Matplotlib绘制图的常用类型
plot(x,y)
plot(x, y)函数用于绘制折线图。折线图是一种用来展示连续数据之间关系的图表类型,适用于表示数据随着一个或多个变量的变化而变化的情况。
具体来说,plot(x, y)函数接受两个参数:
x:表示X轴上的数据点的值,通常是一个数组或列表,表示自变量的取值。y:表示Y轴上的数据点的值,也是一个数组或列表,表示因变量随自变量变化的取值。
折线图会将这些数据点连接起来,形成一条或多条线,以展示数据的趋势或变化情况。以下是一些常见的折线图样式及其特点:
- 单条折线图:用于表示单一变量的变化趋势。可以通过添加数据标记点来强调关键数据点。
- 多条折线图:可以在同一张图上绘制多条折线,用于比较多个变量之间的趋势。每条折线可以使用不同的颜色或线型进行区分。
- 带标记点的折线图:通过在折线上添加标记点,可以更清晰地表示数据的取值,尤其在数据变化明显的位置。
- 平滑曲线折线图:使用平滑曲线(如样条曲线或平滑的多项式拟合曲线)来连接数据点,以平滑显示数据的变化趋势,避免过多的波动。
- 面积图折线图:可以通过在折线下方填充颜色,展示数据随时间的累积变化。常用于表示累积数据,如总收入或总销量。
- 双坐标轴折线图:在同一张图上绘制两条折线,分别使用左右两个不同的Y轴刻度,用于表示不同量纲或变化幅度较大的数据。
例如:
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('_mpl-gallery')
# 生成数据
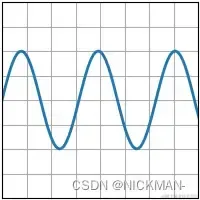
x = np.linspace(0, 10, 100)
y = 4 + 2 * np.sin(2 * x)
# plot
fig, ax = plt.subplots()
ax.plot(x, y, linewidth=2.0)
ax.set(xlim=(0, 8), xticks=np.arange(1, 8),
ylim=(0, 8), yticks=np.arange(1, 8))
plt.show()
scatter(x, y)
scatter(x, y)函数用于绘制散点图。散点图是一种用于展示两个变量之间关系的图表类型,每个数据点由两个数值(X轴和Y轴上的值)表示,以点的形式在图表上进行表示。
scatter(x, y)函数接受两个参数:
x:表示X轴上的数据点的值,通常是一个数组或列表,表示自变量的取值。y:表示Y轴上的数据点的值,也是一个数组或列表,表示因变量的取值。
散点图通过在坐标系中放置单个数据点来展示两个变量之间的关系。以下是一些散点图的特点和用途:
- 相关性检测:通过绘制散点图,可以观察两个变量之间的关系,判断它们之间是否存在线性相关性、正相关还是负相关。
- 分布情况:散点图可以用来展示数据的分布情况,特别是在两个维度上都有变化的情况下。
- 聚类分析:当数据点在图上聚集成群时,散点图可以帮助识别是否存在多个聚类或群集。
- 异常值识别:通过观察散点图,可以识别出位于数据集中的异常值或离群点。
- 多变量关系:散点图也可以用于展示多个变量之间的关系,通过使用不同的颜色、大小或形状来表示不同的变量。
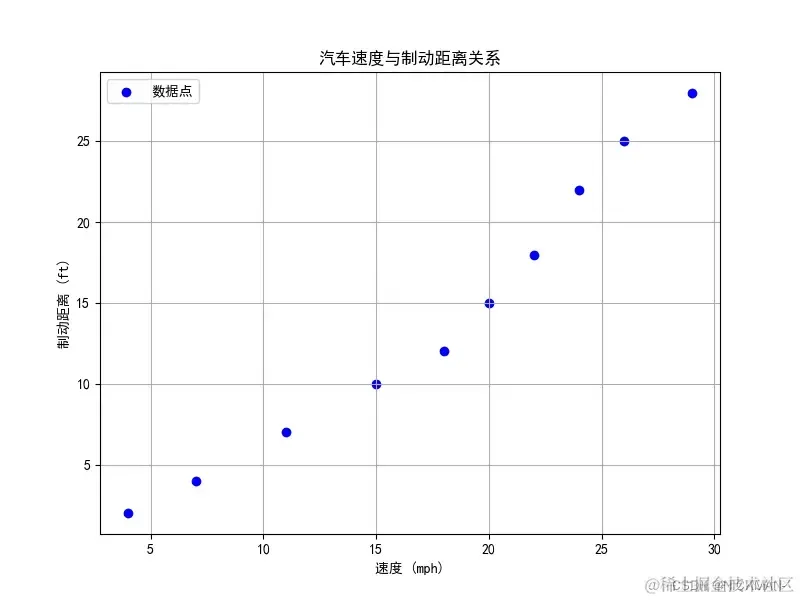
比如生成一个显示汽车速度与制动距离关系的散点图,其中每个数据点表示一个速度-制动距离的对应关系:
import matplotlib.pyplot as plt
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:汽车速度与制动距离的关系
speed = [4, 7, 11, 15, 18, 20, 22, 24, 26, 29]
brake_distance = [2, 4, 7, 10, 12, 15, 18, 22, 25, 28]
# 创建散点图
plt.figure(figsize=(8, 6)) # 设置图像大小
plt.scatter(speed, brake_distance, color='blue', marker='o', label='数据点') # 绘制散点图
plt.title('汽车速度与制动距离关系') # 添加标题
plt.xlabel('速度 (mph)') # 添加X轴标签
plt.ylabel('制动距离 (ft)') # 添加Y轴标签
plt.legend() # 显示图例
plt.grid(True) # 添加网格线
plt.show() # 显示图像
在使用scatter(x, y)函数时,还可以通过设置参数来定制散点图的外观,如点的大小、颜色、标记形状等,以便更好地传达数据的信息。
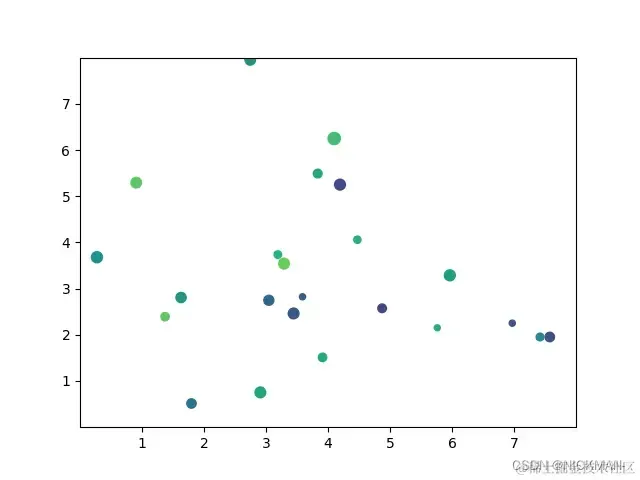
例如生成一个具有随机数据点、自定义样式和点大小、颜色的散点图:
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
np.random.seed(3)
x = 4 + np.random.normal(0, 2, 24) # 生成24个随机数,以4为中心,标准差为2
y = 4 + np.random.normal(0, 2, len(x)) # 生成与x相同数量的随机数,以4为中心,标准差为2
# 设置点的大小和颜色
sizes = np.random.uniform(15, 80, len(x)) # 生成在15和80之间的随机数作为点的大小
colors = np.random.uniform(15, 80, len(x)) # 生成在15和80之间的随机数作为颜色
# 绘制散点图
fig, ax = plt.subplots() # 创建一个图像和坐标轴的组合
ax.scatter(x, y, s=sizes, c=colors, vmin=0, vmax=100) # 绘制散点图,设置点的大小和颜色的范围
# 设置坐标轴范围和刻度
ax.set(xlim=(0, 8), xticks=np.arange(1, 8),
ylim=(0, 8), yticks=np.arange(1, 8))
plt.show() # 显示图像
bar(x, height)
bar(x, height)函数用于绘制条形图(柱状图)。条形图是一种常用的数据可视化方式,用于展示不同类别或组之间的比较。每个条形的高度表示与该类别或组相关联的数值。
bar(x, height)函数接受两个主要参数:
x:表示条形的位置,通常是一个数组或列表,表示每个条形的位置。height:表示每个条形的高度,也是一个数组或列表,表示每个条形的数值。
以下是一些关于bar(x, height)函数的特点和用途:
- 分类比较:条形图适用于对不同类别或组之间的数值进行比较。每个条形代表一个类别,其高度表示与该类别相关的数值。
- 单个数据集内的分布:可以使用条形图来展示单个数据集内不同类别的分布情况,比如一个时间段内不同产品的销售数量。
- 多组数据比较:通过在同一张图上绘制多组条形,可以方便地比较不同组的数据,以查看它们之间的差异。
- 标记数据点:可以在每个条形上方添加数值标签,以明确显示每个类别对应的具体数值。
- 堆叠条形图:通过在同一位置堆叠多个条形,可以展示多个维度的数据,同时呈现每个类别内部的分布。
- 分组条形图:将每个类别内的不同组的条形并列显示,便于比较不同组之间的数值。
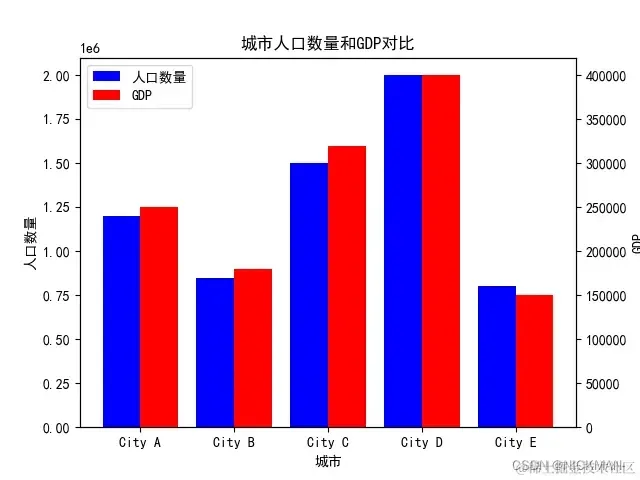
例如创建一个条形图用于比较不同城市的人口数量和GDP:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:不同城市的人口数量和GDP
cities = ['City A', 'City B', 'City C', 'City D', 'City E']
population = [1200000, 850000, 1500000, 2000000, 800000]
gdp = [250000, 180000, 320000, 400000, 150000]
# 设置条形图的位置
x_positions = np.arange(len(cities))
# 创建条形图
fig, ax1 = plt.subplots()
# 绘制人口数量的条形
ax1.bar(x_positions - 0.2, population, width=0.4, align='center', color='b', label='人口数量')
# 创建第二个坐标轴以显示GDP数据
ax2 = ax1.twinx()
ax2.bar(x_positions + 0.2, gdp, width=0.4, align='center', color='r', label='GDP')
# 设置图例和标签
ax1.set_xticks(x_positions)
ax1.set_xticklabels(cities)
ax1.set_xlabel('城市')
ax1.set_ylabel('人口数量')
ax2.set_ylabel('GDP')
# 合并图例
lines, labels = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines + lines2, labels + labels2, loc='upper left')
plt.title('城市人口数量和GDP对比')
plt.show()
每个城市在图中由两个相邻的条形表示,左侧的蓝色条形代表人口数量,右侧的红色条形代表GDP。通过双坐标轴的设计,使得两种数据可以在同一图中进行比较,而X轴上的城市名称使得每个条形与相应城市相关联。这个例子演示了如何处理具有多个数据集和双坐标轴的情况。
stem(x,y)
stem(x, y)函数用于绘制茎叶图(stem plot),也称为蒂叶图。茎叶图是一种用于可视化数据分布和变化的图表类型,特别适用于展示数据的离散值以及它们的频率分布。
stem(x, y)函数接受两个参数:
x:表示X轴上的数据点的值,通常是一个数组或列表,表示数据点的位置。y:表示Y轴上的数据点的值,也是一个数组或列表,表示数据点的取值。
茎叶图的绘制方式是:对每个数据点,将其拆分为茎(高位部分)和叶(个位部分),然后在图表上绘制一个垂直线(茎)和水平线(叶),以表示数据的分布。
茎叶图的特点和用途:
- 数据展示:茎叶图可用于展示离散数据的取值情况,更能突显数据的分布。
- 频率分布:通过茎叶图,可以直观地查看数据的频率分布,有助于发现数据的模式和趋势。
- 离群值识别:茎叶图可以帮助识别离群值,这些值可能在图表上单独突出显示。
- 数据比较:通过绘制多个数据集的茎叶图,可以方便地比较它们之间的分布。
例如:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:随机生成一组数据
data = np.array([21, 35, 22, 18, 26, 39, 29, 28, 23, 35])
# 创建茎叶图
plt.stem(data)
# 添加标题和标签
plt.title('茎叶图示例')
plt.xlabel('数据索引')
plt.ylabel('数据值')
plt.show()
step(x,y)
step(x, y)函数用于绘制阶梯图(step plot),也被称为阶梯线图或台阶图。阶梯图是一种用于可视化离散数据的图表类型,其特点是数据点之间通过垂直和水平线段连接,而不是平滑的曲线。
step(x, y)函数接受两个参数:
x:表示X轴上的数据点的值,通常是一个数组或列表,表示自变量的取值。y:表示Y轴上的数据点的值,也是一个数组或列表,表示因变量的取值。
阶梯图的绘制方式是:对每个数据点,将其前一个数据点的X值作为起点,当前数据点的Y值作为终点,连接这两个点。这样,就可以形成一系列水平线段和垂直线段。
阶梯图的特点和用途:
- 数据展示:阶梯图适用于展示离散数据点之间的变化趋势,尤其适用于时间序列数据。
- 数据步进:通过阶梯图,可以更清晰地表示数据从一个离散点到另一个离散点的变化。
- 模拟变化:阶梯图可用于模拟连续变量在离散时间或事件点上的变化,如模拟某个值在不同时间段内的变化。
例如:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:模拟温度变化
time = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
temperature = np.array([20, 22, 24, 25, 23, 22, 21, 20, 19, 18])
# 创建阶梯图
plt.step(time, temperature, where='mid')
# 添加标题和标签
plt.title('温度变化阶梯图')
plt.xlabel('时间')
plt.ylabel('温度 (°C)')
plt.show()
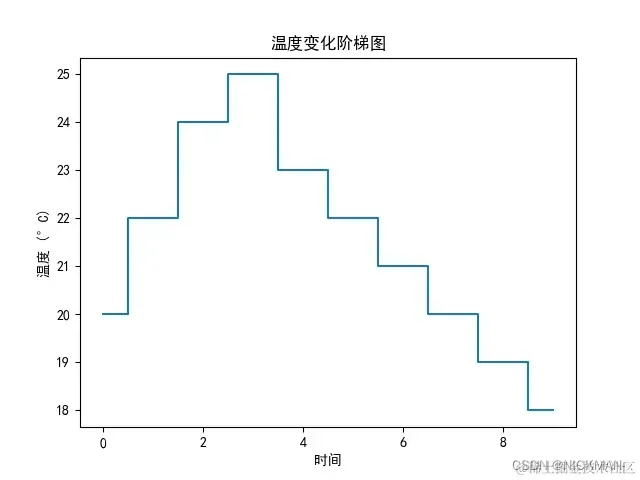
在这个示例图中,time数组表示时间点,temperature数组表示相应时间点的温度。通过plt.step(time, temperature, where='mid')语句,我们绘制了这些温度变化的阶梯图。where='mid'参数指定了线段连接到每个数据点的中间位置。其他部分用于添加标题和标签,最后使用plt.show()显示图像。这个示例演示了如何使用step(x, y)函数绘制阶梯图,以展示离散数据的变化趋势。
fill_between(x, y1, y2)
fill_between(x, y1, y2)函数用于在两个Y轴数据序列之间填充颜色,通常用于表示两个数据序列之间的区域或范围。这个函数可以用于创建各种图表,如误差范围图、置信区间图等。
fill_between(x, y1, y2)函数接受三个参数:
x:表示X轴上的数据点的值,通常是一个数组或列表,表示自变量的取值。y1:表示Y轴上的数据点的值,也是一个数组或列表,表示第一个数据序列的取值。y2:表示Y轴上的数据点的值,也是一个数组或列表,表示第二个数据序列的取值。
fill_between函数会在y1和y2之间的区域填充颜色,从而突出两个数据序列之间的差异或范围。
fill_between函数的特点和用途:
- 数据区间表示:
fill_between函数非常适用于展示数据序列之间的区间、范围或误差。 - 误差范围图:通过填充两个数据序列之间的区域,可以展示测量值的误差范围,帮助理解数据的不确定性。
- 置信区间图:可以使用
fill_between来显示置信区间,即表达数据的预测范围。
在下面这个股票价格波动图的例子中,fill_between函数的目的是用于将股票价格的上限和下限之间的区域填充颜色,以突出价格的波动范围:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:股票价格走势和价格波动范围
days = np.arange(1, 11)
stock_prices = [100, 105, 110, 108, 112, 115, 120, 118, 125, 123]
price_range = [4, 3, 5, 3, 4, 3, 4, 3, 5, 4]
# 创建股票价格波动图
plt.plot(days, stock_prices, color='b', marker='o', label='股票价格')
plt.fill_between(days, np.subtract(stock_prices, price_range), np.add(stock_prices, price_range), color='lightblue', alpha=0.3, label='价格波动范围')
# 添加标题和标签
plt.title('股票价格走势和价格波动范围')
plt.xlabel('天数')
plt.ylabel('价格')
plt.legend()
plt.show()
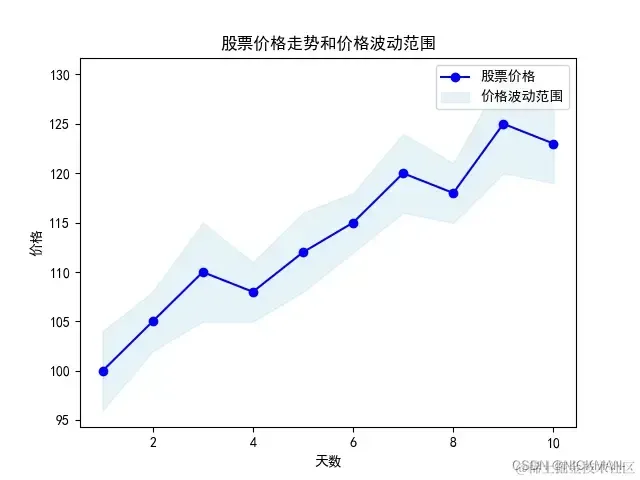
首先,我们有每天的股票价格数据列表 stock_prices,以及每天的价格波动范围列表 price_range。对于每一天,我们通过从相应的 stock_prices 中减去 price_range 来计算下限值,通过加上 price_range 来计算上限值。这样,我们获得了每天股票价格的下限和上限。
然后,使用 plt.fill_between() 函数,我们将这些下限和上限之间的区域进行填充。fill_between 函数的第一个参数是 X 轴的数据,这里是 days,第二个参数是 Y 轴的下限,第三个参数是 Y 轴的上限。这使得函数知道在哪个范围内填充颜色。
stackplot(x, y)
stackplot(x, y)函数用于绘制堆叠区域图(stacked area plot),也称为堆积面积图。堆叠区域图适用于展示多个数据序列在相同X轴上的分布情况,并突出不同数据序列的累积贡献。
stackplot(x, y)函数接受两个参数:
x:表示X轴上的数据点的值,通常是一个数组或列表,表示自变量的取值。y:一个列表(或多维数组)的列表,表示每个数据序列在各个X值上的高度。多个数据序列将在图表上堆叠显示。
堆叠区域图的绘制方式是:从下到上,按照给定的数据序列顺序,将每个数据序列的高度在X轴上进行累积叠加。
堆叠区域图的特点和用途:
- 多个序列比较:堆叠区域图适用于比较多个数据序列之间的分布,可以突出每个数据序列的相对贡献。
- 部分与整体关系:可以用于展示每个部分对于整体的贡献,例如市场份额、不同产品的销售构成等。
- 分布变化:通过展示堆叠的区域,可以清楚地看到各个数据序列在不同X值上的分布变化。
例如:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:不同年龄段的人口构成
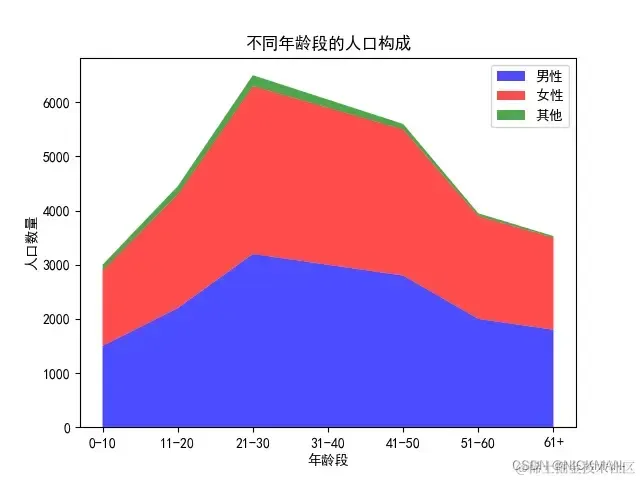
age_groups = ['0-10', '11-20', '21-30', '31-40', '41-50', '51-60', '61+']
male_population = [1500, 2200, 3200, 3000, 2800, 2000, 1800]
female_population = [1400, 2100, 3100, 2900, 2700, 1900, 1700]
other_population = [100, 150, 200, 150, 100, 50, 30]
# 创建人口构成堆叠区域图
plt.stackplot(age_groups, male_population, female_population, other_population,
labels=['男性', '女性', '其他'], colors=['b', 'r', 'g'], alpha=0.7)
# 添加标题和标签
plt.title('不同年龄段的人口构成')
plt.xlabel('年龄段')
plt.ylabel('人口数量')
plt.legend(loc='upper right')
plt.show()
在这个示例中使用plt.stackplot()函数绘制了人口构成的堆叠区域图,每个数据序列在X轴上叠加显示,通过labels参数添加图例标签,colors参数设置不同颜色,alpha参数设置填充颜色的透明度,以突出不同年龄段的人口构成情况。通过比较不同性别和其他人口在不同年龄段的分布,可以更好地了解人口构成的特点和变化趋势。
imshow(Z)
imshow(Z)函数用于显示一个二维数组(或矩阵)Z,将其表示为彩色或灰度图像。这个函数常用于图像处理、数据可视化、热图等应用场景。
imshow(Z)函数接受一个参数:
Z:一个二维数组,表示图像的像素值或数据矩阵。它可以是灰度图像、彩色图像的某个通道,或者表示其他数据的矩阵。
imshow函数的特点和用途:
- 图像显示:
imshow函数可用于将二维数组显示为图像,通过不同的像素值映射到不同的颜色,形成可视化结果。 - 热图:当
Z是一个数据矩阵时,imshow函数可以用于绘制热图,通过不同的数据值映射到不同的颜色,帮助显示数据的分布情况。 - 图像处理:在图像处理中,可以使用
imshow来显示图像的各种处理结果,如滤波、边缘检测等。
以绘制热图(heatmap)为例。热图常用于显示矩阵数据的分布情况,其中矩阵的每个元素通过颜色来表示其值的大小:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:矩阵数据表示数据强度
matrix_data = np.random.random((10, 10)) # 10x10的随机矩阵数据
# 显示热图
plt.imshow(matrix_data, cmap='hot', origin='upper')
# 添加颜色条
plt.colorbar()
# 添加标题和标签
plt.title('数据强度热图')
plt.xlabel('列')
plt.ylabel('行')
plt.show()
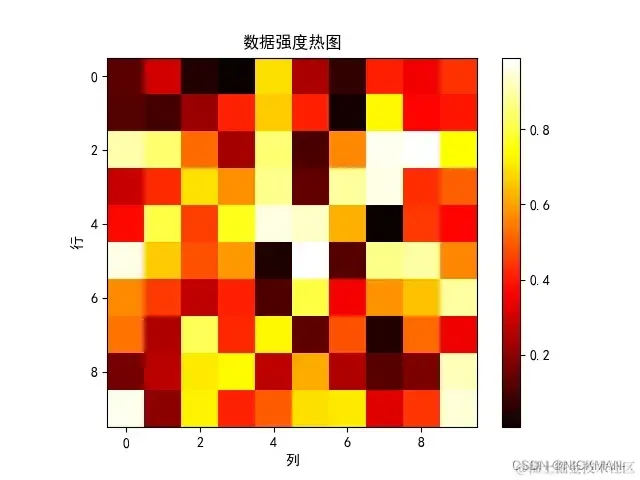
对于这个示例,matrix_data是一个随机生成的10×10矩阵,表示不同位置的数据强度。通过使用imshow(matrix_data, cmap='hot', origin='upper'),将矩阵数据绘制成了一个热图,其中不同颜色表示不同的数据强度。cmap参数指定了使用热色彩映射,origin参数指定了坐标原点在图像的上方。
hist(x)
hist(x)函数用于绘制直方图,用于展示数据的分布情况,特别是连续型数据的频率分布。直方图将数据范围划分为多个区间(称为“箱子”或“bin”),然后统计每个区间中数据的数量或频率。
hist(x)函数接受一个参数:
x:一个一维数组或列表,表示要绘制直方图的数据。
hist函数的特点和用途:
- 数据分布可视化:
hist函数可以将数据的分布情况以直观的方式展示出来,帮助了解数据的中心趋势、离散程度以及异常值等。 - 频率分布:通过将数据分成多个区间,
hist函数可以显示每个区间内数据的频率,帮助你分析数据在不同值范围内的密度。 - 分析分布形状:直方图的形状可以提供关于数据分布是否对称、偏斜或多峰等信息。
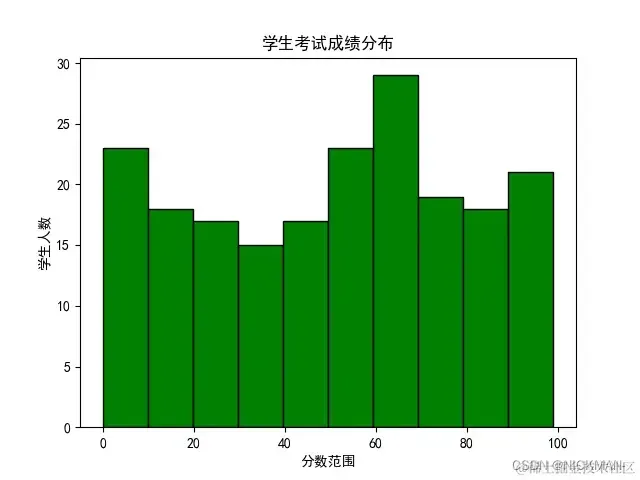
例如分析学生考试成绩分布情况:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:学生考试成绩
exam_scores = np.random.randint(0, 100, 200) # 随机生成200个考试成绩
# 绘制直方图
plt.hist(exam_scores, bins=10, color='green', edgecolor='black')
# 添加标题和标签
plt.title('学生考试成绩分布')
plt.xlabel('分数范围')
plt.ylabel('学生人数')
plt.show()
使用plt.hist(exam_scores, bins=10, color='green', edgecolor='black')函数绘制了直方图,bins参数指定了要使用的区间数量,color参数设置了柱子的填充颜色,edgecolor参数设置了柱子的边框颜色。
pie(x)
pie(x)函数用于绘制饼图(pie chart),用于显示数据的相对比例。饼图通过将数据按照不同的比例分成扇形,以表示各个部分在整体中的贡献。饼图常用于展示分类数据的分布情况。
pie(x)函数接受一个参数:
x:一个包含各个部分比例的一维数组或列表,表示要绘制饼图的数据。
pie函数的特点和用途:
- 数据比例:
pie函数适用于展示不同部分在整体中的比例关系,特别是当你关注数据的相对贡献时。 - 数据分类:饼图可以用于展示数据的分类,各个扇形区域表示不同的数据类别。
- 直观显示:饼图提供了一种直观的方式来显示相对比例,使观察者能够迅速理解数据的分布情况。
比如需要进行能源分析,了解一个城市的不同能源类型在总能源供应中的比例,以及不同能源对环境的影响:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 示例数据:城市能源供应结构比例
energy_sources = ['煤炭', '石油', '天然气', '核能', '可再生能源']
proportions = [30, 25, 20, 10, 15] # 各个能源的供应比例
# 绘制饼图
plt.pie(proportions, labels=energy_sources, autopct='%1.1f%%', startangle=140, colors=['gray', 'pink', 'blue', 'green', 'orange'])
# 添加标题
plt.title('城市能源供应结构')
plt.axis('equal') # 使饼图保持圆形
plt.show()
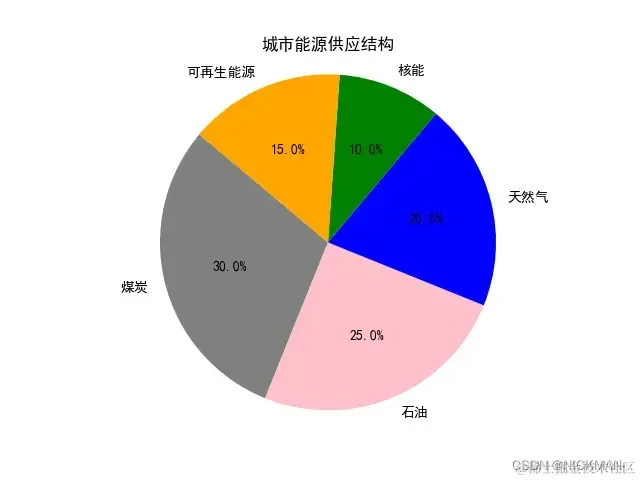
在上图中,使用plt.pie(proportions, labels=energy_sources, autopct='%1.1f%%', startangle=140, colors=['gray', 'black', 'blue', 'green', 'orange'])函数绘制了饼图,labels参数指定了每个扇形的标签,autopct参数设置了百分比显示格式,startangle参数设置了饼图的起始角度,colors参数设置了每个扇形的颜色。
contour(X, Y, Z)和contourf(X, Y, Z)
contour(X, Y, Z)和contourf(X, Y, Z)函数用于绘制等高线图(contour plot)和填充等高线图(filled contour plot),用于表示二维数据的等高线分布。等高线图在可视化数据表面的高度或数值分布时非常有用。
这两个函数的参数如下:
X和Y:表示二维数据的网格点坐标,通常是由numpy.meshgrid函数生成的两个二维数组。Z:一个与X和Y对应的二维数组,表示要绘制等高线的数据值。
contour(X, Y, Z)函数的特点和用途:
- 数据轮廓:
contour函数用于绘制等高线图,其中等高线表示数据表面上的高度或数值分布。 - 轮廓线:绘制的等高线通过线条表示不同数据值的轮廓,颜色通常相同。
- 数据分布:等高线图能够清晰地展示数据在二维空间中的分布情况,特别适用于显示地形高度、温度分布等数据。
contourf(X, Y, Z)函数的特点和用途:
- 填充区域:
contourf函数用于绘制填充等高线图,其中不同等高线之间的区域被填充颜色,以突出数据值的分布。 - 颜色映射:填充区域的颜色根据数据值的大小来映射,可以通过
cmap参数指定颜色映射。 - 数据分布:填充等高线图可以更直观地显示数据值在不同区域的分布,特别适用于表示温度、浓度等数据。
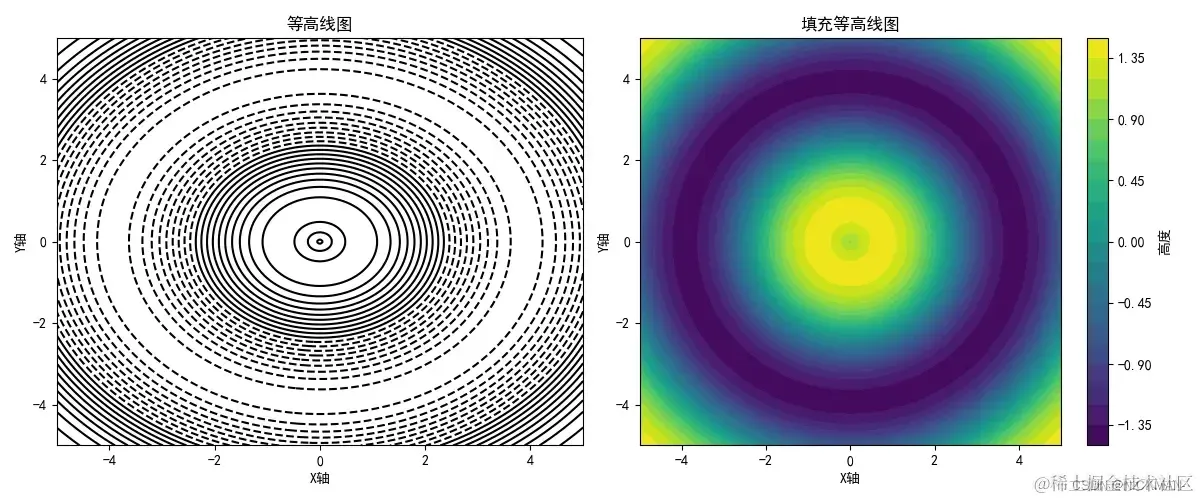
假设想要绘制一个地区的地形高度分布图,包括等高线图和填充等高线图,以便更好地理解地势起伏情况:
import matplotlib.pyplot as plt
import numpy as np
# 设置全局字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定微软雅黑或其他中文字体
# 设置负号为标准的减号
plt.rcParams['axes.unicode_minus'] = False
# 创建网格点坐标
x = np.linspace(-5, 5, 300)
y = np.linspace(-5, 5, 300)
X, Y = np.meshgrid(x, y)
# 示例数据:地形高度
Z = np.sin(np.sqrt(X**2 + Y**2)) + np.cos(np.sqrt(X**2 + Y**2))
# 创建绘图区域
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 绘制等高线图
contour1 = ax1.contour(X, Y, Z, levels=20, colors='black')
ax1.set_title('等高线图')
ax1.set_xlabel('X轴')
ax1.set_ylabel('Y轴')
# 绘制填充等高线图
contourf = ax2.contourf(X, Y, Z, levels=20, cmap='viridis')
ax2.set_title('填充等高线图')
ax2.set_xlabel('X轴')
ax2.set_ylabel('Y轴')
# 添加颜色条
cbar = plt.colorbar(contourf, ax=ax2)
cbar.set_label('高度')
plt.tight_layout()
plt.show()
注意,以上只是一些基本的Matplotlib所能绘制的图形类型,它还可以与很多其他库结合使用,绘制更多更加复杂的图形。
题外话
感谢你能看到最后,给大家准备了一些福利!
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python兼职渠道推荐*
学的同时助你创收,每天花1-2小时兼职,轻松稿定生活费.
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除
版权声明:本文为博主作者:Python_P叔原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Saki_Python/article/details/135102624