前言
近期在做NER的工作,由于缺乏标注数据,所以,你懂的😭😭
Label Studio不仅可以用来标注文本NER任务,还可以用来标注文本分类、图像分类等等其他AI任务。
其他标注任务自己去探索吧,我这里只讲一下NER任务。
一、安装与启动
安装
pip install -U label-studio
启动
# 打开命令行,在命令行中执行:
label-studio
二、基本使用
不出意外的话,在命令行中启动 Label Studio 后,会弹出一个登陆页面
如上图
第一次使用需要创建账号,注册一下就好了
注册好后登陆进去,然后会跳转到如下页面
第一次登陆进来,这个页面应该是空白的,这些都是我自己建的项目。你们不用管
下面,我们开始创建自己的项目:
1、点击右上角的create按钮
点击后弹出如下页面,设置自己的项目名和项目描述
2、设置好项目名称和描述后,点击旁边的 Data Import,进入到数据导入页面
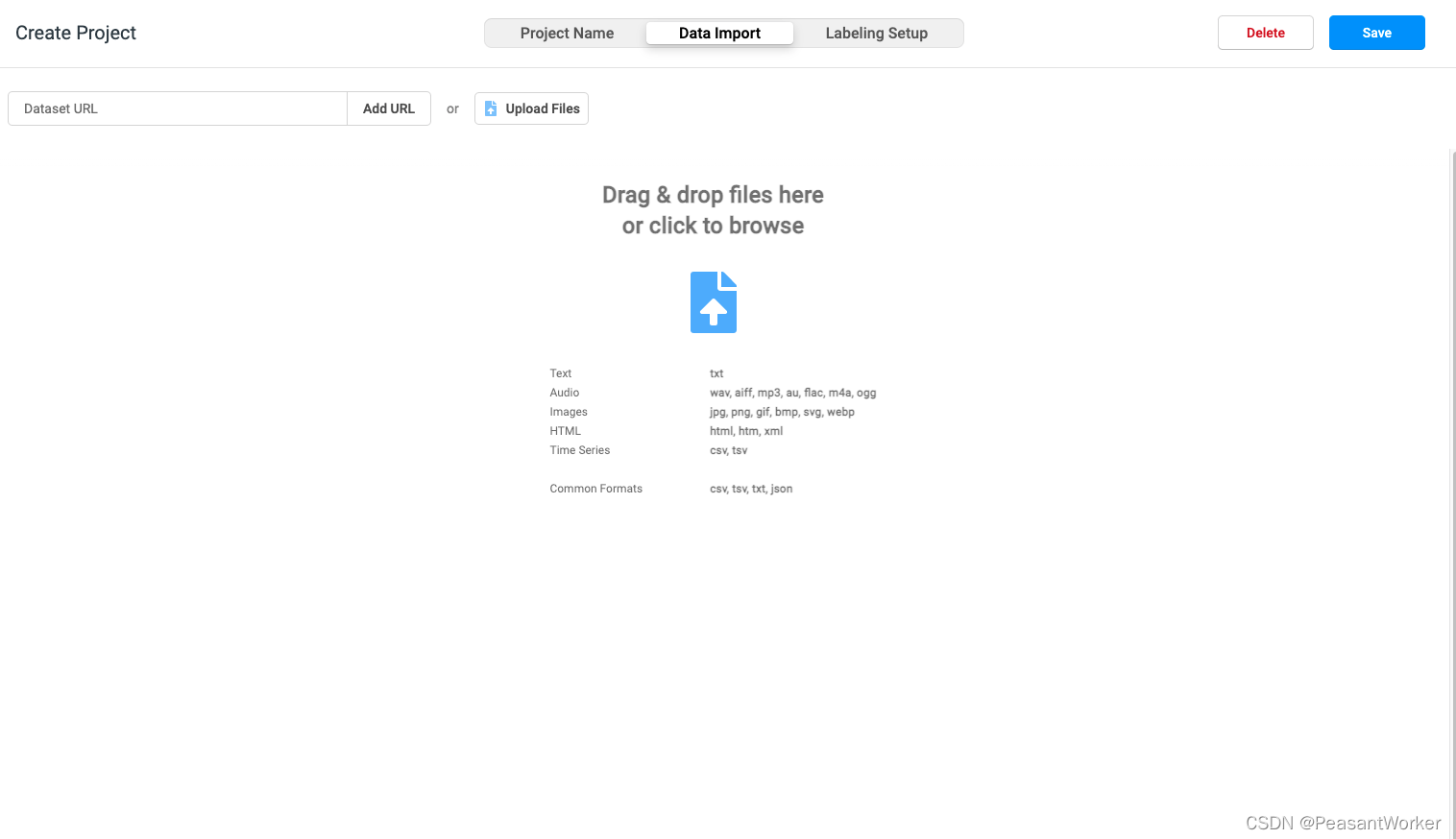
3、点击Upload Files按钮,从本地选择一个待标注的文件
我的文件格式是一行一行的 .txt 文本,如图:
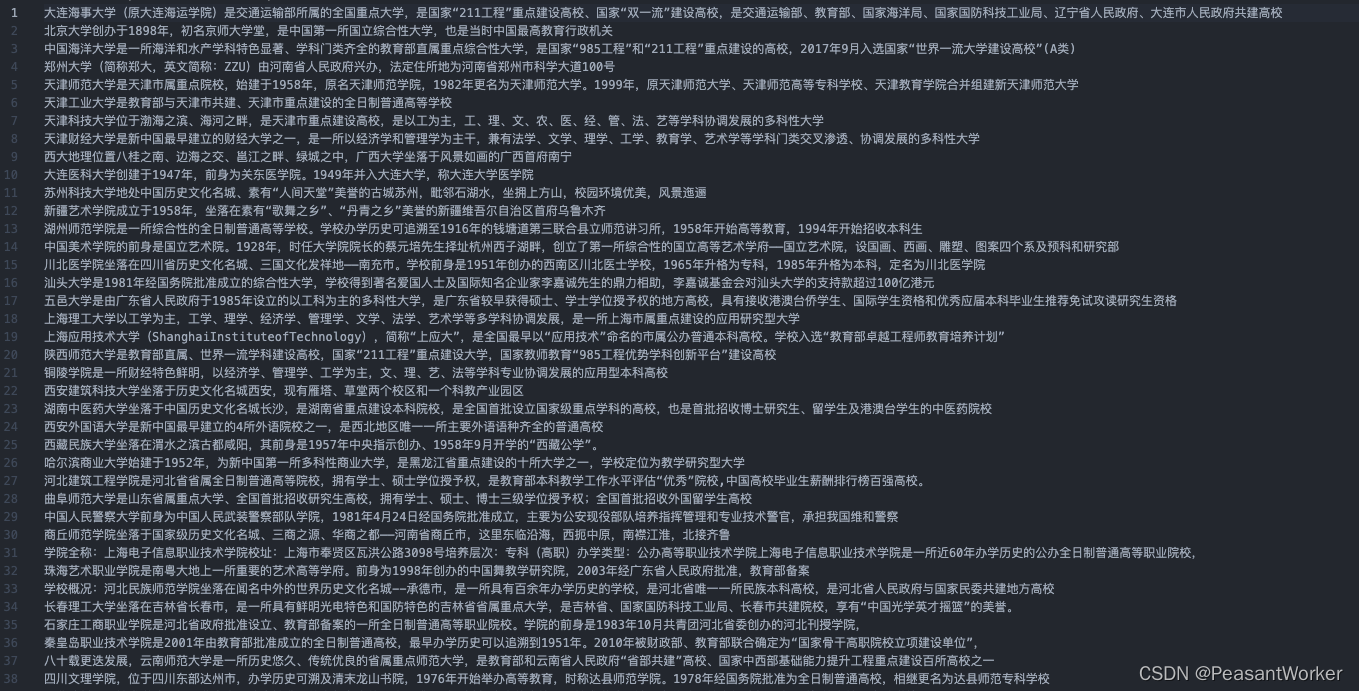
一行表示一条数据。文件格式也可以是CSV,按理说只要是一行一条数据的都可以,感兴趣的同学可以自己探索下。
4、选择好待标注的文件后,点击确定,会弹出如下界面:
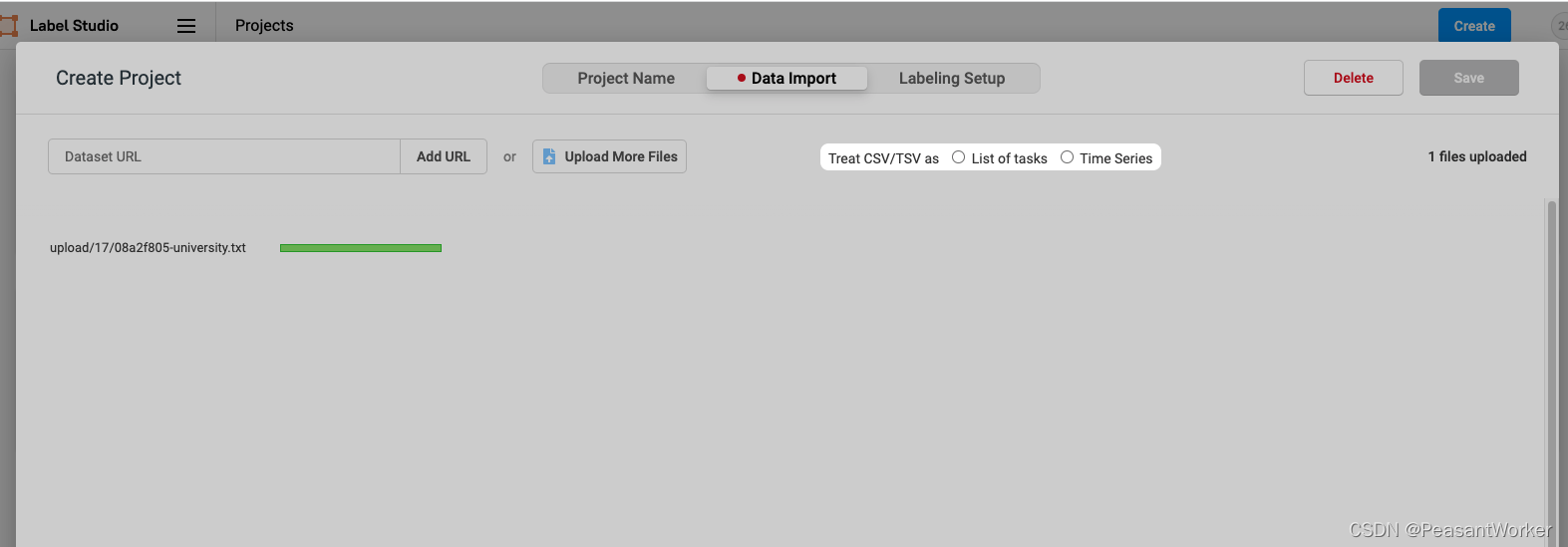
5、这里需要选择是 List of tasks 还是Time Series,这里我选择的是List of tasks
6、选择好后,点击旁边的 Labeling Setup,页面如下:
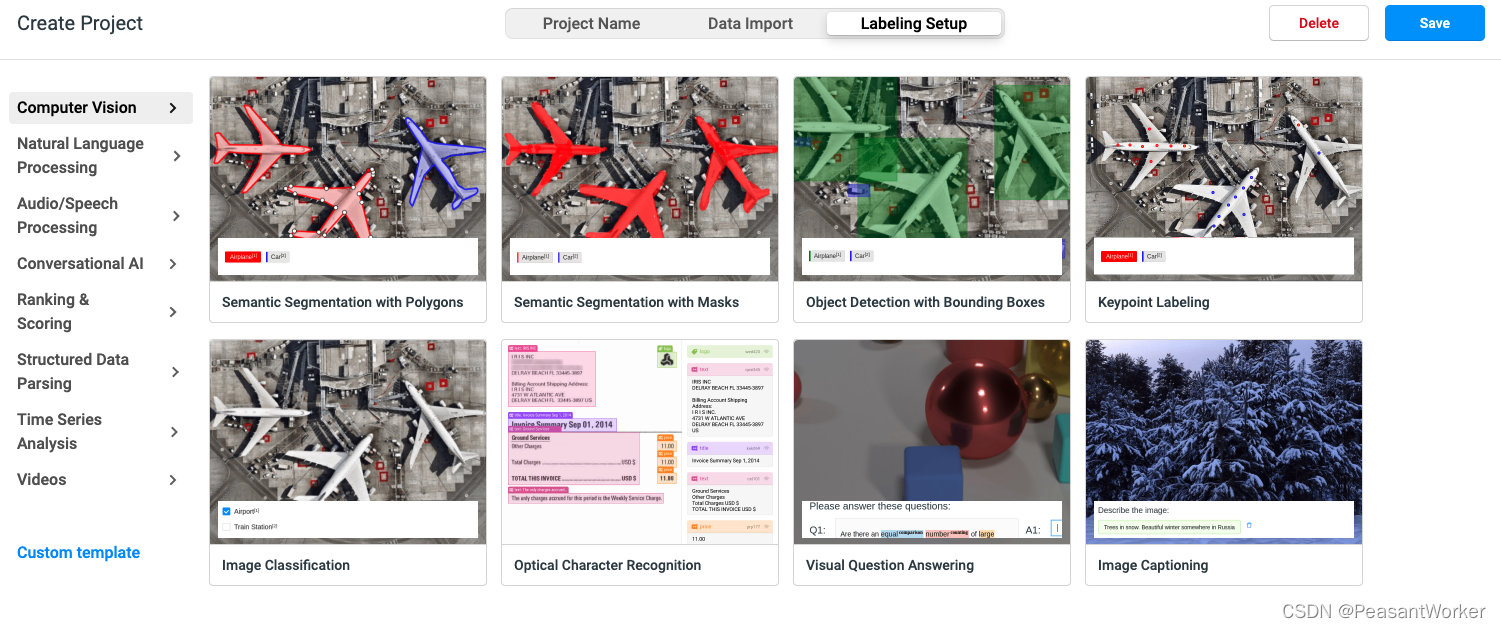
7、找到Natural Language Processing,选择Named Entity Recognition
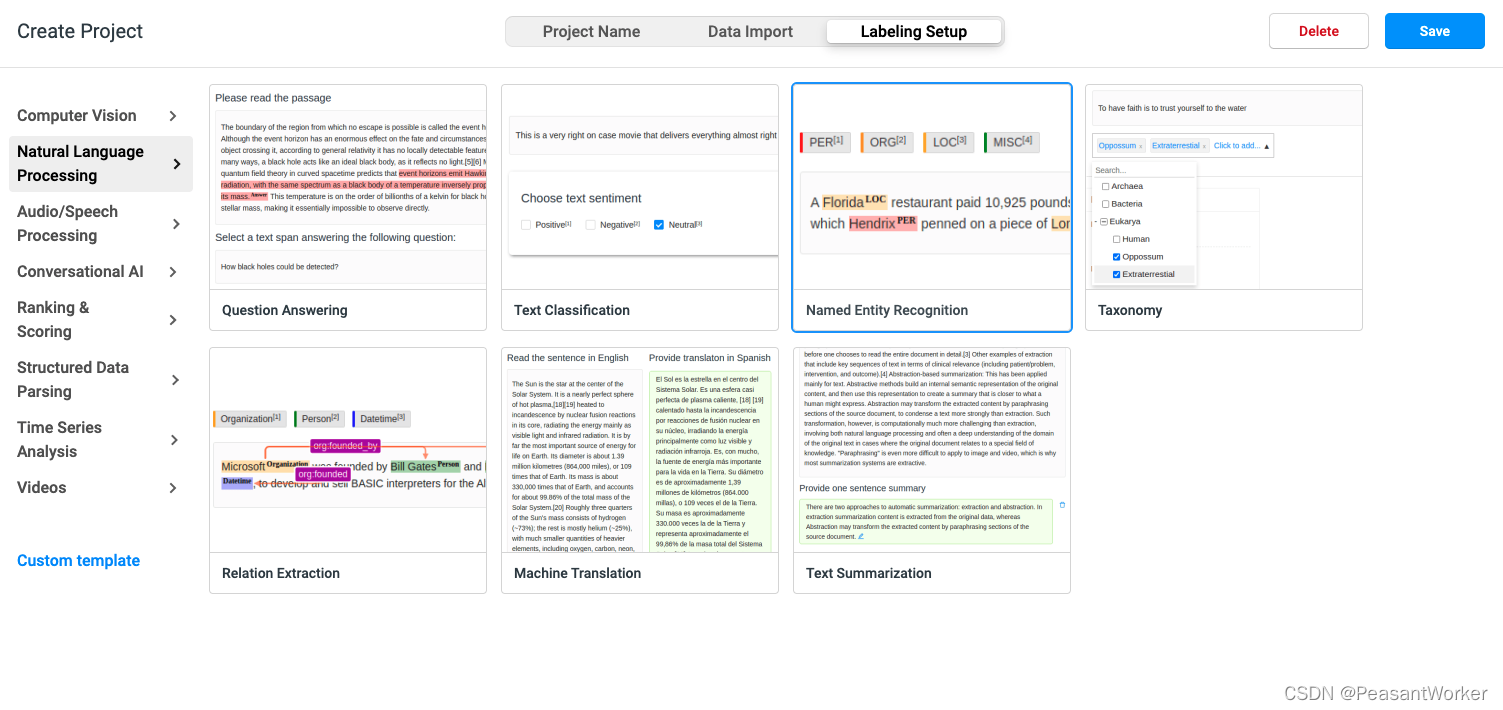
8、选择后,弹出如下页面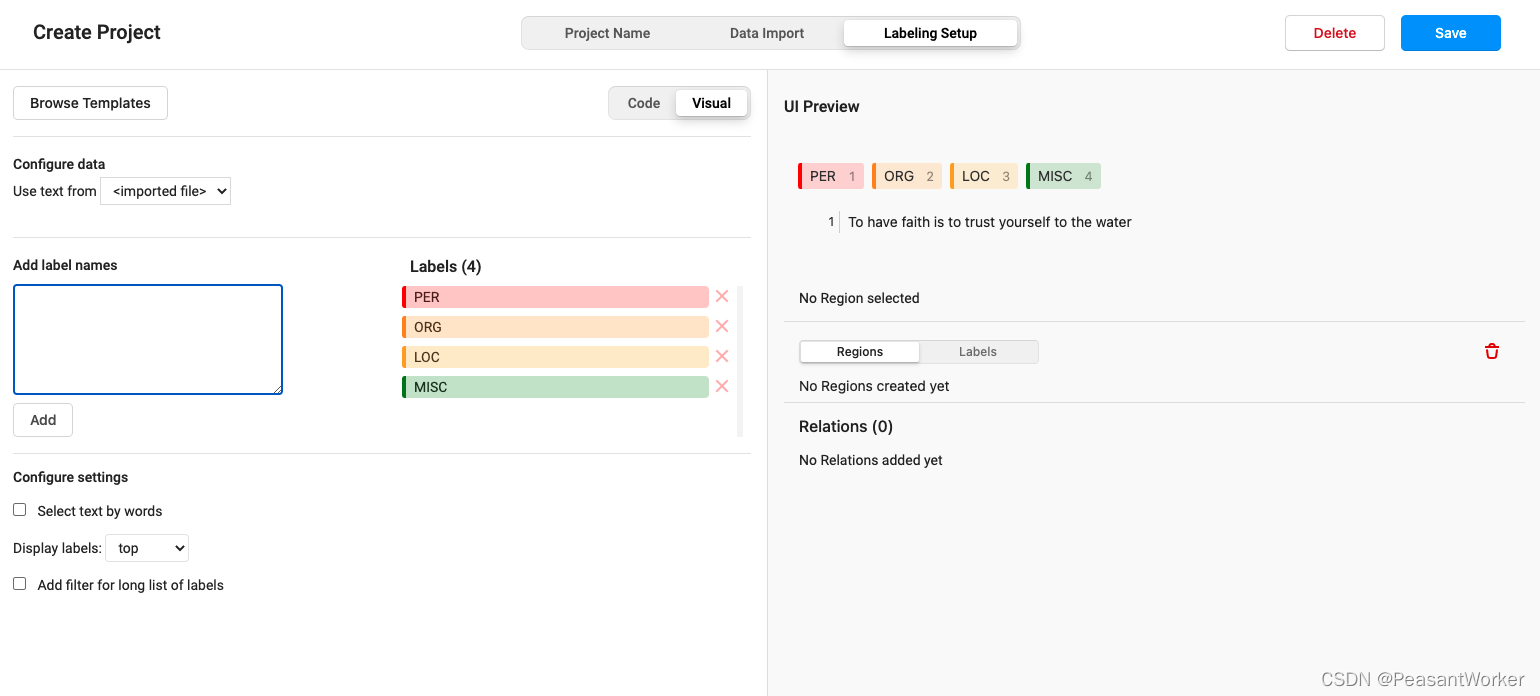
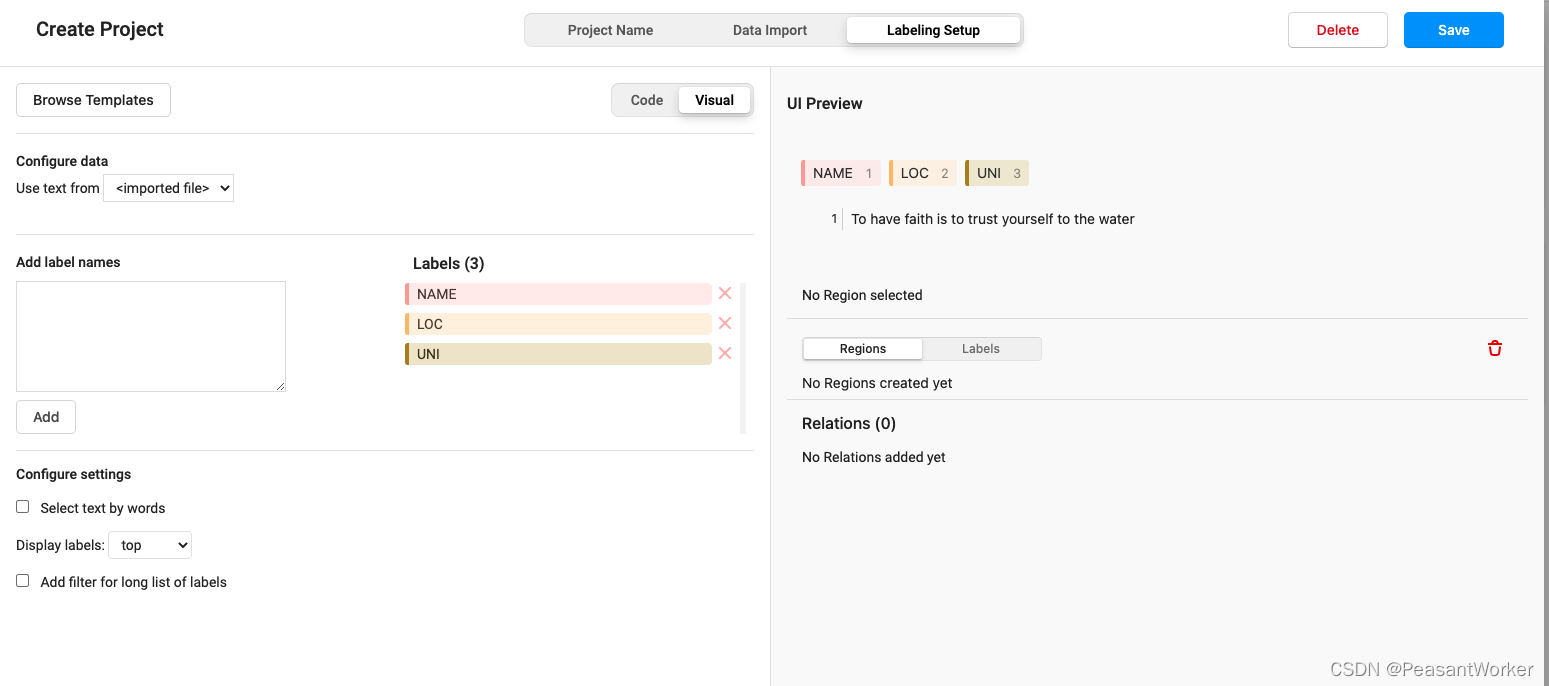
9、默认的四个标签 PER ORG LOC MISC,删掉这四个标签,换成我们自己的标签
从旁边的方框里输入自己的标签名称,再点击Add就可以添加自己自定义的标签了
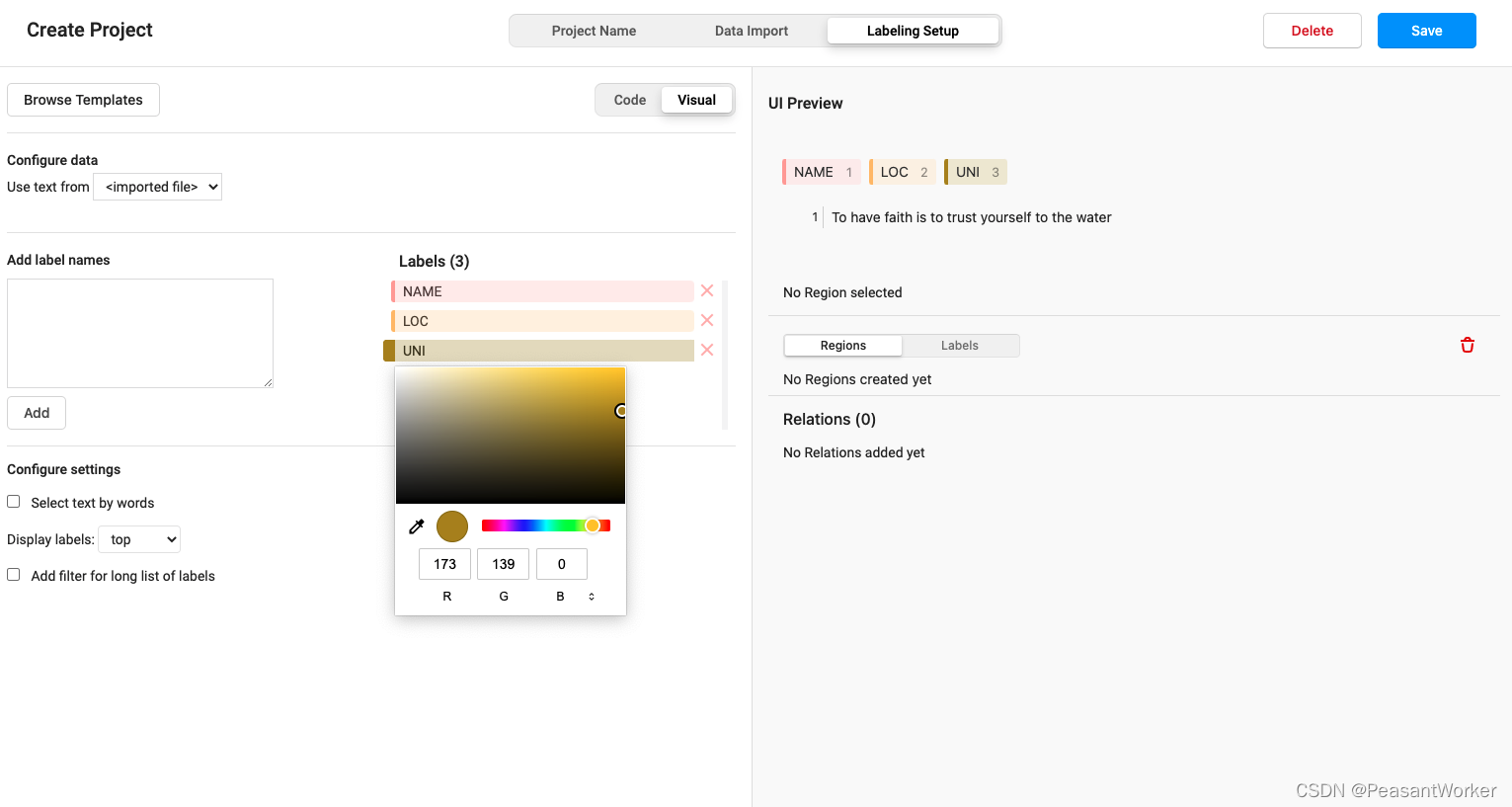
点击我们添加的标签,还能自定义颜色
10、至此,我们就选择好了所有的配置,看起来很麻烦事因为我说的比较细,就怕有些同学看不懂。点击右上角的Save按钮,就可以开始标注了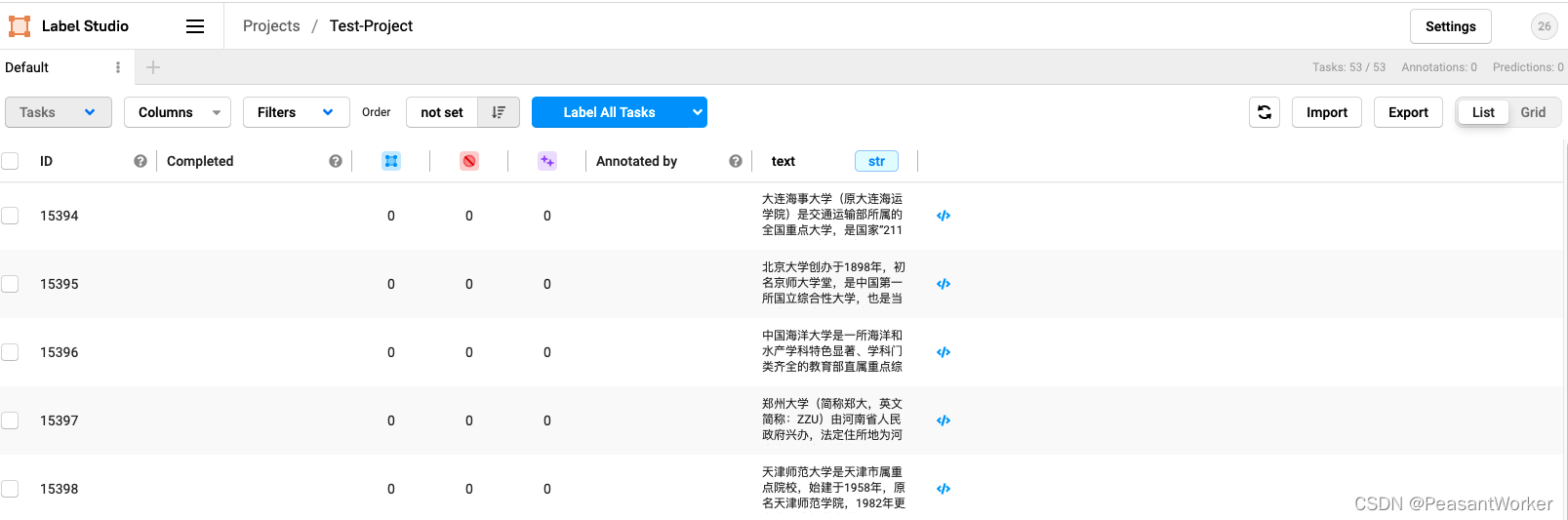
11、点击Label All Tasks 按钮,开始愉(痛)快(苦)地标注之旅吧
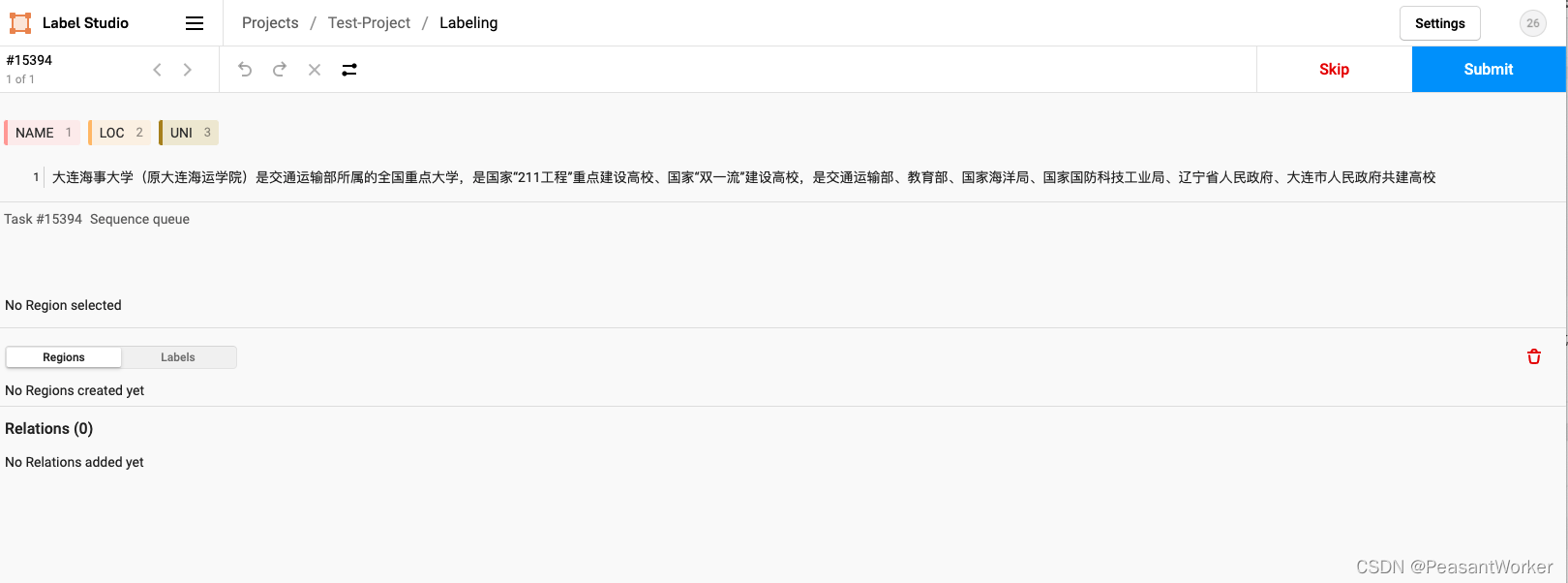
12、点击实体名称,再通过鼠标从待标注的文本选择出正确的实体,如图:
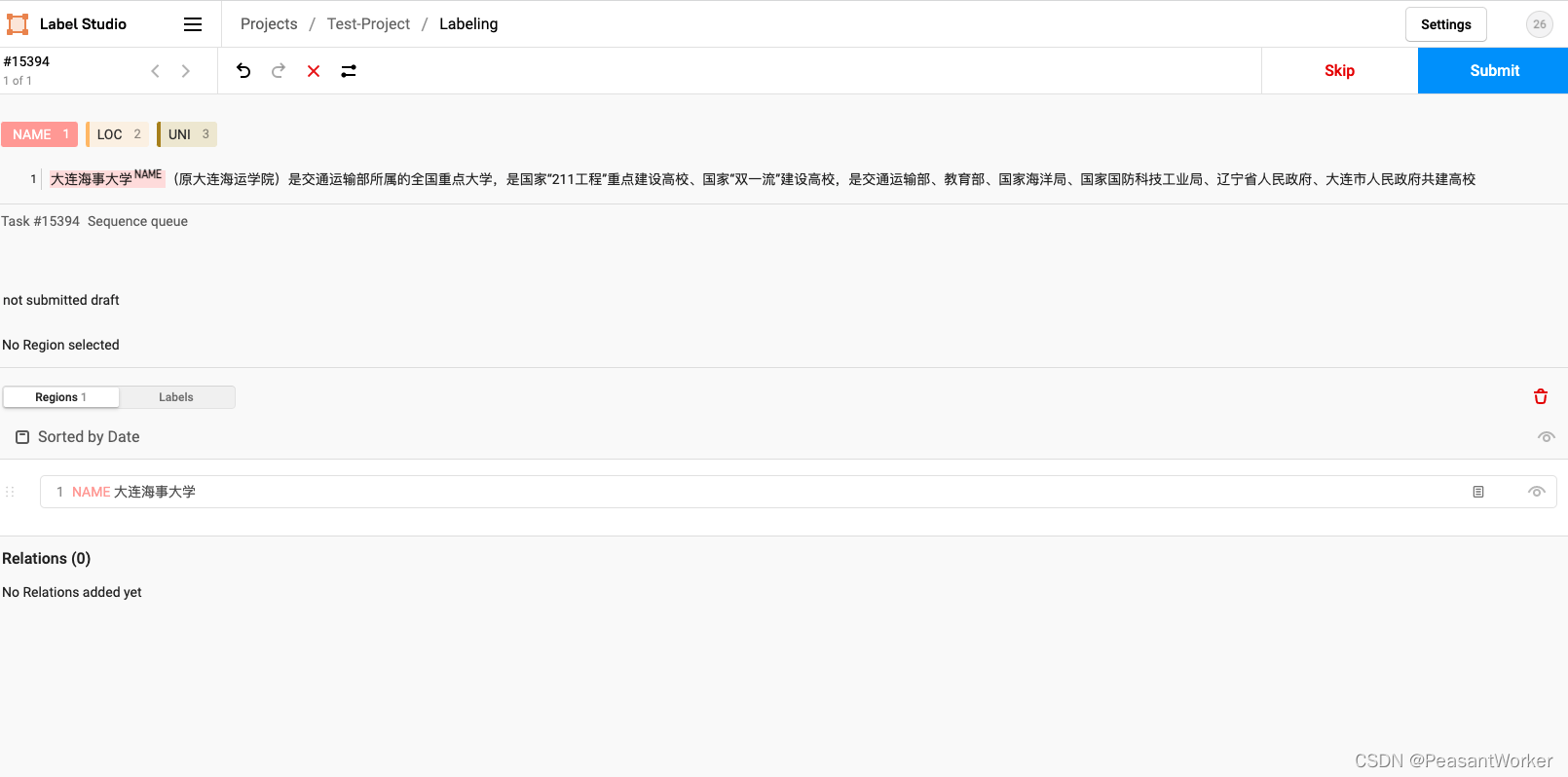
注意:标注完成后,一定要点击Submit提交已标注的数据,要不然,一天白干
设置一下可以让标签显示在实体右上角
13、标注完成后,点击右上角 Export 可以导出已标注的数据
14、这里我们选择CSV,你想导出其他格式的也可以
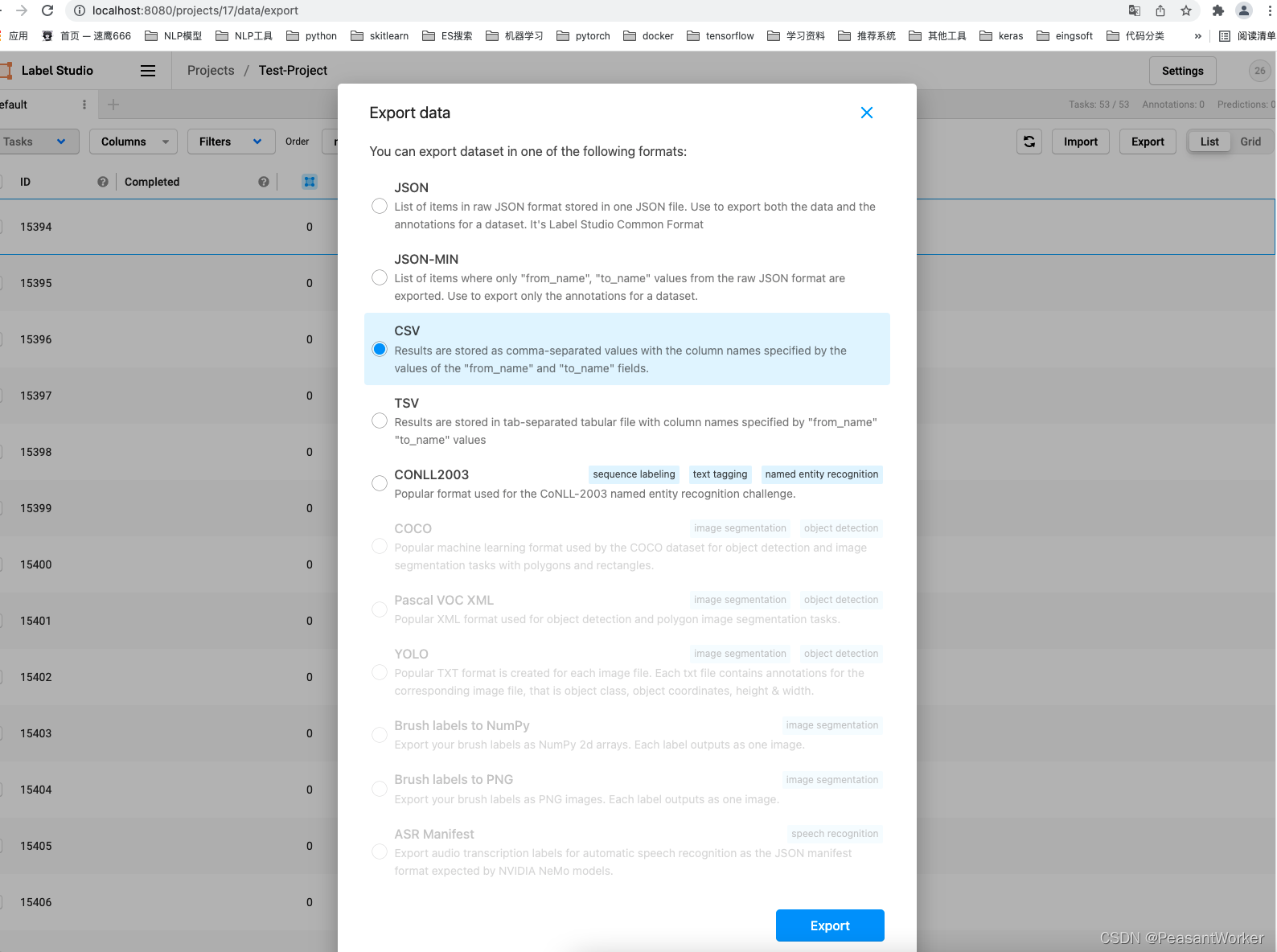
点击下面的Export蓝色按钮,就能导出已标注的数据啦
15、导出的csv的数据格式

16、通过以下代码,我们将其转为以下这种数据格式:
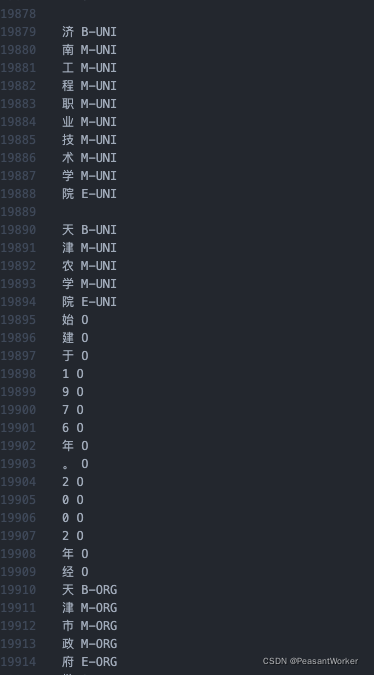
转换代码:
def gen_train_data(file_path, save_path):
"""
file_path: 通过Label Studio导出的csv文件
save_path: 保存的路径
"""
data = pd.read_csv(file_path)
for idx, item in data.iterrows():
text = item['text']
if pd.isna(text):
text = ''
text_list = list(text)
label_list = []
labels = item['label']
label_list = ['O' for i in range(len(text_list))]
if pd.isna(labels):
pass
else:
labels = json.loads(labels)
for label_item in labels:
start = label_item['start']
end = label_item['end']
label = label_item['labels'][0]
label_list[start] = f'B-{label}'
label_list[start+1:end-1] = [f'M-{label}' for i in range(end-start-2)]
label_list[end - 1] = f'E-{label}'
assert len(label_list) == len(text_list)
with open(save_path, 'a') as f:
for idx_, line in enumerate(text_list):
if text_list[idx_] == '\t' or text_list[idx_] == ' ':
text_list[idx_] = ','
line = text_list[idx_] + ' ' + label_list[idx_] + '\n'
f.write(line)
f.write('\n')
直接传参就可以啦
总结
1、我愿称其为 NER 标注神器
2、应该可以多人协同、如果有同学搞定多人协同标注,可以写一篇博客教程,将博客链接放在评论区
3、BiLSTM + CRF NER 任务可以参考:https://blog.csdn.net/qq_44193969/article/details/116008734-文章写的有点潦草,代码可以跑通,后续有空会重新编辑一下,感兴趣的同学将就着看吧哈哈
文章出处登录后可见!