前言:Pandas的数据操作中,最基本的就是操作的筛选了,但是对新学员来说的这又是一个难点,因为方法比较多,不容易记。在此总结一下pandas中的一些常用的数据筛选操作。
逻辑筛选数据:切片([ ]),loc,iloc,这三种都是支持逻辑表达式的,选其中一种比较常用的,逻辑运算符 与或非(& | ~)any,all
展示使用的数据结构:
import pandas as pd
PATH = '/tmp/MSD0921.xlsx'
dataframe = pd.read_excel(PATH,engine='openpyxl', nrows=50)| SD1 | SD2 | SD3 | SD4 | SD5 | SD6 | SD7 | SD8 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 7 | 2 | 1 | 2 | 6 | 7 | 6 |
| 1 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| 2 | 1 | 7 | 1 | 1 | 1 | 6 | 6 | 6 |
| 3 | 6 | 6 | 3 | 2 | 2 | 2 | 2 | 2 |
| 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| … | … | … | … | … | … | … | … | … |
| 258 | 1 | 5 | 2 | 1 | 1 | 7 | 7 | 6 |
| 259 | 1 | 7 | 7 | 4 | 2 | 1 | 7 | 1 |
| 260 | 1 | 3 | 5 | 4 | 5 | 5 | 5 | 6 |
| 261 | 1 | 3 | 5 | 5 | 5 | 5 | 3 | 2 |
| 262 | 1 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
1、筛选出某一列大于某一个数的所有数据,例如:SD1>=7
"""筛选出SD1列中大于等于7的数据"""
dataframe[dataframe['SD1'] >= 7]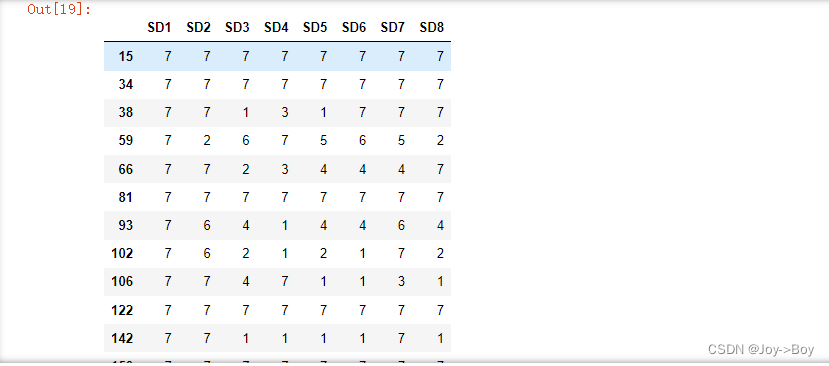
2、筛选出某一列大于或者小于另一列的输有数据,例如:SD1 < SD2
"""筛选出SD1列小于SD2列所有数据"""
dataframe.loc[dataframe['SD1'] < dataframe['SD2']]
3、筛选出某些列的值大于或小于某些值的所有数据,例如:SD1 >6并且SD1<3,使用 &
"""筛选出SD1大于6,并且SD2小于3的所有数据"""
dataframe.loc[(dataframe['SD1'] > 6) & ( dataframe['SD2'] < 3)]
4、筛选出某些列的值大于或小于某些值的所有数据,例如:SD1 >6或者SD1<3,使用 |
"""筛选出SD1小于6,或者SD2小于3的所有数据,并集"""
dataframe.loc[(dataframe['SD1'] > 6) | ( dataframe['SD2'] < 3)]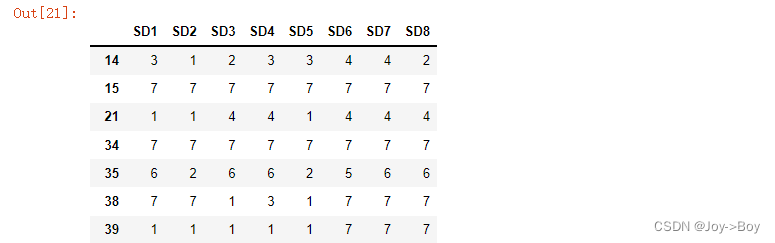
注意:需要注意的是在进行或(|)、与(&)、非(~)运算时,各个独立逻辑表达式需要用括号括起来
除了上边的与或之外,pandas还提供了 all,any,对逻辑计算后的布尔值在进行判断,所有都为True,all才返回True,反之亦然,any满足其中之一即可。all,any可传参数axis,1为行方向,0为列方向。利用此方法可对整体数据逻辑判断。
5、筛选出某些列的值同时大于或同时小于某值的所有数据,例如SD1>6 SD2>6
"""筛选出SD1, SD2同时大于6的所有数据"""
dataframe[(dataframe.loc[:,['SD1', 'SD2']] > 6).all(1)] 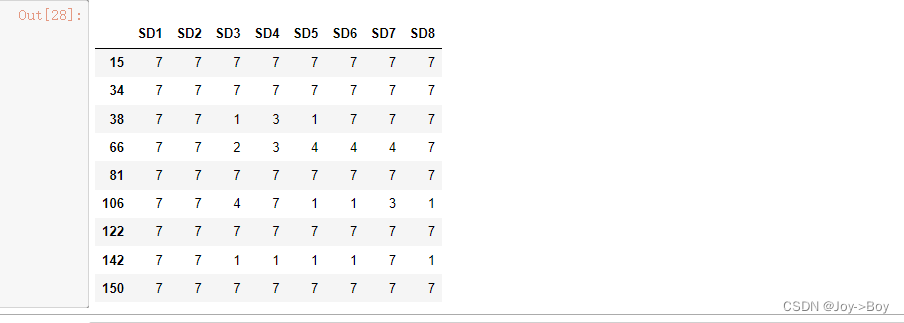
逻辑解读: dataframe.loc[:,['SD1', 'SD2']] > 6,这个逻辑计算的是SD1,SD2同时大于6返回的布尔值,逗号前的冒号表示所有行,返回的是False或者True的一个dataframe数据,整体在进行.all(1),操作返回的是SD1,SD2都为True的为True,否者为False所有行数。在使用切片 [ ],进行取数据。

下篇文章会总结pandas的其他的一些常用方法,函数筛选
pandas结合匿名函数lambda、比较函数eq(),le(),lt(),ge(),gt()
dataframe.query()
dataframe.filter()
dataframe.select_dtypes()
文章出处登录后可见!