任务描述
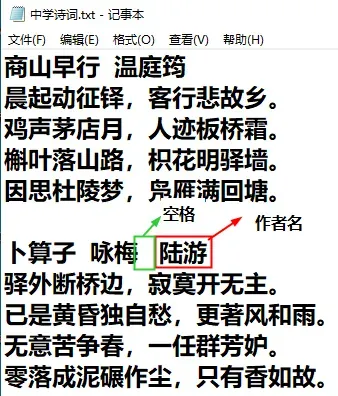
本关任务:编写一个能计算文档《中学诗词.txt》中各位作者作品数量的程序。 遍历文档中每一行,提取作者的姓名,将其作为键加入到字典中,字典的值为作品数量。 然后将字典转换为二维列表,按作品数量的降序排列。
相关知识
为了完成本关任务,你需要掌握:1.字典的操作,2.字典转换为列表。
字典的操作
字典是另一种可变容器模型,且可存储任意类型对象。 字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示 d = {key1 : value1, key2 : value2 } 建立空字典 d={} 向字典添加新内容的方法是增加新的键/值对 d[“范仲淹”]=1 则d为{“范仲淹”:1} 修改键值对的方法为 d[“范仲淹”]=2 则d为{“范仲淹”:2} d[“范仲淹”]的值为2
d.get(key,default)键存在则返回相应值,否则返回默认值
字典转换为二维列表
lt = list(d.items()) 可将字典转换为二维列表, 二维列表的每项值为列表,列表的第一项为字典的键,第二项为字典的值
编程要求
根据提示,在右侧编辑器补充代码,计算并显示各位作者作品数量。
测试说明
平台会对你编写的代码进行测试:

没有伞的孩子,只能学会努力奔跑。 开始你的任务吧,祝你成功!
f1=open("sy9//中学诗词.txt","r",encoding='utf-8')
#代码开始
d={}
fh=[",","。","!","?",",",".","?","!"]
f1.seek(0)
for line in f1:
flag=0
for i in fh:
if i in line:
flag=1
break
else:
m=line.strip()
s=m.rfind(" ")
xm=m[int(s)+1:]
if flag==0 and ("上" not in xm) and ("下" not in xm) and (xm!=""):
if xm not in d:
d[xm]=1
else:
d[xm]=d[xm]+1
lt=list(d.items())
lt.sort(key=lambda x:x[1],reverse=True)
#代码结束
for i in lt:
print(i[0],i[1])
f1.close()任务描述
本关任务:编写一个能统计候选人票数的小程序。
多人对若干个候选人投票。 循环输入候选人的名字,将其存入到列表tp中,直到输入end为止 计算每个候选人的得票数,按从高到低显示名次、姓名、票数 例如输入 li zhang wang li li zhang zhang wang li li end 显示结果为 第1名姓名li票数5 第2名姓名zhang票数3 第3名姓名wang票数2
开始你的任务吧,祝你成功!
tp=[]
x=input("")
while(x!="end"):
tp.append(x)
x=input("")
#代码开始
zd={}
for i in tp:
if i not in zd:
zd[i]=1
else:
zd[i]=zd[i]+1
items=list(zd.items())
items.sort(key=lambda x:x[1],reverse=True)
#代码结束
for i in range(len(items)):
print("第{}名姓名{}票数{}".format(i+1,items[i][0],items[i][1]))任务描述
本关任务:编写一个能计算会员会费的小程序。 某网站可以充值影视会员和体育会员。 影视会员为影视黄金会员(会费199)和影视星钻会员(会费399) 体育会员为体育大众会员(会费98)和体育专业会员(会费198) 会员名单.txt文件如下所示,计算并显示每人的姓名和会费

注意:使用字典来存放不同的会费标准
测试说明
平台会对你编写的代码进行测试:

盛年不重来,一日难再晨。及时宜自勉,岁月不待人。 开始你的任务吧,祝你成功!
f1=open("sy9//会员名单.txt","r",encoding="utf8")
#代码开始
zd1={"影视黄金会员":199,"影视星钻会员":399,"非影视会员":0,}
zd2={"体育大众会员":98,"体育专业会员":198,"非体育会员":0}
for line in f1:
hy=line.strip().split(",")
hf=zd1.get(hy[1],0)+zd2.get(hy[2],0)
print("{} {}".format(hy[0],hf))
#代码结束
f1.close()任务描述
编写一个计算职工工资的小程序 列表zg中存储了员工的姓名、基本工资、分公司和部门信息 格式如下(逗号分隔) mike,9200,北京,销售部 各分公司的津贴标准如下:北京5000上海4000广州3000) 各部门的津贴标准如下:销售部2000经理室3000财会部1000 计算每位员工的工资:基本工资加上分公司津贴和部门津贴 提示:可以分别用两个字典存放津贴。 将每位员工的姓名和工资存放到列表yfgz中 再按工资的降序排列,并显示出来 每行的显示格式为 姓名harry工资16700
例如,输入mike,9200,北京,销售部 harry,8700,北京,经理室 henry,4300,北京,财会部 tony,6600,上海,销售部 tom,7400,上海,财会部 rachel,5200,上海,财会部 jerry,6500,广州,销售部 andy,7600,广州,销售部 rose,6700,北京,财会部 结果为 姓名harry工资16700 姓名mike工资16200 姓名rose工资12700 姓名tony工资12600 姓名andy工资12600 姓名tom工资12400 姓名jerry工资11500 姓名henry工资10300 姓名rachel工资10200
开始你的任务吧,祝你成功!
zg=[]
xx=input("")
while(xx!="end"):
sj=xx.split(',')
zg.append([sj[0],eval(sj[1]),sj[2],sj[3]])
xx=input("")
#代码开始
jt1={"北京":5000,"上海":4000,"广州":3000}
jt2={"销售部":2000,"经理室":3000,"财会部":1000}
yfgz=[]
for i in range(len(zg)):
jt=zg[i][1]+jt1.get(zg[i][2],0)+jt2.get(zg[i][3],0)
yfgz.append([zg[i][0],jt])
yfgz.sort(key=lambda x:x[1],reverse=True)
#代码结束
for x in yfgz:
print("姓名"+x[0]+"工资"+str(x[1])) 任务描述
本关任务:编写一个根据汇率兑换文件的汇率进行外币兑换人民币的小程序。 sy9文件夹下《汇率兑换.txt》文件如下图所示 每行显示1外币名称(外币编码)=汇率人民币
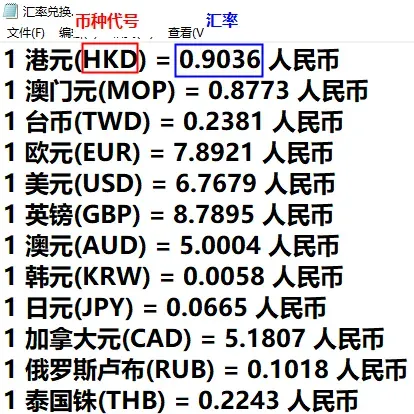
根据这些信息建立一个字典,键为外币编码,值为汇率(数值) 例如,第一项为{“HKD”:0.9036} 循环输入需要兑换的外币代码和金额 例如hkd1000(可以是小写或大写代码) 显示转换后的人民币金额 人民币903.60(保留两位小数) 如果输入的外币代码错误或数字不对,给出相应的提示 循环输入,直到输入0为止
测试说明
平台会对你编写的代码进行测试:
测试输入: 请输入货币USK1000 预期输出: 外币代码错误
测试输入: HKD2UY 预期输出: 数字错误
测试输入: USD200 hkd300 eur500 0 预期输出: 人民币1353.58 人民币271.08 人民币3946.05
纸上得来终觉浅 绝知此事要躬行 开始你的任务吧,祝你成功!
f1=open("sy9//汇率兑换.txt","r",encoding="utf-8")
bzzd={}
#代码开始
for line in f1:
dh1=line.find("(")
dh2=line.find(")")
hl1=line.find("=")
hl2=line.find("人")
dh=line[dh1+1:dh2]
hl=eval(line[hl1+1:hl2])
bzzd[dh]=hl
x=input("")
while x!="0":
dh0=x[:3]
je=x[3:]
dhdx=str.upper(dh0)
if dhdx in bzzd and je.isdigit()==True:
rmb=eval(je)*bzzd.get(dhdx,0)
print("人民币{:.2f}".format(rmb))
if dhdx not in bzzd:
print("币种错误")
if je.isdigit()==False:
print("数字错误")
x=input("")
#代码结束
f1.close()任务描述
本关任务:编写一个计算购买饮品金额的小程序。
编程要求
nc.csv文件中存放某奶茶店的各饮品的编号、名称和价格如下所示

编写程序,首先显示所有饮品的序号、名称和价格。 循环输入饮品的编号和数量,直到输入编号为00。系统输出总计的金额。 若输入饮品的编号错误,系统会显示编码错误,但仍可继续输入。

测试说明
平台会对你编写的代码进行测试:
测试输入: 请选择饮品05 请输入数量1 请选择饮品09 请输入数量2 请选择饮品99 请选择饮品03 请输入数量2 输出 编码错误 应付80元
f1=open("sy9//nc.csv","r",encoding="utf8")
#代码开始
yp=[]
zd={}
for line in f1:
every=line.strip().split(",")
yp.append([every[0],every[1],eval(every[2])])
zd[every[0]]=eval(every[2])
for i in range(len(yp)):
print("编号{}饮品{}价格{}".format(yp[i][0],yp[i][1],yp[i][2]))
x=input("请选择饮品")
je=0
while x!="00":
if x in zd:
n=eval(input("请输入数量"))
je+=zd.get(x,0)*n
else:
print("编码错误")
x=input("请选择饮品")
#代码结束
print("应付{}元".format(je))任务描述
本关任务:编写一个能统计文档中词语词频小程序。 宋词文件如下所示:
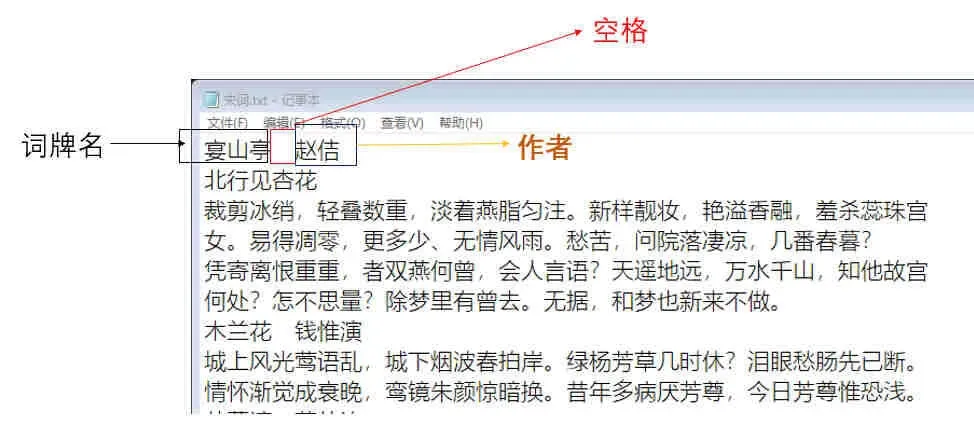
统计文件中词频最高的15个词语(除了词牌名和作者) 注意:标题行的空格是全角空格” ”(可复制此空格) 由于有一个词牌名为东风第一枝,需要将文件中的词牌名删除。(否则会多一个东风)
相关知识
为了完成本关任务,你需要掌握:jieba库分词
jieba库分词
jieba是Python中一个重要的第三方中文分词函数库 Jieba库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组。 jieba.lcut(s) 精确模式对字符串s分词,产生一个列表
测试说明
平台会对你编写的代码进行测试:
输出:

海纳百川有容乃大;壁立千仞无欲则刚。 开始你的任务吧,祝你成功!
import jieba
f1= open("sy9//宋词.txt", "r")
#代码开始
txt=f1.read()
txt=txt.replace("东风第一枝","")
words=jieba.lcut(txt)
jh=set()
f1.seek(0)
for line in f1:
line=line.strip()
if " " in line:
zz=line[line.find(" ")+1:]
cpm=line[:line.find(" ")]
jh.add(zz)
jh.add(cpm)
f1.close()
zd={}
for w in words:
if len(w)>=2 and w not in jh:
zd[w]=zd.get(w,0)+1
items=list(zd.items())
items.sort(key=lambda x:x[1],reverse=True)
#代码结束
for i in range(15):
print("{}{}".format(items[i][0],items[i][1]))任务描述
本关任务:根据宋词文件生成一个词云图片文件,存放在sy9文件夹的pict文件夹下的sc1.png 要求图片宽1000高700背景颜色白色最多300个词 注意:字体使用sy9文件夹下的simhei.ttf字体文件

相关知识
为了完成本关任务,你需要掌握:生成词云图片
生成词云图片
wordcloud库概述 wordcloud是python的一个三方库,称为词云也叫做文字云,是根据文本中的词频,对内容进行可视化的汇总. wordcloud.WordCloud(参数) font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上, 如:font_path = ‘sy9//simhei.ttf’ width : int (default=400) #输出的画布宽度,默认为400像素 height : int (default=200) #输出的画布高度,默认为200像素 background_color : color value (default=”black”) #背景颜色,如background_color=’white’,背景颜色为白色 max_words : number (default=200) #要显示的词的最大个数
不论你在什么时候开始,重要的是开始之后就不要停止。 开始你的任务吧,祝你成功!
import jieba
import wordcloud
f1= open("sy9//宋词.txt", "r")
#代码开始
txt=f1.read()
words=jieba.lcut(txt)
jh=set()
f1.seek(0)
for line in f1:
line=line.strip()
if " " in line:
zz=line[line.find(" ")+1:]
cpm=line[:line.find(" ")]
jh.add(zz)
jh.add(cpm)
f1.close()
lb=[]
for w in words:
if len(w)>=2 and w not in jh:
lb.append(w)
xtxt=",".join(lb)
w=wordcloud.WordCloud(font_path="sy9//simhei.ttf",width=1000,height=700,background_color="white",max_words=300)
w.generate(xtxt)
#代码结束
w.to_file("sy9//pict//sc1.png")文章出处登录后可见!