目录
引言
众所周知,视频是图片连起来快速播放的,所以Stable Diffusion可能是sora参考的重要模型之一。
随着深度学习和生成模型的发展,扩散模型在生成领域也取得了显著进步。这类扩散模型通常分为扩散过程和逆扩散过程。
扩散过程是对数据(如图像)逐步加入噪声,而逆扩散过程则是从噪声中逐渐消除噪声以生成数据。这类模型在图像生成、文本到图像的转换等领域有广泛应用,如DALL-E 2和Stable Diffusion等。
Stable Diffusion(稳定扩散)严格说来它是一个由几个组件(模型)构成的系统,而非单独的一个模型。
一、Stable Diffusion原理
首先
用户输入的Prompt会被Text Encoder(文本编译器)处理,转化为一系列词特征向量。这一步骤会生成77个长度相同的向量,每个向量都包含768个维度。这些向量实际上是将文本信息转化为机器能够理解和处理的数字序列。
随后
这些特征向量会与一张随机图(可视为充满电子雪花或信息噪声的图像)一同输入到Image Information Creator中。在此环节,机器首先将这些特征向量和随机图转换至Latent Space(潜空间)。接着,根据这些特征向量的指引,机器会对随机图进行“降噪”处理,生成一个“中间产物”。这个中间产物虽然对人类而言是难以理解的数字图像,但它已经蕴含了用户Prompt中描述的信息。
最后
这个中间产物会经过Image Decoder(图片解码器)的处理,转化为一张真实可见的图片。
这个过程中,扩散模型功不可没,今天主要讲讲扩散模型的代表DDPM
二、DDPM模型
1 资料
- 代表之作:Denoising Diffusion Probabilistic Models(https://arxiv.org/abs/2006.11239)
-
官方代码:https://github.com/hojonathanho/diffusion
2 原理
DDPM模型通常指的是去噪扩散概率模型(Denoising Diffusion Probabilistic Models)
扩散过程
在扩散过程中,一张图片会逐渐添加高斯噪声,直至其变成随机噪声。
反向过程
而反向过程则是一个去噪过程,它根据扩散过程中学习到的图片风格,对随机噪声进行去噪,最终生成一张与学到的风格相同的图片。
DDPM模型的本质作用是学习训练数据的分布,从而生成尽可能符合训练数据分布的真实图片。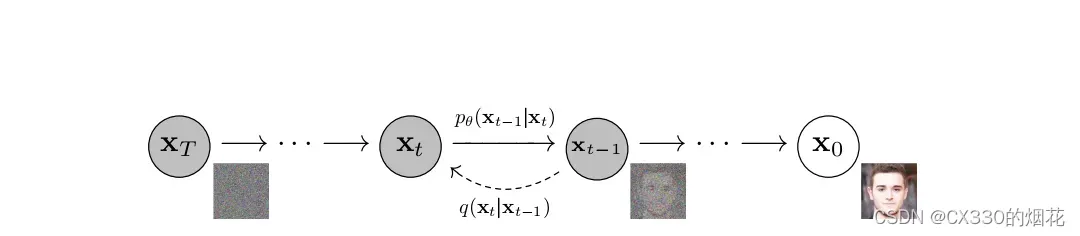
(上图,为其马尔可夫链)
3 公式结论

想看推导过程的可以看原论文Denoising Diffusion Probabilistic Models
三、优缺点
DDPM模型(深度确定性策略梯度模型)在强化学习领域具有其独特的优点和缺点。下面是对其优缺点的简要分析:
优点:
- 高效的动作采样:相较于其他强化学习方法(如基于采样的策略梯度方法),DDPM采用了确定性策略,这意味着在给定状态下,动作是唯一的,不需要进行采样。这大大减少了计算量,提高了训练效率。
- 稳定的训练过程:DDPM通过引入目标网络和软更新机制,使得训练过程更加稳定。这有助于避免训练过程中的震荡和发散,使得模型更容易收敛到好的解。
- 良好的性能:在连续动作空间的强化学习任务中,DDPM通常能够表现出良好的性能。它能够有效地处理复杂的状态空间和动作空间,从而解决一系列具有挑战性的任务。
缺点:
- 对超参数敏感:DDPM的性能在很大程度上取决于超参数的选择,如学习率、折扣因子等。不合适的超参数可能导致模型训练不稳定或性能不佳。因此,在实际应用中,需要进行大量的超参数调优。
- 难以处理高维输入:当状态空间或动作空间维度较高时,DDPM可能会面临挑战。高维输入可能导致模型复杂度增加,训练难度加大,甚至可能引发过拟合等问题。
- 对噪声敏感:由于DDPM采用确定性策略,它可能对输入中的噪声较为敏感。在实际应用中,如果状态表示或奖励函数存在噪声,可能会影响模型的稳定性和性能。
需要注意的是,以上优缺点是基于一般情况的总结,具体表现可能因任务和数据集的不同而有所差异。在实际应用中,应根据具体情况选择合适的模型和方法。
四、改进与完事
然后我又看到了这篇
LDM代表作
High-Resolution Image Synthesis with Latent Diffusion Models
https://arxiv.org/abs/2112.10752
原理概括
为了降低训练扩散模型的算力,LDMs使用一个Autoencoder去学习能尽量表达原始image space的低维空间表达(latent embedding),这样可以大大减少需要的算力。
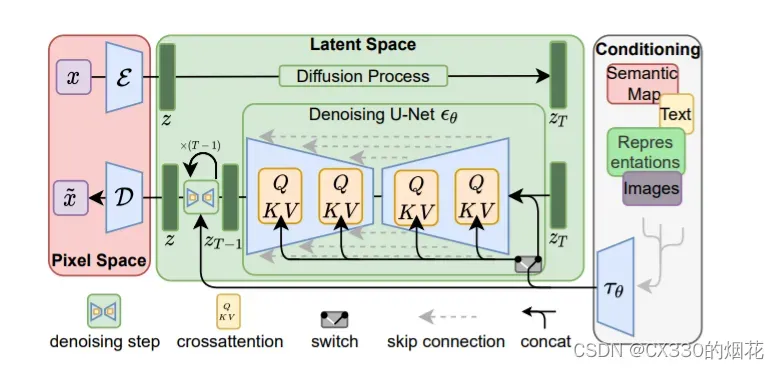
Latent Space(潜空间)
这里用了潜空间,在噪声环节,机器首先将这些特征向量和随机图转换至Latent Space(潜空间)。接着,根据这些特征向量的指引,机器会对随机图进行“降噪”处理,生成一个“中间产物”。
(以上是Wiki上的简单定义https://zh.m.wikipedia.org/zh-cn/%E6%BD%9C%E7%A9%BA%E9%97%B4_(%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0)
五、总结
AI绘画的未来发展方向看起来充满了无限可能。随着人工智能技术的不断进步,像Stable Diffusion这样的AI绘画将会更加智能化,能够更好地模仿人类艺术家的风格和技巧,使非艺术家也能创作出优秀的绘画作品。
版权声明:本文为博主作者:CX330的烟花原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2303_79387663/article/details/136774396