文章目录
DataLoader,何许类?
DataLoader隶属PyTorch中torch.utils.data下的一个类,官方文档如下介绍:
At the heart of PyTorch data loading utility is the torch.utils.data.DataLoader class. It represents a Python iterable over a dataset, with support for
- map-style and iterable-style datasets,
- customizing data loading order,
- automatic batching,
- single- and multi-process data loading,
- automatic memory pinning.
Map-style datasets
map一词除了我们熟知的地图外,其实还有映射的意思。这一应用在我之前写过一篇基于参考点的非支配遗传算法-NSGA-III(一)中就提及过“映射”关系,大家可以自行去查看原为对于“映射”关系的英文描述。
在DataLoader中映射关系是表示的索引到数据之间的关系,其定义:实现
_ getitem_ () and len() protocol,且将data sample与indices/keys(可能是非整数)映射起来的dataset。例如dataset[idx]可读得第idx张图片和对应的label。
需要说明的是,任何继承torch.utils.data.Data类子类军需要重载_getitem_()及_len_()两个函数,且子类在init函数产生的数据路径,将作为DataLoader参数DataSets的实参。两者之间的关系我们将在下文代码中介绍。
iterable-style datasets
定义:为IterableDataset子类的一个实例,实现了__iter()__ protocol,并表示对data sample的迭代。这类dataset适用于对数据的random read开销较大或不合适时,且batch size取决于数据时。例如iter(dataset),可以返回从dataset或远程服务器等读到的数据流。
Data loading order and sampling
For iterable-style datasets, data loading order is entirely controlled by the user-defined iterable. This allows easier implementations of chunk-reading and dynamic batch size (e.g., by yielding a batched sample at each time).
也就是说可以很容易的实现批处理,是通过块来读数据的
The rest of this section concerns the case with map-style datasets. torch.utils.data.Sampler classes are used to specify the sequence of indices/keys used in data loading. They represent iterable objects over the indices to datasets. E.g., in the common case with stochastic gradient decent (SGD), a Sampler could randomly permute a list of indices and yield each one at a time, or yield a small number of them for mini-batch SGD.
torch.utils.data.Sampler类用于指定数据加载中使用的索引/键的顺序。它们代表数据集索引上的可迭代对象。例如,在SGD常见情况下,Sampler可以随机排列一列索引,一次生成每个索引,或者为小批量SGD生成少量索引。
A sequential or shuffled sampler will be automatically constructed based on the shuffle argument to a DataLoader. Alternatively, users may use the sampler argument to specify a custom Sampler object that at each time yields the next index/key to fetch.
DataLoader 的 shuffle 参数,将自动构造顺序或随机排序的采样器。
可以一次生成批量索引列表的自定义采样器作为batch_sampler参数。也可以通过batch_size和drop_last参数启用自动批处理。iterable-style datasets 不能和 sample/ batch_sample 一起使用, 因为iterable-style datasets 没有 index 和 key的概念。
Loading Batched and Non-Batched Data
DataLoader supports automatically collating individual fetched data samples into batches via arguments batch_size, drop_last, batch_sampler, and collate_fn (which has a default function).
Automatic batching (default)
This is the most common case, and corresponds to fetching a minibatch of data and collating them into batched samples, i.e., containing Tensors with one dimension being the batch dimension (usually the first).
包含一个批处理维,用来表示样本批处理后的大小,批处理后的样本称作“批处理样本”。 如一组样本又1600个,每个批处理包含八个样本,每个样本是大小为480*640的RGB图,则会生成200*3*480*640个张量数据。
When batch_size (default 1) is not None, the data loader yields batched samples instead of individual samples. batch_size and drop_last arguments are used to specify how the data loader obtains batches of dataset keys. For map-style datasets, users can alternatively specify batch_sampler, which yields a list of keys at a time.
批处理的个数由每个批处理大小及drop_last(最后不够一个批处理的样本处理过程)决定,每个批处理样本索引可以是任意的,这个可以通过shuttle来决定。
Single- and Multi-process Data Loading
默认情况下,DataLoader使用单进程数据加载。在Python进程中,全局解释器锁(GIL)防止跨线程真正地完全并行化Python代码。为了避免在加载数据时阻塞计算代码,PyTorch提供了一个简单的开关,只需将参数 num_workers 设置为正整数即可执行多进程数据加载。
Memory Pinning
对于数据加载,将pin_memory = True传递给DataLoader将自动将获取的数据张量放入固定内存中,从而能够更快地将数据传输到支持CUDA的GPU。
DataLoader、图片、张量关系
为更好的解释四者之间的关系,我这里直接附上代码,通过注释和说明方式来解释。
def train(config):
# 将参数和缓冲区转移到GPU
dehaze_net = net.dehaze_net().cuda()
# Applies fn recursively to every submodule (as returned by .children()) as well as self.
# Typical use includes initializing the parameters of a model (see also torch.nn.init).
# torch.nn.Module.apply(fn): fn (Module -> None) – function to be applied to each submodule
dehaze_net.apply(weights_init)
# train_dataset and val_dataset目的是获取训练集和验证集数据的文件名,除了个数不一样外,两者init函数所获得的属性一致
train_dataset = dataloader.dehazing_loader(config.orig_images_path,
config.hazy_images_path)
# mode覆盖
val_dataset = dataloader.dehazing_loader(config.orig_images_path,
config.hazy_images_path, mode="val")
# 返回两个DataLoader实例对象集,个数为 (the number of dataset)/batch_size,会调用len()函数
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=config.train_batch_size, shuffle=True,
num_workers=config.num_workers, pin_memory=True)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=config.val_batch_size, shuffle=True,
num_workers=config.num_workers, pin_memory=True)
criterion = nn.MSELoss().cuda()
# torch.nn.Module.parameters()- Returns an iterator over module parameters.
#To construct an Optimizer you have to give it an iterable containing the parameters (all should be Variable s) to optimize. Then, you can specify optimizer-specific options such as the learning rate, weight decay, etc.
optimizer = torch.optim.Adam(dehaze_net.parameters(), lr=config.lr, weight_decay=config.weight_decay)
# Sets the module in training mode.
dehaze_net.train()
说明:1、dehazing_loader()函数是为了获取训练集和测试集数据路径的,该类继承了Data类; def init(self, iterable, start=0): # known special case of enumerate.init
“”” Initialize self. See help(type(self)) for accurate signature. “””
pass
2、获取后的数据,需要借助DataLoader类来实现数据的批处理及张量的表示(前边我们已经说了,任何继承Data类的子类均将重载_getitem_()及_len(),而_getitem()调用就是在DataLoader类调用时被调用的)
批处理样本操作
我们在获得了批处理样本后(如train_loader),如何实现对于每个批处理样本进行操作呢,这里我们可通过enumerate()来实现。我们可以在pycharm中查看enumerate()函数定义:
builtins.py
def __init__(self, iterable, start=0): # known special case of enumerate.__init__
""" Initialize self. See help(type(self)) for accurate signature. """
pass
self指代的就是数据对象,iterable代表数据的个数,从0开始;返回值有两个:一个是序号,一个是数据。
那我们的批处理样本数据可以通过以下代码实现操作
for iteration, (img_orig, img_haze) in enumerate(train_loader):
img_orig = img_orig.cuda()
img_haze = img_haze.cuda()
说明:1、iteration也就是上边的序号,指代批处理的索引;
2、(img_orig, img_haze)表示数据,这里我们采用了list形式来保存数据元素。若批处理大小设置为8,则img_orig及img_haze均为8*3*480*640的张量数据
最后附上各Variables之间的关系图
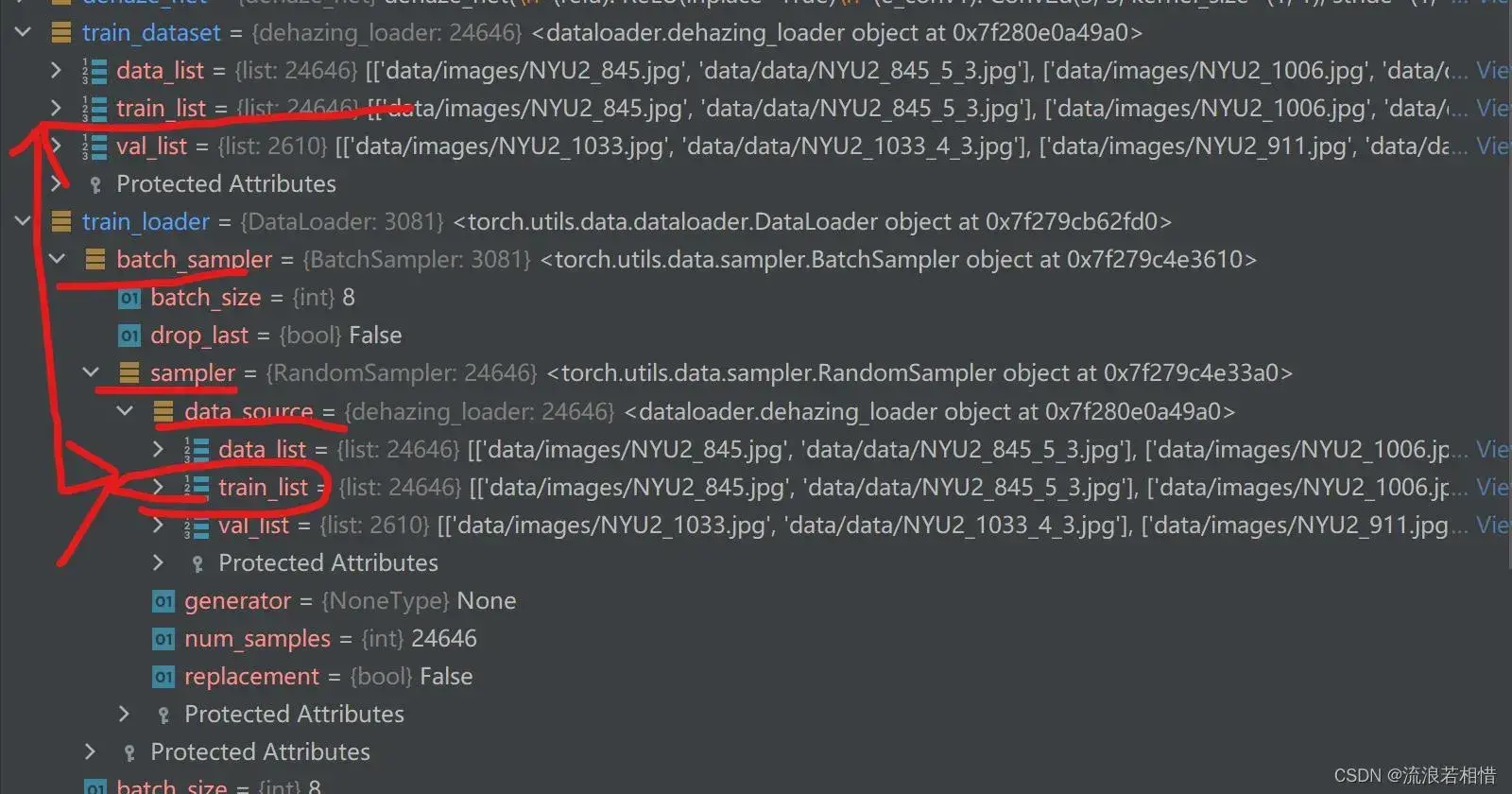
从上边的关系图中也可以看到train_dataset及train_loader最终存储的是数据路径,即data_list。
文章出处登录后可见!