前言
本文源码大部分是采用的OpenCV实战(一)——简单的车牌识别这篇文章所提供的代码,对其代码进行了整合,追加了HSV、tesseract-OCR等内容。大佬文章中有对其步骤的详细讲解和分析,本文只是在原有基础上,进行了拓展和改造,细节内容可直接参考大佬的博文。由于大佬没有提供完整项目和模型,我这进行了自己简单的数据集构建和模型训练。
Windows tesseract-OCR 的安装和简单测试
ps:所有图片素材均源自网络,如果侵权可私信,立删。
开发环境:
- pycharm-2020
- python-3.8.5
- opencv-python-4.5.4.58
- matplotlib-3.5.0
- pip-21.2.3
- Tesseract-OCR-5.0.0
- numpy-1.21.4
- sklearn-0.0.0
- joblib-1.1.0
工程下载
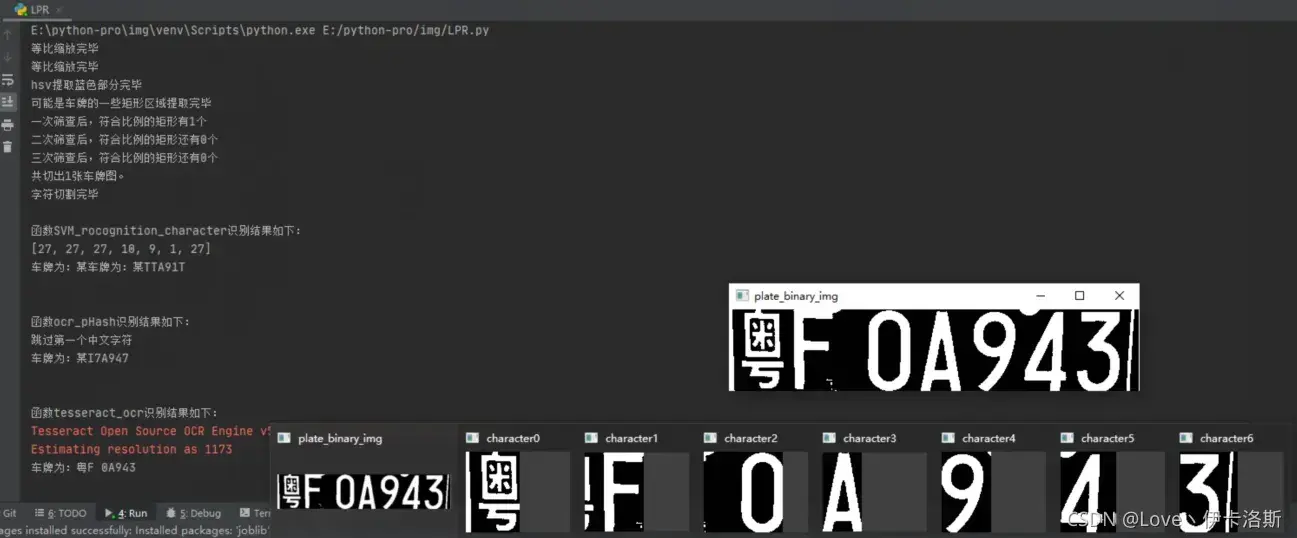
效果图

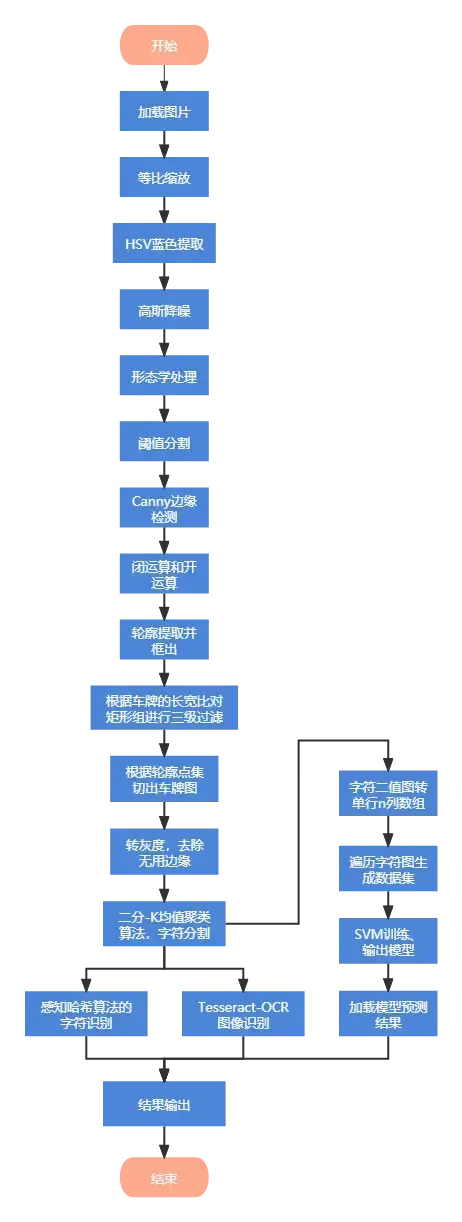
简易流程图
源码
import cv2
import numpy as np
import matplotlib.pyplot as plt
import os
import time
import sklearn
# import pytesseract
# 开发环境 pycharm python-3.8.5 opencv-python-4.5.4.58 matplotlib-3.5.0 pip-21.2.3 Tesseract-OCR-5.0.0
# 参考:https://blog.csdn.net/weixin_41695564/article/details/79712393
# 该函数能够读取磁盘中的图片文件,默认以彩色图像的方式进行读取
def imread_photo(filename, flags=cv2.IMREAD_COLOR):
"""
该函数能够读取磁盘中的图片文件,默认以彩色图像的方式进行读取
输入: filename 指的图像文件名(可以包括路径)
flags用来表示按照什么方式读取图片,有以下选择(默认采用彩色图像的方式):
IMREAD_COLOR 彩色图像
IMREAD_GRAYSCALE 灰度图像
IMREAD_ANYCOLOR 任意图像
输出: 返回图片的通道矩阵
"""
return cv2.imread(filename, flags)
# 等比缩放 参考:https://blog.csdn.net/JulyLi2019/article/details/120720752
def resize_keep_aspectratio(image_src, dst_size):
src_h, src_w = image_src.shape[:2]
# print(src_h, src_w)
dst_h, dst_w = dst_size
# 判断应该按哪个边做等比缩放
h = dst_w * (float(src_h) / src_w) # 按照w做等比缩放
w = dst_h * (float(src_w) / src_h) # 按照h做等比缩放
h = int(h)
w = int(w)
if h <= dst_h:
image_dst = cv2.resize(image_src, (dst_w, int(h)))
else:
image_dst = cv2.resize(image_src, (int(w), dst_h))
h_, w_ = image_dst.shape[:2]
# print(h_, w_)
print('等比缩放完毕')
return image_dst
# 这个函数的作用就是来调整图像的尺寸大小,当输入图像尺寸的宽度大于阈值(默认1000),我们会将图像按比例缩小
def resize_photo(imgArr, MAX_WIDTH=1000):
"""
这个函数的作用就是来调整图像的尺寸大小,当输入图像尺寸的宽度大于阈值(默认1000),我们会将图像按比例缩小
输入: imgArr是输入的图像数字矩阵
输出: 经过调整后的图像数字矩阵
拓展:OpenCV自带的cv2.resize()函数可以实现放大与缩小,函数声明如下:
cv2.resize(src, dsize[, dst[, fx[, fy[, interpolation]]]]) → dst
其参数解释如下:
src 输入图像矩阵
dsize 二元元祖(宽,高),即输出图像的大小
dst 输出图像矩阵
fx 在水平方向上缩放比例,默认值为0
fy 在垂直方向上缩放比例,默认值为0
interpolation 插值法,如INTER_NEAREST,INTER_LINEAR,INTER_AREA,INTER_CUBIC,INTER_LANCZOS4等
"""
img = imgArr
rows, cols = img.shape[:2] # 获取输入图像的高和宽
# 如果宽度大于设定的阈值
if cols > MAX_WIDTH:
change_rate = MAX_WIDTH / cols
img = cv2.resize(img, (MAX_WIDTH, int(rows * change_rate)), interpolation=cv2.INTER_AREA)
return img
# hsv提取蓝色部分
def hsv_color_find(img):
img_copy = img.copy()
"""
提取图中的蓝色部分 hsv范围可以自行优化
"""
hsv = cv2.cvtColor(img_copy, cv2.COLOR_BGR2HSV)
low_hsv = np.array([100, 80, 80])
high_hsv = np.array([124, 255, 255])
# 设置HSV的阈值
mask = cv2.inRange(hsv, lowerb=low_hsv, upperb=high_hsv)
cv2.imshow("hsv_color_find", mask)
# 将掩膜与图像层逐像素相加
res = cv2.bitwise_and(img_copy, img_copy, mask=mask)
cv2.imshow("hsv_color_find2", res)
print('hsv提取蓝色部分完毕')
return res
# 找到可能是车牌的一些矩形区域
def predict(imageArr):
"""
这个函数通过一系列的处理,找到可能是车牌的一些矩形区域
输入: imageArr是原始图像的数字矩阵
输出:gray_img_原始图像经过高斯平滑后的二值图
contours是找到的多个轮廓
"""
img_copy = imageArr.copy()
img_copy = hsv_color_find(img_copy)
# RGB->灰度
gray_img = cv2.cvtColor(img_copy, cv2.COLOR_BGR2GRAY)
# 该函数将源图像转换为指定的高斯核。支持就地过滤。
gray_img_ = cv2.GaussianBlur(gray_img, (5, 5), 0, 0, cv2.BORDER_DEFAULT)
kernel = np.ones((23, 23), np.uint8)
# 使用侵蚀和膨胀作为基本操作来执行高级形态转换。任何操作都可以就地完成.在多通道图像的情况下,每个通道都是独立处理的.
img_opening = cv2.morphologyEx(gray_img, cv2.MORPH_OPEN, kernel)
# 计算两个数组的加权和
img_opening = cv2.addWeighted(gray_img, 1, img_opening, -1, 0)
cv2.imshow("img_opening", img_opening)
# 该函数将固定电平阈值应用于多通道阵列.该函数通常用于从灰度图像中获取双级(二进制)图像(比较也可用于此目的)或消除噪声,即滤除值过小或过大的像素。
ret, img_thresh = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
ret2, img_thresh2 = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY)
cv2.imshow("img_thresh", img_thresh)
cv2.imshow("img_thresh2", img_thresh2)
# 该函数在输入图像中查找边缘,并使用Canny算法在输出映射边缘进行标记。阈值1和阈值2之间的最小值用于边缘连接。最大值用于寻找强边的初始段。
img_edge = cv2.Canny(img_thresh, 100, 200)
# cv2.imshow("img_edge", img_edge)
# # 使用开运算和闭运算让图像边缘成为一个整体
# kernel = np.ones((10, 10), np.uint8)
# 30*30 矩形 其大小需要根据 车牌在图片中宽度的占比和图片像素进行转换, 简测下来大概是 ( 宽占比 * 原图宽像素 / 10 ) 例 0.6 * 500 / 10 = 30
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (10, 10))
img_edge1 = cv2.morphologyEx(img_edge, cv2.MORPH_CLOSE, kernel)
img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel)
img_edge3 = cv2.morphologyEx(img_thresh2, cv2.MORPH_CLOSE, kernel)
img_edge4 = cv2.morphologyEx(img_edge3, cv2.MORPH_CLOSE, kernel)
# img_edge1 = cv2.morphologyEx(img_edge2, cv2.MORPH_CLOSE, kernel)
# img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel)
# cv2.imshow("img_edge1", img_edge1)
# cv2.imshow("img_edge2", img_edge2)
cv2.imshow("img_edge3", img_edge3)
cv2.imshow("img_edge4", img_edge4)
# 查找图像边缘整体形成的矩形区域,可能有很多,车牌就在其中一个矩形区域中
contours, hierarchy = cv2.findContours(img_edge2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours2, hierarchy2 = cv2.findContours(img_edge4, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# print("hierarchy:")
# print(hierarchy)
print('可能是车牌的一些矩形区域提取完毕')
return gray_img_, contours, contours2
# 根据findContours返回的contours 画出轮廓
def draw_contours(img, contours):
for c in contours:
x, y, w, h = cv2.boundingRect(c)
"""
传入一个轮廓图像,返回 x y 是左上角的点, w和h是矩形边框的宽度和高度
"""
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
"""
画出矩形
img 是要画出轮廓的原图
(x, y) 是左上角点的坐标
(x+w, y+h) 是右下角的坐标
0,255,0)是画线对应的rgb颜色
2 是画出线的宽度
"""
# 获得最小的矩形轮廓 可能带旋转角度
rect = cv2.minAreaRect(c)
# 计算最小区域的坐标
box = cv2.boxPoints(rect)
# 坐标规范化为整数
box = np.int0(box)
# 画出轮廓
cv2.drawContours(img, [box], 0, (0, 255, 0), 3)
cv2.imshow("contours", img)
# 根据车牌的一些物理特征(面积等)对所得的矩形进行过滤
def chose_licence_plate(contours, Min_Area=2000):
"""
这个函数根据车牌的一些物理特征(面积等)对所得的矩形进行过滤
输入:contours是一个包含多个轮廓的列表,其中列表中的每一个元素是一个N*1*2的三维数组
输出:返回经过过滤后的轮廓集合
拓展:
(1) OpenCV自带的cv2.contourArea()函数可以实现计算点集(轮廓)所围区域的面积,函数声明如下:
contourArea(contour[, oriented]) -> retval
其中参数解释如下:
contour代表输入点集,此点集形式是一个n*2的二维ndarray或者n*1*2的三维ndarray
retval 表示点集(轮廓)所围区域的面积
(2) OpenCV自带的cv2.minAreaRect()函数可以计算出点集的最小外包旋转矩形,函数声明如下:
minAreaRect(points) -> retval
其中参数解释如下:
points表示输入的点集,如果使用的是Opencv 2.X,则输入点集有两种形式:一是N*2的二维ndarray,其数据类型只能为 int32
或者float32, 即每一行代表一个点;二是N*1*2的三维ndarray,其数据类型只能为int32或者float32
retval是一个由三个元素组成的元组,依次代表旋转矩形的中心点坐标、尺寸和旋转角度(根据中心坐标、尺寸和旋转角度
可以确定一个旋转矩形)
(3) OpenCV自带的cv2.boxPoints()函数可以根据旋转矩形的中心的坐标、尺寸和旋转角度,计算出旋转矩形的四个顶点,函数声明如下:
boxPoints(box[, points]) -> points
其中参数解释如下:
box是旋转矩形的三个属性值,通常用一个元组表示,如((3.0,5.0),(8.0,4.0),-60)
points是返回的四个顶点,所返回的四个顶点是4行2列、数据类型为float32的ndarray,每一行代表一个顶点坐标
"""
temp_contours = []
for contour in contours:
if cv2.contourArea(contour) > Min_Area:
temp_contours.append(contour)
car_plate1 = []
car_plate2 = []
car_plate3 = []
for temp_contour in temp_contours:
rect_tupple = cv2.minAreaRect(temp_contour)
rect_width, rect_height = rect_tupple[1]
if rect_width < rect_height:
rect_width, rect_height = rect_height, rect_width
aspect_ratio = rect_width / rect_height
# 中国:蓝牌和黑牌是440×140,黄牌前牌尺寸同,后牌为440×220;摩托车及轻便摩托车前牌是220×95,后牌是220×140。
# 车牌正常情况下宽高比在2 - 3.15之间 稍微放宽点范围
if aspect_ratio > 1.5 and aspect_ratio < 4.65:
car_plate1.append(temp_contour)
rect_vertices = cv2.boxPoints(rect_tupple)
rect_vertices = np.int0(rect_vertices)
# print(temp_contour)
print('一次筛查后,符合比例的矩形有' + str(len(car_plate1)) + '个')
# 二次筛查 如果符合尺寸的矩形大于1,则缩小宽高比
if len(car_plate1) > 1:
for temp_contour in car_plate1:
rect_tupple = cv2.minAreaRect(temp_contour)
rect_width, rect_height = rect_tupple[1]
if rect_width < rect_height:
rect_width, rect_height = rect_height, rect_width
aspect_ratio = rect_width / rect_height
# 中国:蓝牌和黑牌是440×140,黄牌前牌尺寸同,后牌为440×220;摩托车及轻便摩托车前牌是220×95,后牌是220×140。
# 车牌正常情况下宽高比在2 - 3.15之间 稍微放宽点范围
if aspect_ratio > 1.6 and aspect_ratio < 4.15:
car_plate2.append(temp_contour)
rect_vertices = cv2.boxPoints(rect_tupple)
rect_vertices = np.int0(rect_vertices)
print('二次筛查后,符合比例的矩形还有' + str(len(car_plate2)) + '个')
# 三次筛查 如果符合尺寸的矩形大于1,则缩小宽高比
if len(car_plate2) > 1:
for temp_contour in car_plate2:
rect_tupple = cv2.minAreaRect(temp_contour)
rect_width, rect_height = rect_tupple[1]
if rect_width < rect_height:
rect_width, rect_height = rect_height, rect_width
aspect_ratio = rect_width / rect_height
# 中国:蓝牌和黑牌是440×140,黄牌前牌尺寸同,后牌为440×220;摩托车及轻便摩托车前牌是220×95,后牌是220×140。
# 车牌正常情况下宽高比在2 - 3.15之间 稍微放宽点范围
if aspect_ratio > 1.8 and aspect_ratio < 3.35:
car_plate3.append(temp_contour)
rect_vertices = cv2.boxPoints(rect_tupple)
rect_vertices = np.int0(rect_vertices)
print('三次筛查后,符合比例的矩形还有' + str(len(car_plate3)) + '个')
if len(car_plate3) > 0:
return car_plate3
if len(car_plate2) > 0:
return car_plate2
return car_plate1
# 根据得到的车牌定位,将车牌从原始图像中截取出来,并存在指定目录中。
def license_segment(car_plates, out_path):
"""
此函数根据得到的车牌定位,将车牌从原始图像中截取出来,并存在指定目录中。
输入: car_plates是经过初步筛选之后的车牌轮廓的点集
输出: out_path是车牌的存储路径
"""
i = 0
if len(car_plates) == 1:
for car_plate in car_plates:
row_min, col_min = np.min(car_plate[:, 0, :], axis=0)
row_max, col_max = np.max(car_plate[:, 0, :], axis=0)
cv2.rectangle(img, (row_min, col_min), (row_max, col_max), (0, 255, 0), 2)
card_img = img[col_min:col_max, row_min:row_max, :]
cv2.imwrite(out_path + "/card_img" + str(i) + ".jpg", card_img)
cv2.imshow("card_img" + str(i) + ".jpg", card_img)
i += 1
cv2.waitKey(0)
cv2.destroyAllWindows()
print('共切出' + str(i) + '张车牌图。')
return out_path + "/card_img0.jpg"
# 根据设定的阈值和图片直方图,找出波峰,用于分隔字符
def find_waves(threshold, histogram):
up_point = -1 # 上升点
is_peak = False
if histogram[0] > threshold:
up_point = 0
is_peak = True
wave_peaks = []
for i, x in enumerate(histogram):
if is_peak and x < threshold:
if i - up_point > 2:
is_peak = False
wave_peaks.append((up_point, i))
elif not is_peak and x >= threshold:
is_peak = True
up_point = i
if is_peak and up_point != -1 and i - up_point > 4:
wave_peaks.append((up_point, i))
return wave_peaks
# 将截取到的车牌照片转化为灰度图,然后去除车牌的上下无用的边缘部分,确定上下边框
def remove_plate_upanddown_border(card_img):
"""
这个函数将截取到的车牌照片转化为灰度图,然后去除车牌的上下无用的边缘部分,确定上下边框
输入: card_img是从原始图片中分割出的车牌照片
输出: 在高度上缩小后的字符二值图片
"""
plate_Arr = cv2.imread(card_img)
plate_gray_Arr = cv2.cvtColor(plate_Arr, cv2.COLOR_BGR2GRAY)
ret, plate_binary_img = cv2.threshold(plate_gray_Arr, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
row_histogram = np.sum(plate_binary_img, axis=1) # 数组的每一行求和
row_min = np.min(row_histogram)
row_average = np.sum(row_histogram) / plate_binary_img.shape[0]
row_threshold = (row_min + row_average) / 2
wave_peaks = find_waves(row_threshold, row_histogram)
# 接下来挑选跨度最大的波峰
wave_span = 0.0
for wave_peak in wave_peaks:
span = wave_peak[1] - wave_peak[0]
if span > wave_span:
wave_span = span
selected_wave = wave_peak
plate_binary_img = plate_binary_img[selected_wave[0]:selected_wave[1], :]
cv2.imshow("plate_binary_img", plate_binary_img)
return plate_binary_img
##################################################
# 测试用
# print( row_histogram )
# fig = plt.figure()
# plt.hist( row_histogram )
# plt.show()
# 其中row_histogram是一个列表,列表当中的每一个元素是车牌二值图像每一行的灰度值之和,列表的长度等于二值图像的高度
# 认为在高度方向,跨度最大的波峰为车牌区域
# cv2.imshow("plate_gray_Arr", plate_binary_img[selected_wave[0]:selected_wave[1], :])
##################################################
#####################二分-K均值聚类算法############################
def distEclud(vecA, vecB):
"""
计算两个坐标向量之间的街区距离
"""
return np.sum(abs(vecA - vecB))
def randCent(dataSet, k):
n = dataSet.shape[1] # 列数
centroids = np.zeros((k, n)) # 用来保存k个类的质心
for j in range(n):
minJ = np.min(dataSet[:, j], axis=0)
rangeJ = float(np.max(dataSet[:, j])) - minJ
for i in range(k):
centroids[i:, j] = minJ + rangeJ * (i + 1) / k
return centroids
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = dataSet.shape[0]
clusterAssment = np.zeros((m, 2)) # 这个簇分配结果矩阵包含两列,一列记录簇索引值,第二列存储误差。这里的误差是指当前点到簇质心的街区距离
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = np.inf
minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j, :], dataSet[i, :])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
for cent in range(k):
ptsInClust = dataSet[np.nonzero(clusterAssment[:, 0] == cent)[0]]
centroids[cent, :] = np.mean(ptsInClust, axis=0)
return centroids, clusterAssment
# 将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE的值。
def biKmeans(dataSet, k, distMeas=distEclud):
"""
这个函数首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE的值。
输入:dataSet是一个ndarray形式的输入数据集
k是用户指定的聚类后的簇的数目
distMeas是距离计算函数
输出: centList是一个包含类质心的列表,其中有k个元素,每个元素是一个元组形式的质心坐标
clusterAssment是一个数组,第一列对应输入数据集中的每一行样本属于哪个簇,第二列是该样本点与所属簇质心的距离
"""
m = dataSet.shape[0]
clusterAssment = np.zeros((m, 2))
centroid0 = np.mean(dataSet, axis=0).tolist()
centList = []
centList.append(centroid0)
for j in range(m):
clusterAssment[j, 1] = distMeas(np.array(centroid0), dataSet[j, :]) ** 2
while len(centList) < k: # 小于K个簇时
lowestSSE = np.inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[np.nonzero(clusterAssment[:, 0] == i)[0], :]
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
sseSplit = np.sum(splitClustAss[:, 1])
sseNotSplit = np.sum(clusterAssment[np.nonzero(clusterAssment[:, 0] != i), 1])
if (sseSplit + sseNotSplit) < lowestSSE: # 如果满足,则保存本次划分
bestCentTosplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[np.nonzero(bestClustAss[:, 0] == 1)[0], 0] = len(centList)
bestClustAss[np.nonzero(bestClustAss[:, 0] == 0)[0], 0] = bestCentTosplit
centList[bestCentTosplit] = bestNewCents[0, :].tolist()
centList.append(bestNewCents[1, :].tolist())
clusterAssment[np.nonzero(clusterAssment[:, 0] == bestCentTosplit)[0], :] = bestClustAss
return centList, clusterAssment
# 对车牌的二值图进行水平方向的切分,将字符分割出来
def split_licensePlate_character(plate_binary_img):
"""
此函数用来对车牌的二值图进行水平方向的切分,将字符分割出来
输入: plate_gray_Arr是车牌的二值图,rows * cols的数组形式
输出: character_list是由分割后的车牌单个字符图像二值图矩阵组成的列表
"""
plate_binary_Arr = np.array(plate_binary_img)
row_list, col_list = np.nonzero(plate_binary_Arr >= 255)
dataArr = np.column_stack((col_list, row_list)) # dataArr的第一列是列索引,第二列是行索引,要注意
centroids, clusterAssment = biKmeans(dataArr, 7, distMeas=distEclud)
centroids_sorted = sorted(centroids, key=lambda centroid: centroid[0])
split_list = []
for centroids_ in centroids_sorted:
i = centroids.index(centroids_)
current_class = dataArr[np.nonzero(clusterAssment[:, 0] == i)[0], :]
x_min, y_min = np.min(current_class, axis=0)
x_max, y_max = np.max(current_class, axis=0)
split_list.append([y_min, y_max, x_min, x_max])
character_list = []
for i in range(len(split_list)):
single_character_Arr = plate_binary_img[split_list[i][0]: split_list[i][1], split_list[i][2]:split_list[i][3]]
character_list.append(single_character_Arr)
cv2.imshow('character' + str(i), single_character_Arr)
# 存储所有字符切图
cv2.imwrite('img/LPR/character' + str(i) + '.jpg', single_character_Arr)
print('字符切割完毕')
return character_list # character_list中保存着每个字符的二值图数据
############################
# 测试用
# print(col_histogram )
# fig = plt.figure()
# plt.hist( col_histogram )
# plt.show()
############################
# 输入灰度图,返回hash
def getHash(image):
avreage = np.mean(image)
hash = []
for i in range(image.shape[0]):
for j in range(image.shape[1]):
if image[i, j] > avreage:
hash.append(1)
else:
hash.append(0)
return hash
# 计算汉明距离
def Hamming_distance(hash1, hash2):
num = 0
for index in range(len(hash1)):
if hash1[index] != hash2[index]:
num += 1
return num
# 参考:https://zhuanlan.zhihu.com/p/29868652
# 感知哈希算法(pHash)
# 缩小图片:32 * 32是一个较好的大小,这样方便DCT计算
# 转化为灰度图
# 计算DCT:利用Opencv中提供的dct()方法,注意输入的图像必须是32位浮点型,所以先利用numpy中的float32进行转换
# 缩小DCT:DCT计算后的矩阵是32 * 32,保留左上角的8 * 8,这些代表的图片的最低频率
# 计算平均值:计算缩小DCT后的所有像素点的平均值。
# 进一步减小DCT:大于平均值记录为1,反之记录为0.
# 得到信息指纹:组合64个信息位,顺序随意保持一致性。
# 最后比对两张图片的指纹,获得汉明距离即可。
def classify_pHash(image1_path, image2_path):
image1 = imread_photo(image1_path)
image2 = imread_photo(image2_path)
image1 = cv2.resize(image1, (32, 32))
image2 = cv2.resize(image2, (32, 32))
gray1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)
# 将灰度图转为浮点型,再进行dct变换
dct1 = cv2.dct(np.float32(gray1))
dct2 = cv2.dct(np.float32(gray2))
# 取左上角的8*8,这些代表图片的最低频率
# 这个操作等价于c++中利用opencv实现的掩码操作
# 在python中进行掩码操作,可以直接这样取出图像矩阵的某一部分
dct1_roi = dct1[0:8, 0:8]
dct2_roi = dct2[0:8, 0:8]
hash1 = getHash(dct1_roi)
hash2 = getHash(dct2_roi)
return Hamming_distance(hash1, hash2)
# 原文链接:https://blog.csdn.net/qq_45453185/article/details/103450129
def findSmallest(arr):
smallest = arr[0] # 存储最小的值
smallest_index = 0 # 存储最小元素的索引
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
# 字符识别 传入切好的车牌字符路径,字母集合路径
def ocr_pHash(char_path, letter_path):
print('\n函数ocr_pHash识别结果如下:')
print('跳过第一个中文字符')
hamming_distance_arr = []
license_plate = ""
for i in range(1, 7):
for j in range(0, 36):
# 计算汉明距离结果放入hamming_distance_arr
hamming_distance_arr.append(
classify_pHash(char_path + '/character' + str(i) + '.jpg', letter_path + '/' + str(j) + '.png'))
# 输出汉明距离最小值所对应的字母
num = findSmallest(hamming_distance_arr)
if num < 10:
license_plate += str(num)
else:
license_plate += chr(num + 55)
# 清空数组
hamming_distance_arr.clear()
print('车牌为:某' + license_plate + '\n')
# Tesseract-OCR 图像识别 传入车牌路径
def tesseract_ocr(car_img_path):
print('\n函数tesseract_ocr识别结果如下:')
# 替换成你的路径
ret = os.popen('D:\Tesseract-OCR\\tesseract.exe ' + car_img_path + ' result -l chi_sim')
# print(ret)
# 给tesseract一点处理时间
time.sleep(1)
# 读写模式打开文件
with open('result.txt', 'r', encoding='utf-8') as f:
# 读取第一行
line1 = f.readline()
rows = len(f.readlines())
# print(rows)
if rows > 0:
print('车牌为:' + line1 + '\n')
else:
print('识别失败,哦豁\n')
# 配合pytesseract食用 需要配置Tesseract-OCR的环境变量
# def pytesseract_ocr(car_img_path):
# print('\n函数pytesseract_ocr识别结果如下:')
# img_cv = cv2.imread(car_img_path)
#
# # By default OpenCV stores images in BGR format and since pytesseract assumes RGB format,
# # we need to convert from BGR to RGB format/mode:
# img_rgb = cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB)
# ret = pytesseract.image_to_string(img_rgb, lang='chi_sim')
# print('车牌为:' + ret + '\n')
############################机器学习识别字符##########################################
#这部分是支持向量机的代码
############################机器学习识别字符##########################################
# 加载数据集 传入图片需要压缩的像素比
def load_data(w, h):
"""
这个函数用来加载数据集
"""
middle_route = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K',
'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
sample_number = 0 # 用来计算总的样本数
# 遍历每一个字符照片,得到34*2个1 * w * h的一维数组,把它们合并成为一个68 * w * h(即68行w * h列)的数据集
dataArr = np.zeros((68, w * h))
label_list = []
# 循环数字+字母次
for i in range(0, 34):
with open(r'img\LPR\letter\dizhi\\' + middle_route[i] + '.txt', 'r') as fr_2:
temp_address = [row_1.strip() for row_1 in fr_2.readlines()]
# print(temp_address)
# sample_number += len(temp_address)
for j in range(len(temp_address)):
sample_number += 1
# print(middle_route[i])
# print(temp_address_2[j])
# 读入数据图片,转单通道灰度
temp_img = cv2.imread('img\LPR\letter\\' + middle_route[i] + '\\' + temp_address[j], cv2.IMREAD_GRAYSCALE)
# print('img\LPR\letter\\' + middle_route[i] + '\\' + temp_address[j])
# 将图片压缩到 w * h
temp_img2 = cv2.resize(temp_img, [w, h])
# cv2.imshow("temp_img2", temp_img2)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 改变矩阵的通道数、行数 对矩阵元素进行序列化
temp_img2 = temp_img2.reshape(1, w * h)
dataArr[sample_number - 1, :] = temp_img2
label_list.extend([i] * len(temp_address))
# print(label_list)
# print(len(label_list))
return dataArr, np.array(label_list)
# 保存训练好的模型
def SVM_rocognition(dataArr, label_list):
# 同步注释点1
# 从sklearn.decomposition 导入PCA
# from sklearn.decomposition import PCA
# 初始化一个可以压缩至7个维度的PCA
# estimator = PCA(n_components=7)
# 用dataArr来训练PCA模型,同时返回降维后的数据。
# new_dataArr = estimator.fit_transform(dataArr)
# 使用默认配置初始化SVM,对降维后的训练数据进行建模,并在测试集上做出预测
# svc.fit(new_dataArr, label_list)
import sklearn.svm
svc = sklearn.svm.SVC()
# 使用默认配置初始化SVM,对原始315维像素特征的训练数据进行建模,并在测试集上做出预测
svc.fit(dataArr, label_list)
# 通过joblib的dump可以将模型保存到本地,clf是训练的分类器
import joblib
# 保存训练好的模型,通过svc = joblib.load("based_SVM_character_train_model.m")调用
joblib.dump(svc, "based_SVM_character_train_model.m")
# SVM字符识别
def SVM_rocognition_character(character_list):
print('\n函数SVM_rocognition_character识别结果如下:')
w = 20
h = 40
character_Arr = np.zeros((len(character_list), w * h))
# print(len(character_list))
for i in range(len(character_list)):
character_ = cv2.resize(character_list[i], (w, h), interpolation=cv2.INTER_LINEAR)
new_character_ = character_.reshape((1, w * h))[0]
character_Arr[i, :] = new_character_
# 同步注释点1
# 从sklearn.decomposition 导入PCA
# from sklearn.decomposition import PCA
# # 要求降维后的feature数量少于样本数
# # 初始化一个可以降到7个维度的PCA
# estimator = PCA(n_components=7)
# # 用character_Arr来训练PCA模型,同时返回降维后的数据 character_Arr。
# character_Arr = estimator.fit_transform(character_Arr)
dataArr, label_list = load_data(w, h)
SVM_rocognition(dataArr, label_list)
import joblib
clf = joblib.load("based_SVM_character_train_model.m")
# 返回预测结果,显示标签值
predict_result = clf.predict(character_Arr)
middle_route = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G',
'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
print(predict_result.tolist())
license_plate = '车牌为:某'
for k in range(len(predict_result.tolist())):
# 跳过第一个中文的识别结果
if k != 0:
license_plate += middle_route[predict_result.tolist()[k]]
print('车牌为:某' + license_plate + '\n')
if __name__ == "__main__":
# 你要识别的图片
img = imread_photo("img/LPR/car05.jpg")
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow('img', img)
cv2.imshow('gray_img', gray_img)
# 调整图像的尺寸大小 等比缩放至500*500
img = resize_keep_aspectratio(img, [500, 500])
gray_img = resize_keep_aspectratio(gray_img, [500, 500])
# 过一系列的处理,找到可能是车牌的一些矩形区域
gray_img_, contours, contours2 = predict(img)
cv2.imshow('gray_img_', gray_img_)
# 画出轮廓
# draw_contours(gray_img_, contours)
draw_contours(gray_img, contours2)
# 根据车牌的一些物理特征(面积等)对所得的矩形进行过滤
car_plate = chose_licence_plate(contours2)
if len(car_plate) == 0:
print('没有识别到车牌,程序结束。')
cv2.waitKey(0)
cv2.destroyAllWindows()
else:
# 根据得到的车牌定位,将车牌从原始图像中截取出来,并存在当前目录中。
car_img_path = license_segment(car_plate, "img/LPR")
# 将截取到的车牌照片转化为灰度图,然后去除车牌的上下无用的边缘部分,确定上下边框
plate_binary_img = remove_plate_upanddown_border(car_img_path)
# 对车牌的二值图进行水平方向的切分,将字符分割出来
character_list = split_licensePlate_character(plate_binary_img)
# SVM字符识别
SVM_rocognition_character(character_list)
# 感知哈希算法的字符识别
ocr_pHash('img/LPR', 'img/LPR/letter')
# Tesseract-OCR 图像识别
tesseract_ocr(car_img_path)
# 配合pytesseract食用
# pytesseract_ocr(car_img_path)
cv2.waitKey(0)
cv2.destroyAllWindows()
拓展
切出的车牌图传入百度云做云识别

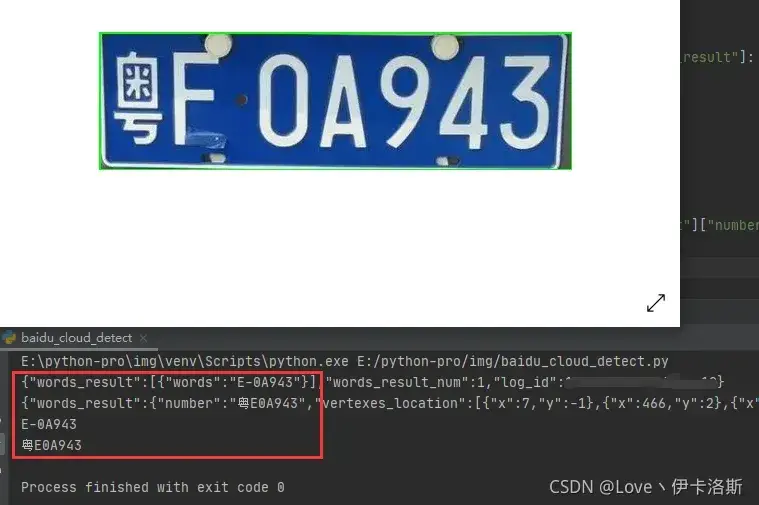
参考:https://cloud.baidu.com/doc/OCR/s/Pkrwx9ye4
官方源码微调如下:
# coding=utf-8
import sys
import json
import base64
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# 防止https证书校验不正确
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 修改为你的个人配置
API_KEY = 'GmhC18eVP1Fo1ECX911dtOzw'
SECRET_KEY = 'PQ2ukO4Aec2PTsgQU9UkiEKYciavlZk8'
# 通用文字识别
OCR_URL1 = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 车牌识别
OCR_URL2 = "https://aip.baidubce.com/rest/2.0/ocr/v1/license_plate"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
读取文件
"""
def read_file(image_path):
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
"""
调用远程服务
"""
def request(url, data):
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# 获取access token
token = fetch_token()
# 拼接通用文字识别高精度url
image_url1 = OCR_URL1 + "?access_token=" + token
# 拼接车牌识别高精度url
image_url2 = OCR_URL2 + "?access_token=" + token
text = ""
# 读取测试图片
file_content = read_file('img/LPR/card_img0.jpg')
# 调用文字识别服务
result1 = request(image_url1, urlencode({'image': base64.b64encode(file_content)}))
# 调用车牌识别服务
result2 = request(image_url2, urlencode({'image': base64.b64encode(file_content)}))
# 解析返回结果
result_json1 = json.loads(result1)
print(result1)
result_json2 = json.loads(result2)
print(result2)
# 通用文字识别
for words_result in result_json1["words_result"]:
text = text + words_result["words"]
# 打印文字
print(text)
text = ""
# 车牌识别
text = text + result_json2["words_result"]["number"]
print(text)
文章出处登录后可见!
已经登录?立即刷新