文章目录
- 前言
- 一、确定爬取的数据来源
- 二、确定获取数据的方式
- 三、编写Python程序进行数据爬取
- 总结
-
-
- Python技术资源分享
-
- 1、Python所有方向的学习路线
- 2、学习软件
- 3、精品书籍
- 4、入门学习视频
- 5、实战案例
- 6、清华编程大佬出品《漫画看学Python》
- 7、Python副业兼职与全职路线
-
-
- 这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【`保证100%免费`】
-
-
前言
常言道“人生苦短,我用Python。”Python可以为我们日常生活增加哪些便利呢,在此文中我将介绍使用Python爬取股票实时数据详情。

一、确定爬取的数据来源
我们爬取股票实时数据的来源一般有两种方式:从股票交易所的网站获取和从第三方财经网站获取。这里以第三方财经网站为例,常用的财经网站有新浪财经、上海证券报、东方财富等。

二、确定获取数据的方式
在确定好来源之后,我们需要选择获取数据的方式。通常情况下,获取数据的方式主要有以下三种:
1.使用网络爬虫爬取网页上的数据。
2.使用API接口获取数据。
3.使用第三方Python库获取数据。
其中,使用第三方Python库获取数据比较简单。常用的Python库有tushare、baostock等。
三、编写Python程序进行数据爬取
通常情况下,编写Python程序进行数据爬取可以使用requests库和beautifulsoup库。下面我将以爬取新浪财经的股票实时数据为例说明如何使用requests库和beautifulsoup库爬取数据。
示例1:爬取新浪财经指定股票实时数据
import requests
from bs4 import BeautifulSoup
url = 'http://finance.sina.com.cn/realstock/company/sh600519/nc.shtml'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取股票代码和名称
stock_name = soup.find('h1', class_='name').text.split()[0]
stock_code = soup.find('a', class_='code').text.split()[0]
# 获取股票实时数据
data = soup.find('div', class_='act_info').find_all('span')
# 输出实时数据
print(f'{stock_name}({stock_code})的实时数据:')
for item in data:
print(f'{item.text} ', end=' ')
在上述代码中,我们使用requests库发送请求,获取新浪财经指定股票的实时数据,将其转换为BeautifulSoup对象,然后通过find()方法获取指定元素。
示例2:爬取新浪财经指定股票历史数据
import requests
from bs4 import BeautifulSoup
url = 'https://finance.sina.com.cn/realstock/company/sh600519/hisdata/klc_kl.shtml'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取股票代码和名称
stock_name = soup.find('h1', class_='name').text.split()[0]
stock_code = soup.find('a', class_='code').text.split()[0]
# 获取股票历史数据
data = soup.find('div', class_='historical-data-wrap').find_all('tr')
# 输出历史数据
print(f'{stock_name}({stock_code})的历史数据:')
for item in data:
history = item.find_all('td')
if len(history) == 7:
date = history[0].text
opening_price = history[1].text
highest_price = history[2].text
closing_price = history[3].text
lowest_price = history[4].text
volume = history[5].text
amount = history[6].text
print(f'{date} 开盘价:{opening_price} 最高价:{highest_price} 收盘价:{closing_price} 最低价:{lowest_price} 成交量:{volume} 成交金额:{amount}')
在上述代码中,我们同样使用requests库发送请求,获取新浪财经指定股票的历史数据,将其转换为BeautifulSoup对象,然后通过find()方法获取指定元素。
总结
以上就是利用Python 爬取股票实时数据详情的完整攻略。
祝大家学习、工作、生活愉快~

【最新Python全套从入门到精通学习资源,文末免费领取!】
Python技术资源分享
如果你对Python感兴趣,学好 Python 不论是就业、副业赚钱、还是提升学习、工作效率,都是非常不错的选择,但要有一个系统的学习规划。
小编是一名Python开发工程师,自己整理了一套 【最新的Python系统学习教程】,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。
如果你是准备学习Python或者正在学习,下面这些你应该能用得上:
1、Python所有方向的学习路线
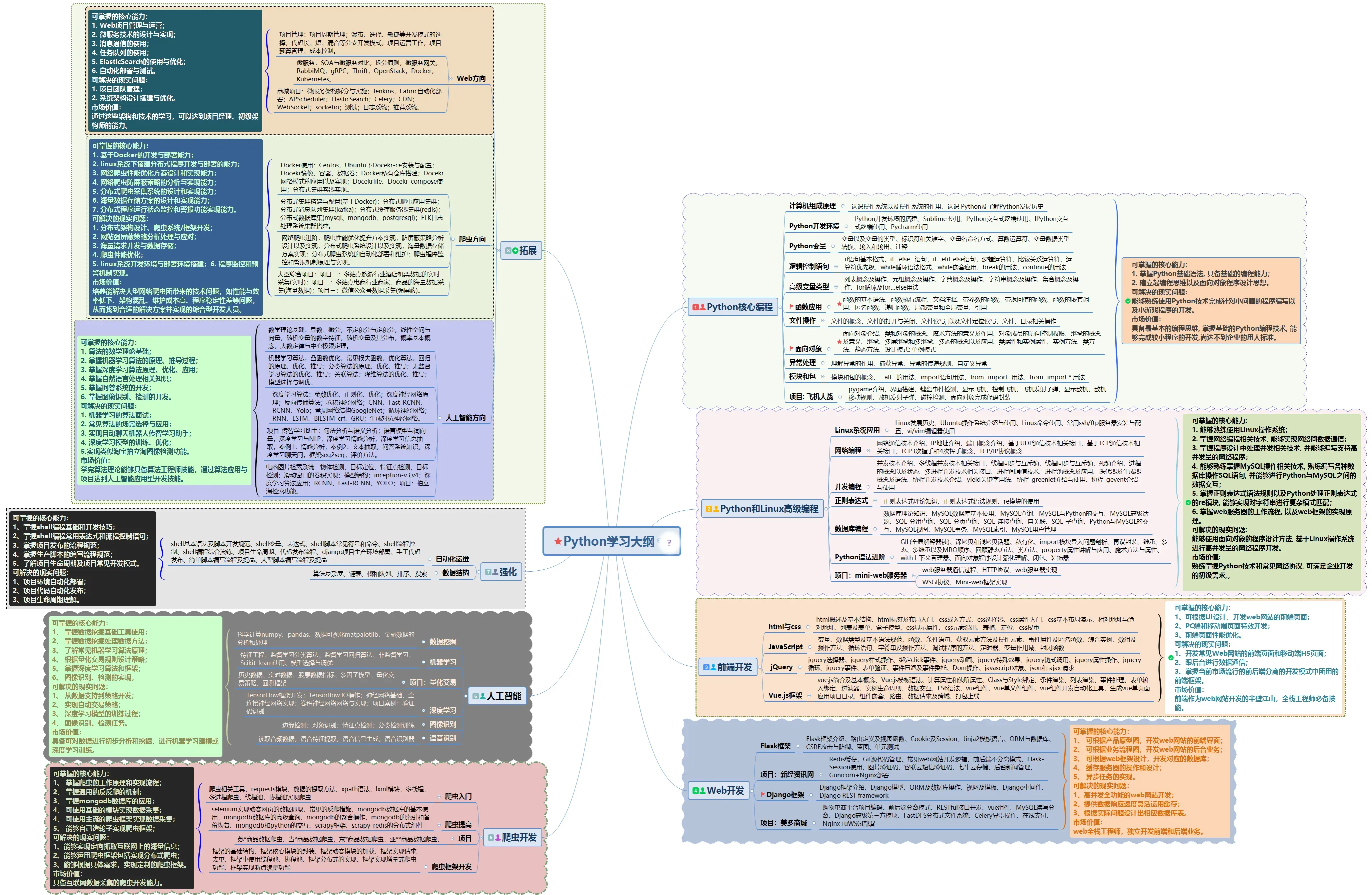
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
2、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
3、精品书籍
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
4、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
5、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
6、清华编程大佬出品《漫画看学Python》
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。

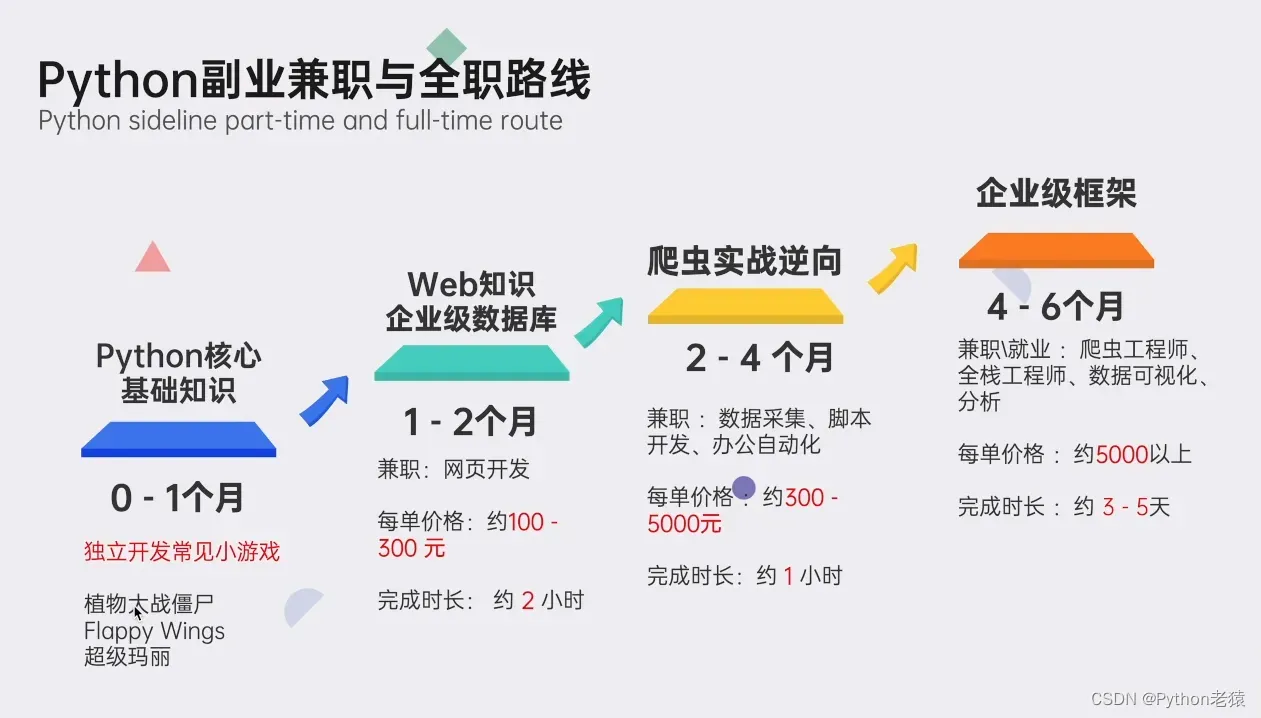
7、Python副业兼职与全职路线
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉CSDN大礼包:《Python入门资料&实战源码&安装工具】免费领取(安全链接,放心点击)

版权声明:本文为博主作者:python零基础入门小白原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2301_80239908/article/details/134034524