参考这篇文章,本文会加一些注解。
源自paper: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
ViT把tranformer用在了图像上, transformer的文章: Attention is all you need
ViT的结构如下:
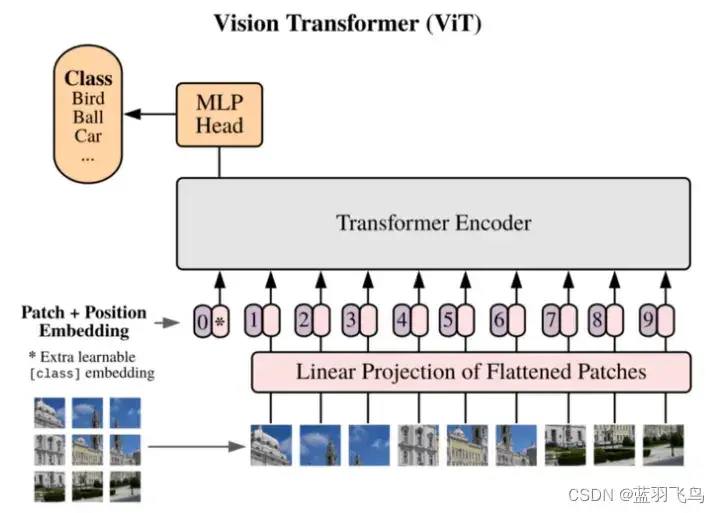
可以看到是把图像分割成小块,像NLP的句子那样按顺序进入transformer,经过MLP后,输出类别。
每个小块是16×16,进入Linear Projection of Flattened Patches, 在每个的开头加上cls token位置信息,
也就是position embedding。
从下而上实现,position embedding, Transformer, Head, Vit的顺序。
首先import
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
image输入要是224x224x3, 所以先reshape一下
# resize to imagenet size
transform = Compose([Resize((224, 224)), ToTensor()])
x = transform(img)
x = x.unsqueeze(0) # add batch dim
x.shape
这是shape是[1, 3, 224, 224]
把图片分成小块

patch_size = 16 # 16 pixels
pathes = rearrange(x, 'b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size)
rearrange里面的(h s1)表示hxs1,而s1是patch_size=16, 那通过hx16=224可以算出height里面包含了h个patch_size,
同理算出weight里面包含了w个patch_size。
然后输出是b (h w) (s1 s2 c),这相当于把每个patch(16x16x3)拉成一个向量,每个batch里面有hxw个这样的向量。
就相当于上图一字排开有hxw个小块。
然后把这些小块放进Linear layer改变每条向量的维度。

上面这些可以写成一个class,用conv2代替linear layer提高计算效率,把拉成的一条向量维度变成e
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# break-down the image in s1 x s2 patches and flat them
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size),
nn.Linear(patch_size * patch_size * in_channels, emb_size)
)
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return x
PatchEmbedding()(x).shape
torch.Size([1, 196, 768])
CLS token
要在刚刚的patch向量中加入cls token和每个patch所在的位置信息,也就是position embedding。
cls token就是每个sequence开头的一个数字。
一张图片的一串patch是一个sequence, 所以cls token就加在它们前面,embedding_size的向量copy batch_size次。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.proj = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.proj(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# prepend the cls token to the input
x = torch.cat([cls_tokens, x], dim=1)
return x
PatchEmbedding()(x).shape
这时的shape是torch.Size([1, 197, 768]),而加cls token之前是torch.Size([1, 196, 768]),可以参考下面的图。
Position embedding
要在每个patch向量前面加上位置信息,但是具体怎么加位置,ViT中这个位置信息是通过学习得到的,
下图中的 * 就是cls token, 然后包含cls, 每个patch前都要加一个位置。
所以加的位置信息为:小图像块的个数+1 (位置0)
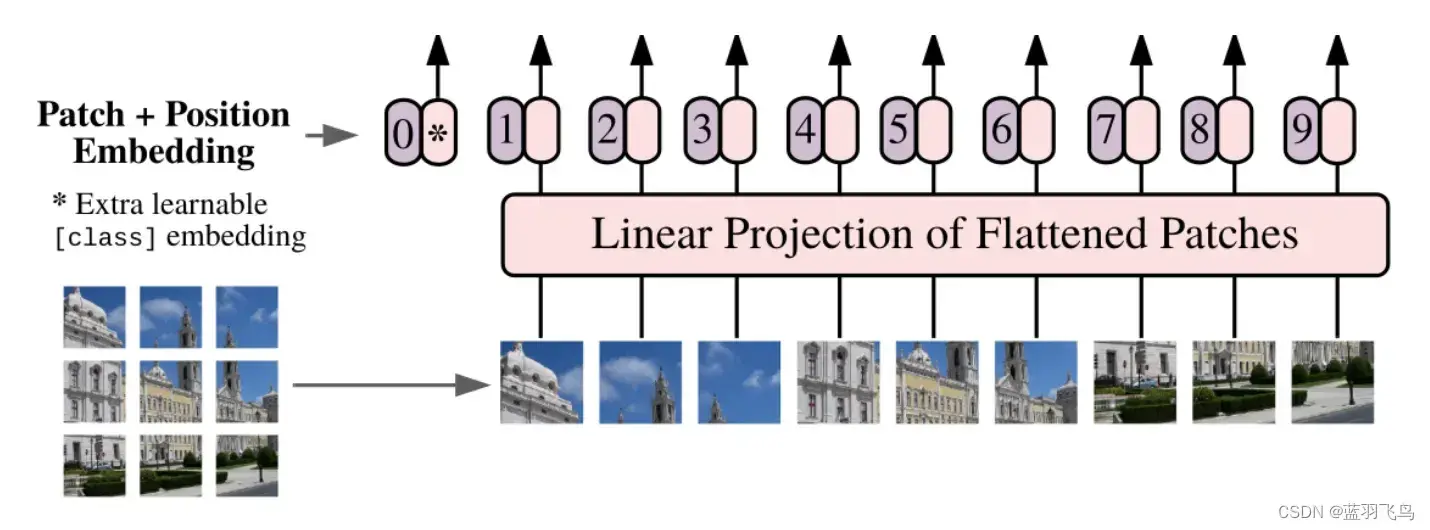
于是在Position embedding class里面再加几句,position是直接加的。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
#img size是长和宽相等的,所以img_size//patch_size就是长和宽有多少个patch + 1(位置0)
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# prepend the cls token to the input
x = torch.cat([cls_tokens, x], dim=1)
# add position embedding
x += self.positions
return x
PatchEmbedding()(x).shape
这时的size是torch.Size([1, 197, 768])
下一步就要实现transformer了,但是只需要encoder部分,它的结构如下
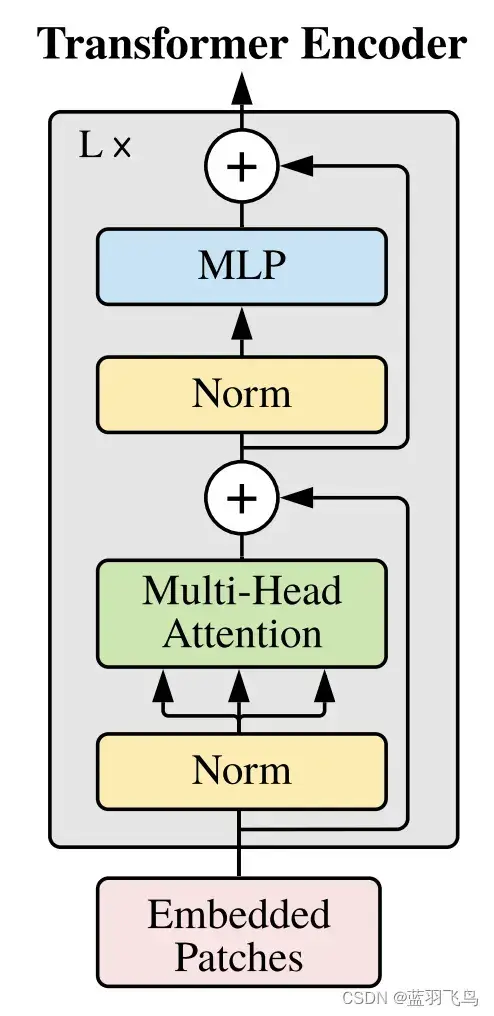
先从Attention开始吧
Attention

Attention有3个输入:query, key. value
利用query和value计算attention矩阵, 这个矩阵用来给value注意力机制。
多头注意力有n个heads同时计算。
实现上可以用pytorch自带的nn.MultiHeadAttention, 也可以自己实现。
为了了解里面的细节,自己来实现一下。
要参考一下transformer的结构。
需要4个FC layer,其中3个给query, key,value, 1个给后面的dropout。
整体流程如下:
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 512, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.num_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.num_heads)
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
下面会解释上面这段代码。
因为要用多头注意力机制,所以要把query, key, value resize成对应多头的形状,
这个用到einops.rearrange,
query, key, value的shape通常是相同的,这里只有一个input x。
对应这几句
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.n_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.n_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.n_heads)
最后的size (b h n d)是指(batch, heads, sequence_len, embedding_size)
回忆一下attention matrix的计算方法
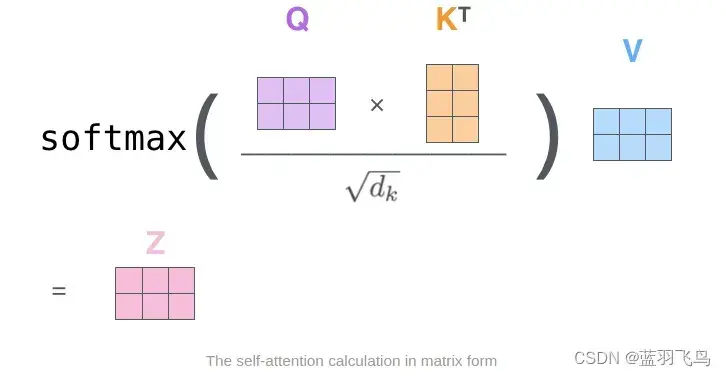
首先要把query和key矩阵乘,除一个scaling, softmax, 再和value矩阵乘
‘bhqd, bhkd -> bhqk’这个看成矩阵的shape,(b,h,q,d)的矩阵 ✖ (b,h,k.d)的矩阵
qxd ✖ (kxd 的转置) -> qxk
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys)
att = F.softmax(energy, dim=-1) / scaling
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
输出的shape就是(batch, head, values_len)
或者把query, key, value写到一个矩阵qkv,如下
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# fuse the queries, keys and values in one matrix
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
patches_embedded = PatchEmbedding()(x)
MultiHeadAttention()(patches_embedded).shape
Residuals
对应下面这一块
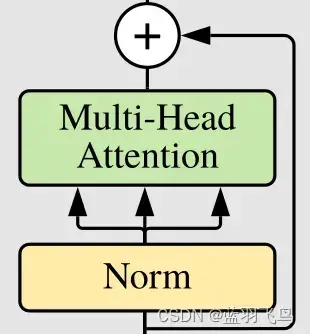
因为residual在后面还会用,直接写成可传入函数的形式,后面会比较方便
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
这个attention的输出会输入到Norm和MLP
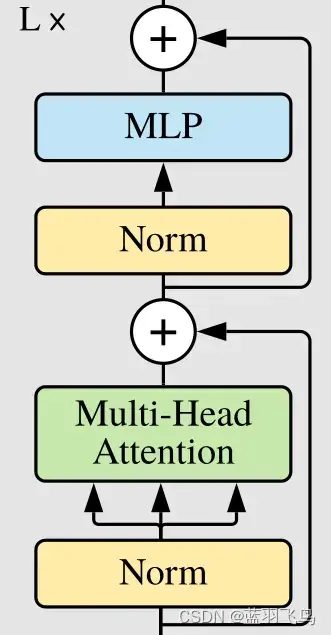
MLP是多层感知器,结构如下
其实就是两个linear, 改变一下维度
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)
现在来把transformer中的encoder block整合
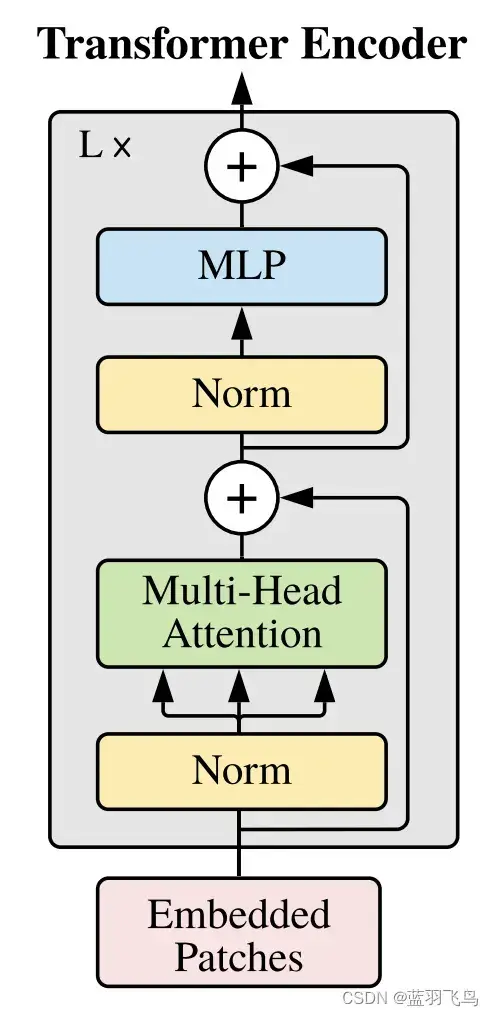
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
测一下
patches_embedded = PatchEmbedding()(x)
TransformerEncoderBlock()(patches_embedded).shape
这时的输出是torch.Size([1, 197, 768])
最后一层是预测每个class的probability,
整个sequence会先通过一个计算mean的模块
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
ViT
把上面的模块组合起来就成了ViT
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
文章出处登录后可见!