@爱学习的DUO
- merge()表示将【左表】和【右表】,按某个均有的字段,进行横向匹配。
1 数据读取(A、B表)
import pandas as pd
A = pd.read_excel('D:/pp/test.xlsx','Sheet1');A
B = pd.read_excel('D:/pp/test.xlsx','Sheet2');B
- A表(左),B表(右)
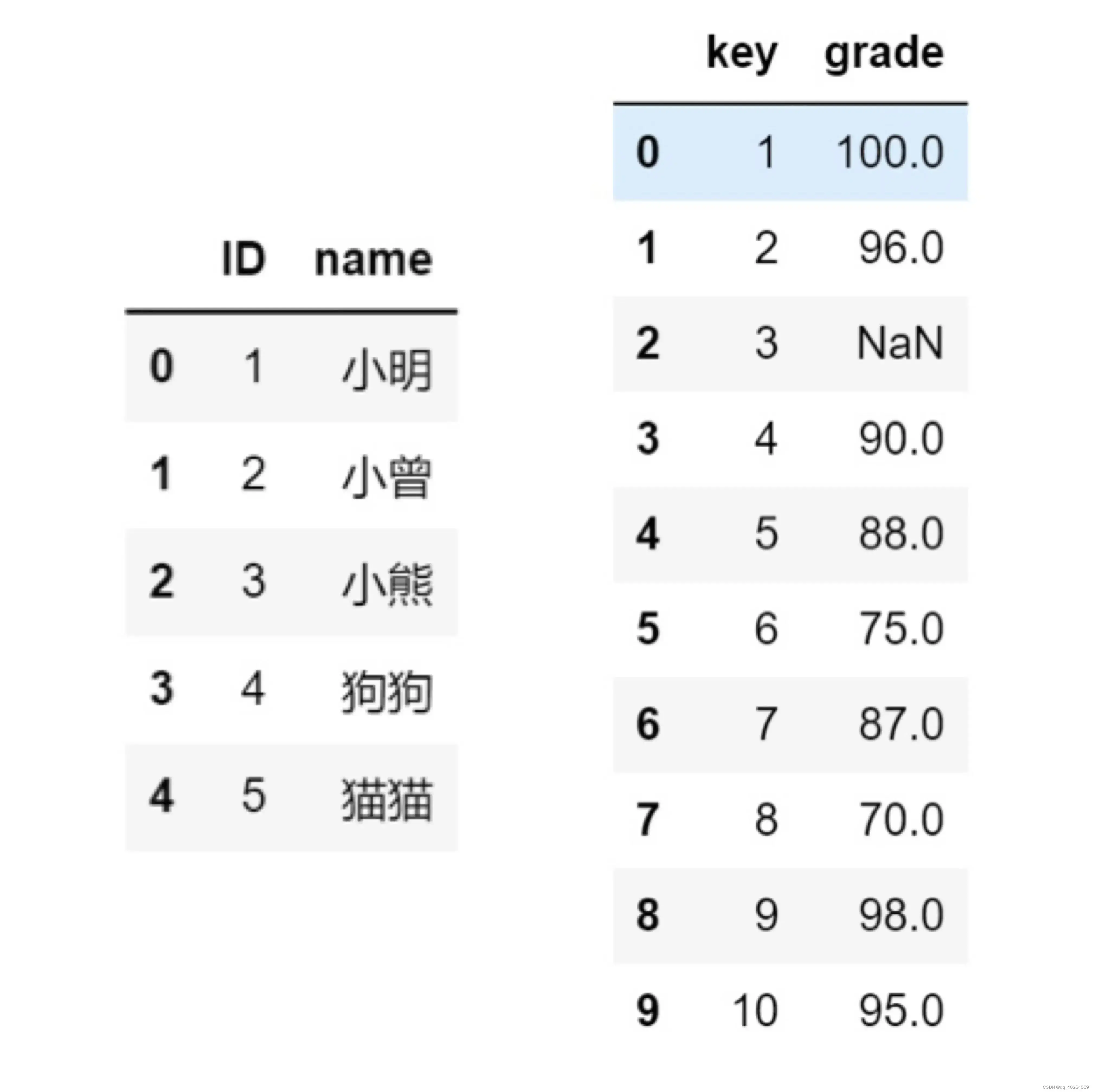
2 当右表无重复项
例1:有A(5行)、B(10行)两个表,按ID和key进行横向匹配。
(1)首先把B表的列名字【key】改为【ID】,以便于后续匹配。
B=B.rename(columns={'key':'ID'});B
(2)用B表去匹配A表(参数=‘left’)。
AB=pd.merge(A,B,on = ['ID'],how='left');AB
- 结果(左表多少行,匹配结果就多少行)
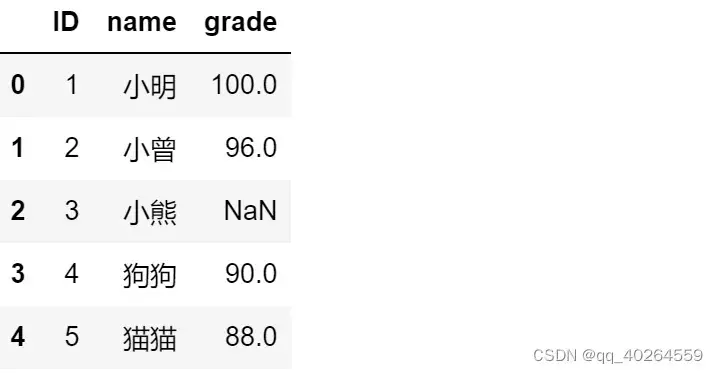
(3)用A表去匹配B表(参数=‘left’)。
BA=pd.merge(B,A,on = ['ID'],how='left');BA
- 结果(左表多少行,匹配结果就多少行)
3 当右表有重复项
3.1 数据读取(C表)
C = pd.read_excel('D:/pp/test.xlsx','Sheet3');C
- 结果

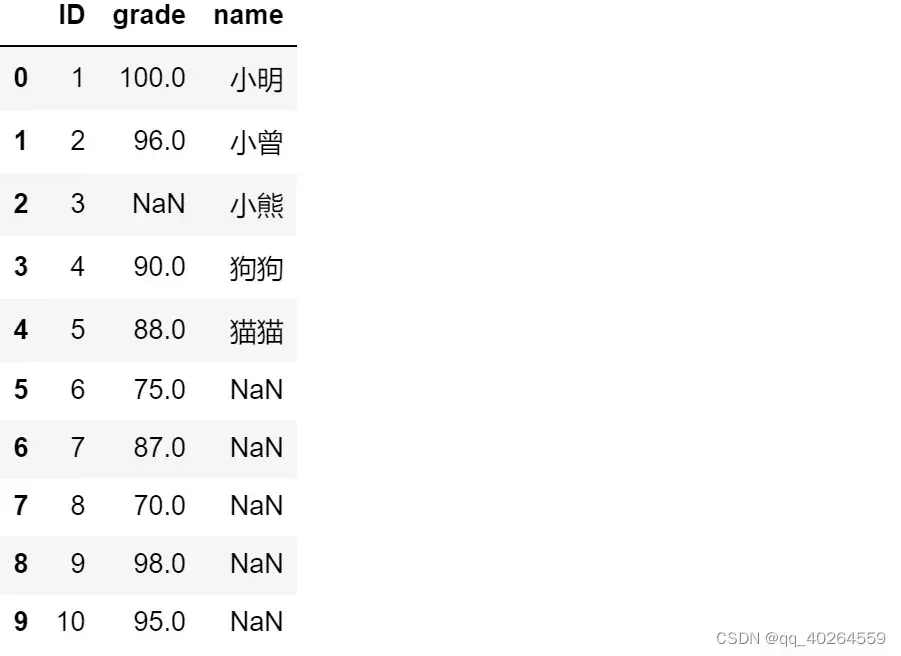
3.2 不对右表去重
AC=pd.merge(A,C,on = ['ID'],how='left');AC
- 结果(发现左表行数增多)
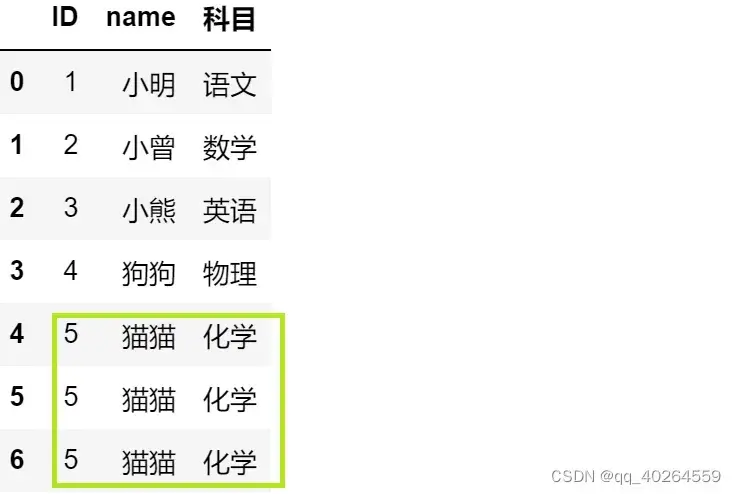
3.3 对右表去重处理
(1)对C表的ID去重,重命名为C_qc
C_qc=C.drop_duplicates(['ID'])
C_qc
- 去重的C表(C_qc)

(2) 使用C表去匹配A表(参数=left)
AC1=pd.merge(A,C_qc,on = ['ID'],how='left');AC1
- 结果

3.4 总结
可以看出,使用merge函数的时候,如果右表有重复值,会导致结果的不准确。所以一般对右表做去重处理,再与左表进行横向匹配。
文章出处登录后可见!
已经登录?立即刷新