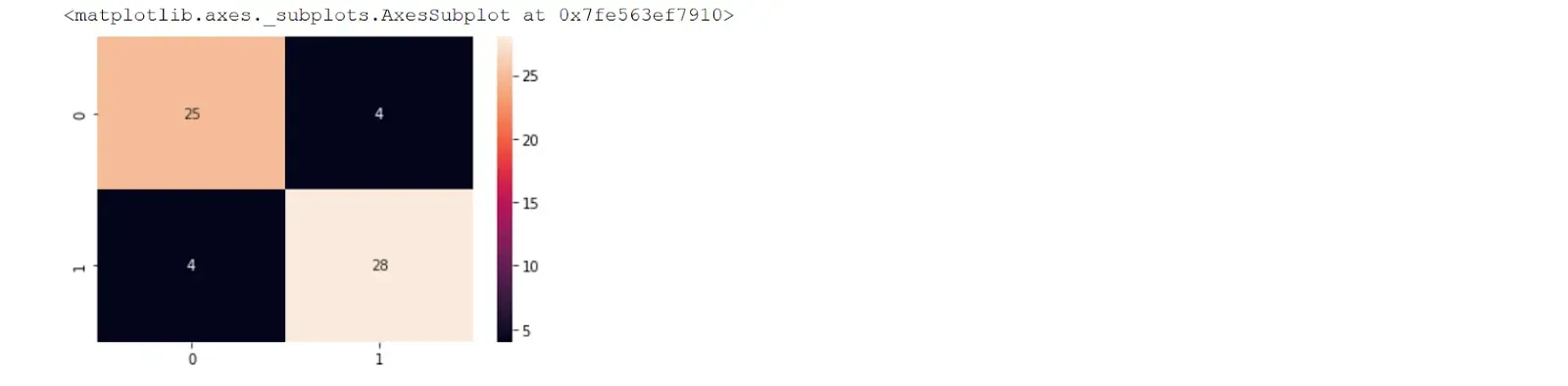
我们可以使用以下命令来分离数据集中健康和不健康的样本
from sklearn.utils import resample
healthy= df[df["target"]==0]
unhealthy=df[df["target"]==1]
随着不健康样本数量的增加,我们将使用重采样技术(过采样)并增加数据集中健康个体的样本。要调整偏斜,我们可以使用以下命令
up_sampled=resample(healthy, replace=True, n_samples=len(unhealthy), random_state=42)
up_sampled=pd.concat([unhealthy, up_sampled])
#check updated class counts
up_sampled['target'].value_counts()
我们还可以使用SMOTE、集成学习(bagging、boosting)、NearMiss 算法等技术来解决数据集中的不平衡问题。此外,我们可以使用 F1-score、精度和召回等指标来评估模型的性能。
现在我们已经调整了倾斜,我们将再次创建 X 和 y 集进行分类。 让我们将它们命名为 X1 和 y1 以避免混淆。
X1=up_sampled.drop(['target'],axis=1)
y1=up_sampled['target']
我们需要重复从设置分类器到为这个新的 X1 和 y1 打印混淆矩阵的所有步骤。
最后,我们可以使用以下方法比较偏斜和调整数据的两种准确度
model_eval = pd.DataFrame({'Model': ['skewed','adjusted'], 'Accuracy': [m1_acc_score,m2_acc_score]})
model_eval = model_eval.set_index('Model').sort_values(by='Accuracy',ascending=False)
fig = plt.figure(figsize=(12, 4))
gs = fig.add_gridspec(1, 2)
gs.update(wspace=0.8, hspace=0.8)
ax0 = fig.add_subplot(gs[0, 0])
sns.heatmap(model_eval,cmap="PiYG",annot=True,fmt=".1%", linewidths=4,cbar=False,ax=ax0)
plt.show()
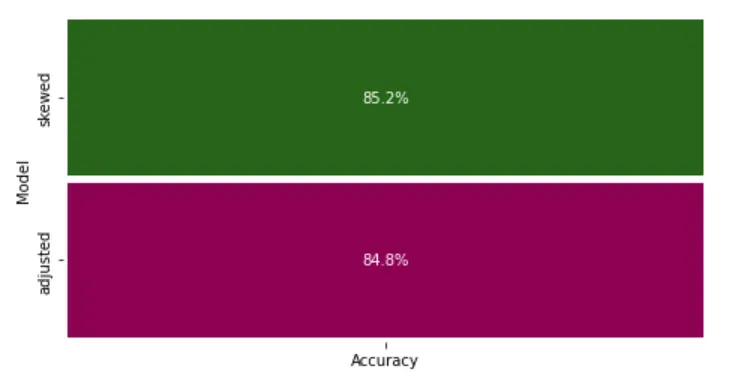
从上图中,模型精度在过采样后略有下降,我们可以看到模型现在优化得更好。尽管我们使用了很多额外的命令来预处理数据和评估结果,但运行 AutoSklearn 分类器只需要一行代码。即使有倾斜的数据,模型实现的准确性也非常好。
返回任务
现在我们将在本节中使用来自 AutoSklearn 的回归模型。
对于这项任务,让我们使用 seaborn 数据集库中的简单”航班”数据集。我们将使用以下命令加载数据集。
#loading the dataset
df = sns.load_dataset('flights')
df.head()

数据集详情:该数据集包含144行3列,分别为年、月、旅客人数。
这里的任务是使用其他两个特征来预测乘客数量。
X=df.drop(["passengers"],axis=1)
y=df["passengers"]
X.shape, y.shape

X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train.shape, X_test.shape,y_train.shape, y_test.shape

我们现在使用 autosklearnregressor 来完成这个回归任务。
import autosklearn.regression
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=5*60,per_run_time_limit=30,tmp_folder='/temp/autosklearn_regression_example_tmp')
automl.fit(X_train, y_train)
from sklearn.metrics import mean_absolute_error
from autosklearn.metrics import mean_absolute_error as auto_mean_absolute_error
现在,让我们看看模型的统计数据
# summarize
print(automl.sprint_statistics())

从上面总结中,我们了解到回归器一共跑了 59 个模型,最终回归模型的计算性能为 0.985 的 R2,相当不错。
由于回归器默认优化了 R2 指标,让我们打印平均绝对误差来更好地评估模型的性能。
# evaluate the best model
y_pred = automl.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
print("MAE: %.3f" % mae)

从模型实现的 R2 值和用于此任务的示例数据集的大小来看,平均绝对误差是可以接受的。
我们还可以使用 matplotlib 绘制预测值与实际值,如下所示
plt.figure(figsize=(8,6))
plt.scatter(y_test, y_pred, c='blue')
p1 = max(max(y_pred), max(y_test))
p2 = min(min(y_pred), min(y_test))
plt.plot([p1, p2], [p1, p2], 'r-')
plt.xlabel('Actual', fontsize=10)
plt.ylabel('Predicted', fontsize=10)
plt.legend(['Actual', 'Predicted'])
plt.axis('equal')
plt.show()
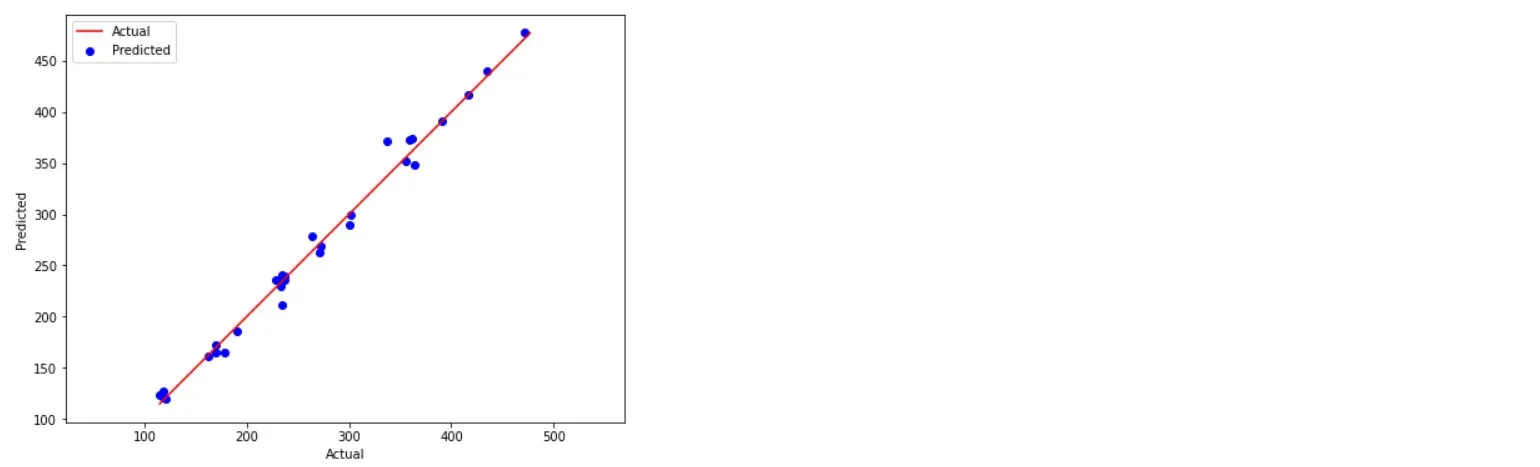
总的来说,可以说MAE值很小,模型取得了很高的验证分数,为0.985,说明模型性能不错。
保存训练好的模型。
上面训练的分类和回归模型可以使用 python 包 Pickle 和 JobLib 保存。然后可以使用这些保存的模型直接对新数据进行预测。我们可以将模型保存为:
1、Pickle
import pickle
# save the model
filename = 'final_model.sav'
pickle.dump(model, open(filename, 'wb'))
这里的”wb”参数意味着我们正在以二进制模式将文件写入磁盘。此外,我们可以将此保存的模型加载为:
#load the model
loaded_model = pickle.load(open(filename, 'rb'))
result = loaded_model.score(X_test, Y_test)
print(result)
这里的”rb”命令表示我们正在以二进制模式读取文件
2、JobLib
同样,我们可以使用以下命令将训练好的模型保存在 JobLib 中。
import joblib
# save the model
filename = 'final_model.sav'
joblib.dump(model, filename)
我们还可以稍后重新加载这些保存的模型以预测新数据。
# load the model from disk
load_model = joblib.load(filename)
result = load_model.score(X_test, Y_test)
print(result)
综上所述
在本文中,我们看到了Auto-Sklearn在分类和回归模型中的应用。对于这两个任务,我们不需要指定特定的算法。
相反,该工具本身迭代了几个内置算法并获得了良好的结果(分类模型的准确性更高,回归模型的平均绝对误差更低)。
因此,AutoSklearn 可以成为使用几行代码构建更好的机器学习模型的宝贵工具。
采集方法:
代码和资料已打包,领取前记得点赞、收藏、关注。有两种获取方式:
- 方式一、发送如下图片至微信,长按识别,回复:automl;
- 方式二、微信搜索公众号:Python学习与数据挖掘,后台回复:automl

版权声明:本文为博主Python学习与数据挖掘原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_38037405/article/details/123176017