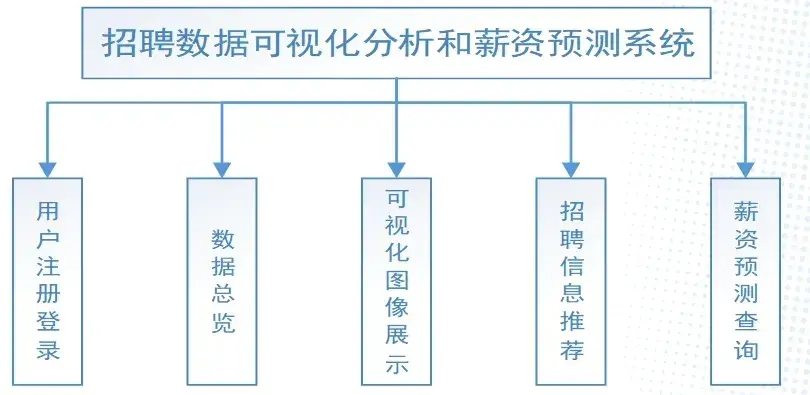
一、说明
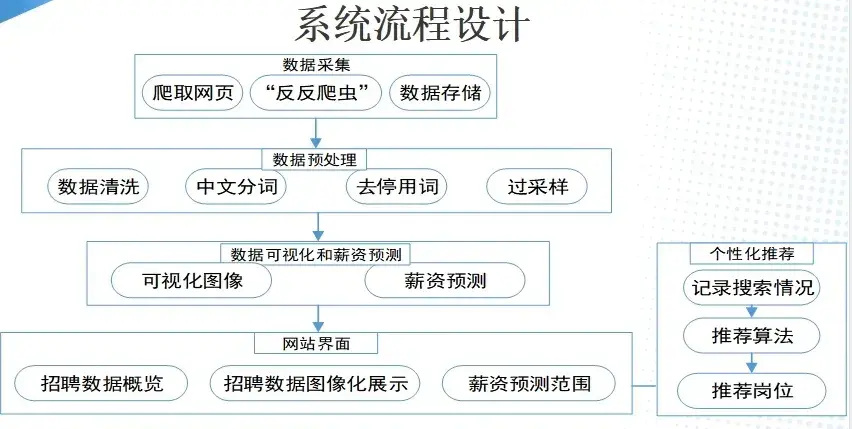
1.数据采集和数据预处理获取有效招聘数据,实现数据总览
2.数据可视化生成招聘数据可视化图像;
3.基于Layui框架建立网站前端:
4.采用基于标签的推荐算法,结合基于内容和基于协同过滤的推荐算法
实现个性化推荐;
5.基于机器学习建立了7个预测模型,通过最优对比选择了神经网络作为薪资预测模型。
二、功能
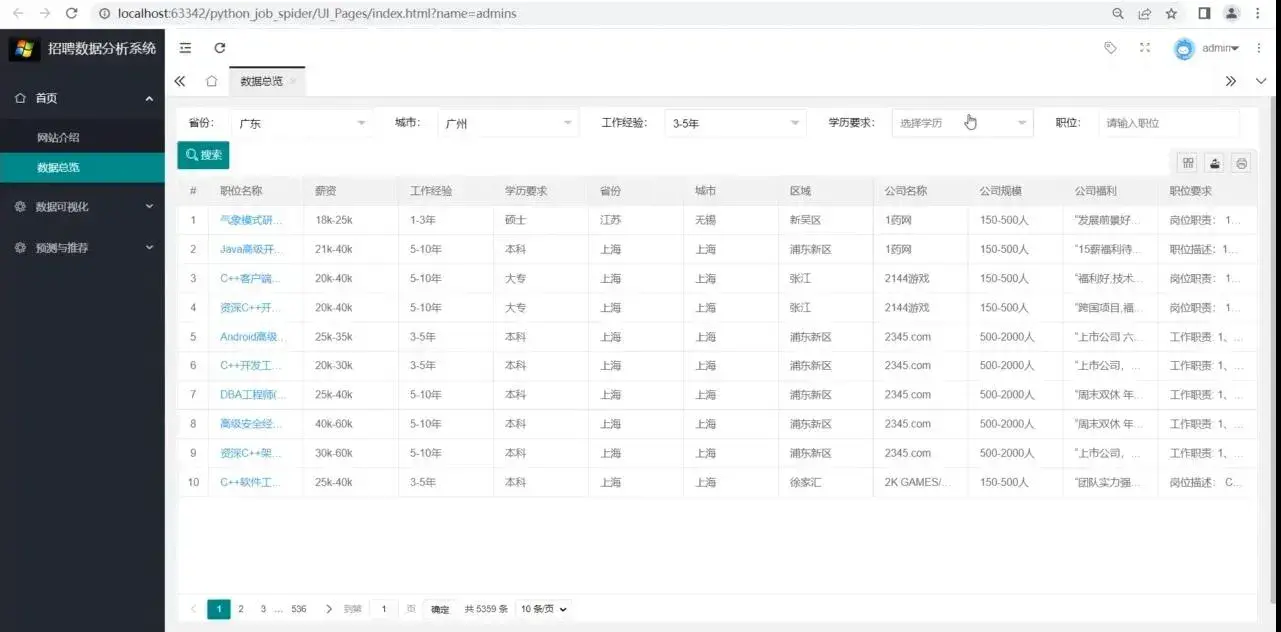
数据总览:
1.查询所有招聘信息
2.查询指定信息
数据可视化:
1.工作经验-新资
2.学历-薪资
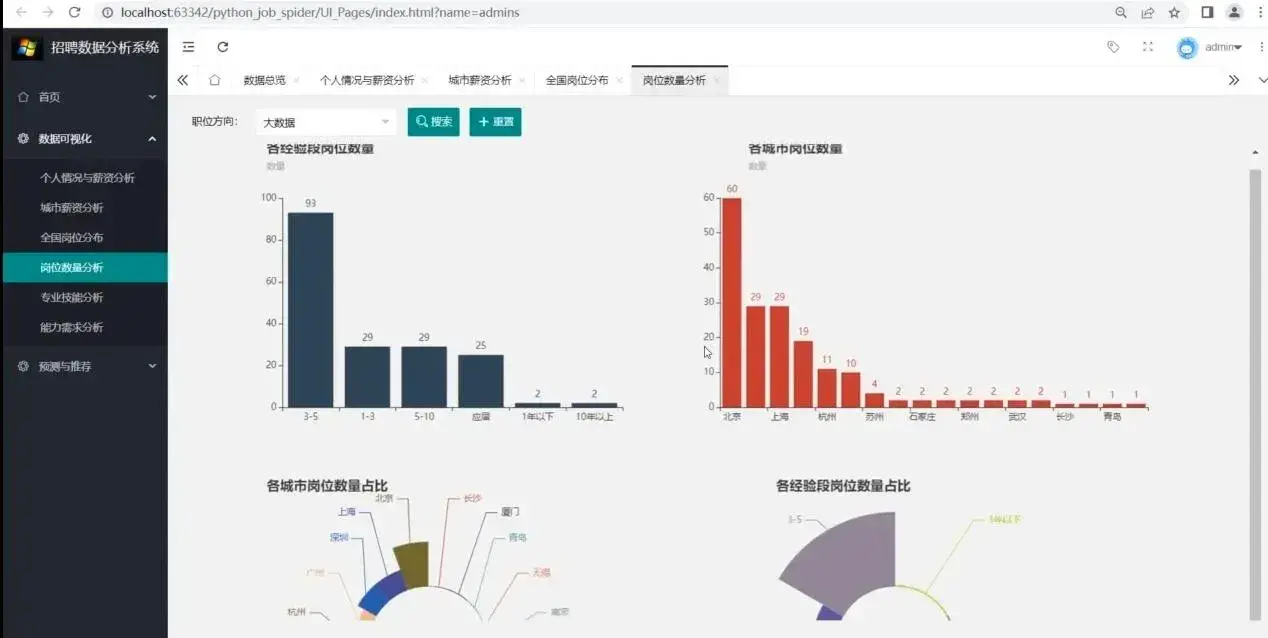
3.岗位数量分析
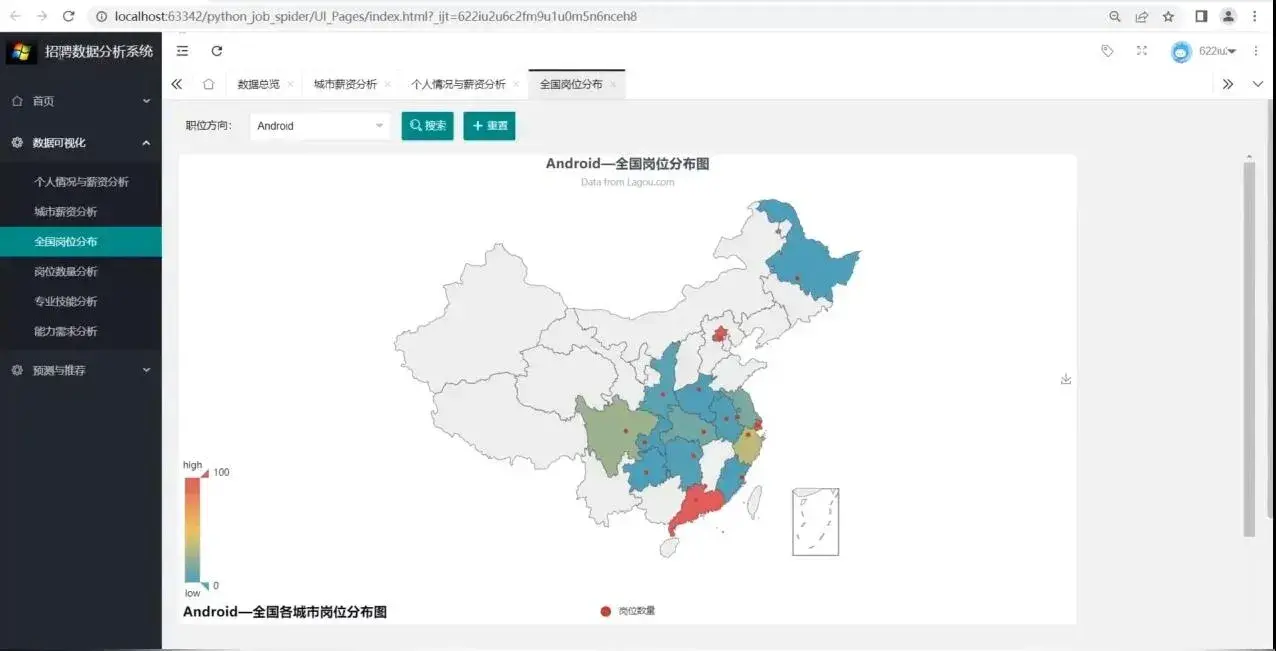
4.岗位全国分布情况
5.岗位专业技能需求
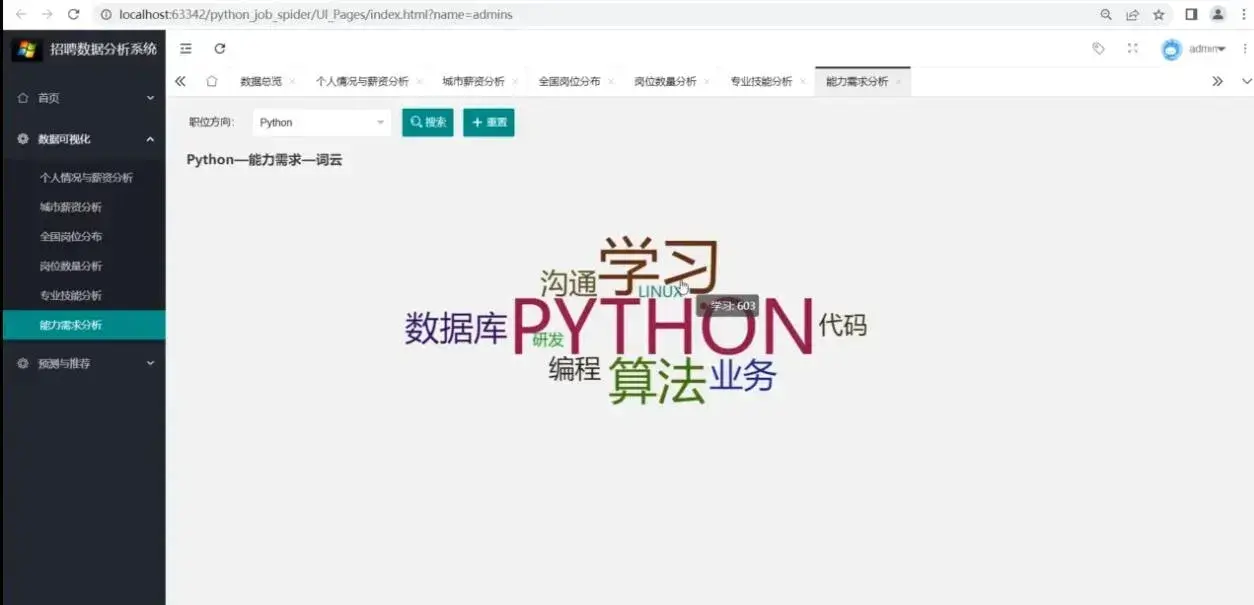
6.岗位职场能力需求
预测与推荐:
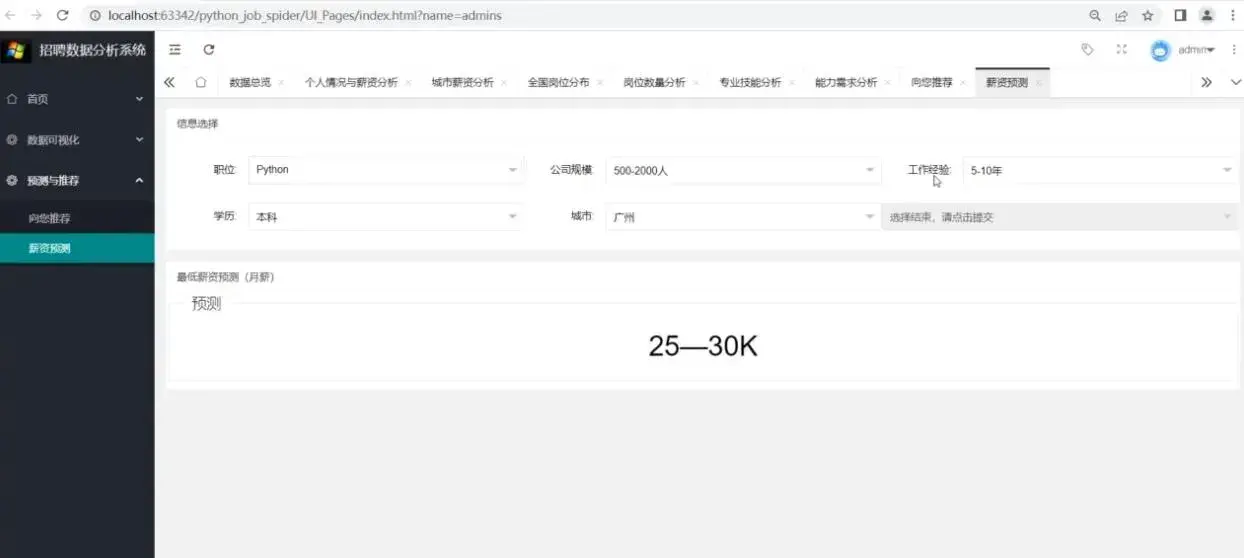
1.根据已知数据预测薪资
2.推荐适合用户的岗位信息
三、基于标签的推荐算法
这个算法结合了基于内容和基于协同过滤两种推荐算法。计算用户对岗位的兴趣度,然后向该用户推荐兴趣度最高的的岗位信息因为热门标签的数据在推荐算法中具有很大的权重,缺少了个性化,用户对物品的兴趣度也会收到影响。这里我们可以通过TF-IDF的思想来改善算法。
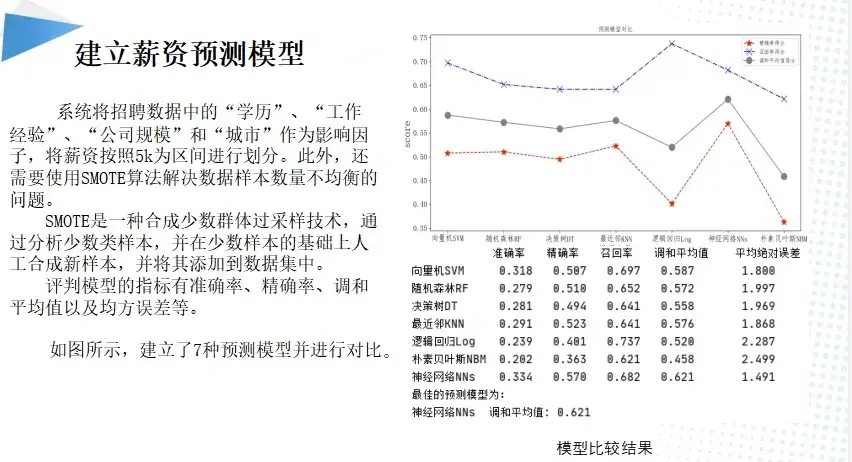
四、建立薪资预测模型
系统将招聘数据中的“学历”、“工作经验”、“公司规模”和“城市”作为影响因子,将薪资按照5k为区间进行划分。此外,还需要使用SMOTE算法解决数据样本数量不均衡的问题。SMOTE是一种合成少数群体过采样技术,通过分析少数类样本,并在少数样本的基础上人工合成新样本,并将其添加到数据集中。
评判模型的指标有准确率、精确率、调和平均值以及均方误差等。
五、运行界面

六、补充
Navicat导入recruit.sql数据库
2、运行步骤
(1)连接好数据库后,运行service.py,出现 【http://127.0.0.1:5000】
(2)启动后台,想要运行网站,运行login.html登录界面,主页界面运行是index.html,右击index.html运行即可
3、推荐模块: 需要新用户有搜索记录,模型才会推荐。
需要的包:
flask
pymysql
numpy
sklearn
flask_cors
pandas
SMOTE
文章出处登录后可见!