文章目录
- Pandas文本数据处理技术指南
-
- 引言
- 1. 查找文本数据
- 2. 替换文本数据
- 3. 拼接文本数据
- 4. 正则表达式操作
- 5. 虚拟变量
- 6. 处理缺失值
- 7. 分割文本数据
- 8. 字符串处理方法
- 9. 文本数据的合并与连接
- 10. 文本数据的排序
- 11. 文本数据的统计分析
- 12. 文本数据的分组与聚合
- 13. 文本数据的自定义函数应用
- 14. 文本数据的时间序列分析
- 心得
- 总结
Pandas文本数据处理技术指南
引言
在数据分析和机器学习领域,文本数据处理是一个至关重要的步骤。Pandas库作为Python中最常用的数据处理库之一,提供了丰富的文本数据处理方法。本文将深入探讨Pandas中文本数据处理的几个关键方向:查找、替换、拼接、正则表达式和虚拟变量。通过详细的代码实例和解析,帮助读者更好地理解和应用这些技术。

1. 查找文本数据
在处理文本数据时,查找特定的文本片段是常见的需求。Pandas提供了str.contains()方法来实现文本查找。下面是一个简单的例子:
import pandas as pd
# 创建一个包含文本数据的DataFrame
data = {'text': ['apple', 'banana', 'orange', 'grape']}
df = pd.DataFrame(data)
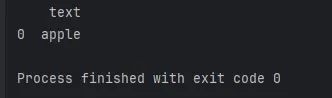
# 查找包含 'apple' 的行
result = df[df['text'].str.contains('apple')]
print(result)
这段代码将输出包含 ‘apple’ 的行。通过灵活使用str.contains(),可以根据实际需求找到所需的文本数据。
2. 替换文本数据
替换文本数据是清理和标准化数据的一部分。Pandas中的str.replace()方法提供了强大的替换功能。以下是一个简单的例子:
# 替换 'apple' 为 'pear'
df['text'] = df['text'].str.replace('apple', 'pear')
print(df)
这段代码将替换DataFrame中的文本数据,将 ‘apple’ 替换为 ‘pear’。
3. 拼接文本数据
有时候,我们需要将多个文本列合并成一个。Pandas中的str.cat()方法可以实现文本拼接。以下是一个示例:
# 创建两个包含文本数据的列
df['color'] = ['red', 'yellow', 'orange', 'purple']
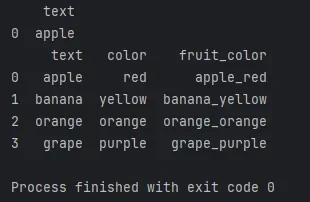
# 将 'text' 和 'color' 列拼接成一个新列 'fruit_color'
df['fruit_color'] = df['text'].str.cat(df['color'], sep='_')
print(df)
这段代码将创建一个新列 ‘fruit_color’,将 ‘text’ 和 ‘color’ 列的值以下划线分隔拼接在一起。
4. 正则表达式操作
正则表达式是处理复杂文本模式的强大工具。在Pandas中,str.extract()方法可以根据正则表达式提取特定模式的文本。以下是一个简单的示例:
# 提取文本中的数字
df['numbers'] = df['text'].str.extract('(\d+)')
print(df)
这段代码将提取 ‘text’ 列中的数字,并将其存储在新列 ‘numbers’ 中。
5. 虚拟变量
虚拟变量通常用于将分类数据转换为机器学习模型可用的形式。Pandas中的get_dummies()方法可以实现虚拟变量的创建。以下是一个例子:
# 创建虚拟变量
df_dummies = pd.get_dummies(df['color'], prefix='color')
# 将虚拟变量合并到原始DataFrame
df = pd.concat([df, df_dummies], axis=1)
print(df)
这段代码将创建一个新的DataFrame,其中包含原始数据列 ‘color’ 的虚拟变量。
6. 处理缺失值
在文本数据处理中,我们常常会遇到包含缺失值的情况。Pandas中的str.replace()方法可以用于处理文本数据中的缺失值,例如将缺失值替换为特定的默认值:
# 将缺失值替换为 'unknown'
df['text'] = df['text'].str.replace(r'^\s*$', 'unknown', regex=True)
print(df)
这段代码将使用正则表达式替换空白字符(包括空字符串)为 ‘unknown’。
7. 分割文本数据
有时,我们需要将包含多个元素的文本数据进行分割。Pandas中的str.split()方法可以实现文本数据的分割。以下是一个示例:
# 分割 'text' 列中的单词,并创建新的列 'word_list'
df['word_list'] = df['text'].str.split()
print(df)
这段代码将创建一个新列 ‘word_list’,其中包含 ‘text’ 列中每个单词组成的列表。
8. 字符串处理方法
Pandas提供了丰富的字符串处理方法,如str.upper()、str.lower()、str.strip()等,用于处理字符串的大小写、空格等。以下是一个示例:
# 将 'text' 列中的文本转换为大写
df['text_upper'] = df['text'].str.upper()
print(df)
这段代码将创建一个新列 ‘text_upper’,其中包含 ‘text’ 列中文本的大写版本。
9. 文本数据的合并与连接
在实际的数据处理中,有时我们需要将不同来源或格式的文本数据进行合并和连接。Pandas中的str.cat()方法是一种简便的合并文本数据的方式。以下是一个例子:
# 创建两个包含文本数据的Series
series1 = pd.Series(['apple', 'banana', 'orange'], name='fruits')
series2 = pd.Series(['red', 'yellow', 'orange'], name='colors')
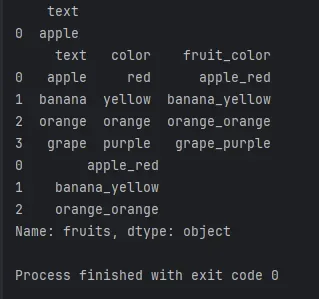
# 使用str.cat()合并两个Series
result_series = series1.str.cat(series2, sep='_')
print(result_series)
这段代码将创建一个新的Series,将两个原始Series的元素以下划线分隔合并在一起。
10. 文本数据的排序
排序对于理解和分析文本数据非常重要。Pandas中的sort_values()方法可以用于按照文本数据的字母顺序进行排序。以下是一个简单的例子:
# 按照 'text' 列的字母顺序升序排序
df_sorted = df.sort_values(by='text')
print(df_sorted)
这段代码将按照 ‘text’ 列的字母顺序对DataFrame进行升序排序。
11. 文本数据的统计分析
在处理文本数据时,经常需要对文本进行统计分析,例如计算每个单词出现的频率。Pandas中的value_counts()方法可以用于统计唯一值的频率。以下是一个示例:
# 计算 'text' 列中每个单词的频率
word_counts = df['text'].str.split(expand=True).stack().value_counts()
print(word_counts)
这段代码将统计 ‘text’ 列中每个单词的频率,并以Series形式输出。
12. 文本数据的分组与聚合
在处理大规模文本数据时,分组和聚合是必不可少的步骤。Pandas中的groupby()和agg()方法可以用于对文本数据进行分组和聚合。以下是一个例子:
# 创建一个包含文本数据的DataFrame
data = {'category': ['fruit', 'fruit', 'vegetable', 'fruit', 'vegetable'],
'text': ['apple', 'banana', 'carrot', 'orange', 'cucumber']}
df = pd.DataFrame(data)
# 按照 'category' 列进行分组,并统计每个类别下的文本数量
grouped_df = df.groupby('category')['text'].agg(['count', 'unique'])
print(grouped_df)
这段代码将按照 ‘category’ 列进行分组,并统计每个类别下的文本数量以及唯一的文本列表。
13. 文本数据的自定义函数应用
有时,我们需要应用自定义函数来处理文本数据。Pandas中的apply()方法可以用于对文本数据应用自定义函数。以下是一个简单的例子:
# 创建一个自定义函数,将文本转换为大写并加上感叹号
def custom_function(text):
return text.upper() + '!'
# 应用自定义函数到 'text' 列
df['text_processed'] = df['text'].apply(custom_function)
print(df)
这段代码将创建一个新列 ‘text_processed’,其中包含 ‘text’ 列中文本经过自定义函数处理后的结果。
14. 文本数据的时间序列分析
如果文本数据包含时间信息,我们可以进行时间序列分析。Pandas中的to_datetime()方法和resample()方法可以用于处理时间序列数据。以下是一个简单的例子:
# 创建包含时间信息的DataFrame
date_data = {'date': ['2022-01-01', '2022-01-02', '2022-01-03'],
'text': ['apple', 'banana', 'orange']}
df_time = pd.DataFrame(date_data)
# 将 'date' 列转换为时间格式
df_time['date'] = pd.to_datetime(df_time['date'])
# 将 'date' 列设置为索引,然后按照月份进行聚合
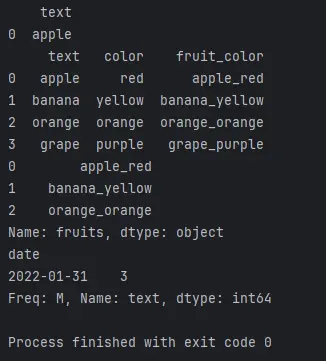
df_time = df_time.set_index('date')
monthly_counts = df_time.resample('M')['text'].count()
print(monthly_counts)
这段代码将按照月份对时间序列数据进行聚合,统计每月文本数据的数量。
心得
通过深入学习Pandas库在文本数据处理方面的各项技术,我对如何更有效地处理和分析文本数据有了更深刻的理解。以下是我在学习过程中得出的一些心得体会:
-
工具的威力: Pandas作为Python中强大的数据处理工具,提供了丰富而灵活的文本数据处理方法。深入了解这些方法,能够使数据处理任务更加高效、简便。
-
多方向技术的综合运用: 文本数据处理不是一成不变的,不同的任务和数据情境需要不同的处理方法。通过掌握查找、替换、拼接、正则表达式、虚拟变量等多方向的技术,我可以更灵活地应对各种文本数据处理的挑战。
-
数据清洗的重要性: 处理缺失值、替换异常值、分割文本数据等清洗步骤是确保数据质量的关键。在这一过程中,我学到了保持数据一致性和完整性的重要性。
-
个性化处理的实现: 通过自定义函数的应用,我可以对文本数据进行个性化处理,满足特定需求。这种灵活性是Pandas库在文本数据处理中的一大优势。
-
时间序列分析的应用: 学会使用Pandas进行时间序列分析,我能够更好地理解和利用包含时间信息的文本数据,对数据趋势和周期性有更深入的洞察。
-
统计分析与可视化: 利用
value_counts()等统计方法,我能够更直观地了解文本数据的分布情况,结合可视化工具,提高对数据的洞察力。
通过不断实践和应用这些技术,我逐渐感受到自己在文本数据处理方面的进步。这些技能不仅对于数据分析师和科学家们在处理实际工作中的数据具有重要意义,同时也为机器学习任务提供了强有力的数据准备工具。我将继续深入学习和实践,不断提升在文本数据处理领域的能力。
总结
本文深入探讨了Pandas库在文本数据处理方面的多项技术,旨在帮助读者更好地理解和应用这些功能。以下是本文主要内容的总结:
-
查找文本数据: 使用
str.contains()方法可以方便地查找包含特定文本片段的行,提高数据筛选的效率。 -
替换文本数据: 利用
str.replace()方法可以对文本数据进行替换,清理和标准化数据。 -
拼接文本数据: 通过
str.cat()方法可以将多个文本列合并成一个,灵活应对不同数据的拼接需求。 -
正则表达式操作: 使用
str.extract()方法结合正则表达式,能够高效地提取特定模式的文本信息。 -
虚拟变量: 利用
get_dummies()方法可以将分类数据转换为虚拟变量,为机器学习模型做准备。 -
处理缺失值: 使用
str.replace()方法处理文本数据中的缺失值,保证数据的完整性。 -
分割文本数据: 利用
str.split()方法可以将文本数据进行分割,生成新的列或Series。 -
字符串处理方法: 掌握
str.upper()、str.lower()、str.strip()等方法,能够方便地处理字符串的大小写和空格。 -
合并与连接: 通过
str.cat()方法以及合并DataFrame的方式,实现文本数据的合并和连接。 -
排序文本数据: 使用
sort_values()方法按照字母顺序对文本数据进行排序,提高数据观察和理解的便利性。 -
统计分析: 利用
value_counts()方法对文本数据进行统计分析,了解数据分布和频率。 -
分组与聚合: 使用
groupby()和agg()方法进行文本数据的分组和聚合,获取汇总信息。 -
自定义函数应用: 利用
apply()方法能够应用自定义函数,实现对文本数据的个性化处理。 -
时间序列分析: 利用
to_datetime()和resample()方法处理包含时间信息的文本数据,进行时间序列分析。
通过综合运用以上技术,读者可以更灵活地处理各类文本数据,满足不同任务的需求。文本数据处理是数据分析和机器学习过程中不可或缺的一环,通过掌握这些技术,读者将能够更加高效地进行数据清理、探索性分析和建模工作,提升数据处理的水平和效果。希望本文能够为读者提供实用的知识和技能,使其在文本数据处理领域更具信心和实力。
版权声明:本文为博主作者:一见已难忘的申公豹原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_52908342/article/details/136069285