目录
1、selenium简介
Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等; 支持的开发语言有Java、Python、C#、ruby。
2004年selenium诞生
2006年webdriver诞生
2008年selenium与webdriver合并selenium2.0
2016年selenium3.0诞生
2021年selenium4.0诞生
Selenium IDE
嵌入到FIrefox浏览器中的一个插件,实现简单的浏览器操作的录制和回放功能,应用场景:快速的创建bug重现场景,在测试人员测试过程中,发现bug之后可以通过IDE将重现的步骤录制下来,以帮助开发人员更容易的重现bug
IDE录制的脚本可以转换为多种语言。从而帮助我们快速的开发脚本
Ps: 按经验建议尽量少用录制,在人工智能没发展到一定程度,这是一条歪路。
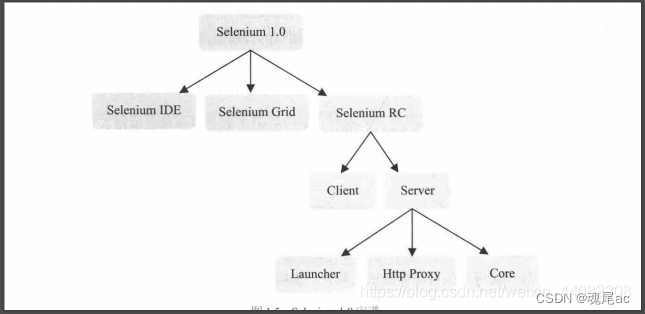
Selenium RC
Selenium RC 是Selenium家族的核心部分。Selenium RC 支持多种不同语言编写的自动化脚本测试,通过Selenium RC服务器作为代理服务器去访问应用,从而达到测试的目的。
Selenium RC分为Client Libraries和Selenium Server。Client Libraries库主要用于编写测试脚本,用来控制Selenium Server的库。Selenium Server 负责控制浏览器行为。总的来说,Selenium Server 包括三个部分:Launcher、Http Proxy和Core。其中,Selenium Core是被Selenium Server嵌入到浏览器页面中。其实Selenium Core就是一堆JavaScript函数的集合,即通过这些javascript函数我们才能实现用程序对浏览器的操作。Launcher用于启动浏览器,把Selenium Core加载到浏览器页面当中,并把浏览器的代理设置为Selenium Server的Http Proxy。
Ps: 建议做WEB自动化过程中可以顺便将js学会。
2、环境 Python + selenium
2.1、selenium库安装
命令:pip install selenium 或 pip3 install selenium
2.2、驱动下载
浏览器驱动下载 chrome (ie、火狐可自行学习)
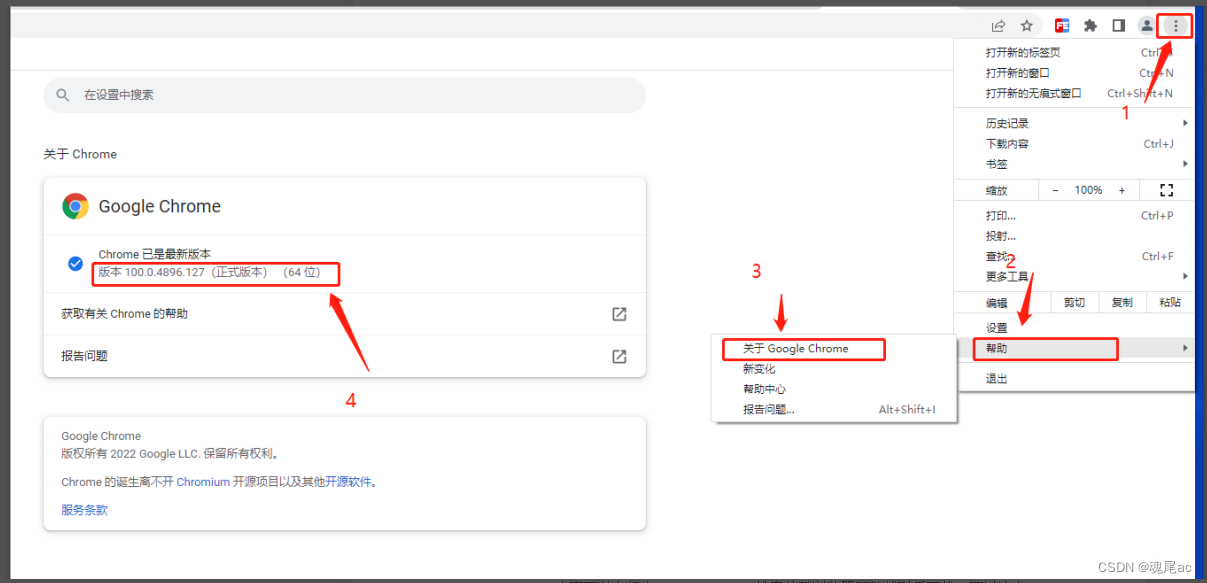
- 确认谷歌浏览器版本,操作如下图,确认版本为100.0.4896.127
- 针对浏览器版本去下载对应的驱动
大家可以自行去www.baidu.com搜索谷歌浏览器驱动找到后下载,不过这个过程可能比较久。在这里提供所有版本的下载连接
http://chromedriver.storage.googleapis.com/index.html
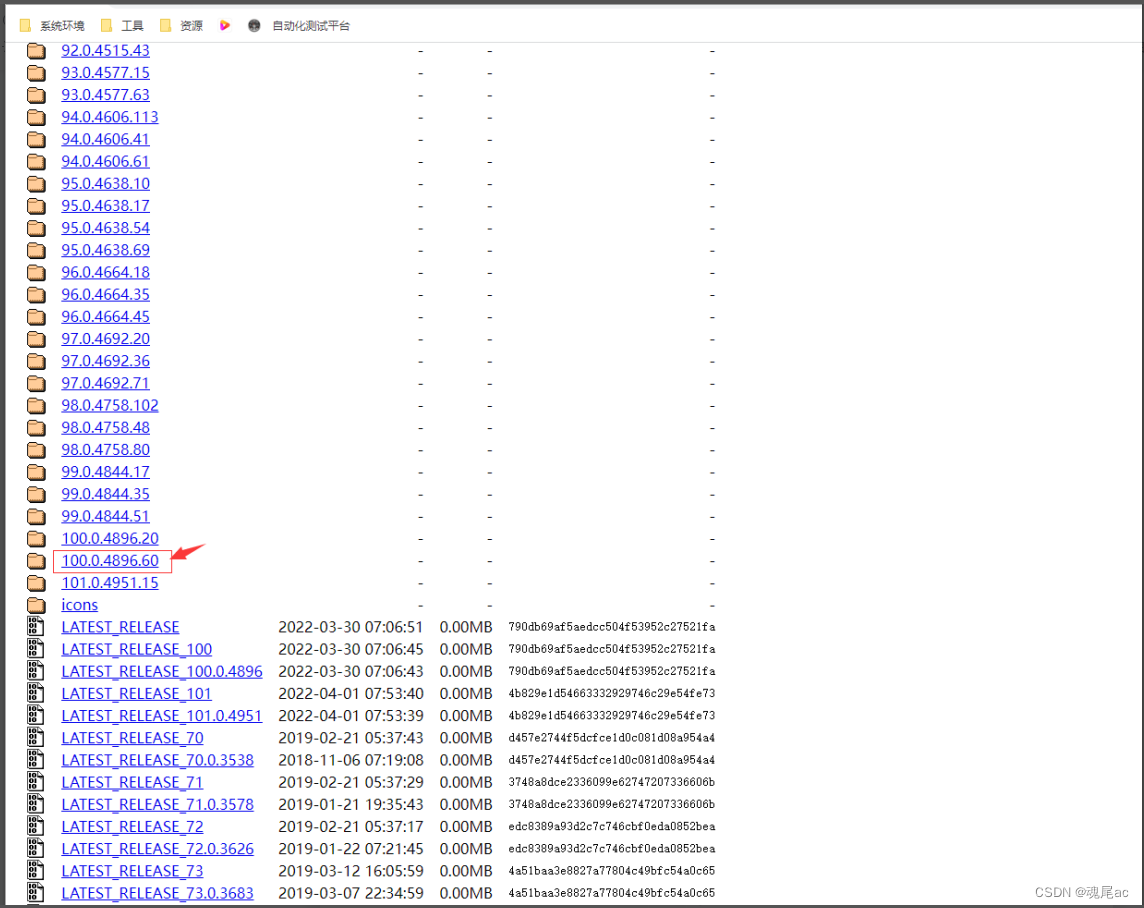
进入网站找到对应版本的驱动下载,上图版本是100.0.4896.127,是以要找到对应版本下载,如果找不到对应版本,可以找最相近的版本。也是可以用来驱动浏览器的,不能用一定会有对应版本出现;现在没有找到100.0.4896.127版本,所以找到最接近版本100.0.4896.60下载
选择当前系统所对应的版本,像window版本,直接下win32的包,不用担心64位系统。通用,如果不通用,肯定会有一个win64的包。
将下载的zip压缩包解压出来的chromedriver.exe的文件
2.3、驱动位置与使用
驱动位置有两种,这里讲灵活放置法,规范放置法大家可当课题自行去研究。
灵活放置是将驱动文件放到selenium执行代码文件同级目录下即可。
举例:
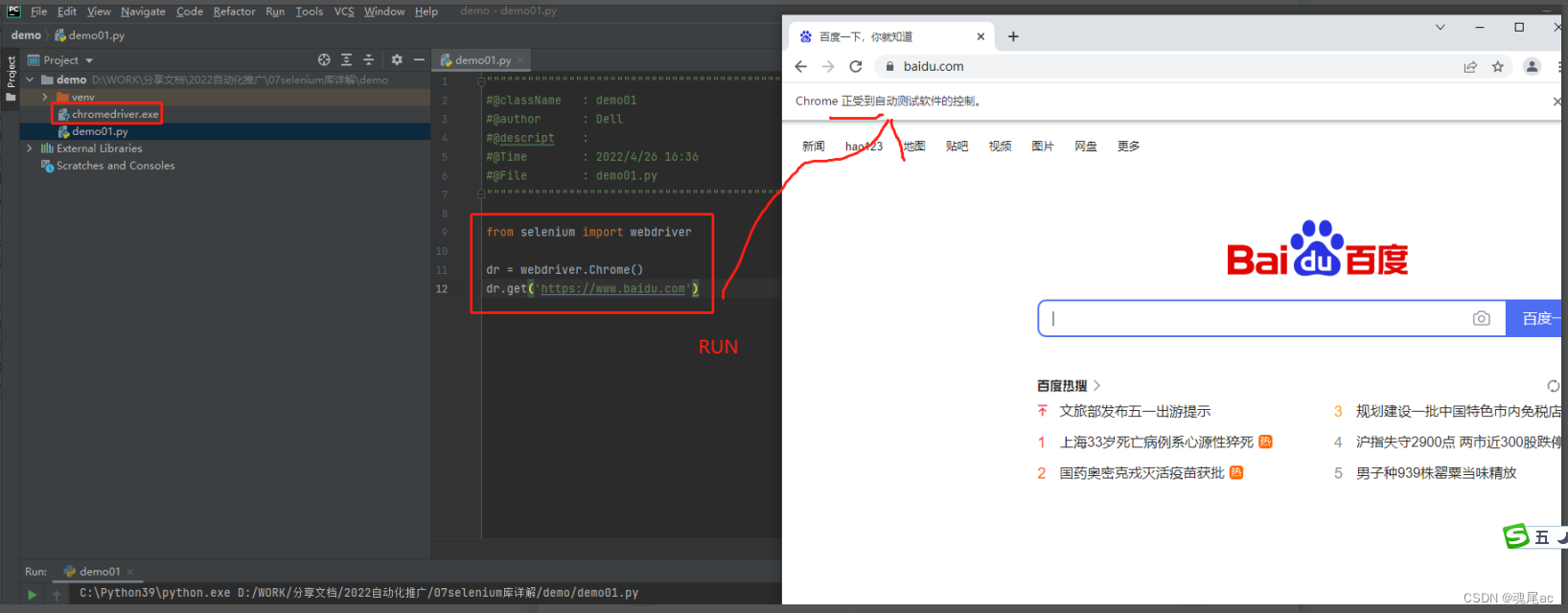
新增一个python项目,然后将chromedriver.exe文件放到项目目录下
新增一个demo01.py文件在文件里编写打开百度的代码
from selenium import webdriver
dr = webdriver.Chrome()
dr.get('https://www.baidu.com')
运行。如下图,成功打开谷歌浏览器,访问百度网站
3、selenium库代码讲解
使用selenium之前,需要先了解一些网页元素定位的知识,结合这些知识来实现元素定位后点击,编辑等
如何手动进行元素定位?
打开浏览器—f12进入开发者模式—在Elements页面—使用选择工具去页面点击对应元素—HTML将自动展开并高亮显示选择到的元素标记
重要知识点
- find_element() 与 find_elements() 方法
- 元素定位八大方式
将上面两点结合起来讲解,如下:
3.1~3.7介绍定位八大方式,3.8是讲js独立脚本
3.1、id
在网页HTML中发现有一个元素刚好有id属性,很幸运,因id基本上需要唯一,不然Doc会出现未知异常。我们可以使用其定位出来这元素来实现对应操作。因为它是唯一的,所以一般可以使用find_element()来定位
举例:
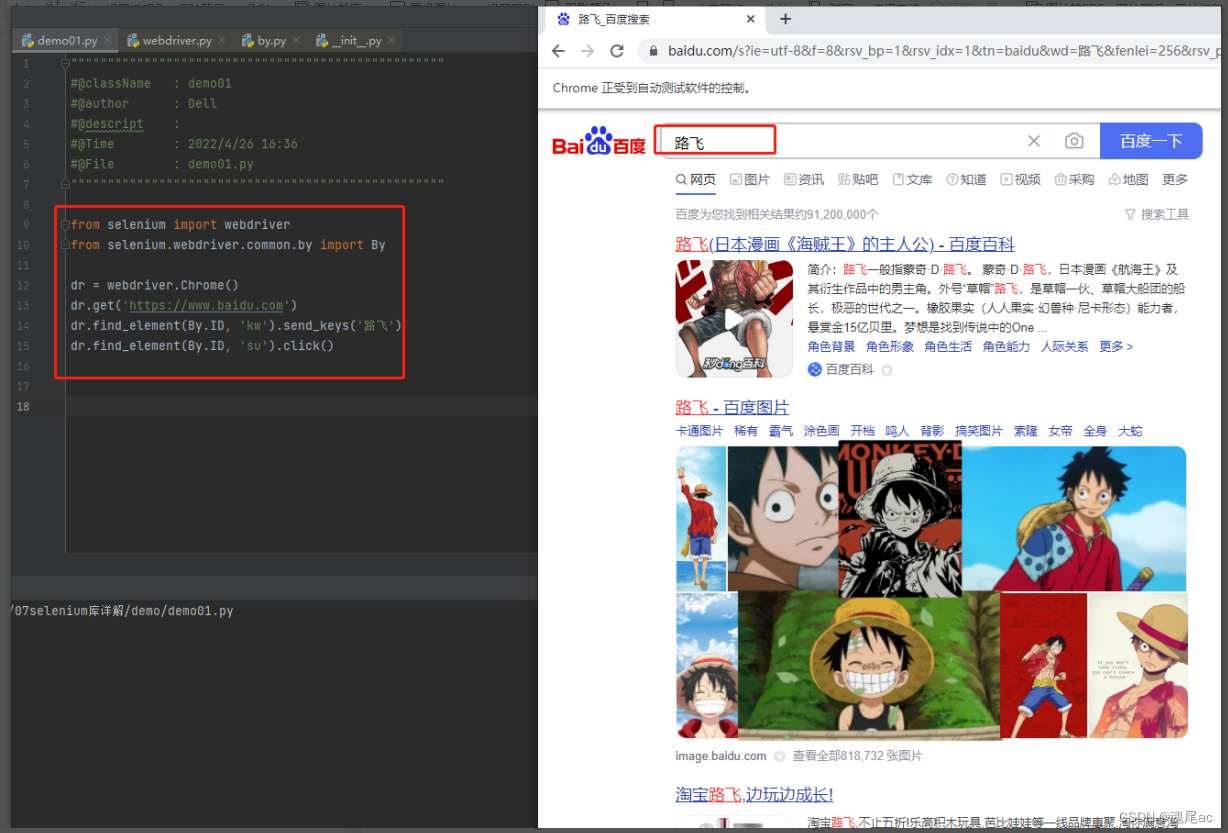
进入百度,搜索’路飞’,
可以通过 f12在html里知道百度搜索框架的id是kw,搜索按钮的id是su
所以编写代码如下:
#导入库
from selenium import webdriver
from selenium.webdriver.common.by import By
#初始化浏览器
dr = webdriver.Chrome()
#打开百度
dr.get('https://www.baidu.com')
#输入路飞
dr.find_element(By.ID, 'kw').send_keys('路飞')
#点击百度一下
dr.find_element(By.ID, 'su').click()在最开始需要将 selenium 的 webdriver与By 导入
在输入路径语句中查询元素方法find_element里参数一By.ID表示定位属性是id,参数二表示属性值为kw
代码执行如下
3.1、name
在网页HTML中发现有一个元素有name属性,也很幸运,因为开发能添加name,也是要给其标记,将其与其他元素区别。我们可以使用其定位出来这元素来实现对应操作。
举例:
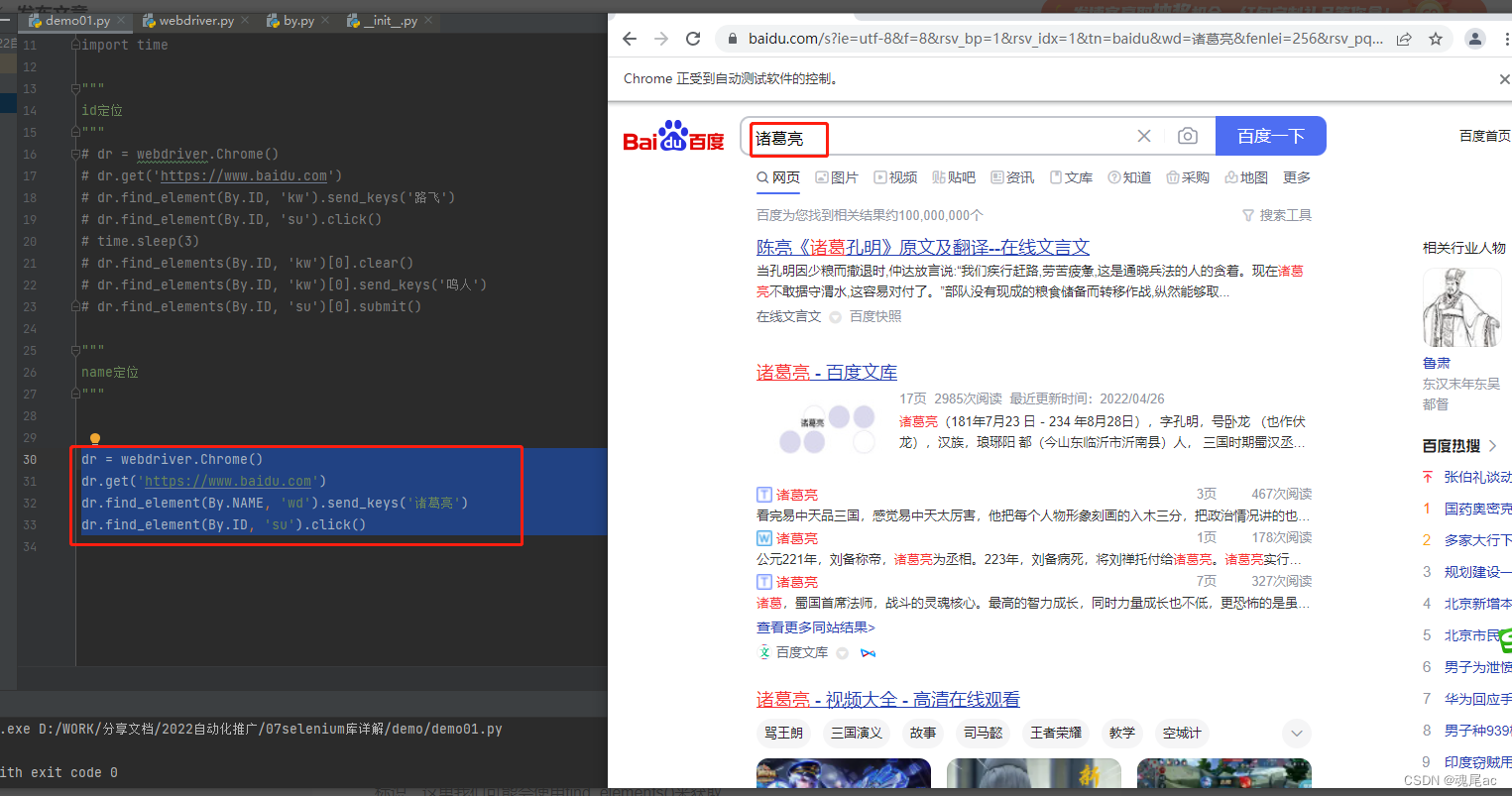
还是进入百度,搜索’诸葛亮’
可以通过 f12在html里知道百度搜索框的name是wd,搜索按钮的id是su
所以编写代码如下:(在上面已经导包了,下面的代码就不导包了)
dr = webdriver.Chrome()
dr.get('https://www.baidu.com')
dr.find_element(By.NAME, 'wd').send_keys('诸葛亮')
dr.find_element(By.ID, 'su').click()可以见输入诸葛亮这条语句查询元素方法find_element参数一由 By.NAME表示用name定位,参数二也是取name的值wd
代码执行如下
3.3、Class
网页HTML一般都会有class属性,前端开发者会用其来归类批量添加样式,所以它可能不是唯一的标识。这里我们可能会使用find_elements()来获取
举例:
进入CSDN,点击分类
使用f12查看CSDN的HTML,发现在所有分类元素的class均是navigation-right
所以代码编写如下
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
#点击第一个分类
dr.find_elements(By.CLASS_NAME, 'navigation-right')[0].click()
#等待3秒
time.sleep(3)
#点击第一个分类
dr.find_elements(By.CLASS_NAME, 'navigation-right')[1].click()可以见点击查询元素方法find_element参数一由 By.CLASS_NAME表示了要取class定位,参数二则是给出class的值
代码执行如下

3.4、tag
tag是网页HTML中的标记,HTML由标记组成,一个标记就是一个元素,所以它基本上不会唯一,所以也使用find_elemenets()来获取
举例:
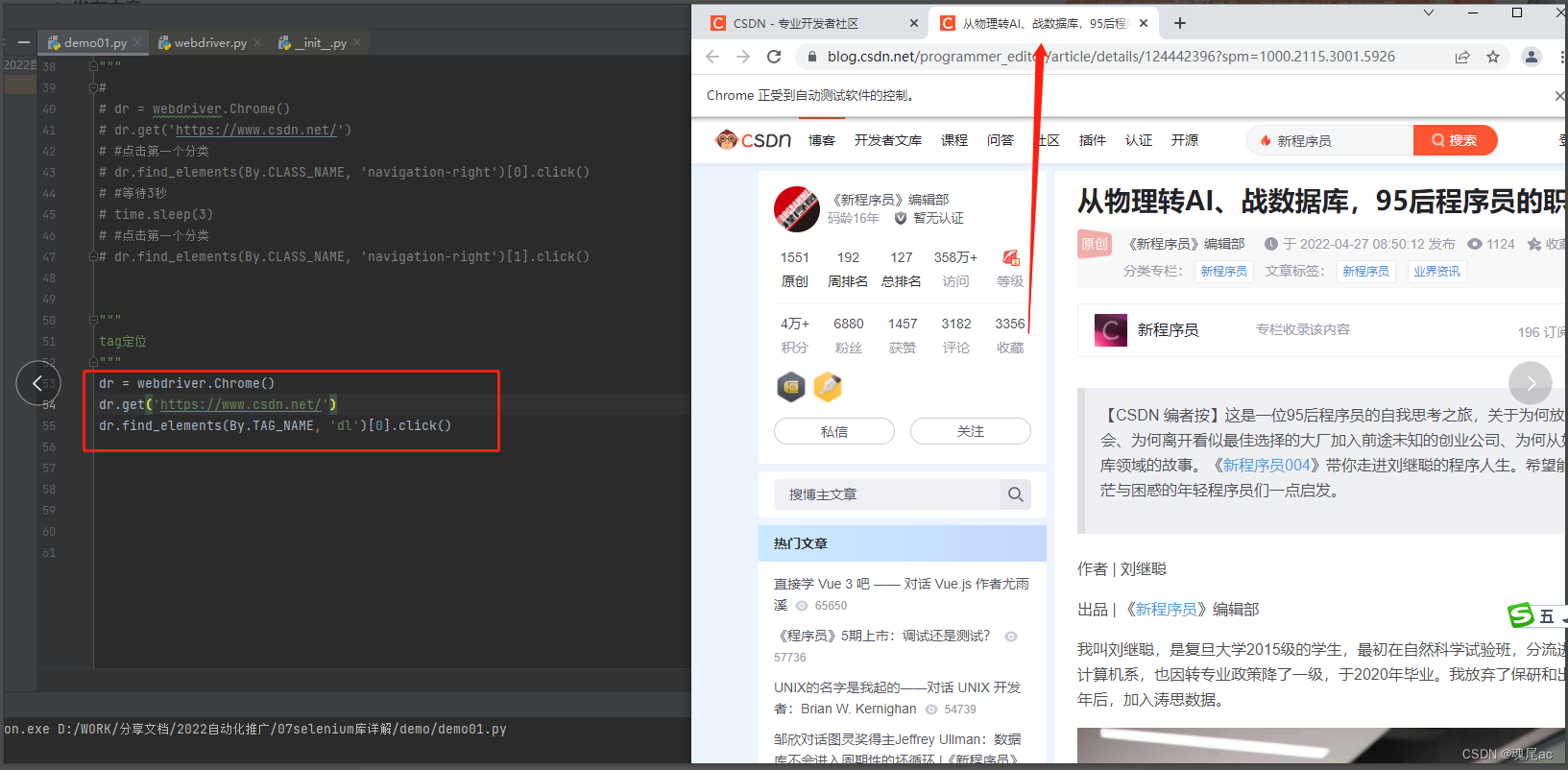
进入CSDN,点击头条新闻
使用F12查看CSDN的HTML,发现头条新闻的分类元素的标签是dl
所以代码编写如下
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_elements(By.TAG_NAME, 'dl')[0].click()可以见点击查询元素方法find_element参数一由 By.TAG_NAME表示了要取tag定位,参数二则是给出tag名
代码执行结果如下
3.5、Link
Link表示包含有属性href = “https://www.xxxxxxx.com”元素,可以通过linktext定位,linktext是页面上展示的文字。它还可以部分linktext定位。
网上很多文章将linktext通过全linktext与部分linktext区分为两种定位方式,没有本文最后的JS定位方式,也是对的。
举例:
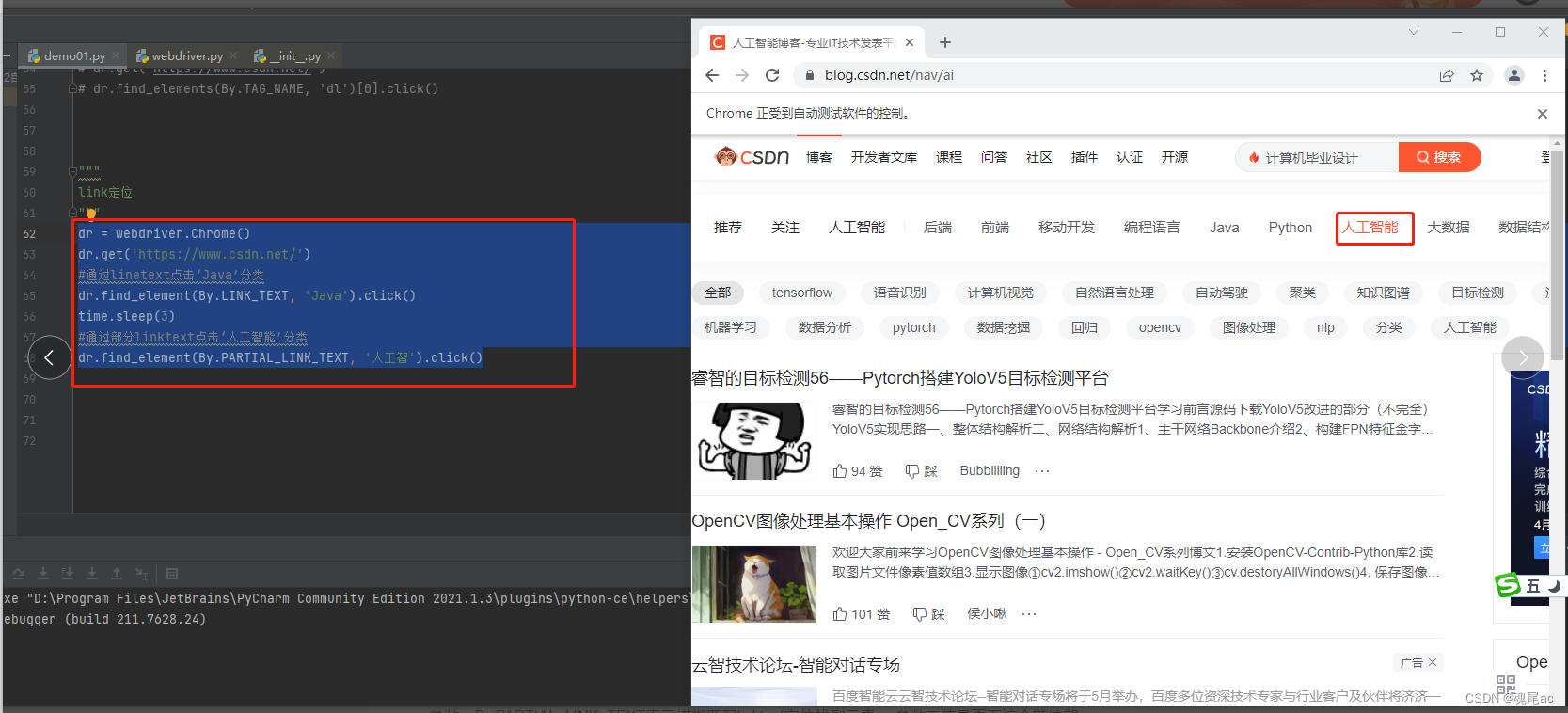
进入CSDN,点击分类
使用F12查看CSDN的HTML,发现分类都是有href属性的,可以用linktext定位
所以代码编写如下:
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
#通过linetext点击‘Java’分类
dr.find_element(By.LINK_TEXT, 'Java').click()
time.sleep(3)
#通过部分linktext点击‘人工智能’分类
dr.find_element(By.PARTIAL_LINK_TEXT, '人工智').click()参数一By.LINK_TEXT表示全部匹配linktext定位找到元素,参数二值是页面这个链接的全部文案‘Java’
参数一By.PARTIAL_LINK_TEXT表示模糊匹配linktext定位找到元素 ,参数二值是页面这个链接部分文案‘人工智’
代码执行结果如下
3.6、xpath
xpath是XML路径定位器,HTML与XML相似,所以也可以用xpath来定位,这个相对于前面的来说,需要大家掌握一些xpath的理论知识。
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| . . | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 任何元素 |
xpath定位逻辑是通过id、name、class等属性定位到一个大范围元素然后再通过路 径 定位到精准元素;针对定位到多个元素时也可以下标取值,但下标从1开始。可以 用 xpath定位到任何元素
表格的内容弄懂后,但并不一定会用到,懂了是让自己知道xpath是如何定位的;实战中基本上用到xpath定位时,一般使用浏览器f12里面copy xpath功能,获取到对应元素的xpath(老手一般是自己写xpath,因为F12有时复制的xpath不是最精简的)
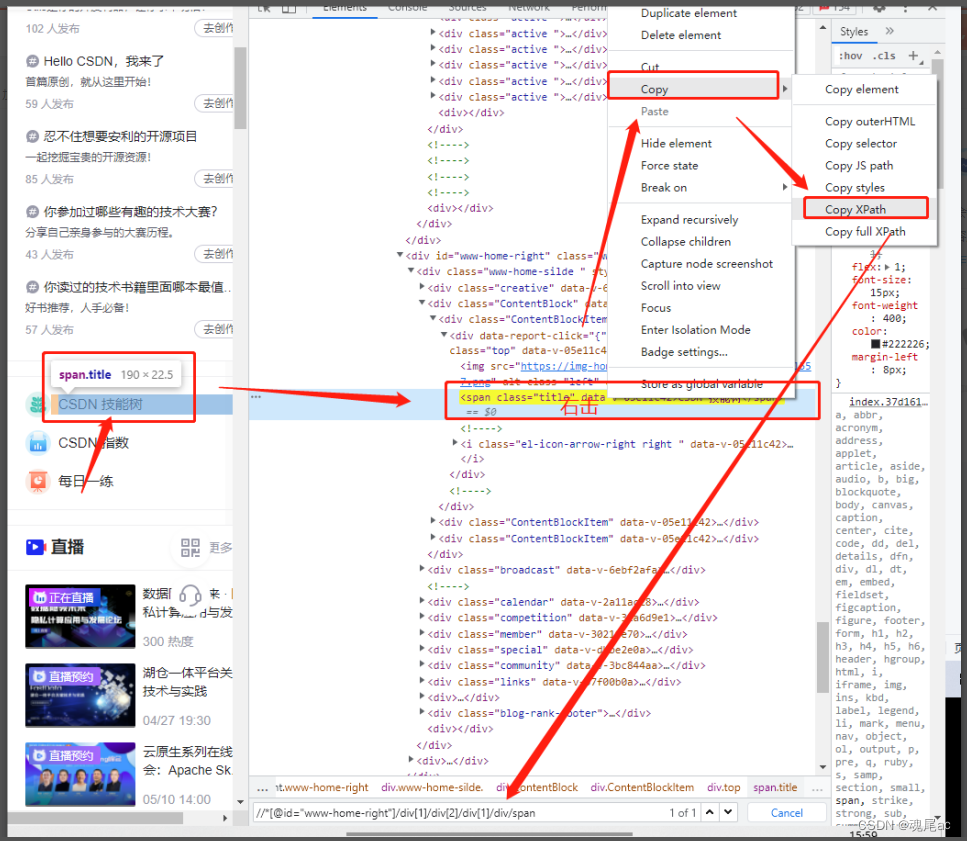
比如我要获取CSDN技术树元素的xpath,只需要按照下图箭头的顺序点击,即可获取到对应的xpath了
然后用基来举例:
举例:
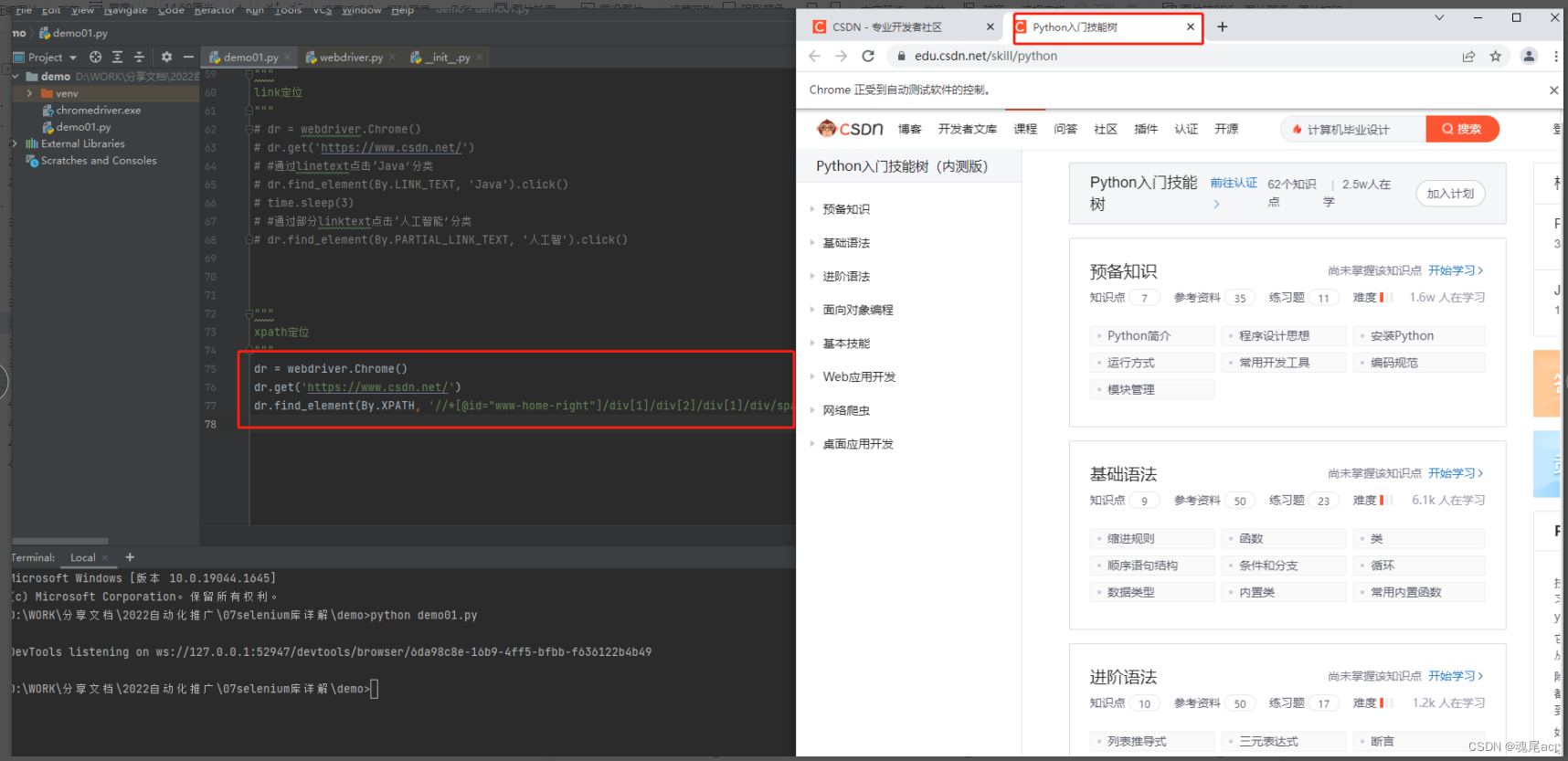
进入CSDN,点击技能树元素
通过F12里的copy xpath功能可以知道技能树元素的xpath为//*[@id="www-home-right"]/div[1]/div[2]/div[1]/div/span
所以代码编写如下
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_element(By.XPATH, '//*[@id="www-home-right"]/div[1]/div[2]/div[1]/div/span').click()参数一By.XPATH表示使用xpath方式定位,参数二是给元素xpath值
代码执行如下
3.7、css选择器
css是前端样式,这里说的css定位是用css样式里定位元素用的方法叫做css选择器。
符号.代表class, 符号 # 代表id, 路径空格写tag名
它与xpath一样,可以定位到任何元素,也可以直接通过F12的copy selector来取 得元素的css选择器
举例
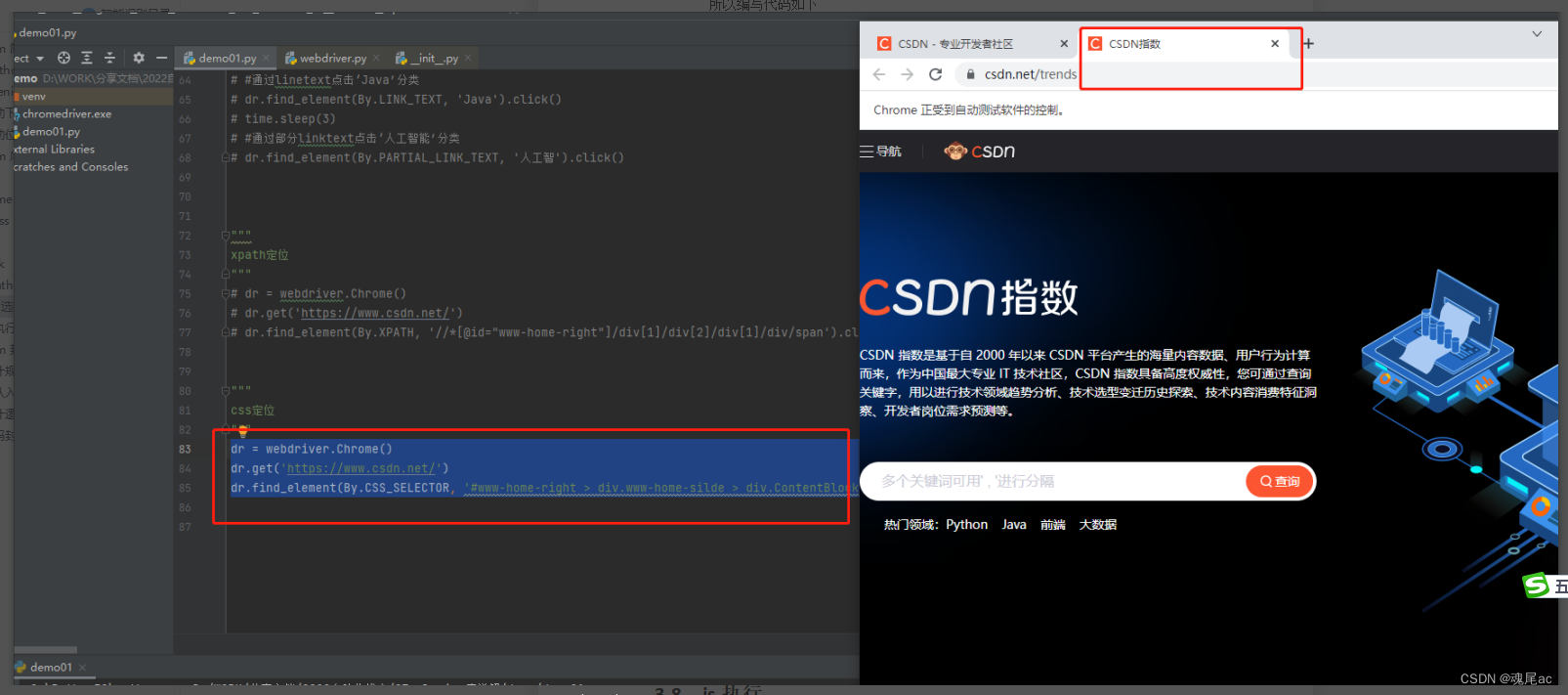
进入CSDN, 点击CSDN指数元素
通过f12里的copy selector取得元素的css选择器为:#www-home-right > div.www-home-silde > div.ContentBlock > div:nth-child(1) > div > span
所以代码编写如下
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_element(By.CSS_SELECTOR, '#www-home-right > div.www-home-silde > div.ContentBlock > div:nth-child(2) > div > span').click()参数一By.CSS_SELECTOR表示使用css方式定位,参数二是给元素css选择器
代码执行如下:
3.8、js执行
js不是定位器
js不是定位器
js不是定位器
js是javascript,是可以独以运行的脚本;不使用selenium的方法,进行页面元素的点击、输入、拖拽等等操作,像如果对js使用很熟练,那么也就完全不需要管上面的定位方式。全部可以使用js来实现页面元素的各种操作。
像滚动条拖拽是没法用元素定位操作的,只能使用js
举例:(新手经典问题)
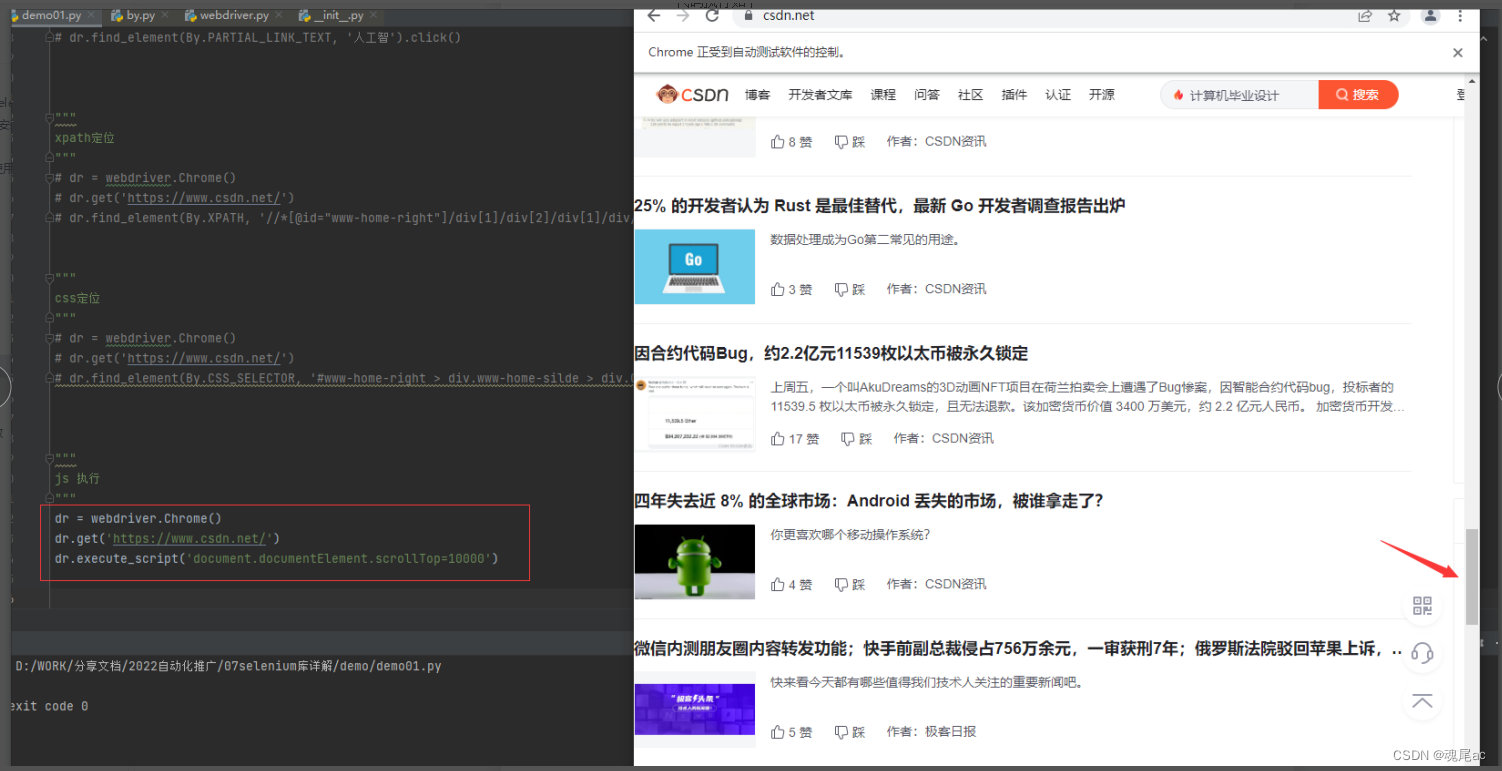
进入CSDN,拖拽滚动条
滚动条拖拽的js为document.documentElement.scrollTop=10000
代码编写如下
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.execute_script('document.documentElement.scrollTop=10000')使用exeute_script执行JS
代码执行如下
4、selenium封装
上面讲了selenium八大元素定位方式,但做自动化肯定不是一直写这样的python代码,因为时间与空间上都浪费人力,不如功能测试,所以我们需要学会去二次封装selenium。将其制定成规则化的自然代码来让自动化变得简单易懂。
4.1、设计规则
一、做自动化是模拟人的操作,所以有操作字段:点击、输入等
二、定位元素需要定位方式,所以有定位器字段:id、name、class、tag、link、plink、xpath、css、js
三、定位器有了,定位器的对象字段也要有
四、页面相同属性的元素有多个,所以需要一个下标字段
五、输入、下拉、检查需要值,所以值字段也需要一个
基本上暂时可以先确定这些字段:
operation、type、locatuion、index、value
4.2、确认入口函数
设计好五个参数后,基本上操作就只需要这五个参数了,所以需要一个统一入口函数,将这五个参数均带入其实。
def web_autotest_opr(operation, type, locatuion, index, value)
4.3、设计逻辑
一、封装浏览器打开功能,返回浏览器对象
二、封装入口函数
三、封装定位元素方式
四、封装元素操作方式
4.4、代码封装
from selenium import webdriver
from selenium.webdriver.common.by import By
def open_url(url):
'''
打开浏览顺访问url,并返回浏器操作句柄
:param url: 要测试的网站url
:return: webdriver对像
'''
opr = webdriver.Chrome()
opr.get(url)
return opr
def get_element(opr:webdriver.Chrome, type, locatuion, index):
'''
获取元素并返回
:param opr: 浏览器句柄
:param type: 定位器类型
:param locatuion: 定位器
:param index: 下标
:return: 元素对象
'''
if str.lower(type) == 'id':
return opr.find_elements(By.ID, locatuion)[index]
elif str.lower(type) == 'name':
return opr.find_elements(By.NAME, locatuion)[index]
elif str.lower(type) == 'class':
return opr.find_elements(By.CLASS_NAME, locatuion)[index]
elif str.lower(type) == 'tag':
return opr.find_elements(By.TAG_NAME, locatuion)[index]
elif str.lower(type) == 'link':
return opr.find_elements(By.LINK_TEXT, locatuion)[index]
elif str.lower(type) == 'plink':
return opr.find_elements(By.PARTIAL_LINK_TEXT, locatuion)[index]
elif str.lower(type) == 'xpath':
return opr.find_elements(By.XPATH, locatuion)[index]
elif str.lower(type) == 'css':
return opr.find_elements(By.CSS_SELECTOR, locatuion)[index]
def element_opr(el:webdriver.Chrome.find_element, operation, value):
'''
元素操作
:param el: 元素对象
:param operation: 操作类型
:param value: 值
:return: 成功(True)or失败(False)
'''
if operation == '点击':
el.click()
return True
elif operation == '输入':
el.send_keys(value)
return True
def web_autotest_opr(opr:webdriver.Chrome ,operation, type, locatuion, index=0, value=''):
'''
元素操作统一入口
:param opr: 浏览器句柄
:param operation: 操作类型
:param type: 定位器类型
:param locatuion: 定位器
:param index: 下标
:param value: 值
:return: 成功(True)or失败(False)
'''
if str.lower(type) != 'js':
el = get_element(opr, type, locatuion, index)
result = element_opr(el, operation, value)
else:
result = opr.execute_script(locatuion)
return result
这一部分属于UI自动化测试框架的核心部分的封装,当然逻辑肯定不止这些,并且上面这些代码是面向过程的,等大家有实力了,可以慢慢优化这些代码,尽量变成面向对象的。
想了解Web自动化框架的可以进入:Python 从无到有搭建WebUI自动化测试框架_魂尾ac的博客-CSDN博客_python ui自动化测试框架
文章出处登录后可见!