博客编写背景
本次博客是对深度学在机械设备的故障诊断(模式识别)领域的入门级的基础教程,主要是专门针对CWRU滚动轴承故障数据集的数据读取、数据集的划分进行展开。希望对初入故障诊断的大四毕业设计和研一的课题入门有一定的帮助。后续将会持续进行进阶的博客撰写和代码的编写。
数据集读取
不管是深度学习做寿命预测还是做故障诊断,我相信,难道初学者的第一步便是对数据集进行读取的操作以及进行振动信号的预处理如FFT、STFT、HHT、CWT;或者从一维时间序列转成二维图像等。本文主要是针对一维原始振动数据的读取。
对于CWRU轴承数据集,有不同的载荷工况、不同故障类型、同一故障类型又有不同的故障程度。因此,一般进行故障诊断,基础的就是对不同的故障进行分类识别,进阶的就是扩充每一种故障类别的严重程度。再然后就 涉及到不同工况的、甚至不同的数据集之间的迁移诊断。
下面将具体针对数据集的样本数量、长度、工况、故障程度灵活选取的实现展开。
(1)每一类故障样本的数量num;
(2)每一类故障样本的长度length;
(3)每一类故障样本的负载的大小hp;
(4)每一类故障样本的故障程度fault_diameter;
下面为定义的数据加载函数的部分代码
def load_data(num = 90,length = 1280,hp = [0,1,2],fault_diameter = [0.007,0.028],split_rate = [0.7,0.2,0.1]):
#num 为每类故障样本数量,length为样本长度,hp为负载大小,可取[0,1,2,3],fauit_diameter为故障程度,可取[0.007,0.014,0.021]
#split_rate为训练集,验证集和测试集划分比例。取值从0-1。
#bath_path1 为西储大学数据集中,正常数据的文件夹路径
#bath_path2 为西储大学数据集中,12K采频数据的文件夹路径
bath_path1 = r"D:\software\work\files\数据集\西储大学数据集\CWRU\Normal Baseline Data\\"
bath_path2 = r"D:\software\work\files\数据集\西储大学数据集\CWRU\12k Drive End Bearing Fault Data\\"
data_list = []
label = 0
(5)数据集划分
数据的划分,一般按照训练集、验证集、测试集这三种进行划分,本文推荐0.7,0.2,0.1的比例。
如果是采用Tensorflow或者keras,可以只需要划分出训练集和测试集,然后再调用model.fit函数时,使用vaildation_split,在训练集的基础上随机划分出0.05-0.30的数据作为验证集。注意测试集不能参与训练以及模型的验证,否则就算是作弊。
最终处理的数据集均带有标签
train_data = train[:,0:length]
train_label = np_utils.to_categorical(train[:,length],len(hp)*(1+3*len(fault_diameter)))
eval_data = eval[:,0:length]
eval_label = np_utils.to_categorical(eval[:,length],len(hp)*(1+3*len(fault_diameter)))
test_data = test[:,0:length]
test_label = np_utils.to_categorical(test[:,length],len(hp)*(1+3*len(fault_diameter)))
return train_data,train_label,eval_data,eval_label,test_data,test_label
训练与测试
(1)损失函数: 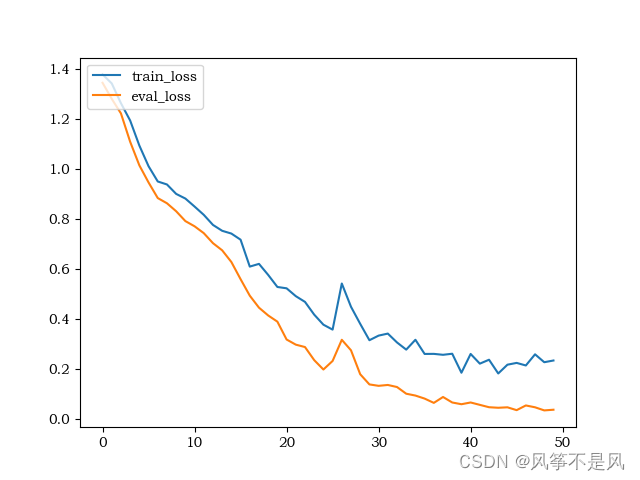
(2)准确率:
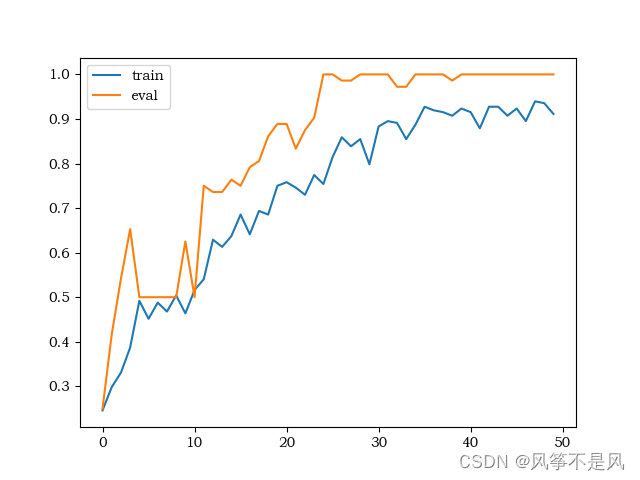
(3)测试集可视化:
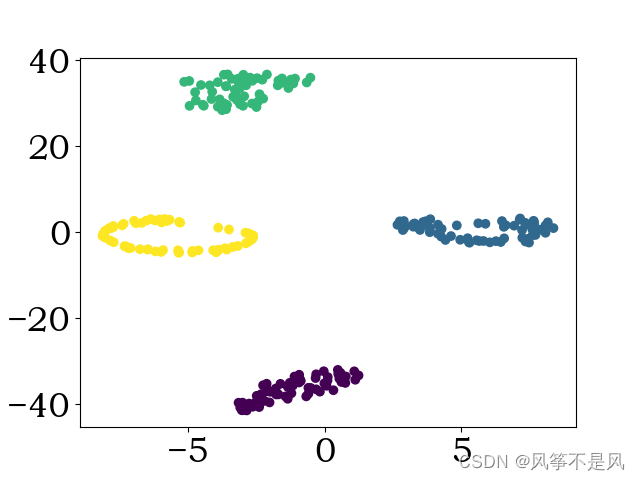
完整数据读取代码
import random
import numpy as np
import scipy.io as scio
from sklearn import preprocessing
from keras.utils import np_utils
def deal_data(data,length,label):
data = np.reshape(data,(-1))
num = len(data)//length
data = data[0:num*length]
data = np.reshape(data,(num,length))
min_max_scaler = preprocessing.MinMaxScaler()
data = min_max_scaler.fit_transform(np.transpose(data,[1,0]))
data = np.transpose(data,[1,0])
label = np.ones((num,1))*label
return np.column_stack((data,label))
def open_data(bath_path,key_num):
path = bath_path + str(key_num) + ".mat"
str1 = "X" + "%03d"%key_num + "_DE_time"
data = scio.loadmat(path)
data = data[str1]
return data
def split_data(data,split_rate):
length = len(data)
num1 = int(length*split_rate[0])
num2 = int(length*split_rate[1])
index1 = random.sample(range(num1),num1)
train = data[index1]
data = np.delete(data,index1,axis=0)
index2 = random.sample(range(num2),num2)
eval = data[index2]
test = np.delete(data,index2,axis=0)
return train,eval,test
def load_data(num = 90,length = 1280,hp = [0,1,2],fault_diameter = [0.007,0.028],split_rate = [0.7,0.2,0.1]):
#num 为每类故障样本数量,length为样本长度,hp为负载大小,可取[0,1,2,3],fauit_diameter为故障程度,可取[0.007,0.014,0.021]
#split_rate为训练集,验证集和测试集划分比例。取值从0-1。
#bath_path1 为西储大学数据集中,正常数据的文件夹路径
#bath_path2 为西储大学数据集中,12K采频数据的文件夹路径
bath_path1 = r"D:\software\work\matlab\files\数据集\西储大学数据集\CWRU\Normal Baseline Data\\"
bath_path2 = r"D:\software\work\matlab\files\数据集\西储大学数据集\CWRU\12k Drive End Bearing Fault Data\\"
data_list = []
label = 0
for i in hp:
#正常数据
#path1 = bath_path1 + str(97+i) + ".mat"
#normal_data = scio.loadmat(path1)
#str1 = "X0" + str(97+i) + "_DE_time"
normal_data = open_data(bath_path1,97+i)
data = deal_data(normal_data,length,label = label)
data_list.append(data)
#故障数据
for j in fault_diameter:
if j == 0.007:
inner_num = 105
ball_num = 118
outer_num = 130
elif j == 0.014:
inner_num = 169
ball_num = 185
outer_num = 197
else:
inner_num = 209
ball_num = 222
outer_num = 234
inner_data = open_data(bath_path2,inner_num + i)
inner_data = deal_data(inner_data,length,label + 1)
data_list.append(inner_data)
ball_data = open_data(bath_path2,ball_num + i)
ball_data = deal_data(ball_data,length,label + 2)
data_list.append(ball_data)
outer_data = open_data(bath_path2,outer_num + i)
outer_data = deal_data(outer_data,length,label + 3)
data_list.append(outer_data)
label = label + 4
#保持每类数据数据量相同
num_list = []
for i in data_list:
num_list.append(len(i))
min_num = min(num_list)
if num > min_num:
print("每类数量超出上限,最大数量为:%d" %min_num)
min_num = min(num,min_num)
#划分训练集,验证集和测试集,并随机打乱顺序
train = []
eval = []
test = []
for data in data_list:
data = data[0:min_num,:]
a,b,c = split_data(data,split_rate)
train.append(a)
eval.append(b)
test.append(c)
train = np.reshape(train,(-1,length+1))
train = train[random.sample(range(len(train)),len(train))]
train_data = train[:,0:length]
train_label = np_utils.to_categorical(train[:,length],len(hp)*(1+3*len(fault_diameter)))
eval = np.reshape(eval,(-1,length+1))
eval = eval[random.sample(range(len(eval)),len(eval))]
eval_data = eval[:,0:length]
eval_label = np_utils.to_categorical(eval[:,length],len(hp)*(1+3*len(fault_diameter)))
test = np.reshape(test,(-1,length+1))
test = test[random.sample(range(len(test)),len(test))]
test_data = test[:,0:length]
test_label = np_utils.to_categorical(test[:,length],len(hp)*(1+3*len(fault_diameter)))
return train_data,train_label,eval_data,eval_label,test_data,test_label
文章出处登录后可见!
已经登录?立即刷新