运行配置
github地址:https://github.com/kwea123/ngp_pl
- git拉取代码
git clone https://github.com/kwea123/ngp_pl
- 创建环境
conda create -n ngp_pl python=3.8
- 工具
make
apt install make
cmake3.18.0
wget https://cmake.org/files/v3.18/cmake-3.18.0-Linux-x86_64.tar.gz
tar zxvf cmake-3.18.0-Linux-x86_64.tar.gz
sudo mv cmake-3.18.0-Linux-x86_64 /usr/local/cmake-3.18.0
sudo ln -sf /usr/local/cmake-3.18.0/bin/* /usr/bin/
cmake --version
- python依赖包
pytorch
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
requirement.txt
pip install -r requirement.txt
注:cuda使用11.3版本
pip install torch-scatter -f https://data.pyg.org/whl/torch-1.11.0+cu113.html
git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
cd tiny-cuda-nn
cmake . -B build
cmake --build build --config RelWithDebInfo -j
pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
cd bindings/torch
python setup.py install
要求cuda11.3
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
- cuda extension
pip 要 >= 22.1
运行下列代码 (please run this each time you pull the code)
pip install models/csrc/
数据
- NSVF data
Download preprocessed datasets (Synthetic_NeRF, Synthetic_NSVF, BlendedMVS, TanksAndTemples) from NSVF. Do not change the folder names since there is some hard-coded fix in my dataloader.
- NeRF++ data
Download data from here.
- Colmap data
For custom data, run colmap and get a folder sparse/0 under which there are cameras.bin, images.bin and points3D.bin. The following data with colmap format are also supported:
- nerf_llff_data
- mipnerf360 data
- HDR-NeRF data. Additionally, download my colmap pose estimation from here and extract to the same location.
- RTMV data Download data from here. To convert the hdr images into ldr images for training, run python misc/prepare_rtmv.py <path/to/RTMV>, it will create images/ folder under each scene folder, and will use these images to train (and test).
Training
python train.py --root_dir <path/to/lego> --exp_name Lego
python train.py --root_dir ./data/Synthetic_NeRF/Lego --exp_name Lego
概念
Instant-ngp重要的加速手段:
- cuda加速
- 多分辨率Hash位置编码
- 射线推进:指数步进、空白跳过、样本压缩
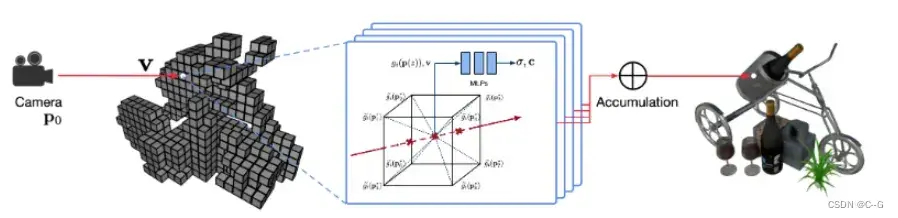
Instant-ngp
类似文章:NSVF
类似文章:DVGO
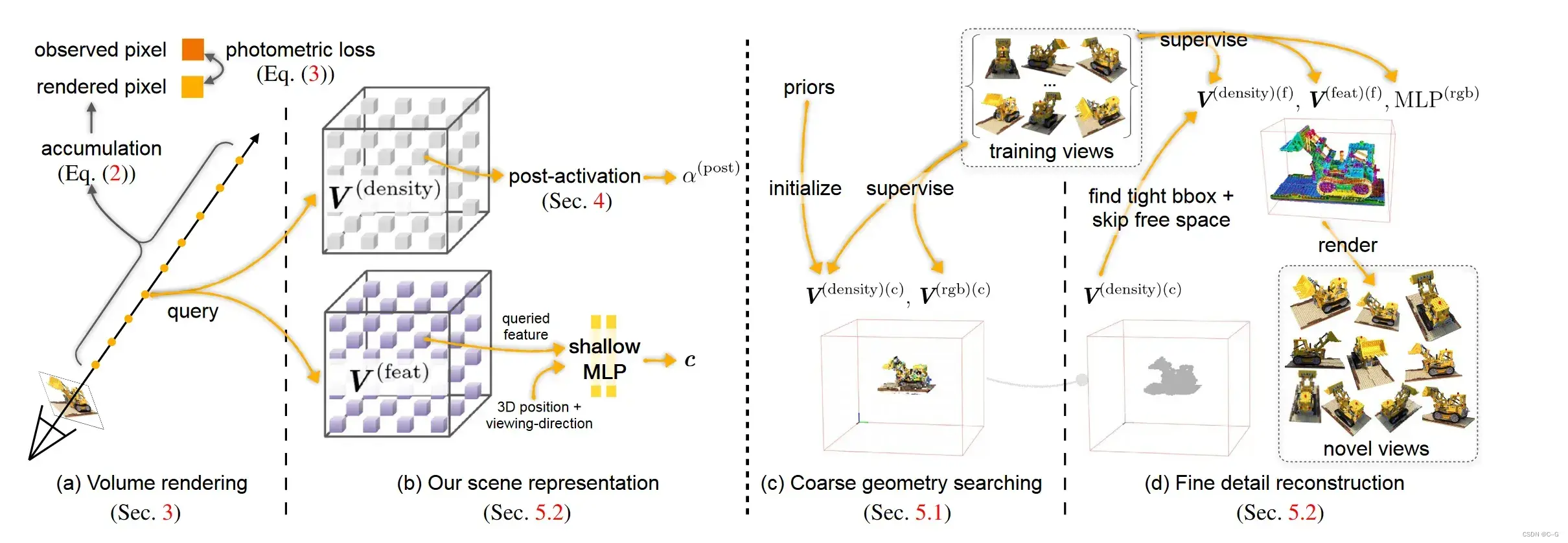
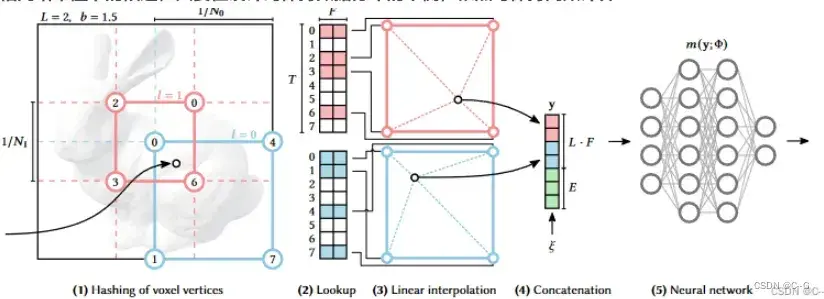
多分辨率Hash位置编码
早期将机器学习模型的输入编码到高维空间的例子包括单热编码和核心技巧,通过这种技巧,数据的复杂排列可以线性可分。对于神经网络来说,输入编码已被证明在循环架构的注意力组件中很有用,随后是transformer,它们帮助神经网络识别它当前正在处理的位置。
NeRF使用了球函数,即:
在经典数据结构和神经方法之间,有一种名为参数编码的方法,其在实验中获得了最先进的结果。其想法是在辅助数据结构中安排额外的可训练参数(除了权重和偏差),例如网格或树,并根据输入向量查找和插值(可选)这些参数。这种安排通过牺牲更大的内存占用来交换更小的计算成本。对于通过网络向后传播的每个梯度,全连接MLP网络中的每个权值都必须更新,对于可训练的输入编码参数(“特征向量”),只有非常小的数量受到影响。例如,对于特征向量的三线性插值三维网格,对于每个反向传播到编码的样本,只需要更新8个这样的网格点。通过这种方式,尽管参数编码的参数总数要比固定输入编码高得多,但训练期间更新所需的参数数量和内存访问并不会显著增加。通过减小MLP层的大小,这样的参数模型通常可以在不牺牲近似质量的情况下更快地训练收敛。

- 图(a)展示了不使用位置编码
- 图(b)展示了使用原始NeRF位置编码
- 图(c)展示了不使用多分辨率的密集网格位置编码,使用
个网格点存储特征信息,这种策略对场景所有块基于的资源是一样的,而场景中大部分是空白的区域,因此导致资源浪费(资源需求增长为
,而实际需要为
)。
- 图(d)则是在(c)的基础上增加了多分辨率策略。多分辨率结构可以联想到CNN中常用的金字塔网络结构。通过将网格划分多个不同的分辨率大小,一方面网格中的采样点增加了不同分辨率的特性信息,提高了PSNR,另一方面采取合理的不同分辨率层数,减少了网格点的数量。
- 图(e)(f)则是在(d)的基础上使用Hash表存储特征信息,其中(e)规定每层分辨率大小使用的Hash表大小为
,而(f)是
,Hash表存取数据的时间复杂度是
,因此大大提升了数据读取速度。此外,由于密集网格中大多数网格是空白的,是不具备关键信息的,因此Hash表在容量有限的情况下导致的Hash冲突对整体影响不大。
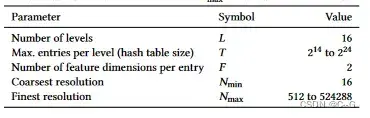
Instant-ngp的位置编码提高了近似质量和训练速度,而不会产生显著的性能开销。在模型中,编码参数是可训练的。这些被安排到L层次,每个层次包含维度为F的特征向量,最多T大小。这些超参数的典型值下图所示。
下图说明了在多分辨率哈希编码中执行的步骤。每个层次(图中红色和蓝色表示其中两个层次)是独立的,并在网格顶点上存储特征向量,其分辨率被选择为最粗和最佳分辨率之间的几何级数:
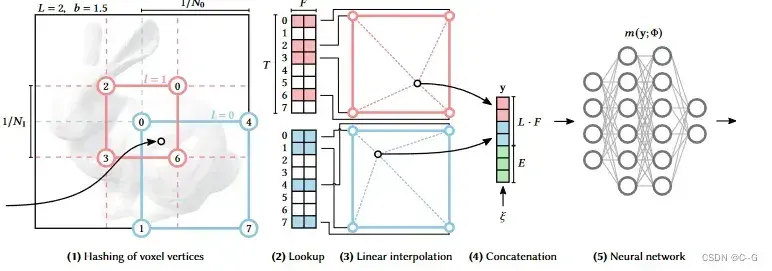
然后根据采样点在不同层中所在的网格,对每层的8个网格点进行三线性插值,得到2*16维特征,拼接上编码后方向特征,输入小mlp网络
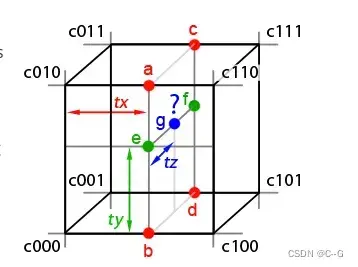
Hash表的存取方式使用了空间哈希函数的形式
其中,表示按位异或运算,
是唯一的大素数。这个公式按位异或运算每维线性同同排列的结果,去关联维度对哈希值的影响。值得注意的是,要实现独立性,d维度中只有d−1维必须被排列,因此选择
以获得更好的缓存一致性,
= 2,654,435,761,
= 805,459,861。
射线推进
原始NeRF中将射线划分为等距离大小,然后进行均匀采样。射线采样分为粗采样和细采样,其中粗采样64个样本点,细采样根据粗采样的结果进行优化采样位置,在密度高的地方多采样,采样128个样本点。但是在实际场景中,大多数是空白的区域,也就是大多射线的采样是没必要的。因此,固定采样策略会浪费大量资源,增加无用的耗时。
为了减少无用的采样操作和精准采样,Instant-npg采用最先进的射线推进技术,其中包括指数步进、空白跳过和样本压缩。
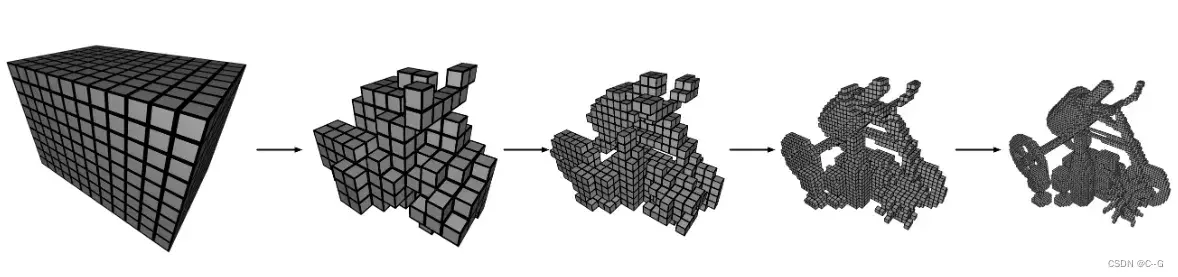
为了实现射线推进,论文采用根据场景大小变化的占用网格,通过Ray Matching查询射线与网格的交点。射线采样采用指数步进策略,对离相机进的场景多采样,离相机远的场景减少采样次数,并根据交点情况和网格占用情况进行空白跳过和样本压缩。
在实验中,由于占用率的不同,每条射线的样本数量是可变的,因此要在固定大小的批次中包含尽可能多的射线,而不是从固定的射线计数构建可变大小的批次。
如下图,Ray-Marching根据占用情况对采样点进行筛选。
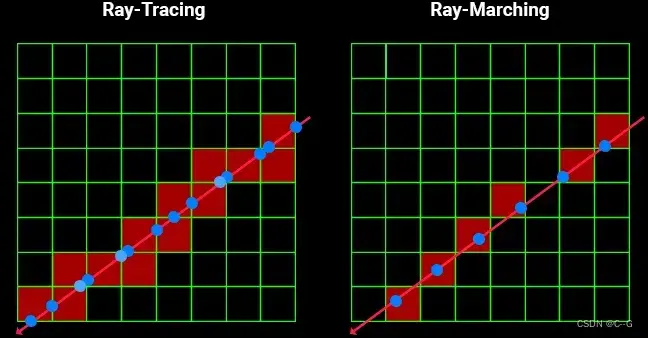
Ray Matching方法如下图所示(下图展示二维情况),网格边界为深色边框,红色射线为射线
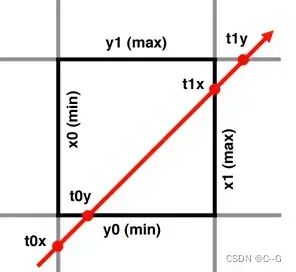
t0x = (B0x - Ox) / Dx
t0y = (B0y - Oy) / Dy
tmin = (t0x > t0y) ? t0x : t0y
t1x = (B1x - Ox) / Dx
t1y = (B1y - Oy) / Dy
tmax = (t1x < t1y) ? t1x : t1y
射线与网格无交点的情况如下
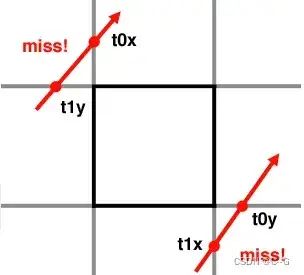
if (t0x > t1y || t0y > t1x)
return false
文章出处登录后可见!