目录
近期,特斯拉CEO马斯克公开表示:OpenAI不该闭源,自家首款聊天机器人将开源。
说起这个事,我觉得和大模型和电动车,有异曲同工之妙。
马斯克的特斯拉电动车,开源后并没有造成电车的销量下降,而且随着生态的繁荣,电动车的配套设施越来越完善,各个国家的准入法规越来越宽松,特斯拉大行其道。
还记得那个宗毅吗,2014年特斯卡刚进中国,他就买了一辆。可是他要在北京和广州两地跑,没有充电桩呀!于是他喊出,从北京到广州都修上一路的充电桩!这在当时可是如同把喜马拉雅山打个隧道,一样轰动的事啊。于是,修充电桩,比他在芬尼克兹和裂变式创业上的成就,更被人熟知。
现在,充电桩的问题,已经不是问题了,这就是马斯克开源的心得。
如今,大模型和电动车一样,当然他要喊开源,希望更多企业来烘托这个生态。
开源当然是好事,但是,如同特斯拉开源,我们也无法去造车一样,大模型开源,普通人也无法去训练一个新的大模型,那都是大象跳舞的事,你以为,我们缺的是你的那点源代码吗?
当然,我还是赞同开源的,我坚定认为开源是人类文明的象征之一。
一、说说开源和闭源
开源并不是一丝不挂,闭源也不是拒人千里。
我想对于开源,CSDN的朋友们应该极其熟悉了吧,我借用一个图,将开源这事再说说。
这是乌克兰程序员 Paul Bagwell 画的,乌克兰是个好地方。
可以说是一图看懂开源协议,值得点赞收藏。

看到了吧,开源就要了解开源协议,不是说开源,你就可以直接C+V大法伺候了,或者套个壳子,去融资,当然,这么干的也有,还是著名投资人和大厂,下一章说。
世界上的开源协议有上百种,很少有人能彻底搞清它们之间的区别,其实,现在最流行的六种开源协议——GPL、BSD、MIT、Mozilla、Apache 和 LGPL,结合上面的图,把这6种搞明白,你就可以说自己懂开源协议了。
1. GUN GPL协议
只要软件中包含了遵循 GPL 协议的产品或代码,该软件就必须也遵循 GPL 许可协议,也就是必须开源免费,不能闭源收费,因此这个协议并不适合商用软件。
LINUX这样的软件,都是遵守GPL协议的。
| 特点 | 说明 |
|---|---|
| 复制自由 | 允许把软件复制到任何人的电脑中,并且不限制复制的数量。 |
| 传播自由 | 允许软件以各种形式进行传播。 |
| 收费传播 | 允许在各种媒介上出售该软件,但必须提前让买家知道这个软件是可以免费获得的;因此,一般来讲,开源软件都是通过为用户提供有偿服务的形式来盈利的。 |
| 修改自由 | 允许开发人员增加或删除软件的功能,但软件修改后必须依然基于GPL许可协议授权。 |
如上图,修改自由,但是你新增了代码,也要继续遵守原协议。
2. BSD(Berkeley Software Distribution,伯克利软件发布版)协议
BSD对商业是比较友好的,很多公司会选择BSD协议的开源软件,来进行修改和二次开发。
BSD 协议基本上允许用户“为所欲为”,用户可以使用、修改和重新发布遵循该许可的软件。
BSD协议的三个条件:
- 如果再发布的软件中包含源代码,则源代码必须继续遵循 BSD 许可协议。
- 如果再发布的软件中只有二进制程序,则需要在相关文档或版权文件中声明原始代码遵循了 BSD 协议。
- 不允许用原始软件的名字、作者名字或机构名称进行市场推广。
上图中,关于BSD协议的“你的名字”,指的是原作者的名字。
3. Apache 许可证版本(Apache License Version)协议

这个图标,大家都太熟悉了亲切了,这个组织太庞大了,太有POWER了。
Apache 和 BSD 类似。
Apache 协议在为开发人员提供版权及专利许可的同时,允许用户拥有修改代码及再发布的自由。
现在热门的 Hadoop、Apache HTTP Server、MongoDB,等项目都是基于该许可协议研发的,程序开发人员在开发遵循该协议的软件时,要严格遵守下面的四个条件:
- 该软件及其衍生品必须继续使用 Apache 许可协议。如上图所分类的情况。
- 如果修改了程序源代码,需要在文档中进行声明。
- 若软件是基于他人的源代码编写而成的,则需要保留原始代码的协议、商标、专利声明及其他原作者声明的内容信息。如上图,YES的说明。
- 如果再发布的软件中有声明文件,则需在此文件中标注 Apache 许可协议及其他许可协议。
可以说,由于有BSD和Apache协议的存在,很多大厂的产品体系,才可能会如此的丰富,继承和发展了这些开源产品。
4. MIT(Massachusetts Institute of Technology)协议
由上图可以看到,MIT的限制,比Apache的还少,可能是目前限制最少的开源许可协议。
只要程序的开发者在修改后的源代码中保留原作者的许可信息即可(这其实很友好,你甚至可以用这条来营销,这条实际是MIT和BSD的核心区别),因此普遍被商业软件所使用。
使用 MIT 协议的软件有 PuTTY等。
5. GUN LGPL(GPL V2)
该协议主要是为类库设计的开源协议。这就是上图左侧,一路NO下来的分支。
LGPL 允许商业软件通过类库引用(link)的方式使用 LGPL 类库,而不需要开源商业软件的代码。这使得采用 LGPL 协议的开源代码可以被商业软件作为类库引用并发布和销售。
6. Mozilla许可证
Mozilla许可证(Mozilla Public License,MPL)是一种自由软件许可证,它由Mozilla基金会制定。该许可证是一种类似于GNU通用公共许可证(GPL)和MIT许可证的许可证,允许用户修改和分发软件的源代码,同时还保护原作者的版权。MPL还允许将代码与其他许可证一起使用,包括GPL和Apache许可证。该许可证最初用于发布Mozilla浏览器的源代码,后来也被用于其他开源软件项目,如OpenOffice.org和MongoDB等。
有人说,开源协议不一定具备法律效力,这个问题比较复杂,软件重合度取证,有时和论文查重一样,有时需要“自由心证”。但是当涉及软件版权纠纷时,开源协议也是非常重要的证据之一。
二、开源和闭源对大模型技术发展的影响
大模型当然要开源,如果这个世界上只有一个OpenAI,那么他将很快消失。
开源对大模型技术的发展,起到了巨大的推波助澜的作用。如果没有开源,大模型的万花筒里,不会如此丰富多彩。
国内的大模型,包括大厂和开源,这里有我的一篇简单总结的文章。
这当然只是很少的一些,光是百度智能云集成的第三方开源大模型,就是数十个之多。
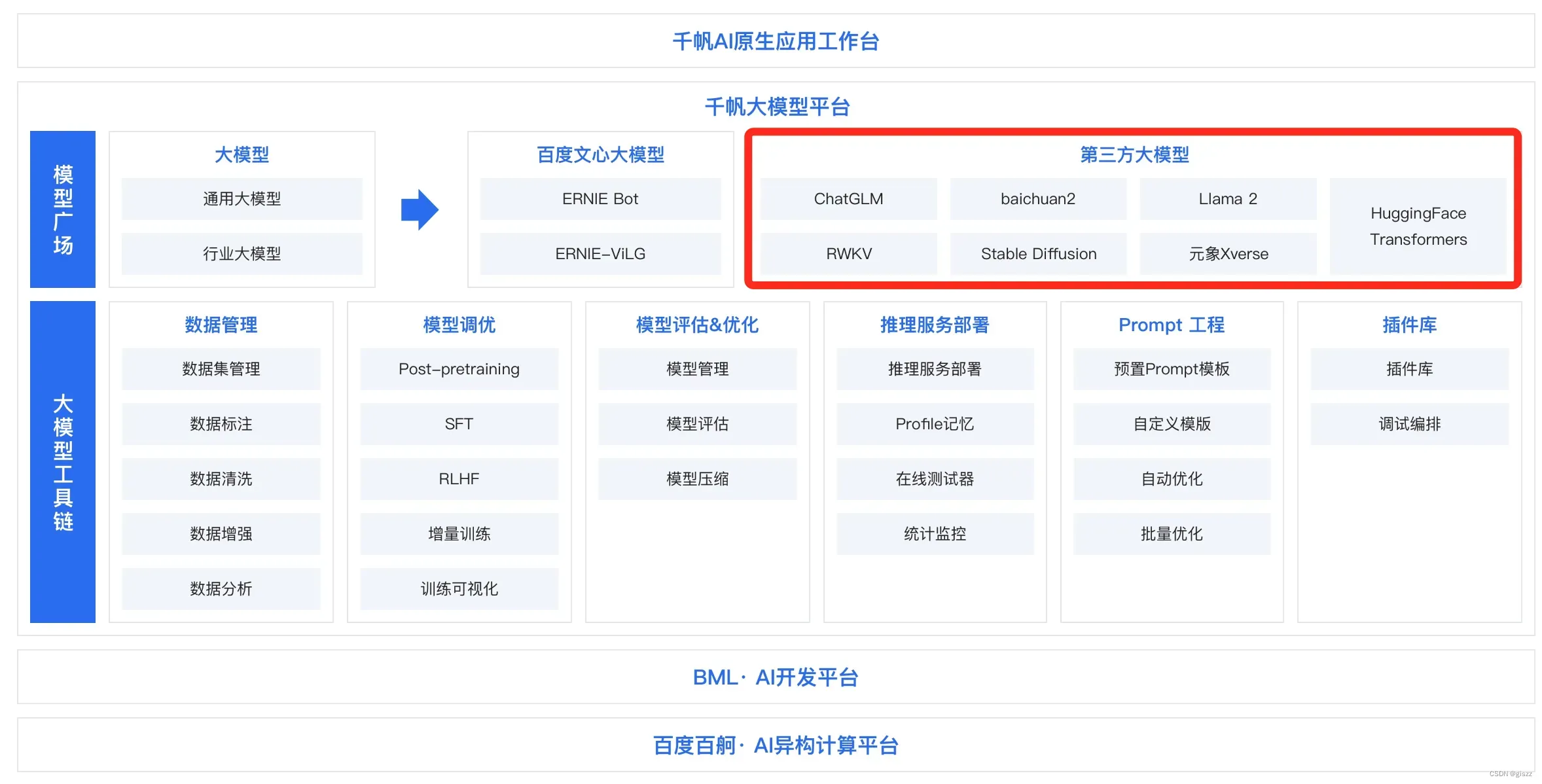
除了让人类的生活更美好,程序员肯定是首先想让自己的生活更美好。当然,在成就他人的过程中,成就自己,是更高的维度。
百度除了自研的ERNIE大模型外,还集成了很多开源模型,比如Meta著名的Llama,当然,这些开源模型,都有自己的限制,例如Llama就要求每个月的调用量,不能超过一定的数量。
从上图中,其实就回答了开源和闭源,对大模型技术发展的影响,就是你中有我,我中有你,共同打造一个生态,大家一起赚钱。如果这个世界上,只有一家独大,而且是在这么重要的涉及国力发展和社会安全的领域,那么这个拥有者,需要极大的保护能力, 保护自己和自己的这个宝贝的安全呦。
当然,有了开源的模型,一定离不开“套壳”这个话题。
很多成功的商业软件,都是来自于开源。
李开复的知名大模型公司,发布的“零一万物”(Yi)大语言模型,就被开源社区暴出,疑似套壳Meta公司在今年开源的大模型LLaMA。
这个大厂新模型exactly就是LLaMA的架构,但是为了表示不一样,把代码里面的名字从LLaMA改成了他们的名字,然后换了几个变量名。
零一回应说:GPT 是一个业内公认的成熟架构,LLaMA 在 GPT 上做了总结。零一万物研发大模型的结构设计基于 GPT 成熟结构,借鉴了行业顶尖水平的公开成果,同时基于零一万物团队对模型和训练的理解做了大量工作…… Yi 开源模型在其他方面的精力,比如数据工程、训练方法、baby sitting(训练过程监测)的技巧、hyperparameter 设置、评估方法以及对评估指标的本质理解深度、对模型泛化能力的原理的研究深度、行业顶尖的 AI Infra 能力等,投入了大量研发和打底工作……”
大家可能觉得这是在解释,很无聊。
其实,他说的是对的。即使大模型开源,也很少会开源训练机,更别说独特的训练方法和是数据了。
所以他们是肯定做了大量的工作,也是对得起融资的以亿计算的美元的。
为什么马斯克说开源呢,因为OpenAI公司对于 GPT-2 之后的模型就不再开源了。而Meta公司推出的开源模型LLaMA,其训练使用的公开数据集均超过万亿词元,展现出与非开源大模型相近水平的任务处理能力。当然大家都用这个来作为自己的大模型基础了。
OPENAI也说了,GPT-5以后,研发和突破,将越来越难。在投入和产出的曲线上,将无法达到平衡,因此,可以说,大模型的发展,在爆发之后,基本就到了一个平台期,后续将是各种深度的垂直应用,各种场景的爆发,深度的结合业务,去驱动技术。光是训练模型一个劲的去理解人类,其实是浪费算力的。
还是马斯克想的明白,除了搞AI,更重要的,还是多生孩子,现在生育率太低了。由此可以看出,马斯克的底层逻辑,还是AI为人类所用,并不是要颠覆一切。
三、开源与闭源的商业模式比较
开源,闭源,还是要看哪个能赚到美元。
因为这不矛盾。
在《2023年全球最佳大模型》中,开源占据了半壁江山,如果没有很好的商业模式,会有这么多人做吗。
当然,这不是说,你扶老太太,就一定是你撞的。
真的有活雷锋,这个不排除在外。
但是从商业模式角度讲,开源真的是更厉害的商业模式。
这十个大模型,有的真的很厉害。
OpenAI的GPT-4
比如GPT-4,OpenAI已经通过使用来自人类反馈的强化学习(RLHF)与领域专家进行对抗性测试,竭尽全力使GPT-4模型更符合人类价值观。GPT-4是一个混合模型,由8个不同的模型组成,每个模型都有2200亿个参数。
GOOGLE的PaLM 2 AI
Google在PaLM 2模型上专注于常识推理、形式逻辑、数学和20多种语言的高级编码。
META的LLaMA
Llama正式发布了各种类型的LLaMA模型,从70亿个参数到650亿个参数。
这个开源模型,实际上是有商用限制的。
其他的大模型,基本都是OpenAI的前员工、GOOGLE支持的公司,或者从Llama衍生出来的。
说说开源和闭源的对比

实际上,虽然开源,也不是就可以顺便的上手商用,一是许可协议,二是算力、财力和能力的限制。
零一从Llama衍生而来,都用了大几千万美元,才发布出来,更别所小的社区了。
实际上,闭源的大模型公司,默默都在扶持一些开源的大模型的发展。
四:处在大模型洪流中,向何处去?
提示:你认为中国大模型应该何去何从?
这个话题太大了,其实中国的大模型,发展的路线图,基本已经出来了。
除了顶级玩家,更多的玩家,机会必将出现在垂直行业细分领域,值得深度去耕耘。历史总是相似的,之前的成功者,现在会更加成功。
当然,这次技术爆炸给普通人的机会也很多。因为,大模型之大,就是因为操作要足够傻瓜化。
傻瓜相机也是大模型,内部预制了大量的参数,去“撞”当前的光照和焦距条件,找到标签打分更高的模式,设定,拍照,OK!
大模型也是如此,将给我们带来一台新的傻瓜相机,非常好玩!但是单反是不是就卖不动了?不是,单反依旧很贵。
而且,这个傻瓜相机,必将随着时间的发展,不以相机的形式出现,而是融入到你的手机中、手表中,渗透到生活的方方面面。
LLM语言大模型,就有很多经典的应用,可以说大有用武之地,一些厂商预制的典型应用范式中,可窥见一斑:
客服问答、文档分析、数据分析、办公助手、代码助手、网页分析、创意营销、商品导购、教育问答、文档校对等。
而且随着文档、图片的输入和输出,更多大模型,将更深入的影响普通人的生活。
至于开源和闭源,我们谁到知道,开源有赚钱的方法,比如提供服务,闭源也会走公益,比如支持开源社区和基金。你中有我,我中有你。
讲个小故事,前几天和一个超级大厂的大佬聊天,他说,他们企业的管理案例,在哈佛都找不到匹配,因为国外的企业没那么多人呀,那些大师们从来没想过这事儿。所有说,中国的大模型,有足够的群众基础,大数据基础,应用场景基础,去发展的更好。
版权声明:本文为博主作者:giszz原创文章,版权归属原作者,如果侵权,请联系我们删除!