什么是CLIP
Contrastive Language-Image Pre-Training—CLIP
利用文本的监督信号训练一个迁移能力强的视觉模型
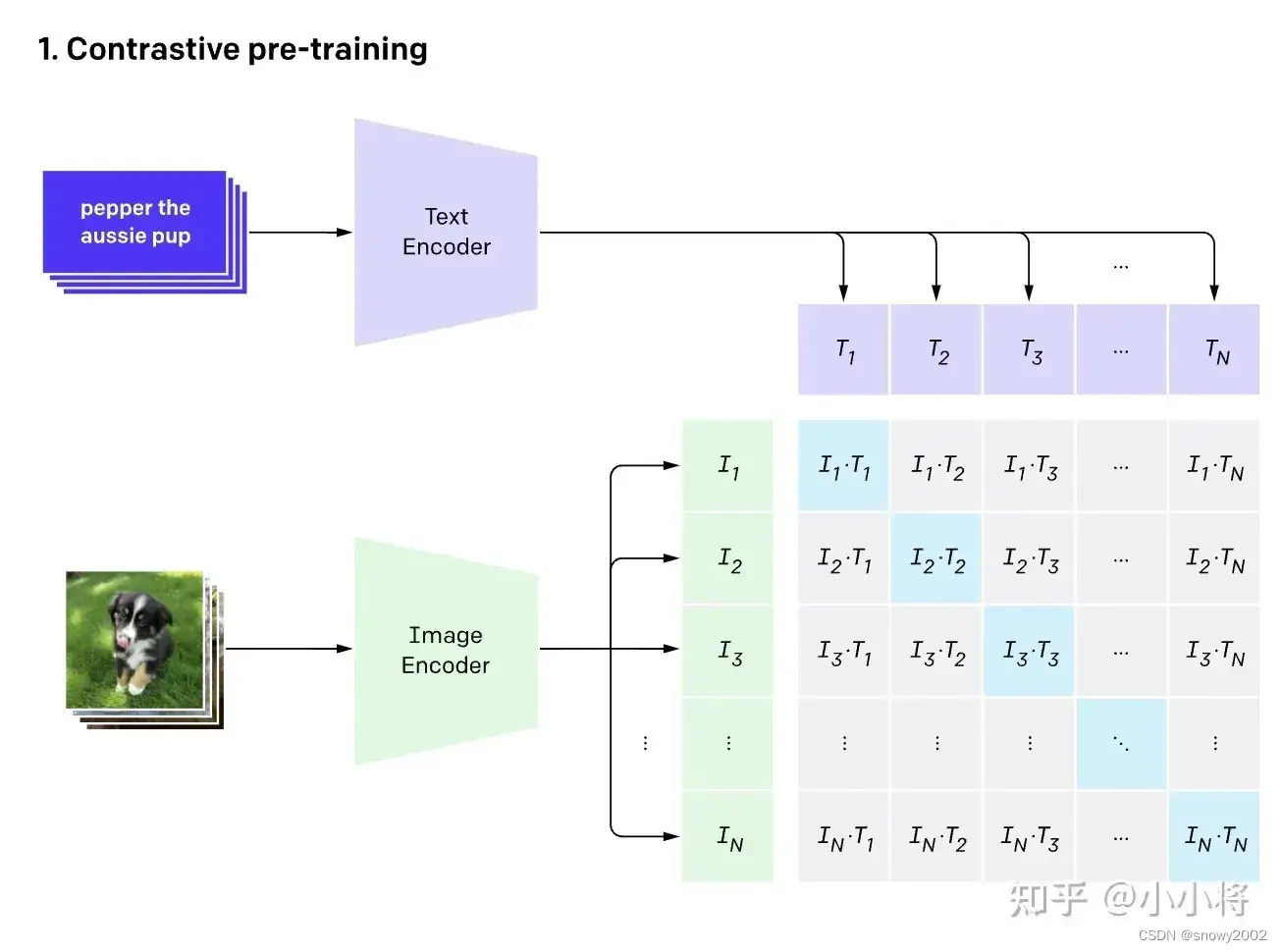
- 这个模型有什么用呢?想象我们有一个图像分类的任务
- 训练1000个类别,预测一张图片是这1000个类别中的哪一类
- 现在如果加入50个新的类别的图像,试想会发生什么呢?
- 传统的图像分类模型无法对类别进行拓展,想要保证准确率只能从头开始训练,费时费力。
- CLIP模型就可以用来解决这种问题,预训练后的模型就可以直接进行zero-shot
与前人工作对比:
- CLIP论文指出,17年就已经开始有这些方法了,但是没获得太多关注。
- 17年类似方法在ImageNet上的效果只要17%。
- 然后openAI说:不是方法不行,而是资源不到位(暴力出奇迹)
- 一个648解决不了,那就再来十次648.。。。
CLIP的成果:
- CLIP在完全不使用ImageNet中所有训练数据的前提下
- 直接Zero-shot得到的结果与ResNet在128W ImageNet数据训练效果一致
- CLIP使用4亿个配对的数据和文本来进行训练,不标注直接爬取(没有解决transformer训练所需数据量大的缺点)
监督训练和zero-shot
在监督学习中,计算机通过示例学习。它从过去的数据中学习,并将学习的结果应用到当前的数据中,以预测未来的事件。在这种情况下,输入和期望的输出数据都有助于预测未来事件。
无监督学习是训练机器使用既未分类也未标记的数据的方法。这意味着无法提供训练数据,机器只能自行学习。机器必须能够对数据进行分类,而无需事先提供任何有关数据的信息。
简而言之:
- 有监督训练:利用已经打好标签的数据训练模型。
- 无监督训练:训练所用的数据没有任何标签。
什么是zero-shot(零样本学习):
- 定义 zero-shot顾名思义即是对某些类别完全不提供训练样本,也就是说没有标注样本的迁移任务被称为zero-shot。
- 不需要任何训练样本就可以直接进行预测
- 模仿人脑的学习能力和知识的迁移能力,根据以往的经验对未知的事物做出预测。
简单的zero-shot的实例:

首先,我们可以将其视为一个类似于自然语言处理的任务,它使用词嵌入(将词汇表中的词或短语映射到实数向量,要求具有相似含义的词将具有相似的词嵌入)。那么对于上面的例子,零样本学习是下面这样来处理的,
- 训练数据中并没有斑马的图像,但是有带条纹的动物(如老虎),有跟马长得相似的一类动物(如马、驴),还有黑白色的动物(如熊猫)的各种图像。可以提取这些图像的特征(条纹、形状似马、黑/白色)并生成词嵌入,组成字典。
- 然后,我们描述斑马的外观,并使用前面训练集里提出的特征来将斑马的外观转化成相应的词嵌入。
- 最后,当你给模型输入一张斑马的图像,它会先提取图像的特征,转化成词嵌入,然后与字典中最接近的词嵌入进行比较,得出那图像可能是只斑马。
CLIP模型的基本架构
模型训练:
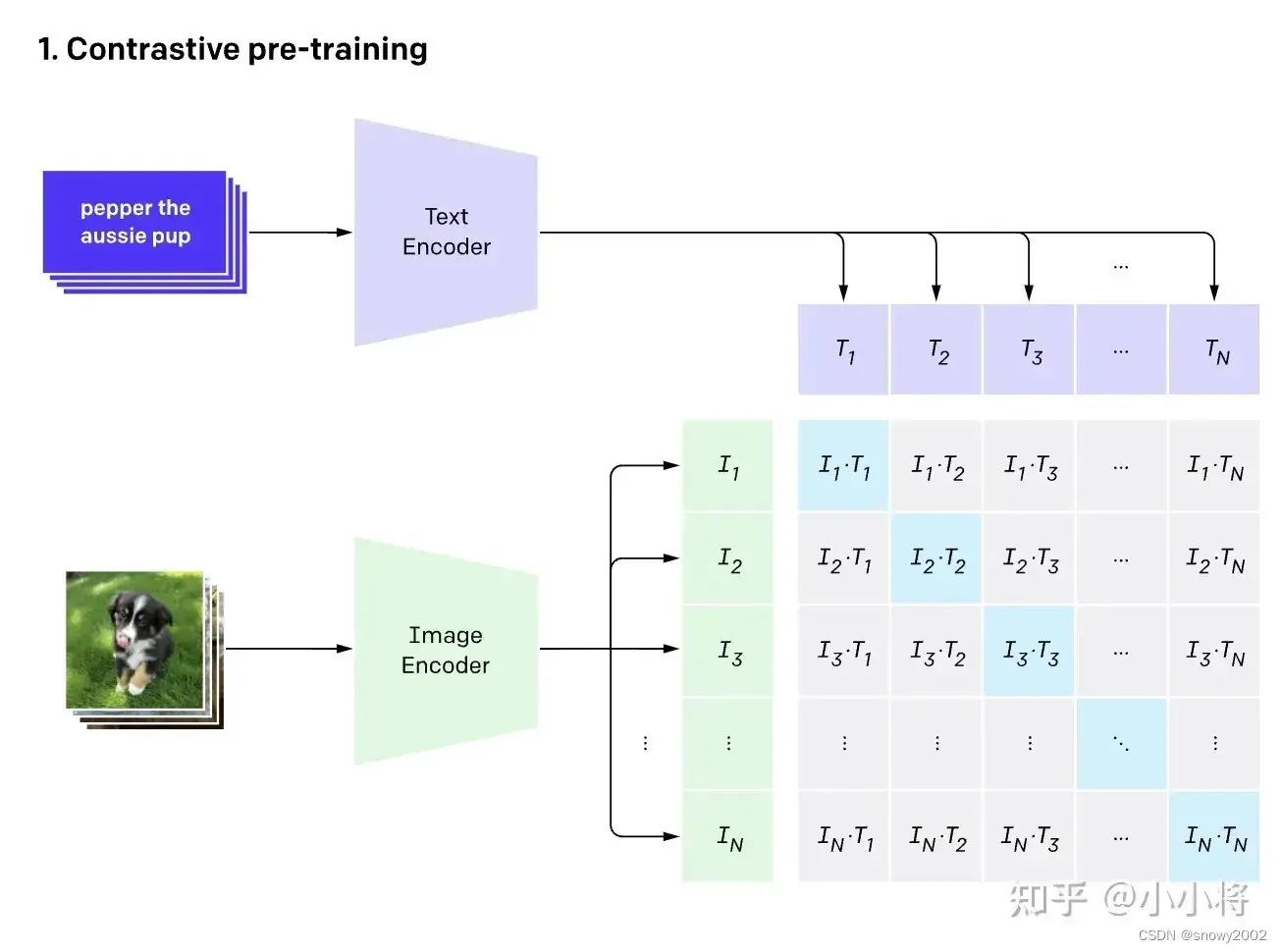
- 输入图片->图像编码器(vision transformer)->图片特征向量
- 输入文字->文本编码器(text )->文本特征向量
- 对两个特征进行线性投射,得到相同维度的特征,并进行L2归一化
- 计算两个特征向量的相似度(夹角余弦)
- 对n个类别进行softmax,确定个正样本和个负样本,并最大化正样本的权重。
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
模型预测:
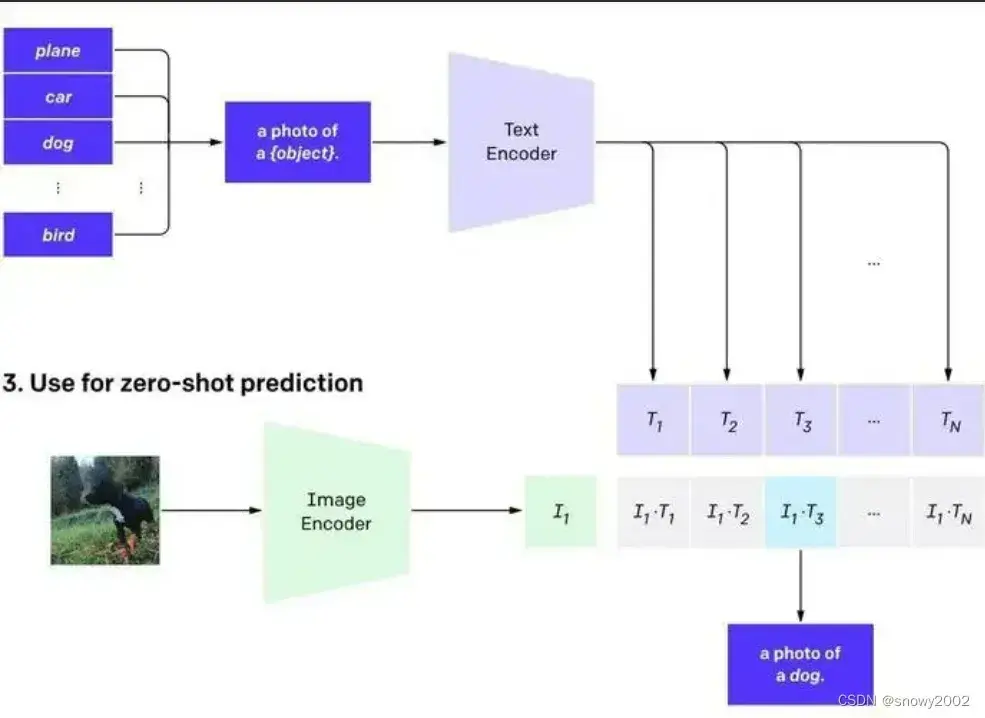
- 给出一些文本提升(给出选项)
- 选项中要包含正确答案
- 然后计算每一个文本提升和图片特征的相似度。
- 找到相似度最高的即为正确答案
合理的提示:
- 预测时的提示非常重要
- 首先是需要一句话或者几个词来提示
- 最好要加上预测的场景,要具有情景的相关性
- 提示要全面,这样预测准确率也会提高。
CLIP模型的展示
文章出处登录后可见!
已经登录?立即刷新