数据集和源码请点赞关注收藏后评论区留下QQ邮箱或者私信
线性回归是利用最小二乘函数对一个或多个因变量之间关系进行建模的一种回归分析,这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个变量的称为一元回归,大于一个变量的情况叫做多元回归。利用线性回归,我们可以预测一组特定数据是否在一定时期内增长或下降。
接下来以线性回归预测波士顿房价进行实战解析
线性回归代码如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 读数据
data = np.loadtxt(boston_house_price.csv', float, delimiter=",", skiprows=1)
X, y = data[:, :13], data[:, 13]
# Z-score归一化
for i in range(X.shape[1]):
X[:, i] = (X[:, i] - np.mean(X[:, i])) / np.std(X[:, i])
# 划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 将训练集、测试集改为列向量的形式
y_train = y_train.reshape((-1, 1))
y_test = y_test.reshape((-1, 1))
# 初始化模型参数
def initialize_params(feature_num):
w=np.random.rand(feature_num,1)
b=0
return w,b
def forward(X, y, w, b):
num_train=X.shape[0]
y_hat=np.dot(X,w)+b
loss=np.sum((y_hat-y)**2)/num_train
dw=np.dot(X.T,(y_hat-y))/num_train
db=np.sum((y_hat-y))/num_train
return y_hat,loss,dw,db
# 定义线性回归模型的训练过程
def my_linear_regression(X, y, learning_rate, epochs):
loss_his=[]
w,b=initialize_params(X.shape[1])
for i in range(epochs):
y_hat,loss,dw,db=forward(X,y,w,b)
w+=-learning_rate*dw
b+=-learning_rate*db
loss_his.append(loss)
if i%100==0:
print("epochs %d loss %f"%(i,loss))
return loss_his,w,b
# 线性回归模型训练
loss_his, w, b = my_linear_regression(X_train, y_train, 0.01, 5000)
# 打印loss曲线
plt.plot(range(len(loss_his)), loss_his, linewidth=1, linestyle="solid", label="train loss")
plt.show()
# 打印训练后得到的模型参数
print("w:", w, "\nb", b)
# 定义MSE函数
def MSE(y_test, y_pred):
return np.sum(np.square(y_pred - y_test)) / y_pred.shape[0]
# 定义R系数函数
def r2_score(y_test, y_pred):
# 测试集标签均值
y_avg = np.mean(y_test)
# 总离差平方和
ss_tot = np.sum((y_test - y_avg) ** 2)
# 残差平方和
ss_res = np.sum((y_test - y_pred) ** 2)
# R计算
r2 = 1 - (ss_res / ss_tot)
return r2
# 在测试集上预测
y_pred = np.dot(X_test, w) + b
# 计算测试集的MSE
print("测试集的MSE: {:.2f}".format(MSE(y_test, y_pred)))
# 计算测试集的R方系数
print("测试集的R2: {:.2f}".format(r2_score(y_test, y_pred)))损失值随训练次数的变化图如下 可以看出符合肘部方法
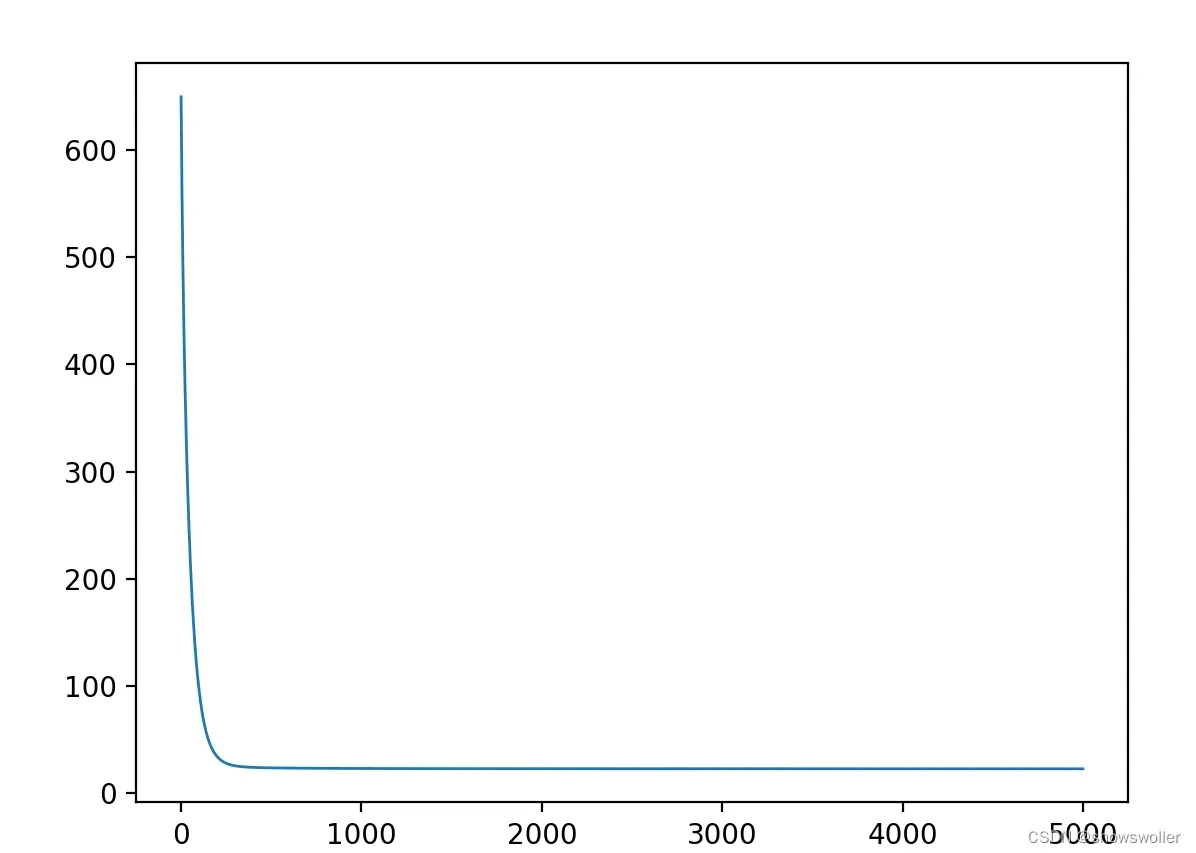
接下来可视化分析影响房价的因素
""" 各个字段的含义: CRIM 犯罪率 ZN 住宅用地所占比例 INDUS 城镇中非商业用地所占比例 CHAS 是否处于查尔斯河边 NOX 一氧化碳浓度 RM 住宅房间数 AGE 1940年以前建成的业主自住单位的占比 DIS 距离波士顿5个商业中心的加权平均距离 RAD 距离高速公路的便利指数 TAX 不动产权税 PTRATIO 学生/教师比例 B 黑人比例 LSTAT 低收入阶层占比 MEDV 房价中位数 """
可视化结果如下
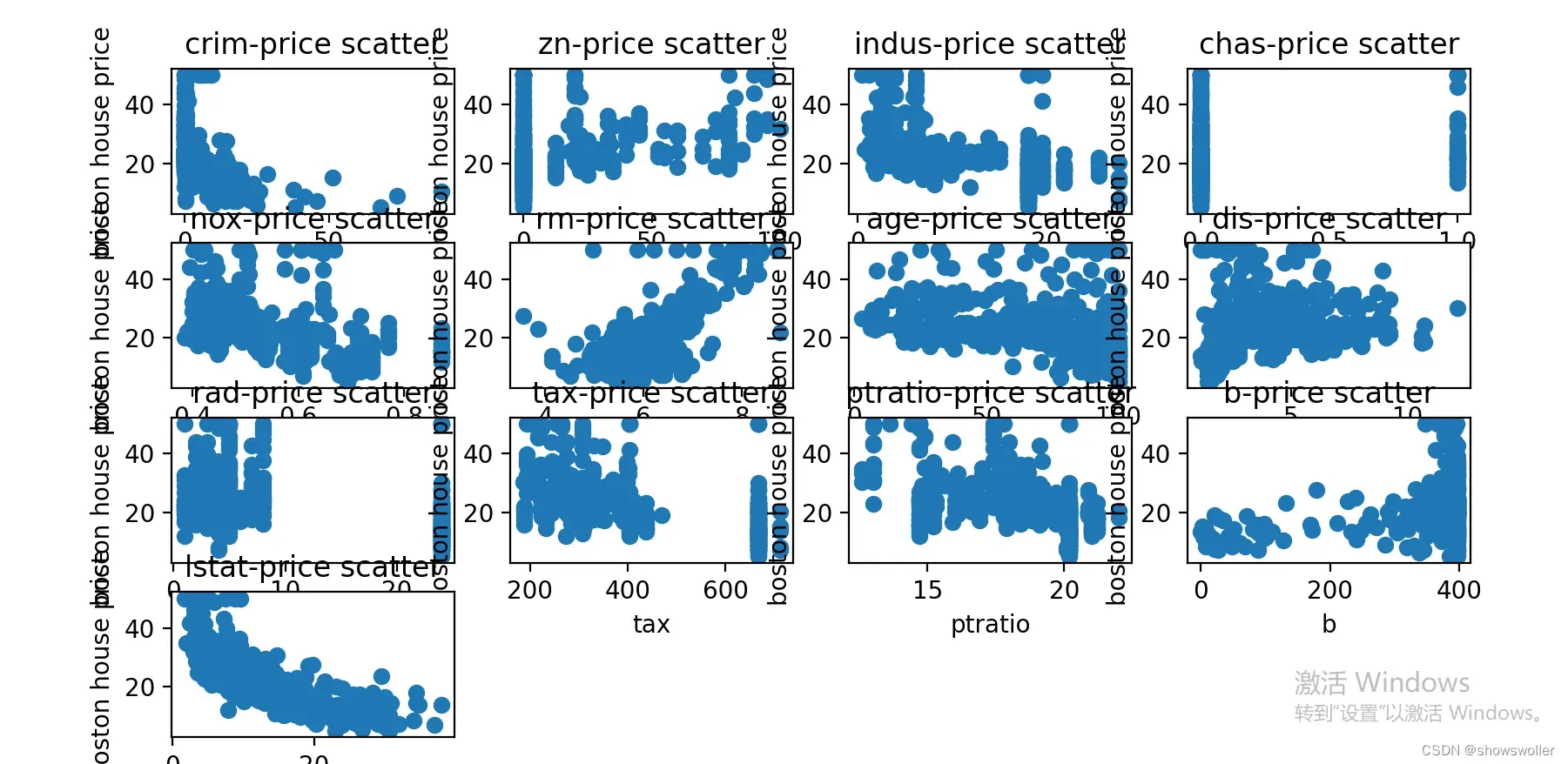
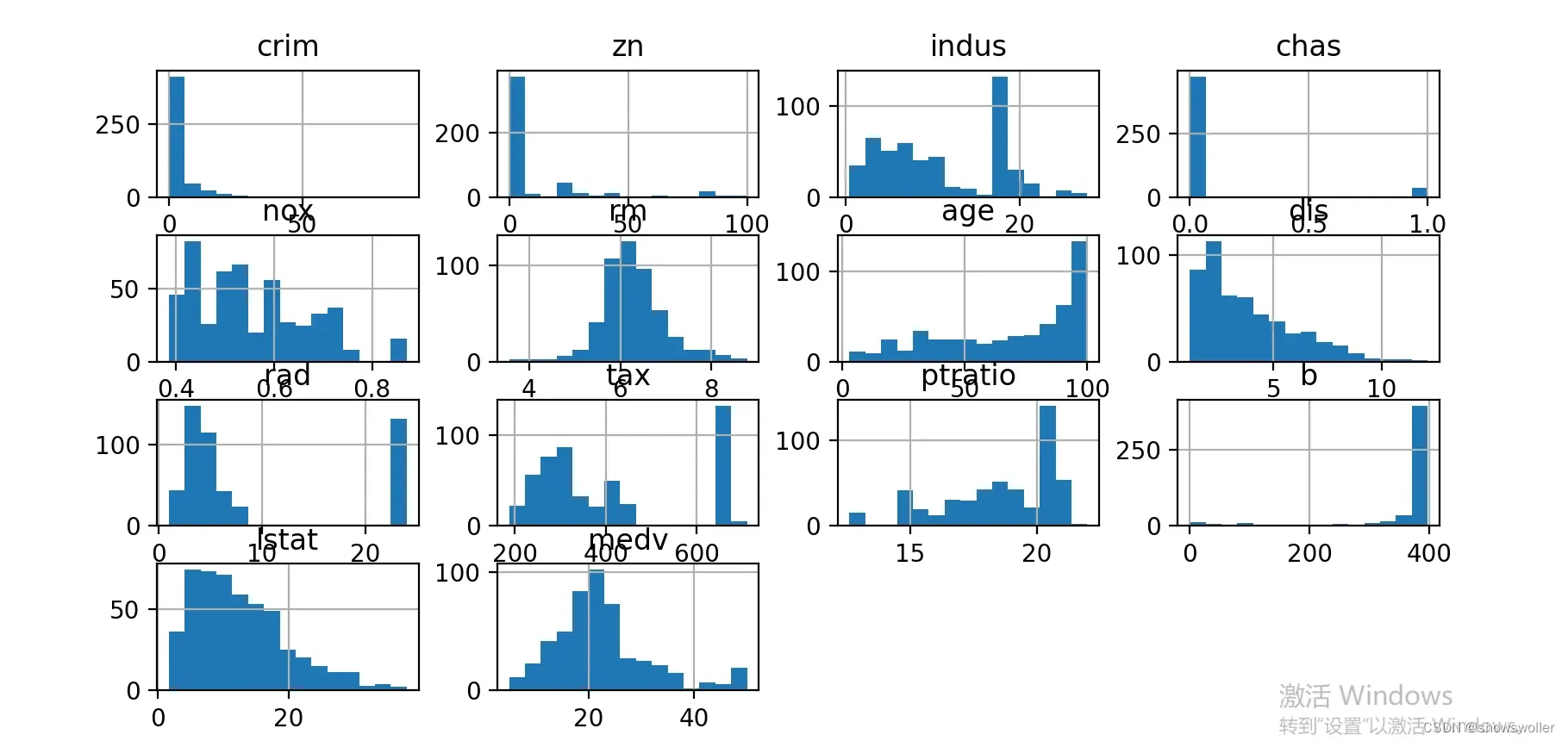
可视化部分代码如下
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv(boston_house_price.csv',encoding='utf-8')
print(df.head())
df.describe()
df['medv'].hist()
sns.boxplot(x=df['medv'])#有点问题 要加个x传参
plt.scatter(df['rm'],df['medv'])
def box_plot_outliers(df,s):
q1,q3=df[s].quantile(0.25),df[s].quantile(0.75)
iqr=q3-q1
low,up=q1-1.5*iqr,q3+1.5*iqr
df=df[(df[s]>up)|(df[s]<low)]
return df
df_filter=box_plot_outliers(df,'rm')
df_filter.mean()
plt.scatter(df['dis'],df['medv'])
plt.scatter(df['rad'],df['medv'])
plt.scatter(df['b'],df['medv'])
df.corr()
plt.style.use({'figure.figsize':(15,10)})
df.hist(bins=15)
sns.boxplot(data=df)
plt.figure(figsize=(12,22))
for i in range(13):
plt.subplot(4,4,(i+1))
plt.scatter(df.iloc[:,i],df['medv'])
plt.title('{}-price scatter'.format(df.columns[i]))
plt.xlabel(df.columns[i])
plt.ylabel('boston house price')
plt.show()
plt.tight_layout()数据集和源码请点赞关注收藏后评论区留下QQ邮箱或者私信
版权声明:本文为博主作者:showswoller原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/jiebaoshayebuhui/article/details/127500484