前言
学习爬虫你完全可以理解为找辣条君借钱(借100万),首先如果想找辣条借钱那首先需要知道我的居住地址,然后想办法去到辣条的所在的(可以走路可以坐车),然后辣条身上的东西比较多,有100万,打火机,烟,手机衣服,需要从这些东西里面筛选出你需要的东西,拿到你想要的东西之后我们就可以去存钱,我们通过一个图片来理解爬虫的运行流程:
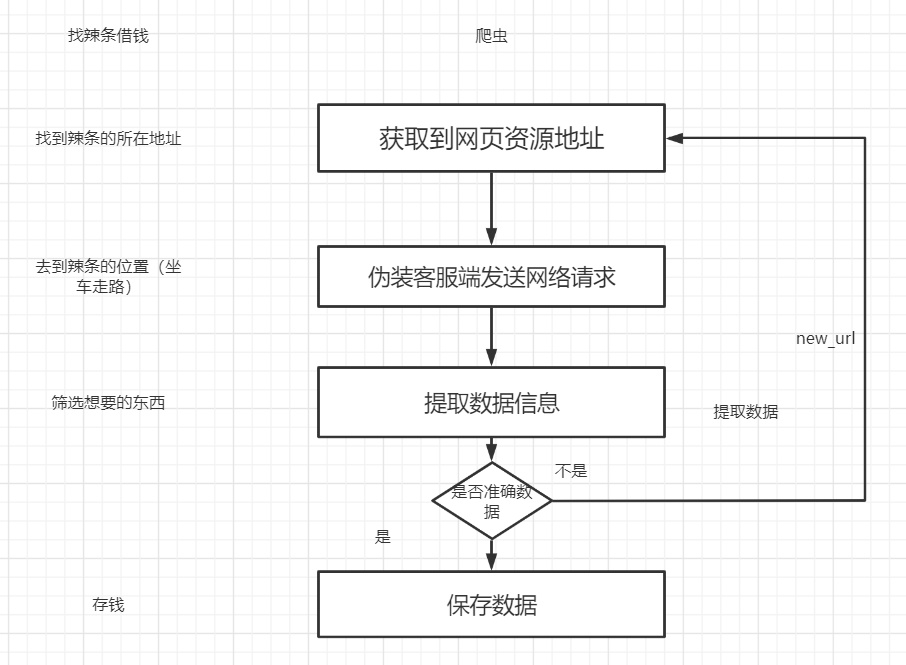
爬虫的流程至关重要,要是能把这个流程搞定那么爬虫的过程在你的脑海里就有基本的认知,可以说你的爬虫就已经学会20%了

一、获取数据地址信息
认识网址
首先我们先来认识所谓的网址,网址的高端叫法叫做‘统一资源定位符’,在互联网里面如果获取到数据都是通过网址来定位到的(就跟你找辣条借钱首先需要知道辣条目前所在的地址)那么每天都在用的网址到底是有什么特殊的含义呢?
网址有包含:协议部分、域名部分、文件名部分、参数部分
1、协议比较常见的就是http以及hettps
2、域名部分也就是我们说的服务器地址
3、文件名部分就是我们所需要的数据所在的地方
4、参数部分根据我们所查询的条件筛选数据
总而言之我们知道需要获取到互联网数据需要拿到网址

数据的区分
回过头思考一下找辣条借钱的案列,如果你想找到辣条是需要通过我的地址,那么我给的地址可能是我的工作地址,那要是我回家我的地址就更换了,那么我们所说的网址也是的,我们能在搜索页面看到的网址是静态网址,那我们有些网址的数据是在不断更新的(类似新闻网站),那这种不断加载的数据就叫做动态数据,那我要如何区分我们的数据是静态数据还是动态数据呢?
1、我们可以直接观察页面,静态数据加载的会更快一些,动态数据加载相对慢一些
2、我们可以在浏览器页面鼠标右击点击查看网页源代码,搜索你需要的数据如果有就是静态数据,如果没有就是动态数据
抓包
那我们的动态数据要如何获取呢?可以通过抓包的方式获取,何为抓包;众所周知我们在互联网里所获取的数据都是通过网络,那我们能不能把这些网络传递的数据从中进行拦截,举个例子我们现在外出上班都需要租房,按照正常的想法是租客找房东获取到房源信息,这个是理想状态,但是我们现在想租房好的房源信息都是在中介的手里,就会出现我想租房需要先找到中介,然后中介找房东获取优质房源,房东返回房源信息给中介,中介在给我,那么抓包也是这个意思,我可以从中拦截所有的数据信息
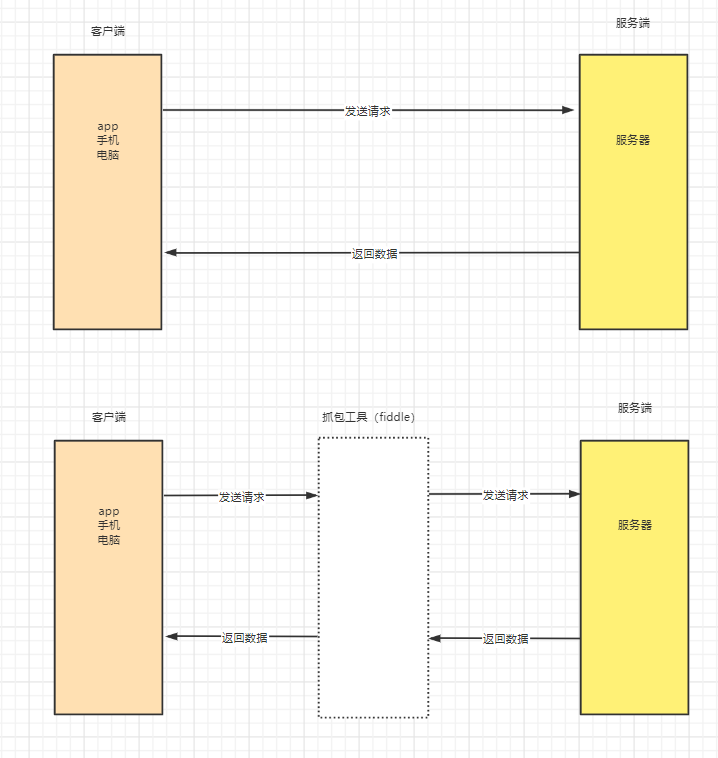
那这个抓包我们应该要怎么使用呢,每个浏览器都会自带抓包工具,在浏览器页面鼠标右击点击检查(这里推荐大家使用谷歌的浏览器,方便快捷更专业)
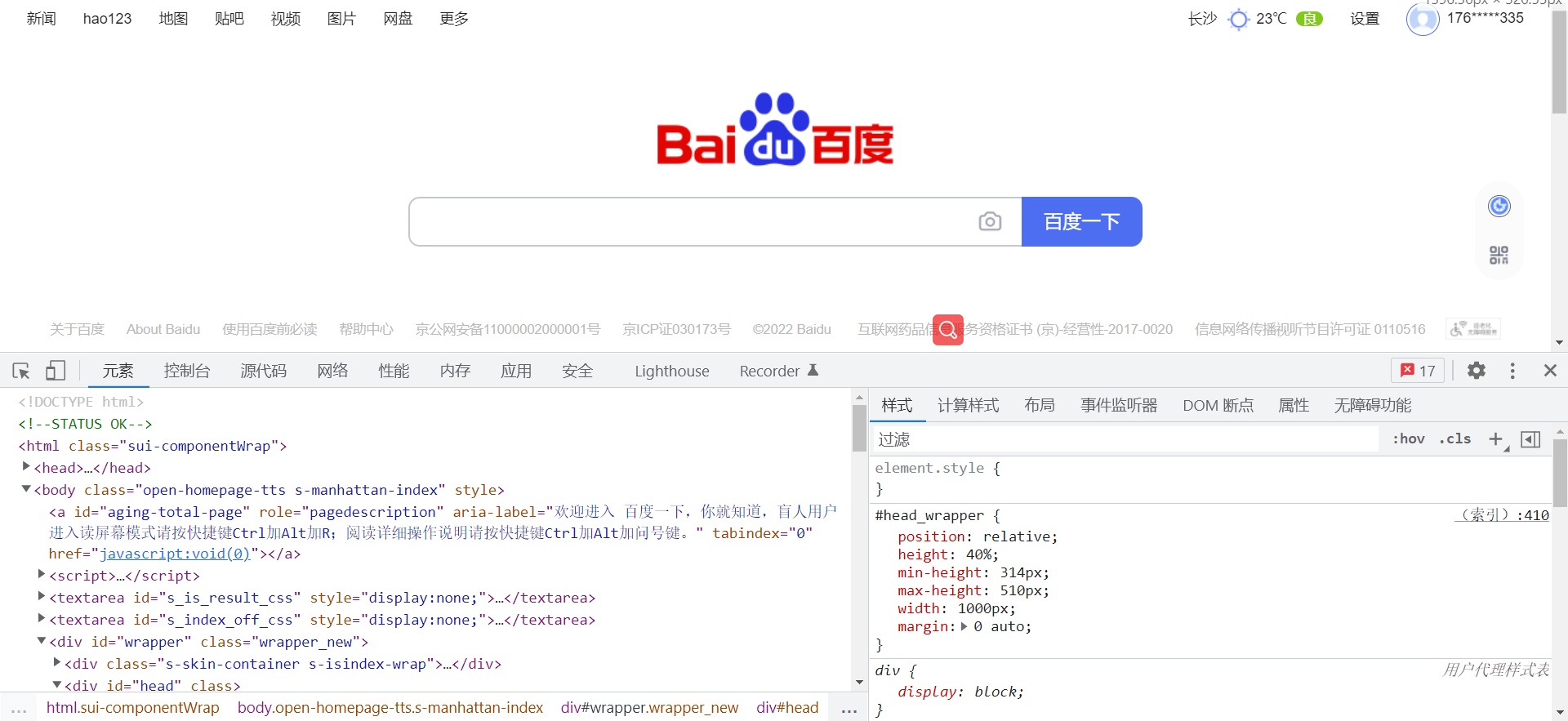
元素:网页加载之后的代码信息
控制台:可以用来调试网页代码
源代码:网页开发的源代码信息
网络:通过网络加载的全部数据
这4个是我们重点需要学习的内容,那我们想要的动态数据就在网络的XHR选项里,可以通过这种方式获取到我们想要的网络数据
二、发送网络请求
当我们获取到目标地址之后正常的第一想法是,在浏览器的搜索框复制看看这个网址是得到什么数据,那我们想通过爬虫取实现的话就需要通过代码,那怎么去实现呢,我们可以使用Python的第三方工具去进行,常见的第三方库urllib,requests,scrapy,…,在刚刚学习时requests就已经能够满足我们日常的需求,发送请求我们需求注意我们作为一个爬虫请求别人的网址是不受欢迎的,就好比你找辣条借钱,但是我跟你素不相识我是没有理由借给你的,同理爬虫在请求网址时有些网站也是不想给我们数据的,那我们怎么办呢? 你可以把自己进行伪装,伪装成辣条的亲朋好友我才可能借钱给你,我们爬虫的核心就在于伪装成浏览器发送网络请求
伪装成客户端(浏览器,APP)
那我们怎样伪装呢?我们在抓包的时候在标头里会有请求标头会看到入下的数据,那我们来重点认识一些关键的信息:
Accept:浏览器接受的数据
Accept-Encoding:接受的格式
Accept-Language:接受的语言
Connection:链接的类型
Cookie:实现状态保存,可以怎么去理解他呢,可以用来记录你的用户信息,就好比你之前找我借钱,我会给你写个借条,下次你过来借钱拿着这个借条我就知道是你
Host:链接的主机
Referer:来源、防盗链接, 类似想我们现在的行程码你是从来个地方来的
User-Agent:用户代理,浏览器的身份标识,可以理解为你的身份证
那么这些东西都是我们在发送请求需要带上证明自己身份的东西
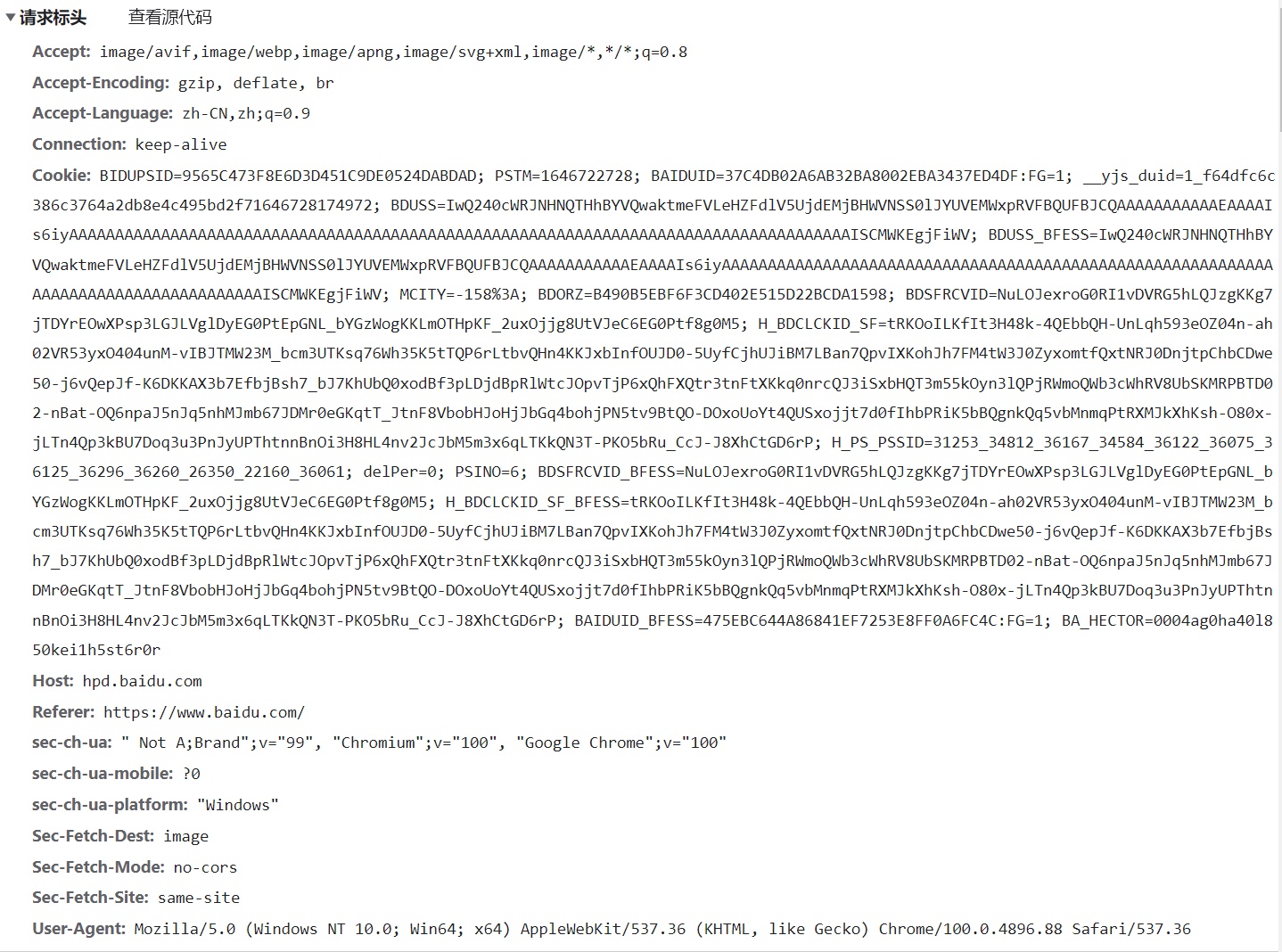
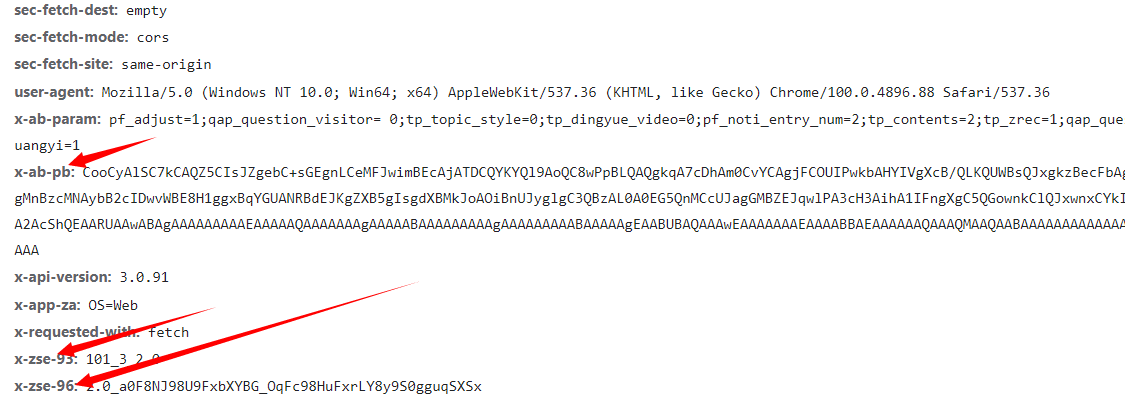
请求头加密
请求头的东西并不是一成不变的有时候会有一些特殊的字段,那我们需要加什么请求头也是根据你的网址来的,那我们看到的请求字段可能是加密的如下图,那么我们要是遇见这种加密的我们又该如何进行参数的传递呢?就需要进行js逆向(js逆向就不在这里开展讲解)
请求方式
请求方式是用来区分网址的请求规律,常见的有get和post,get一般是获取网页的数据,post需要提交数据给服务器(比方说你登录的时候需要把账户和密码进行传递)


提取数据
通过爬虫获取的数据分为结构化数据和非结构化数据
结构化数据:json、xml
非结构数据:html
针对我们获取的数据的不同提取数据的方式也不一样,要是我们获取的是json数据我们可以直接将其转换成字典类型进行获取数据,要是我们获取的是html的数据我们可以通过xpath、bs4、pyquery、正则等方式进行提取,这里我们重点学习xpath
XPath 术语
节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
请看下面这个 XML 文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
上面的XML文档中的节点例子:
<bookstore> (文档节点)
<author>J K. Rowling</author> (元素节点)
lang="en" (属性节点)
基本值(或称原子值,Atomic value)
基本值是无父或无子的节点。
基本值的例子:
J K. Rowling
"en"
项目(Item)
项目是基本值或者节点。
节点关系
父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
XML 实例文档
我们将在下面的例子中使用这个 XML 文档。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()< 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XML 实例文档
我们将在下面的例子中使用此 XML 文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
XPath 轴
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
位置路径表达式
位置路径可以是绝对的,也可以是相对的。
绝对路径起始于正斜杠( / ),而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:
绝对位置路径:
/step/step/...
相对位置路径:
step/step/...
每个步均根据当前节点集之中的节点来进行计算。
步(step)包括:
-
轴(axis)
定义所选节点与当前节点之间的树关系
-
节点测试(node-test)
识别某个轴内部的节点
-
零个或者更多谓语(predicate)
更深入地提炼所选的节点集
步的语法:
轴名称::节点测试[谓语]
实例
| 例子 | 结果 |
|---|---|
| child::book | 选取所有属于当前节点的子元素的 book 节点。 |
| attribute::lang | 选取当前节点的 lang 属性。 |
| child:: * | 选取当前节点的所有子元素。 |
| attribute:: * | 选取当前节点的所有属性。 |
| child::text() | 选取当前节点的所有文本子节点。 |
| child::node() | 选取当前节点的所有子节点。 |
| descendant::book | 选取当前节点的所有 book 后代。 |
| ancestor::book | 选择当前节点的所有 book 先辈。 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child:: */child::price | 选取当前节点的所有 price 孙节点。 |
XPath 表达式可返回节点集、字符串、逻辑值以及数字。
XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| – | 减法 | 6 – 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
XML实例文档
我们将在下面的例子中使用这个 XML 文档:
“books.xml” :
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
加载 XML 文档
所有现代浏览器都支持使用 XMLHttpRequest 来加载 XML 文档的方法。
针对大多数现代浏览器的代码:
var xmlhttp=new XMLHttpRequest()
针对古老的微软浏览器(IE 5 和 6)的代码:
var xmlhttp=new ActiveXObject("Microsoft.XMLHTTP")
选取节点
不幸的是,Internet Explorer 和其他处理 XPath 的方式不同。
在我们的例子中,包含适用于大多数主流浏览器的代码。
Internet Explorer 使用 selectNodes() 方法从 XML 文档中的选取节点:
xmlDoc.selectNodes(xpath);
Firefox、Chrome、Opera 以及 Safari 使用 evaluate() 方法从 XML 文档中选取节点:
xmlDoc.evaluate(xpath, xmlDoc, null, XPathResult.ANY_TYPE,null);
选取所有 title
下面的例子选取所有 title 节点:
/bookstore/book/title
四、保存数据
数据的保存一般根据企业的要求,基本都是保存在数据库的,数据库主要掌握mysql、mongdb
文章出处登录后可见!