YOLOv5目录结构
├── data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
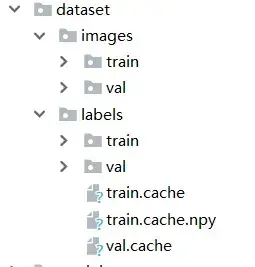
|——dataset :存放自己的数据集,分为images和labels两部分
├── models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
├── utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
├── weights:放置训练好的权重参数pt文件。
├── detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
├── train.py:训练自己的数据集的函数。
├── test.py:测试训练的结果的函数。
|—— hubconf.py:pytorch hub 相关代码
|—— sotabench.py: coco数据集测试脚本
|—— tutorial.ipynb: jupyter notebook 演示文件
├──requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
|—-run日志文件,每次训练的数据,包含权重文件,训练数据,直方图等
|——LICENCE 版权文件
以上就是yolov5项目代码的整体介绍。我们训练和测试自己的数据集基本就是利用到如上的代码。
data文件夹
- yaml多种数据集的配置文件,如coco,coco128,pascalvoc等
- hyps 超参数微调配置文件
- scripts文件夹存放着下载数据集额shell命令
在利用自己的数据集进行训练时,需要将配置文件中的路径进行修改,改成自己对应的数据集所在目录,最好复制+重命名。
train: E:/project/yolov5/yolov5-master/dataset/images/train # train images
val: E:/project/yolov5/yolov5-master/dataset/images/val # val images
dataset文件夹
存放着自己的数据集,但应按照image和label分开,同时每一个文件夹下,又应该分为train,val。
.cache文件为缓存文件,将数据加载到内存中,方便下次调用快速。
model文件夹
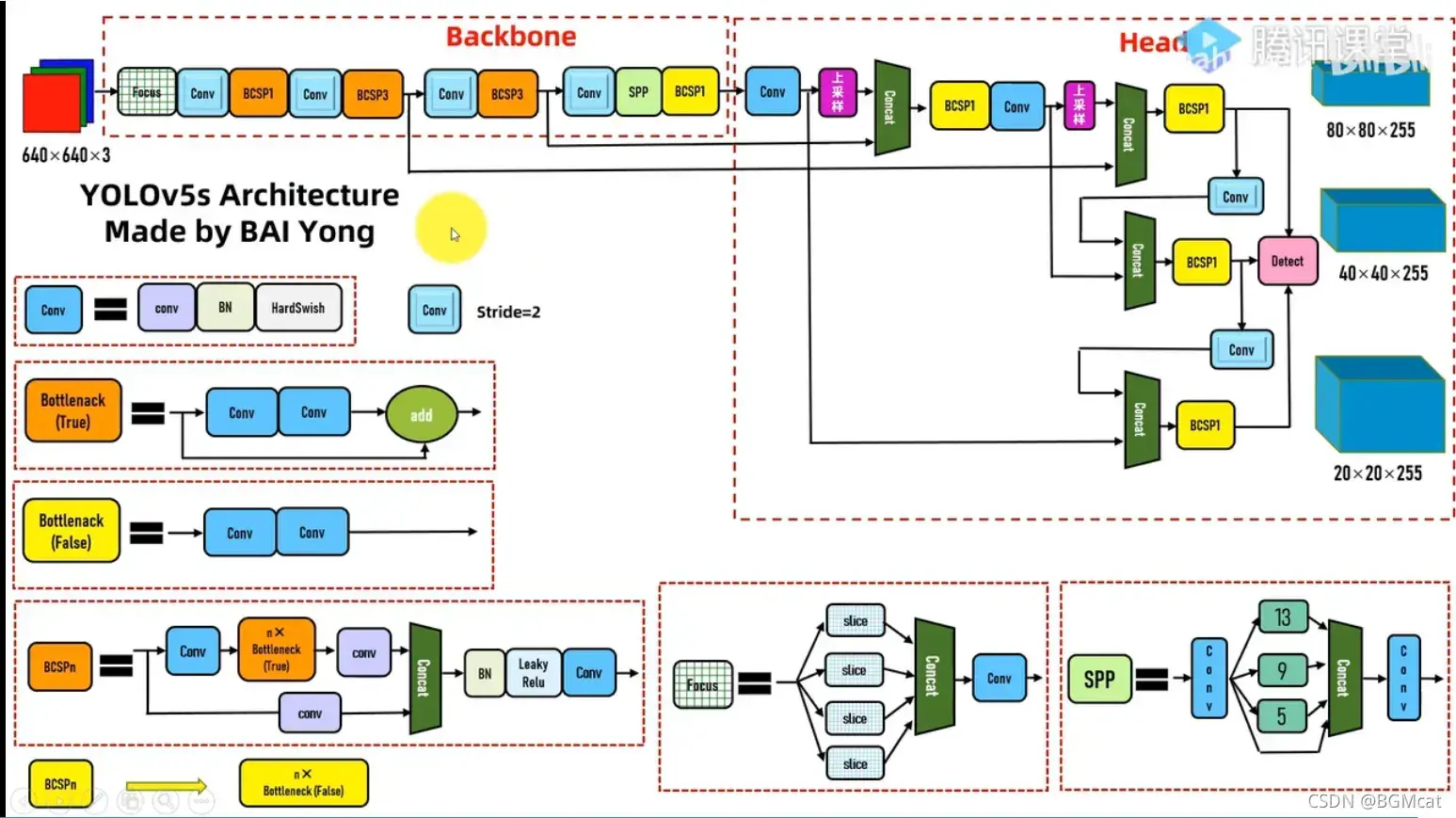
common.py 网络组件模块
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Common modules
"""
import logging
import math
import warnings
from copy import copy
from pathlib import Path
import numpy as np
import pandas as pd
import requests
import torch
import torch.nn as nn
from PIL import Image
from torch.cuda import amp
from utils.datasets import exif_transpose, letterbox
from utils.general import colorstr, increment_path, make_divisible, non_max_suppression, save_one_box, \
scale_coords, xyxy2xywh
from utils.plots import Annotator, colors
from utils.torch_utils import time_sync
LOGGER = logging.getLogger(__name__)
#为same卷积或same池化自动扩充
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
#标准的卷积 conv+BN+hardswish
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, 卷积核kernel, 步长stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):#正向传播
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
#深度可分离卷积网络
class DWConv(Conv):
# Depth-wise convolution class
def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
class TransformerLayer(nn.Module):
# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads):
super().__init__()
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
x = self.fc2(self.fc1(x)) + x
return x
class TransformerBlock(nn.Module):
# Vision Transformer https://arxiv.org/abs/2010.11929
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*[TransformerLayer(c2, num_heads) for _ in range(num_layers)])
self.c2 = c2
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
b, _, w, h = x.shape
p = x.flatten(2).unsqueeze(0).transpose(0, 3).squeeze(3)
return self.tr(p + self.linear(p)).unsqueeze(3).transpose(0, 3).reshape(b, self.c2, w, h)
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
#*把list拆分为一个个元素
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class C3TR(C3):
# C3 module with TransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)
class C3SPP(C3):
# C3 module with SPP()
def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = SPP(c_, c_, k)
class C3Ghost(C3):
# C3 module with GhostBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*[GhostBottleneck(c_, c_) for _ in range(n)])
#金字塔池化
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
#把宽和高填充整合到c空间中
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
class GhostConv(nn.Module):
# Ghost Convolution https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
super().__init__()
c_ = c2 // 2 # hidden channels
self.cv1 = Conv(c1, c_, k, s, None, g, act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
def forward(self, x):
y = self.cv1(x)
return torch.cat([y, self.cv2(y)], 1)
class GhostBottleneck(nn.Module):
# Ghost Bottleneck https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pw
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False),
Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity()
def forward(self, x):
return self.conv(x) + self.shortcut(x)
class Contract(nn.Module):
# Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
s = self.gain
x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
class Expand(nn.Module):
# Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
s = self.gain
x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
#自动调整大小
class AutoShape(nn.Module):
# YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
conf = 0.25 # NMS confidence threshold
iou = 0.45 # NMS IoU threshold
classes = None # (optional list) filter by class
multi_label = False # NMS multiple labels per box
max_det = 1000 # maximum number of detections per image
def __init__(self, model):
super().__init__()
self.model = model.eval()
def autoshape(self):
LOGGER.info('AutoShape already enabled, skipping... ') # model already converted to model.autoshape()
return self
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model.model[-1] # Detect()
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
@torch.no_grad()
def forward(self, imgs, size=640, augment=False, profile=False):
# Inference from various sources. For height=640, width=1280, RGB images example inputs are:
# file: imgs = 'data/images/zidane.jpg' # str or PosixPath
# URI: = 'https://ultralytics.com/images/zidane.jpg'
# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
# PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
# numpy: = np.zeros((640,1280,3)) # HWC
# torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
t = [time_sync()]
p = next(self.model.parameters()) # for device and type
if isinstance(imgs, torch.Tensor): # torch
with amp.autocast(enabled=p.device.type != 'cpu'):
return self.model(imgs.to(p.device).type_as(p), augment, profile) # inference
# Pre-process
n, imgs = (len(imgs), imgs) if isinstance(imgs, list) else (1, [imgs]) # number of images, list of images
shape0, shape1, files = [], [], [] # image and inference shapes, filenames
for i, im in enumerate(imgs):
f = f'image{i}' # filename
if isinstance(im, (str, Path)): # filename or uri
im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
im = np.asarray(exif_transpose(im))
elif isinstance(im, Image.Image): # PIL Image
im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
files.append(Path(f).with_suffix('.jpg').name)
if im.shape[0] < 5: # image in CHW
im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
im = im[..., :3] if im.ndim == 3 else np.tile(im[..., None], 3) # enforce 3ch input
s = im.shape[:2] # HWC
shape0.append(s) # image shape
g = (size / max(s)) # gain
shape1.append([y * g for y in s])
imgs[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
shape1 = [make_divisible(x, int(self.stride.max())) for x in np.stack(shape1, 0).max(0)] # inference shape
x = [letterbox(im, new_shape=shape1, auto=False)[0] for im in imgs] # pad
x = np.stack(x, 0) if n > 1 else x[0][None] # stack
x = np.ascontiguousarray(x.transpose((0, 3, 1, 2))) # BHWC to BCHW
x = torch.from_numpy(x).to(p.device).type_as(p) / 255. # uint8 to fp16/32
t.append(time_sync())
with amp.autocast(enabled=p.device.type != 'cpu'):
# Inference
y = self.model(x, augment, profile)[0] # forward
t.append(time_sync())
# Post-process
y = non_max_suppression(y, self.conf, iou_thres=self.iou, classes=self.classes,
multi_label=self.multi_label, max_det=self.max_det) # NMS
for i in range(n):
scale_coords(shape1, y[i][:, :4], shape0[i])
t.append(time_sync())
return Detections(imgs, y, files, t, self.names, x.shape)
class Detections:
# YOLOv5 detections class for inference results
def __init__(self, imgs, pred, files, times=None, names=None, shape=None):
super().__init__()
d = pred[0].device # device
gn = [torch.tensor([*[im.shape[i] for i in [1, 0, 1, 0]], 1., 1.], device=d) for im in imgs] # normalizations
self.imgs = imgs # list of images as numpy arrays
self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
self.names = names # class names
self.files = files # image filenames
self.xyxy = pred # xyxy pixels
self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
self.n = len(self.pred) # number of images (batch size)
self.t = tuple((times[i + 1] - times[i]) * 1000 / self.n for i in range(3)) # timestamps (ms)
self.s = shape # inference BCHW shape
def display(self, pprint=False, show=False, save=False, crop=False, render=False, save_dir=Path('')):
crops = []
for i, (im, pred) in enumerate(zip(self.imgs, self.pred)):
s = f'image {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
if pred.shape[0]:
for c in pred[:, -1].unique():
n = (pred[:, -1] == c).sum() # detections per class
s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
if show or save or render or crop:
annotator = Annotator(im, example=str(self.names))
for *box, conf, cls in reversed(pred): # xyxy, confidence, class
label = f'{self.names[int(cls)]} {conf:.2f}'
if crop:
file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
crops.append({'box': box, 'conf': conf, 'cls': cls, 'label': label,
'im': save_one_box(box, im, file=file, save=save)})
else: # all others
annotator.box_label(box, label, color=colors(cls))
im = annotator.im
else:
s += '(no detections)'
im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
if pprint:
LOGGER.info(s.rstrip(', '))
if show:
im.show(self.files[i]) # show
if save:
f = self.files[i]
im.save(save_dir / f) # save
if i == self.n - 1:
LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
if render:
self.imgs[i] = np.asarray(im)
if crop:
if save:
LOGGER.info(f'Saved results to {save_dir}\n')
return crops
def print(self):
self.display(pprint=True) # print results
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {tuple(self.s)}' %
self.t)
def show(self):
self.display(show=True) # show results
def save(self, save_dir='runs/detect/exp'):
save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) # increment save_dir
self.display(save=True, save_dir=save_dir) # save results
def crop(self, save=True, save_dir='runs/detect/exp'):
save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) if save else None
return self.display(crop=True, save=save, save_dir=save_dir) # crop results
def render(self):
self.display(render=True) # render results
return self.imgs
def pandas(self):
# return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
new = copy(self) # return copy
ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
return new
def tolist(self):
# return a list of Detections objects, i.e. 'for result in results.tolist():'
x = [Detections([self.imgs[i]], [self.pred[i]], self.names, self.s) for i in range(self.n)]
for d in x:
for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
setattr(d, k, getattr(d, k)[0]) # pop out of list
return x
def __len__(self):
return self.n
#用于二级分类
class Classify(nn.Module):
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
self.flat = nn.Flatten()
def forward(self, x):
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
return self.flat(self.conv(z)) # flatten to x(b,c2)
experimental.py 实验性质代码
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Experimental modules
"""
import numpy as np
import torch
import torch.nn as nn
from models.common import Conv
from utils.downloads import attempt_download
class CrossConv(nn.Module):
# Cross Convolution Downsample
def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
# ch_in, ch_out, kernel, stride, groups, expansion, shortcut
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, (1, k), (1, s))
self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class Sum(nn.Module):
# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
def __init__(self, n, weight=False): # n: number of inputs
super().__init__()
self.weight = weight # apply weights boolean
self.iter = range(n - 1) # iter object
if weight:
self.w = nn.Parameter(-torch.arange(1., n) / 2, requires_grad=True) # layer weights
def forward(self, x):
y = x[0] # no weight
if self.weight:
w = torch.sigmoid(self.w) * 2
for i in self.iter:
y = y + x[i + 1] * w[i]
else:
for i in self.iter:
y = y + x[i + 1]
return y
class MixConv2d(nn.Module):
# Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True):
super().__init__()
groups = len(k)
if equal_ch: # equal c_ per group
i = torch.linspace(0, groups - 1E-6, c2).floor() # c2 indices
c_ = [(i == g).sum() for g in range(groups)] # intermediate channels
else: # equal weight.numel() per group
b = [c2] + [0] * groups
a = np.eye(groups + 1, groups, k=-1)
a -= np.roll(a, 1, axis=1)
a *= np.array(k) ** 2
a[0] = 1
c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
self.m = nn.ModuleList([nn.Conv2d(c1, int(c_[g]), k[g], s, k[g] // 2, bias=False) for g in range(groups)])
self.bn = nn.BatchNorm2d(c2)
self.act = nn.LeakyReLU(0.1, inplace=True)
def forward(self, x):
return x + self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
#模型集成
class Ensemble(nn.ModuleList):
# Ensemble of models
def __init__(self):
super().__init__()
def forward(self, x, augment=False, profile=False, visualize=False):
y = []
for module in self:
y.append(module(x, augment, profile, visualize)[0])
# y = torch.stack(y).max(0)[0] # max ensemble
# y = torch.stack(y).mean(0) # mean ensemble
y = torch.cat(y, 1) # nms ensemble
return y, None # inference, train output
#加载模型权重文件,并构造模型
def attempt_load(weights, map_location=None, inplace=True, fuse=True):
from models.yolo import Detect, Model
# Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
model = Ensemble()
for w in weights if isinstance(weights, list) else [weights]:
ckpt = torch.load(attempt_download(w), map_location=map_location) # load,下载不在本地的权重文件
if fuse:
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
else:
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse
# Compatibility updates
for m in model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
m.inplace = inplace # pytorch 1.7.0 compatibility
if type(m) is Detect:
if not isinstance(m.anchor_grid, list): # new Detect Layer compatibility
delattr(m, 'anchor_grid')
setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
elif type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if len(model) == 1:
return model[-1] # return model
else:
print(f'Ensemble created with {weights}\n')
for k in ['names']:
setattr(model, k, getattr(model[-1], k))
model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
return model # return ensemble
tf.py 模型导出脚本,负责将模型转化,TensorFlow, Keras and TFLite versions of YOLOv5
yolo.py 整体网络代码
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
YOLO-specific modules
Usage:
$ python path/to/models/yolo.py --cfg yolov5s.yaml
"""
import argparse
import sys
from copy import deepcopy
from pathlib import Path
FILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
# ROOT = ROOT.relative_to(Path.cwd()) # relative
from models.common import *
from models.experimental import *
from utils.autoanchor import check_anchor_order
from utils.general import check_yaml, make_divisible, print_args, set_logging
from utils.plots import feature_visualization
from utils.torch_utils import copy_attr, fuse_conv_and_bn, initialize_weights, model_info, scale_img, \
select_device, time_sync
try:
import thop # for FLOPs computation
except ImportError:
thop = None
LOGGER = logging.getLogger(__name__)
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
#模型中保存的参数有两种:y一种是反向传播需要被optimizer更新的,称之为parameter
#一种是反向传播不需要被optimizer更新,称为buffer
#第二种参数需要创建tensor,然后将tensor通过register——buffer进行注册
#可以通过model。buffers()返回,注册完成后参数也会自动保存到orderdict中去
#optim.step 只能更新nn.parameter 类型的参数
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv 1*1 卷积
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)#预测框坐标信息
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid
#网络模型类
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once,初始化偏执
# Init weights, biases
initialize_weights(self)#初始化权重
self.info()#每一层的信息
LOGGER.info('')
def forward(self, x, augment=False, profile=False, visualize=False):
if augment:
return self._forward_augment(x) # augmented inference, None
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self._forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, 1), None # augmented inference, train
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
def _descale_pred(self, p, flips, scale, img_size):
# de-scale predictions following augmented inference (inverse operation)
if self.inplace:
p[..., :4] /= scale # de-scale
if flips == 2:
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
elif flips == 3:
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
else:
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
p = torch.cat((x, y, wh, p[..., 4:]), -1)
return p
def _clip_augmented(self, y):
# Clip YOLOv5 augmented inference tails
nl = self.model[-1].nl # number of detection layers (P3-P5)
g = sum(4 ** x for x in range(nl)) # grid points
e = 1 # exclude layer count
i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
y[0] = y[0][:, :-i] # large
i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
y[-1] = y[-1][:, i:] # small
return y
def _profile_one_layer(self, m, x, dt):
c = isinstance(m, Detect) # is final layer, copy input as inplace fix
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
if c:
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
LOGGER.info(
('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self
def autoshape(self): # add AutoShape module
LOGGER.info('Adding AutoShape... ')
m = AutoShape(self) # wrap model
copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
return m
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, Detect):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
#解析网络模型配置文件,并构建模型
def parse_model(d, ch): # model_dict, input_channels(3)
LOGGER.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
#将模型结构的depth_multiple,width_multiple提取出来,赋值给gd,gw
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
# 控制深度
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
c1, c2 = ch[f], args[0] #c1:3
if c2 != no: # if not output
#控制宽度(卷积核个数)
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
#*arg表示会接收任意数量个参数,调用时打包为一个元组传入实参
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n_, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
if __name__ == '__main__':
#建立参数解析对象
parser = argparse.ArgumentParser()
#添加属性
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--profile', action='store_true', help='profile model speed')
opt = parser.parse_args()
opt.cfg = check_yaml(opt.cfg) # check YAML
print_args(FILE.stem, opt)
set_logging()
device = select_device(opt.device)
# Create model
model = Model(opt.cfg).to(device)
model.train()
# Profile
if opt.profile:
img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
y = model(img, profile=True)
# Tensorboard (not working https://github.com/ultralytics/yolov5/issues/2898)
# from torch.utils.tensorboard import SummaryWriter
# tb_writer = SummaryWriter('.')
# LOGGER.info("Run 'tensorboard --logdir=models' to view tensorboard at http://localhost:6006/")
# tb_writer.add_graph(torch.jit.trace(model, img, strict=False), []) # add model graph
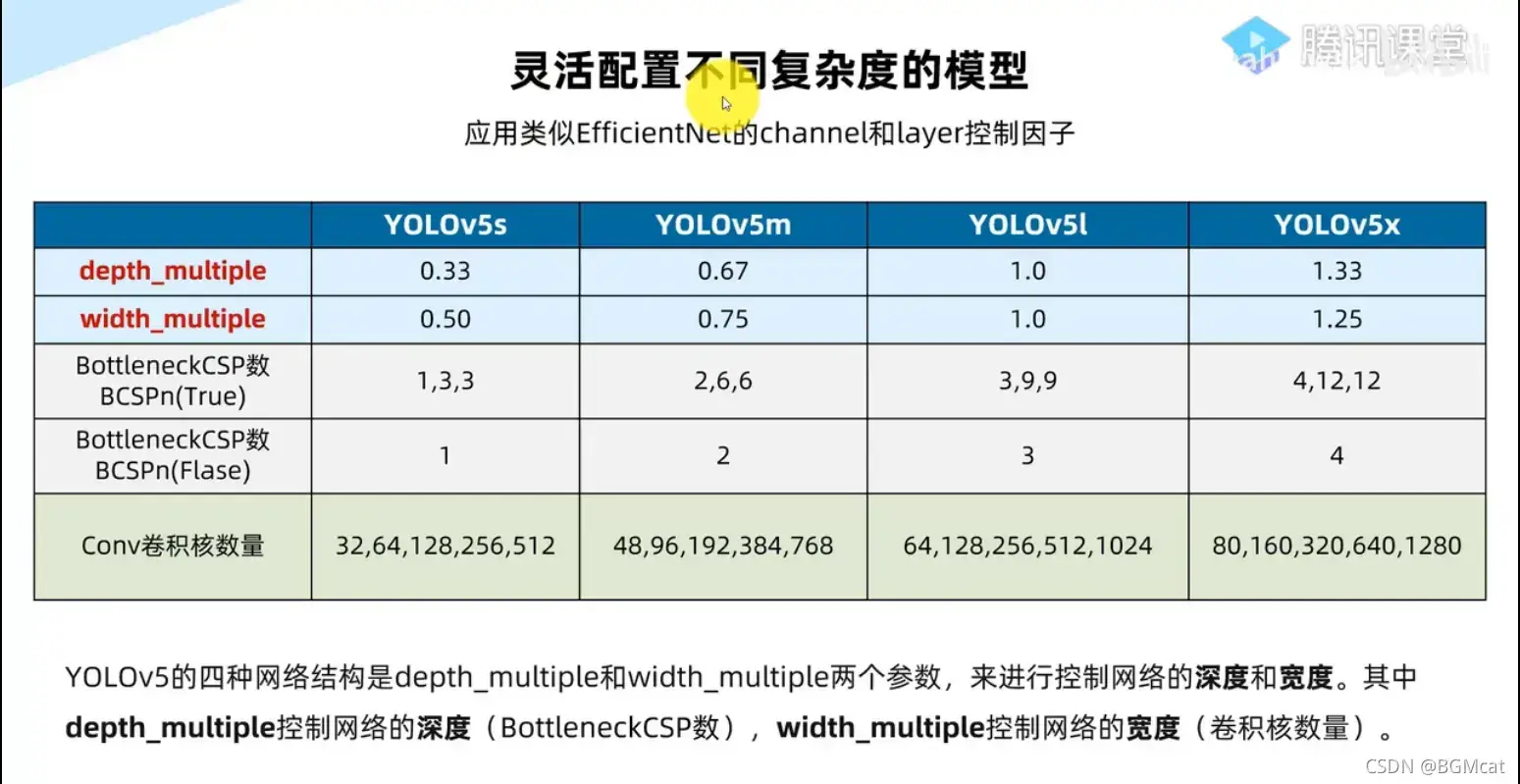
yolo5s.yaml 网络模型配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes 类别数
depth_multiple: 0.33 # model depth multiple 控制模型的深度
width_multiple: 0.50 # layer channel multiple 控制conv 通道的个数,卷积核数量
#depth_multiple: 表示BottleneckCSP模块的层缩放因子,将所有的BotleneckCSP模块的B0ttleneck乘上该参数得到最终个数
#width_multiple表示卷积通道的缩放因子,就是将配置里的backbone和head部分有关conv通道的设置,全部乘以该系数
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
#from 列参数 :当前模块输入来自那一层输出,-1 表示是从上一层获得的输入
#number 列参数:本模块重复次数,1 表示只有一个,3 表示有三个相同的模块
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 128表示128个卷积核,3 表示3*3卷积核,2表示步长为2
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
#作者没有分neck模块,所以head部分包含了panet+detect部分
head:
[[-1, 1, Conv, [512, 1, 1]], #上采样
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
run 文件夹
train文件夹存放着训练数据时记录的数据过程
detect文件夹存放着使用训练好的模型,每次预测判断的数据
utils文件夹
目标检测性能指标
检测精度
- precision,recall,f1 score
- iou(intersection over union)交并比
- P-R curve (precision-recall curve)
- AP (average precison)
- mAP (mean ap)
检测速度
- 前传耗时
- 每秒帧数FPS
- 浮点运算量 FLOPS
activation.py 激活函数相关代码
augmentations.py 图片扩展变换相关函数
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Image augmentation functions
"""
import logging
import math
import random
import cv2
import numpy as np
from utils.general import colorstr, segment2box, resample_segments, check_version
from utils.metrics import bbox_ioa
class Albumentations:
# YOLOv5 Albumentations class (optional, only used if package is installed)
def __init__(self):
self.transform = None
try:
import albumentations as A
check_version(A.__version__, '1.0.3') # version requirement
self.transform = A.Compose([
A.Blur(p=0.01),
A.MedianBlur(p=0.01),
A.ToGray(p=0.01),
A.CLAHE(p=0.01),
A.RandomBrightnessContrast(p=0.0),
A.RandomGamma(p=0.0),
A.ImageCompression(quality_lower=75, p=0.0)],
bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
logging.info(colorstr('albumentations: ') + ', '.join(f'{x}' for x in self.transform.transforms if x.p))
except ImportError: # package not installed, skip
pass
except Exception as e:
logging.info(colorstr('albumentations: ') + f'{e}')
def __call__(self, im, labels, p=1.0):
if self.transform and random.random() < p:
new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
return im, labels
def augment_hsv(im, hgain=0.5, sgain=0.5, vgain=0.5):
# HSV color-space augmentation
if hgain or sgain or vgain:
r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
hue, sat, val = cv2.split(cv2.cvtColor(im, cv2.COLOR_BGR2HSV))
dtype = im.dtype # uint8
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=im) # no return needed
def hist_equalize(im, clahe=True, bgr=False):
# Equalize histogram on BGR image 'im' with im.shape(n,m,3) and range 0-255
yuv = cv2.cvtColor(im, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
if clahe:
c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
yuv[:, :, 0] = c.apply(yuv[:, :, 0])
else:
yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
def replicate(im, labels):
# Replicate labels
h, w = im.shape[:2]
boxes = labels[:, 1:].astype(int)
x1, y1, x2, y2 = boxes.T
s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels)
for i in s.argsort()[:round(s.size * 0.5)]: # smallest indices
x1b, y1b, x2b, y2b = boxes[i]
bh, bw = y2b - y1b, x2b - x1b
yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
im[y1a:y2a, x1a:x2a] = im[y1b:y2b, x1b:x2b] # im4[ymin:ymax, xmin:xmax]
labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
return im, labels
#缩放图片,resize保持图片的宽高比,剩下的部分有灰色填充
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
#缩放到输入大小img_size的时候,如果没有设置上采样,则只能下采样
#上采用会使图片变得模糊,影响性能
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle 获取最小的矩形填充
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
#scaleFill为True则不进行填充
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
#计算上下左右填充大小
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
#随机透视变换
#计算方法为坐标向量和变换矩阵的乘积
def random_perspective(im, targets=(), segments=(), degrees=10, translate=.1, scale=.1, shear=10, perspective=0.0,
border=(0, 0)):
# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
# targets = [cls, xyxy]
height = im.shape[0] + border[0] * 2 # shape(h,w,c)
width = im.shape[1] + border[1] * 2
# Center
C = np.eye(3)
C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
# Perspective
P = np.eye(3)
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
# Rotation and Scale
R = np.eye(3)
a = random.uniform(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
s = random.uniform(1 - scale, 1 + scale)
# s = 2 ** random.uniform(-scale, scale)
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear
S = np.eye(3)
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Translation
T = np.eye(3)
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
# Combined rotation matrix
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if perspective:
im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
else: # affine
im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
# Visualize
# import matplotlib.pyplot as plt
# ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
# ax[0].imshow(im[:, :, ::-1]) # base
# ax[1].imshow(im2[:, :, ::-1]) # warped
# Transform label coordinates
n = len(targets)
if n:
use_segments = any(x.any() for x in segments)
new = np.zeros((n, 4))
if use_segments: # warp segments
segments = resample_segments(segments) # upsample
for i, segment in enumerate(segments):
xy = np.ones((len(segment), 3))
xy[:, :2] = segment
xy = xy @ M.T # transform
xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
# clip
new[i] = segment2box(xy, width, height)
else: # warp boxes
xy = np.ones((n * 4, 3))
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform
xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip
new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
# filter candidates
i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
targets = targets[i]
targets[:, 1:5] = new[i]
return im, targets
def copy_paste(im, labels, segments, p=0.5):
# Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
n = len(segments)
if p and n:
h, w, c = im.shape # height, width, channels
im_new = np.zeros(im.shape, np.uint8)
for j in random.sample(range(n), k=round(p * n)):
l, s = labels[j], segments[j]
box = w - l[3], l[2], w - l[1], l[4]
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
labels = np.concatenate((labels, [[l[0], *box]]), 0)
segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
result = cv2.bitwise_and(src1=im, src2=im_new)
result = cv2.flip(result, 1) # augment segments (flip left-right)
i = result > 0 # pixels to replace
# i[:, :] = result.max(2).reshape(h, w, 1) # act over ch
im[i] = result[i] # cv2.imwrite('debug.jpg', im) # debug
return im, labels, segments
#cutout数据增强,填充随机颜色
def cutout(im, labels, p=0.5):
# Applies image cutout augmentation https://arxiv.org/abs/1708.04552
if random.random() < p:
h, w = im.shape[:2]
scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
for s in scales:
mask_h = random.randint(1, int(h * s)) # create random masks
mask_w = random.randint(1, int(w * s))
# box
xmin = max(0, random.randint(0, w) - mask_w // 2)
ymin = max(0, random.randint(0, h) - mask_h // 2)
xmax = min(w, xmin + mask_w)
ymax = min(h, ymin + mask_h)
# apply random color mask
im[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
# return unobscured labels
if len(labels) and s > 0.03:
box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
labels = labels[ioa < 0.60] # remove >60% obscured labels
return labels
def mixup(im, labels, im2, labels2):
# Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
im = (im * r + im2 * (1 - r)).astype(np.uint8)
labels = np.concatenate((labels, labels2), 0)
return im, labels
#挑选合适的目标框送入训练,阈值
def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
# Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
autoanchor.py 自动描边相关函数
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Auto-anchor utils
"""
import random
import numpy as np
import torch
import yaml
from tqdm import tqdm
from utils.general import colorstr
#检查anchor顺序和stride的顺序是否一致
def check_anchor_order(m):
# Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
a = m.anchors.prod(-1).view(-1) # anchor area
da = a[-1] - a[0] # delta a
ds = m.stride[-1] - m.stride[0] # delta s
if da.sign() != ds.sign(): # same order
print('Reversing anchor order')
m.anchors[:] = m.anchors.flip(0)
#自动绘制外边框,描框
def check_anchors(dataset, model, thr=4.0, imgsz=640):
# Check anchor fit to data, recompute if necessary
prefix = colorstr('autoanchor: ')
print(f'\n{prefix}Analyzing anchors... ', end='')
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
def metric(k): # compute metric
r = wh[:, None] / k[None]
x = torch.min(r, 1. / r).min(2)[0] # ratio metric wh 方向找最小值
best = x.max(1)[0] # best_x nx9个anchor中找最大值
aat = (x > 1. / thr).float().sum(1).mean() # anchors above threshold
bpr = (best > 1. / thr).float().mean() # best possible recall
return bpr, aat
anchors = m.anchors.clone() * m.stride.to(m.anchors.device).view(-1, 1, 1) # current anchors
bpr, aat = metric(anchors.cpu().view(-1, 2))
print(f'anchors/target = {aat:.2f}, Best Possible Recall (BPR) = {bpr:.4f}', end='')
if bpr < 0.98: # threshold to recompute,如果bpr小于98,则根据k-mean算法聚类新的描框
print('. Attempting to improve anchors, please wait...')
na = m.anchors.numel() // 2 # number of anchors
try:
anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
except Exception as e:
print(f'{prefix}ERROR: {e}')
new_bpr = metric(anchors)[0]
if new_bpr > bpr: # replace anchors
anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
m.anchors[:] = anchors.clone().view_as(m.anchors) / m.stride.to(m.anchors.device).view(-1, 1, 1) # loss
check_anchor_order(m)
print(f'{prefix}New anchors saved to model. Update model *.yaml to use these anchors in the future.')
else:
print(f'{prefix}Original anchors better than new anchors. Proceeding with original anchors.')
print('') # newline
#anchor做kmean处理,用到了进化算法
def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
""" Creates kmeans-evolved anchors from training dataset
Arguments:
dataset: path to data.yaml, or a loaded dataset
n: number of anchors
img_size: image size used for training
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
gen: generations to evolve anchors using genetic algorithm
verbose: print all results
Return:
k: kmeans evolved anchors
Usage:
from utils.autoanchor import *; _ = kmean_anchors()
"""
from scipy.cluster.vq import kmeans
thr = 1. / thr
prefix = colorstr('autoanchor: ')
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
print(f'{prefix}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr')
print(f'{prefix}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, '
f'past_thr={x[x > thr].mean():.3f}-mean: ', end='')
for i, x in enumerate(k):
print('%i,%i' % (round(x[0]), round(x[1])), end=', ' if i < len(k) - 1 else '\n') # use in *.cfg
return k
if isinstance(dataset, str): # *.yaml file
with open(dataset, errors='ignore') as f:
data_dict = yaml.safe_load(f) # model dict
from utils.datasets import LoadImagesAndLabels
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
# Get label wh
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
# Filter
i = (wh0 < 3.0).any(1).sum()
if i:
print(f'{prefix}WARNING: Extremely small objects found. {i} of {len(wh0)} labels are < 3 pixels in size.')
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# wh = wh * (np.random.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
# Kmeans calculation
print(f'{prefix}Running kmeans for {n} anchors on {len(wh)} points...')
s = wh.std(0) # sigmas for whitening
k, dist = kmeans(wh / s, n, iter=30) # points, mean distance,使用scipy包含的kmeans函数
assert len(k) == n, f'{prefix}ERROR: scipy.cluster.vq.kmeans requested {n} points but returned only {len(k)}'
k *= s
wh = torch.tensor(wh, dtype=torch.float32) # filtered
wh0 = torch.tensor(wh0, dtype=torch.float32) # unfiltered
k = print_results(k)
# Plot
# k, d = [None] * 20, [None] * 20
# for i in tqdm(range(1, 21)):
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
# ax = ax.ravel()
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
# fig.savefig('wh.png', dpi=200)
# Evolve
npr = np.random
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), desc=f'{prefix}Evolving anchors with Genetic Algorithm:') # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
kg = (k.copy() * v).clip(min=2.0)
fg = anchor_fitness(kg)
if fg > f:#有更好的fitness
f, k = fg, kg.copy()#使用进化后的描框值
pbar.desc = f'{prefix}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
if verbose:
print_results(k)
return print_results(k)
callback.py
datasets.py 读取数据集,并做处理的相关函数
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Dataloaders and dataset utils
"""
import glob
import hashlib
import json
import logging
import os
import random
import shutil
import time
from itertools import repeat
from multiprocessing.pool import ThreadPool, Pool
from pathlib import Path
from threading import Thread
from zipfile import ZipFile
import cv2
import numpy as np
import torch
import torch.nn.functional as F
import yaml
from PIL import Image, ExifTags
from torch.utils.data import Dataset
from tqdm import tqdm
from utils.augmentations import Albumentations, augment_hsv, copy_paste, letterbox, mixup, random_perspective
from utils.general import check_dataset, check_requirements, check_yaml, clean_str, segments2boxes, \
xywh2xyxy, xywhn2xyxy, xyxy2xywhn, xyn2xy
from utils.torch_utils import torch_distributed_zero_first
# Parameters
HELP_URL = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
#图片格式
IMG_FORMATS = ['bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng', 'webp', 'mpo'] # acceptable image suffixes
#视频格式
VID_FORMATS = ['mov', 'avi', 'mp4', 'mpg', 'mpeg', 'm4v', 'wmv', 'mkv'] # acceptable video suffixes
NUM_THREADS = min(8, os.cpu_count()) # number of multiprocessing threads
# Get orientation exif tag
# 是专门为数码相机相片设计的
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == 'Orientation':
break
#返回文件列表的hash值
def get_hash(paths):
# Returns a single hash value of a list of paths (files or dirs)
size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
h = hashlib.md5(str(size).encode()) # hash sizes
h.update(''.join(paths).encode()) # hash paths
return h.hexdigest() # return hash
#获取图片的宽高信息
def exif_size(img):
# Returns exif-corrected PIL size
s = img.size # (width, height)
try:
rotation = dict(img._getexif().items())[orientation]#调整数据相机照片方向
if rotation == 6: # rotation 270
s = (s[1], s[0])
elif rotation == 8: # rotation 90
s = (s[1], s[0])
except:
pass
return s
def exif_transpose(image):
"""
Transpose a PIL image accordingly if it has an EXIF Orientation tag.
From https://github.com/python-pillow/Pillow/blob/master/src/PIL/ImageOps.py
:param image: The image to transpose.
:return: An image.
"""
exif = image.getexif()
orientation = exif.get(0x0112, 1) # default 1
if orientation > 1:
method = {2: Image.FLIP_LEFT_RIGHT,
3: Image.ROTATE_180,
4: Image.FLIP_TOP_BOTTOM,
5: Image.TRANSPOSE,
6: Image.ROTATE_270,
7: Image.TRANSVERSE,
8: Image.ROTATE_90,
}.get(orientation)
if method is not None:
image = image.transpose(method)
del exif[0x0112]
image.info["exif"] = exif.tobytes()
return image
def create_dataloader(path, imgsz, batch_size, stride, single_cls=False, hyp=None, augment=False, cache=False, pad=0.0,
rect=False, rank=-1, workers=8, image_weights=False, quad=False, prefix=''):
# Make sure only the first process in DDP process the dataset first, and the following others can use the cache
with torch_distributed_zero_first(rank):
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
batch_size = min(batch_size, len(dataset))
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, workers]) # number of workers
sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
loader = torch.utils.data.DataLoader if image_weights else InfiniteDataLoader
# Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
dataloader = loader(dataset,
batch_size=batch_size,
num_workers=0,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
return dataloader, dataset
class InfiniteDataLoader(torch.utils.data.dataloader.DataLoader):
""" Dataloader that reuses workers
Uses same syntax as vanilla DataLoader
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()
def __len__(self):
return len(self.batch_sampler.sampler)
def __iter__(self):
for i in range(len(self)):
yield next(self.iterator)
class _RepeatSampler(object):
""" Sampler that repeats forever
Args:
sampler (Sampler)
"""
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
yield from iter(self.sampler)
#定义迭代器,用于detect.py
class LoadImages:
# YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
def __init__(self, path, img_size=640, stride=32, auto=True):
p = str(Path(path).resolve()) # os-agnostic absolute path
#采用正则表达式来提取图片,视频,可以获取文件路径
if '*' in p:
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p):
files = [p] # files
else:
raise Exception(f'ERROR: {p} does not exist')
#提取照片和视频的文件路径
images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
# 获取图片与视频的数量
ni, nv = len(images), len(videos)
self.img_size = img_size#图片的大小
self.stride = stride
self.files = images + videos#整合到一个列表
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv
#初始化模块信息,对于image和video做不同的处理
self.mode = 'image'
self.auto = auto
if any(videos):#如果包含视频文件,就初始化OpenCV中的视频模块
self.new_video(videos[0]) # new video
else:
self.cap = None
#打印提示信息
assert self.nf > 0, f'No images or videos found in {p}. ' \
f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}'
def __iter__(self):
self.count = 0
return self
def __next__(self):
if self.count == self.nf:#数据是否读完了
raise StopIteration
path = self.files[self.count]
if self.video_flag[self.count]:#如果是视频
# Read video
self.mode = 'video'
ret_val, img0 = self.cap.read()
if not ret_val:
self.count += 1
self.cap.release()#释放对象
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1
print(f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: ', end='')
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
assert img0 is not None, 'Image Not Found ' + path
print(f'image {self.count}/{self.nf} {path}: ', end='')
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride, auto=self.auto)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)#将数组内存转化为连续,提高运行速度
return path, img, img0, self.cap#返回resize+pad图片,原始图片,视频对象
def new_video(self, path):
self.frame = 0#记录帧数
self.cap = cv2.VideoCapture(path)#初始化视频对象
self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))#获取总帧数
def __len__(self):
return self.nf # number of files
#未使用
class LoadWebcam: # for inference
# YOLOv5 local webcam dataloader, i.e. `python detect.py --source 0`
def __init__(self, pipe='0', img_size=640, stride=32):
# self.mode = 'cap'
self.img_size = img_size
self.stride = stride
self.pipe = eval(pipe) if pipe.isnumeric() else pipe
self.cap = cv2.VideoCapture(self.pipe) # video capture object
self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if cv2.waitKey(1) == ord('q'): # q to quit
self.cap.release()
cv2.destroyAllWindows()
raise StopIteration
# Read frame
ret_val, img0 = self.cap.read()
img0 = cv2.flip(img0, 1) # flip left-right
# Print
assert ret_val, f'Camera Error {self.pipe}'
img_path = 'webcam.jpg'
print(f'webcam {self.count}: ', end='')
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return img_path, img, img0, self.cap
def __len__(self):
return 0
#定义迭代器,用于detect.py文件,处理摄像头
'''
cv2视频函数;
cap.grap()获取视频的下一帧,返回T/F
cap.retrieve()在grap后使用,对获取的帧进行解码,返回T/F
cap.read(frame)结合了grap和retrieve的功能,抓取下一帧并解码
'''
class LoadStreams:
#多个ip或者rtsp摄像头
# YOLOv5 streamloader, i.e. `python detect.py --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`
def __init__(self, sources='streams.txt', img_size=640, stride=32, auto=True):
self.mode = 'stream'
self.img_size = img_size
self.stride = stride
#如果sources是一个保存了多个视频流的文件
#获取每一个视频流,保存为一个文件
if os.path.isfile(sources):
with open(sources, 'r') as f:
sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
else:
sources = [sources]
n = len(sources)
self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
self.sources = [clean_str(x) for x in sources] # clean source names for later,视频流个数
self.auto = auto
for i, s in enumerate(sources): # index, source
# Start thread to read frames from video stream
print(f'{i + 1}/{n}: {s}... ', end='')#打印当前视频,总视频数,视频流地址
if 'youtube.com/' in str(s) or 'youtu.be/' in str(s): # if source is YouTube video
check_requirements(('pafy', 'youtube_dl'))
import pafy
s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam #如果source = 0 就打开摄像头,否则打开视频流的地址
cap = cv2.VideoCapture(s)
assert cap.isOpened(), f'Failed to open {s}'
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))#视频宽高
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.fps[i] = max(cap.get(cv2.CAP_PROP_FPS) % 100, 0) or 30.0 # 30 FPS fallback,视频帧率
self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
_, self.imgs[i] = cap.read() # guarantee first frame
#多线程读取,daemon=True 表示守护线程
self.threads[i] = Thread(target=self.update, args=([i, cap, s]), daemon=True)
print(f" success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
self.threads[i].start()
print('') # newline
# check for common shapes
#获取进行resize+pad之后的shape,letter函数默认按照矩形推理填充
s = np.stack([letterbox(x, self.img_size, stride=self.stride, auto=self.auto)[0].shape for x in self.imgs])
self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
if not self.rect:#画面不同形状警告
print('WARNING: Different stream shapes detected. For optimal performance supply similarly-shaped streams.')
def update(self, i, cap, stream):
# Read stream `i` frames in daemon thread
n, f, read = 0, self.frames[i], 1 # frame number, frame array, inference every 'read' frame
while cap.isOpened() and n < f:
n += 1
# _, self.imgs[index] = cap.read()
cap.grab()
if n % read == 0:#
success, im = cap.retrieve()
if success:
self.imgs[i] = im
else:
print('WARNING: Video stream unresponsive, please check your IP camera connection.')
self.imgs[i] *= 0
cap.open(stream) # re-open stream if signal was lost
time.sleep(1 / self.fps[i]) # wait time
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
#q键退出
if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
cv2.destroyAllWindows()
raise StopIteration
# Letterbox
img0 = self.imgs.copy()
# letterbox对图片进行缩放
img = [letterbox(x, self.img_size, stride=self.stride, auto=self.rect and self.auto)[0] for x in img0]
# Stack
#t图片拼接以前
img = np.stack(img, 0)
# Convert
img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
img = np.ascontiguousarray(img)
return self.sources, img, img0, None
def __len__(self):
return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
#返回标记文件,。txt
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
#自定义数据集,重写len,getitem方法
class LoadImagesAndLabels(Dataset):
# YOLOv5 train_loader/val_loader, loads images and labels for training and validation
cache_version = 0.6 # dataset labels *.cache version
def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, image_weights=False,
cache_images=False, single_cls=False, stride=32, pad=0.0, prefix=''):
self.img_size = img_size#输入图片大小
self.augment = augment#数据增强
self.hyp = hyp#超参数
self.image_weights = image_weights#图片采样权重
self.rect = False if image_weights else rect#矩形训练
#mosaic数据增强
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
#mosic数据边界增强
self.mosaic_border = [-img_size // 2, -img_size // 2]
self.stride = stride#模型下采样步长
self.path = path
self.albumentations = Albumentations() if augment else None
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
#获取数据集路径,包含图片路径txt文件或者图片的文件夹
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / '**' / '*.*'), recursive=True)#获取所有匹配的文件路径
# f = list(p.rglob('**/*.*')) # pathlib
elif p.is_file(): # file
with open(p, 'r') as t:
t = t.read().strip().splitlines() #获取图片路径,切换相对路径
parent = str(p.parent) + os.sep#获取上级父目录,os.sep为自适应系统分隔符,Windows \ linux为 / mac 为:
f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
else:
raise Exception(f'{prefix}{p} does not exist')
#图片排序
self.img_files = sorted([x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS])
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in img_formats]) # pathlib
assert self.img_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\nSee {HELP_URL}')
# Check cache
self.label_files = img2label_paths(self.img_files) # labels,返回标签
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')#cache labels,将标签加载到内存中不必每次在读取
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == self.cache_version # same version
assert cache['hash'] == get_hash(self.label_files + self.img_files) # same hash
except:
cache, exists = self.cache_labels(cache_path, prefix), False # cache
# Display cache
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupted, total
if exists:
d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupted"
tqdm(None, desc=prefix + d, total=n, initial=n) # display cache results
if cache['msgs']:
logging.info('\n'.join(cache['msgs'])) # display warnings
assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {HELP_URL}'
# Read cache
[cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
labels, shapes, self.segments = zip(*cache.values())#解压cacha
self.labels = list(labels)
self.shapes = np.array(shapes, dtype=np.float64)
#根据索引排序数据集与标签路径,shape,h/w
self.img_files = list(cache.keys()) # update
self.label_files = img2label_paths(cache.keys()) # update
n = len(shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
self.n = n
self.indices = range(n)
# Update labels
include_class = [] # filter labels to include only these classes (optional)
include_class_array = np.array(include_class).reshape(1, -1)
for i, (label, segment) in enumerate(zip(self.labels, self.segments)):
if include_class:
j = (label[:, 0:1] == include_class_array).any(1)
self.labels[i] = label[j]
if segment:
self.segments[i] = segment[j]
if single_cls: # single-class training, merge all classes into 0
self.labels[i][:, 0] = 0
if segment:
self.segments[i][:, 0] = 0
# Rectangular Training
if self.rect:
# Sort by aspect ratio
s = self.shapes # wh
ar = s[:, 1] / s[:, 0] # aspect ratio
irect = ar.argsort()
self.img_files = [self.img_files[i] for i in irect]
self.label_files = [self.label_files[i] for i in irect]
self.labels = [self.labels[i] for i in irect]
self.shapes = s[irect] # wh
ar = ar[irect]
# Set training image shapes
shapes = [[1, 1]] * nb
for i in range(nb):
ari = ar[bi == i]
mini, maxi = ari.min(), ari.max()
if maxi < 1:
shapes[i] = [maxi, 1]
elif mini > 1:
shapes[i] = [1, 1 / mini]
self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride
# Cache images into memory for faster training (WARNING: large datasets may exceed system RAM)
self.imgs, self.img_npy = [None] * n, [None] * n
if cache_images:
if cache_images == 'disk':
self.im_cache_dir = Path(Path(self.img_files[0]).parent.as_posix() + '_npy')
self.img_npy = [self.im_cache_dir / Path(f).with_suffix('.npy').name for f in self.img_files]
self.im_cache_dir.mkdir(parents=True, exist_ok=True)
gb = 0 # Gigabytes of cached images
self.img_hw0, self.img_hw = [None] * n, [None] * n
results = ThreadPool(NUM_THREADS).imap(lambda x: load_image(*x), zip(repeat(self), range(n)))
pbar = tqdm(enumerate(results), total=n)
for i, x in pbar:
if cache_images == 'disk':
if not self.img_npy[i].exists():
np.save(self.img_npy[i].as_posix(), x[0])
gb += self.img_npy[i].stat().st_size
else:
self.imgs[i], self.img_hw0[i], self.img_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
gb += self.imgs[i].nbytes
pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB {cache_images})'
pbar.close()
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
# Cache dataset labels, check images and read shapes
x = {} # dict
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels..."
with Pool(NUM_THREADS) as pool:
pbar = tqdm(pool.imap(verify_image_label, zip(self.img_files, self.label_files, repeat(prefix))),
desc=desc, total=len(self.img_files))
for im_file, l, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f
nf += nf_f
ne += ne_f
nc += nc_f
if im_file:
x[im_file] = [l, shape, segments]
if msg:
msgs.append(msg)
pbar.desc = f"{desc}{nf} found, {nm} missing, {ne} empty, {nc} corrupted"
pbar.close()
if msgs:
logging.info('\n'.join(msgs))
if nf == 0:
logging.info(f'{prefix}WARNING: No labels found in {path}. See {HELP_URL}')
x['hash'] = get_hash(self.label_files + self.img_files)
x['results'] = nf, nm, ne, nc, len(self.img_files)
x['msgs'] = msgs # warnings
x['version'] = self.cache_version # cache version
try:
np.save(path, x) # save cache for next time
path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
logging.info(f'{prefix}New cache created: {path}')
except Exception as e:
logging.info(f'{prefix}WARNING: Cache directory {path.parent} is not writeable: {e}') # path not writeable
return x
def __len__(self):
return len(self.img_files)
# def __iter__(self):
# self.count = -1
# print('ran dataset iter')
# #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
# return self
def __getitem__(self, index):
index = self.indices[index] # linear, shuffled, or image_weights
hyp = self.hyp#超参数
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index)
shapes = None
# MixUp augmentation,数据增强
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))
else:
# Load image
img, (h0, w0), (h, w) = load_image(self, index)
# Letterbox
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
labels = self.labels[index].copy()
#调整标签坐标不在是归一化的值
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
if self.augment:#随机透视变换
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
nl = len(labels) # number of labels
if nl:#调整标签框坐标归一化0-1
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
if self.augment:#图片随机旋转,上下
# Albumentations
img, labels = self.albumentations(img, labels)
nl = len(labels) # update after albumentations
# HSV color-space,随机改变图片的色调(H),饱和度(s),亮度(V)
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nl:
labels[:, 1] = 1 - labels[:, 1]
# Cutouts
# labels = cutout(img, labels, p=0.5)
#初始化标签框对应的图片序号,方便collate-fn的使用
labels_out = torch.zeros((nl, 6))
if nl:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return torch.from_numpy(img), labels_out, self.img_files[index], shapes
@staticmethod
#整理函数,如何取样,可以定义自己的函数来实现功能
def collate_fn(batch):
img, label, path, shapes = zip(*batch) # transposed
for i, l in enumerate(label):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img, 0), torch.cat(label, 0), path, shapes
@staticmethod
def collate_fn4(batch):
img, label, path, shapes = zip(*batch) # transposed
n = len(shapes) // 4
img4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
ho = torch.tensor([[0., 0, 0, 1, 0, 0]])
wo = torch.tensor([[0., 0, 1, 0, 0, 0]])
s = torch.tensor([[1, 1, .5, .5, .5, .5]]) # scale
for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
i *= 4
if random.random() < 0.5:
im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2., mode='bilinear', align_corners=False)[
0].type(img[i].type())
l = label[i]
else:
im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
l = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
img4.append(im)
label4.append(l)
for i, l in enumerate(label4):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img4, 0), torch.cat(label4, 0), path4, shapes4
# Ancillary functions --------------------------------------------------------------------------------------------------
#加载图片并根据设定的输入大小与原图片大小比例ratio进行resize
def load_image(self, i):
# loads 1 image from dataset index 'i', returns im, original hw, resized hw
im = self.imgs[i]
if im is None: # not cached in ram
npy = self.img_npy[i]
if npy and npy.exists(): # load npy
im = np.load(npy)
else: # read image
path = self.img_files[i]
im = cv2.imread(path) # BGR
assert im is not None, 'Image Not Found ' + path
h0, w0 = im.shape[:2] # orig hw
r = self.img_size / max(h0, w0) # ratio
#根据ratio进行不同的插值
if r != 1: # if sizes are not equal
im = cv2.resize(im, (int(w0 * r), int(h0 * r)),
interpolation=cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEAR)
return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
else:
return self.imgs[i], self.img_hw0[i], self.img_hw[i] # im, hw_original, hw_resized
#引入三张随机照片,生成一个图像增强图片
def load_mosaic(self, index):
# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
labels4, segments4 = [], []
s = self.img_size
#随机取mosaic中心点
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y
#随机取三张图片的索引
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
#加载图片并根据设定的输入大小与图片原大小的比例ratio进行resize
img, _, (h, w) = load_image(self, index)
# place img in img4
if i == 0: # top left
#初始化大图
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
#设置大图上的位置(左上角)
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
#选取小图上位置
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
#将小图上截取的部分贴到大图上
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
#计算小图到大图上时所产生的偏移,用来计算mosaic增强后的标签框位置
padw = x1a - x1b
padh = y1a - y1b
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
#重新调整标签框坐标信息
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels)
segments4.extend(segments)
# Concat/clip labels
#调整坐标框在图片内部
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img4, labels4 = replicate(img4, labels4) # replicate
# Augment
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
#进行mosaic的时候将四张图片整合到一起之后shape为[2*img_size,2*img_size]
#随机旋转平移缩放剪切,并resize为输入大小img_size
img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img4, labels4
#随机加入8张照片,构造9张照片
def load_mosaic9(self, index):
# YOLOv5 9-mosaic loader. Loads 1 image + 8 random images into a 9-image mosaic
labels9, segments9 = [], []
s = self.img_size
#随机取三张图片的索引
indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
#加载图片并根据设定的输入大小与图片原大小的比例ratio进行resize
img, _, (h, w) = load_image(self, index)
# place img in img9
if i == 0: # center
#初始化大图
img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
h0, w0 = h, w
c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
elif i == 1: # top
c = s, s - h, s + w, s
elif i == 2: # top right
c = s + wp, s - h, s + wp + w, s
elif i == 3: # right
c = s + w0, s, s + w0 + w, s + h
elif i == 4: # bottom right
c = s + w0, s + hp, s + w0 + w, s + hp + h
elif i == 5: # bottom
c = s + w0 - w, s + h0, s + w0, s + h0 + h
elif i == 6: # bottom left
c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
elif i == 7: # left
c = s - w, s + h0 - h, s, s + h0
elif i == 8: # top left
c = s - w, s + h0 - hp - h, s, s + h0 - hp
padx, pady = c[:2]
x1, y1, x2, y2 = [max(x, 0) for x in c] # allocate coords
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
labels9.append(labels)
segments9.extend(segments)
# Image
img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
hp, wp = h, w # height, width previous
# Offset
#随机取mosaic中心
yc, xc = [int(random.uniform(0, s)) for _ in self.mosaic_border] # mosaic center x, y
img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
# Concat/clip labels
labels9 = np.concatenate(labels9, 0)
labels9[:, [1, 3]] -= xc
labels9[:, [2, 4]] -= yc
c = np.array([xc, yc]) # centers
segments9 = [x - c for x in segments9]
for x in (labels9[:, 1:], *segments9):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img9, labels9 = replicate(img9, labels9) # replicate
# Augment
img9, labels9 = random_perspective(img9, labels9, segments9,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img9, labels9
def create_folder(path='./new'):
# Create folder
if os.path.exists(path):
shutil.rmtree(path) # delete output folder
os.makedirs(path) # make new output folder
def flatten_recursive(path='../datasets/coco128'):
# Flatten a recursive directory by bringing all files to top level
new_path = Path(path + '_flat')
create_folder(new_path)
for file in tqdm(glob.glob(str(Path(path)) + '/**/*.*', recursive=True)):
shutil.copyfile(file, new_path / Path(file).name)
def extract_boxes(path='../datasets/coco128'): # from utils.datasets import *; extract_boxes()
# Convert detection dataset into classification dataset, with one directory per class
path = Path(path) # images dir
shutil.rmtree(path / 'classifier') if (path / 'classifier').is_dir() else None # remove existing
files = list(path.rglob('*.*'))
n = len(files) # number of files
for im_file in tqdm(files, total=n):
if im_file.suffix[1:] in IMG_FORMATS:
# image
im = cv2.imread(str(im_file))[..., ::-1] # BGR to RGB
h, w = im.shape[:2]
# labels
lb_file = Path(img2label_paths([str(im_file)])[0])
if Path(lb_file).exists():
with open(lb_file, 'r') as f:
lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # labels
for j, x in enumerate(lb):
c = int(x[0]) # class
f = (path / 'classifier') / f'{c}' / f'{path.stem}_{im_file.stem}_{j}.jpg' # new filename
if not f.parent.is_dir():
f.parent.mkdir(parents=True)
b = x[1:] * [w, h, w, h] # box
# b[2:] = b[2:].max() # rectangle to square
b[2:] = b[2:] * 1.2 + 3 # pad
b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int)
b[[0, 2]] = np.clip(b[[0, 2]], 0, w) # clip boxes outside of image
b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
assert cv2.imwrite(str(f), im[b[1]:b[3], b[0]:b[2]]), f'box failure in {f}'
def autosplit(path='../datasets/coco128/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
""" Autosplit a dataset into train/val/test splits and save path/autosplit_*.txt files
Usage: from utils.datasets import *; autosplit()
Arguments
path: Path to images directory
weights: Train, val, test weights (list, tuple)
annotated_only: Only use images with an annotated txt file
"""
path = Path(path) # images dir
files = sum([list(path.rglob(f"*.{img_ext}")) for img_ext in IMG_FORMATS], []) # image files only
n = len(files) # number of files
random.seed(0) # for reproducibility
indices = random.choices([0, 1, 2], weights=weights, k=n) # assign each image to a split
txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
[(path.parent / x).unlink(missing_ok=True) for x in txt] # remove existing
print(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
for i, img in tqdm(zip(indices, files), total=n):
if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
with open(path.parent / txt[i], 'a') as f:
f.write('./' + img.relative_to(path.parent).as_posix() + '\n') # add image to txt file
def verify_image_label(args):
# Verify one image-label pair
im_file, lb_file, prefix = args
nm, nf, ne, nc, msg, segments = 0, 0, 0, 0, '', [] # number (missing, found, empty, corrupt), message, segments
try:
# verify images
im = Image.open(im_file)
im.verify() # PIL verify
shape = exif_size(im) # image size
assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
assert im.format.lower() in IMG_FORMATS, f'invalid image format {im.format}'
if im.format.lower() in ('jpg', 'jpeg'):
with open(im_file, 'rb') as f:
f.seek(-2, 2)
if f.read() != b'\xff\xd9': # corrupt JPEG
Image.open(im_file).save(im_file, format='JPEG', subsampling=0, quality=100) # re-save image
msg = f'{prefix}WARNING: {im_file}: corrupt JPEG restored and saved'
# verify labels
if os.path.isfile(lb_file):
nf = 1 # label found
with open(lb_file, 'r') as f:
l = [x.split() for x in f.read().strip().splitlines() if len(x)]
if any([len(x) > 8 for x in l]): # is segment
classes = np.array([x[0] for x in l], dtype=np.float32)
segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in l] # (cls, xy1...)
l = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
l = np.array(l, dtype=np.float32)
nl = len(l)
if nl:
assert l.shape[1] == 5, f'labels require 5 columns, {l.shape[1]} columns detected'
assert (l >= 0).all(), f'negative label values {l[l < 0]}'
assert (l[:, 1:] <= 1).all(), f'non-normalized or out of bounds coordinates {l[:, 1:][l[:, 1:] > 1]}'
l = np.unique(l, axis=0) # remove duplicate rows
if len(l) < nl:
segments = np.unique(segments, axis=0)
msg = f'{prefix}WARNING: {im_file}: {nl - len(l)} duplicate labels removed'
else:
ne = 1 # label empty
l = np.zeros((0, 5), dtype=np.float32)
else:
nm = 1 # label missing
l = np.zeros((0, 5), dtype=np.float32)
return im_file, l, shape, segments, nm, nf, ne, nc, msg
except Exception as e:
nc = 1
msg = f'{prefix}WARNING: {im_file}: ignoring corrupt image/label: {e}'
return [None, None, None, None, nm, nf, ne, nc, msg]
def dataset_stats(path='coco128.yaml', autodownload=False, verbose=False, profile=False, hub=False):
""" Return dataset statistics dictionary with images and instances counts per split per class
To run in parent directory: export PYTHONPATH="$PWD/yolov5"
Usage1: from utils.datasets import *; dataset_stats('coco128.yaml', autodownload=True)
Usage2: from utils.datasets import *; dataset_stats('../datasets/coco128_with_yaml.zip')
Arguments
path: Path to data.yaml or data.zip (with data.yaml inside data.zip)
autodownload: Attempt to download dataset if not found locally
verbose: Print stats dictionary
"""
def round_labels(labels):
# Update labels to integer class and 6 decimal place floats
return [[int(c), *[round(x, 4) for x in points]] for c, *points in labels]
def unzip(path):
# Unzip data.zip TODO: CONSTRAINT: path/to/abc.zip MUST unzip to 'path/to/abc/'
if str(path).endswith('.zip'): # path is data.zip
assert Path(path).is_file(), f'Error unzipping {path}, file not found'
ZipFile(path).extractall(path=path.parent) # unzip
dir = path.with_suffix('') # dataset directory == zip name
return True, str(dir), next(dir.rglob('*.yaml')) # zipped, data_dir, yaml_path
else: # path is data.yaml
return False, None, path
def hub_ops(f, max_dim=1920):
# HUB ops for 1 image 'f': resize and save at reduced quality in /dataset-hub for web/app viewing
f_new = im_dir / Path(f).name # dataset-hub image filename
try: # use PIL
im = Image.open(f)
r = max_dim / max(im.height, im.width) # ratio
if r < 1.0: # image too large
im = im.resize((int(im.width * r), int(im.height * r)))
im.save(f_new, quality=75) # save
except Exception as e: # use OpenCV
print(f'WARNING: HUB ops PIL failure {f}: {e}')
im = cv2.imread(f)
im_height, im_width = im.shape[:2]
r = max_dim / max(im_height, im_width) # ratio
if r < 1.0: # image too large
im = cv2.resize(im, (int(im_width * r), int(im_height * r)), interpolation=cv2.INTER_LINEAR)
cv2.imwrite(str(f_new), im)
zipped, data_dir, yaml_path = unzip(Path(path))
with open(check_yaml(yaml_path), errors='ignore') as f:
data = yaml.safe_load(f) # data dict
if zipped:
data['path'] = data_dir # TODO: should this be dir.resolve()?
check_dataset(data, autodownload) # download dataset if missing
hub_dir = Path(data['path'] + ('-hub' if hub else ''))
stats = {'nc': data['nc'], 'names': data['names']} # statistics dictionary
for split in 'train', 'val', 'test':
if data.get(split) is None:
stats[split] = None # i.e. no test set
continue
x = []
dataset = LoadImagesAndLabels(data[split]) # load dataset
for label in tqdm(dataset.labels, total=dataset.n, desc='Statistics'):
x.append(np.bincount(label[:, 0].astype(int), minlength=data['nc']))
x = np.array(x) # shape(128x80)
stats[split] = {'instance_stats': {'total': int(x.sum()), 'per_class': x.sum(0).tolist()},
'image_stats': {'total': dataset.n, 'unlabelled': int(np.all(x == 0, 1).sum()),
'per_class': (x > 0).sum(0).tolist()},
'labels': [{str(Path(k).name): round_labels(v.tolist())} for k, v in
zip(dataset.img_files, dataset.labels)]}
if hub:
im_dir = hub_dir / 'images'
im_dir.mkdir(parents=True, exist_ok=True)
for _ in tqdm(ThreadPool(NUM_THREADS).imap(hub_ops, dataset.img_files), total=dataset.n, desc='HUB Ops'):
pass
# Profile
stats_path = hub_dir / 'stats.json'
if profile:
for _ in range(1):
file = stats_path.with_suffix('.npy')
t1 = time.time()
np.save(file, stats)
t2 = time.time()
x = np.load(file, allow_pickle=True)
print(f'stats.npy times: {time.time() - t2:.3f}s read, {t2 - t1:.3f}s write')
file = stats_path.with_suffix('.json')
t1 = time.time()
with open(file, 'w') as f:
json.dump(stats, f) # save stats *.json
t2 = time.time()
with open(file, 'r') as f:
x = json.load(f) # load hyps dict
print(f'stats.json times: {time.time() - t2:.3f}s read, {t2 - t1:.3f}s write')
# Save, print and return
if hub:
print(f'Saving {stats_path.resolve()}...')
with open(stats_path, 'w') as f:
json.dump(stats, f) # save stats.json
if verbose:
print(json.dumps(stats, indent=2, sort_keys=False))
return stats
donwload.py 下载需要的权重文件等函数
general.py 项目通用代码
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
General utils
"""
import contextlib
import glob
import logging
import math
import os
import platform
import random
import re
import signal
import time
import urllib
from itertools import repeat
from multiprocessing.pool import ThreadPool
from pathlib import Path
from subprocess import check_output
from zipfile import ZipFile
import cv2
import numpy as np
import pandas as pd
import pkg_resources as pkg
import torch
import torchvision
import yaml
from utils.downloads import gsutil_getsize
from utils.metrics import box_iou, fitness
# Settings
torch.set_printoptions(linewidth=320, precision=5, profile='long')
np.set_printoptions(linewidth=320, formatter={'float_kind': '{:11.5g}'.format}) # format short g, %precision=5
pd.options.display.max_columns = 10
#禁止OpenCV的多线程,使用torch的所线程
cv2.setNumThreads(0) # prevent OpenCV from multithreading (incompatible with PyTorch DataLoader)
os.environ['NUMEXPR_MAX_THREADS'] = str(min(os.cpu_count(), 8)) # NumExpr max threads
FILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
class Profile(contextlib.ContextDecorator):
# Usage: @Profile() decorator or 'with Profile():' context manager
def __enter__(self):
self.start = time.time()
def __exit__(self, type, value, traceback):
print(f'Profile results: {time.time() - self.start:.5f}s')
class Timeout(contextlib.ContextDecorator):
# Usage: @Timeout(seconds) decorator or 'with Timeout(seconds):' context manager
def __init__(self, seconds, *, timeout_msg='', suppress_timeout_errors=True):
self.seconds = int(seconds)
self.timeout_message = timeout_msg
self.suppress = bool(suppress_timeout_errors)
def _timeout_handler(self, signum, frame):
raise TimeoutError(self.timeout_message)
def __enter__(self):
signal.signal(signal.SIGALRM, self._timeout_handler) # Set handler for SIGALRM
signal.alarm(self.seconds) # start countdown for SIGALRM to be raised
def __exit__(self, exc_type, exc_val, exc_tb):
signal.alarm(0) # Cancel SIGALRM if it's scheduled
if self.suppress and exc_type is TimeoutError: # Suppress TimeoutError
return True
def try_except(func):
# try-except function. Usage: @try_except decorator
def handler(*args, **kwargs):
try:
func(*args, **kwargs)
except Exception as e:
print(e)
return handler
def methods(instance):
# Get class/instance methods
return [f for f in dir(instance) if callable(getattr(instance, f)) and not f.startswith("__")]
#设置日志的保存级别
def set_logging(rank=-1, verbose=True):
logging.basicConfig(
format="%(message)s",
level=logging.INFO if (verbose and rank in [-1, 0]) else logging.WARN)
def print_args(name, opt):
# Print argparser arguments
print(colorstr(f'{name}: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items()))
#初始化随机数种子
def init_seeds(seed=0):
# Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
# cudnn seed 0 settings are slower and more reproducible, else faster and less reproducible
import torch.backends.cudnn as cudnn
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
cudnn.benchmark, cudnn.deterministic = (False, True) if seed == 0 else (True, False)
# 获取最近训练的权重文件,last.pt
def get_latest_run(search_dir='.'):
# Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
return max(last_list, key=os.path.getctime) if last_list else ''
def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
# Return path of user configuration directory. Prefer environment variable if exists. Make dir if required.
env = os.getenv(env_var)
if env:
path = Path(env) # use environment variable
else:
cfg = {'Windows': 'AppData/Roaming', 'Linux': '.config', 'Darwin': 'Library/Application Support'} # 3 OS dirs
path = Path.home() / cfg.get(platform.system(), '') # OS-specific config dir
path = (path if is_writeable(path) else Path('/tmp')) / dir # GCP and AWS lambda fix, only /tmp is writeable
path.mkdir(exist_ok=True) # make if required
return path
def is_writeable(dir, test=False):
# Return True if directory has write permissions, test opening a file with write permissions if test=True
if test: # method 1
file = Path(dir) / 'tmp.txt'
try:
with open(file, 'w'): # open file with write permissions
pass
file.unlink() # remove file
return True
except IOError:
return False
else: # method 2
return os.access(dir, os.R_OK) # possible issues on Windows
def is_docker():
# Is environment a Docker container?
return Path('/workspace').exists() # or Path('/.dockerenv').exists()
def is_colab():
# Is environment a Google Colab instance?
try:
import google.colab
return True
except ImportError:
return False
def is_pip():
# Is file in a pip package?
return 'site-packages' in Path(__file__).resolve().parts
def is_ascii(s=''):
# Is string composed of all ASCII (no UTF) characters? (note str().isascii() introduced in python 3.7)
s = str(s) # convert list, tuple, None, etc. to str
return len(s.encode().decode('ascii', 'ignore')) == len(s)
def is_chinese(s='人工智能'):
# Is string composed of any Chinese characters?
return re.search('[\u4e00-\u9fff]', s)
def emojis(str=''):
# Return platform-dependent emoji-safe version of string
return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
def file_size(path):
# Return file/dir size (MB)
path = Path(path)
if path.is_file():
return path.stat().st_size / 1E6
elif path.is_dir():
return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / 1E6
else:
return 0.0
def check_online():
# Check internet connectivity
import socket
try:
socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
return True
except OSError:
return False
@try_except
#检查当前的分支和Git上的版本是否一致,否则提醒用户
def check_git_status():
# Recommend 'git pull' if code is out of date
msg = ', for updates see https://github.com/ultralytics/yolov5'
print(colorstr('github: '), end='')
assert Path('.git').exists(), 'skipping check (not a git repository)' + msg
assert not is_docker(), 'skipping check (Docker image)' + msg
assert check_online(), 'skipping check (offline)' + msg
cmd = 'git fetch && git config --get remote.origin.url'
url = check_output(cmd, shell=True, timeout=5).decode().strip().rstrip('.git') # git fetch
branch = check_output('git rev-parse --abbrev-ref HEAD', shell=True).decode().strip() # checked out
n = int(check_output(f'git rev-list {branch}..origin/master --count', shell=True)) # commits behind
if n > 0:
s = f"⚠️ YOLOv5 is out of date by {n} commit{'s' * (n > 1)}. Use `git pull` or `git clone {url}` to update."
else:
s = f'up to date with {url} ✅'
print(emojis(s)) # emoji-safe
def check_python(minimum='3.6.2'):
# Check current python version vs. required python version
check_version(platform.python_version(), minimum, name='Python ')
def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False):
# Check version vs. required version
current, minimum = (pkg.parse_version(x) for x in (current, minimum))
result = (current == minimum) if pinned else (current >= minimum)
assert result, f'{name}{minimum} required by YOLOv5, but {name}{current} is currently installed'
@try_except
def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), install=True):
# Check installed dependencies meet requirements (pass *.txt file or list of packages)
prefix = colorstr('red', 'bold', 'requirements:')
check_python() # check python version
if isinstance(requirements, (str, Path)): # requirements.txt file
file = Path(requirements)
assert file.exists(), f"{prefix} {file.resolve()} not found, check failed."
requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(file.open()) if x.name not in exclude]
else: # list or tuple of packages
requirements = [x for x in requirements if x not in exclude]
n = 0 # number of packages updates
for r in requirements:
try:
pkg.require(r)
except Exception as e: # DistributionNotFound or VersionConflict if requirements not met
s = f"{prefix} {r} not found and is required by YOLOv5"
if install:
print(f"{s}, attempting auto-update...")
try:
assert check_online(), f"'pip install {r}' skipped (offline)"
print(check_output(f"pip install '{r}'", shell=True).decode())
n += 1
except Exception as e:
print(f'{prefix} {e}')
else:
print(f'{s}. Please install and rerun your command.')
if n: # if packages updated
source = file.resolve() if 'file' in locals() else requirements
s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
print(emojis(s))
#检查图像的尺寸是否是32的整数倍。否则调整
def check_img_size(imgsz, s=32, floor=0):
# Verify image size is a multiple of stride s in each dimension
if isinstance(imgsz, int): # integer i.e. img_size=640
new_size = max(make_divisible(imgsz, int(s)), floor)
else: # list i.e. img_size=[640, 480]
new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
if new_size != imgsz:
print(f'WARNING: --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
return new_size
def check_imshow():
# Check if environment supports image displays
try:
assert not is_docker(), 'cv2.imshow() is disabled in Docker environments'
assert not is_colab(), 'cv2.imshow() is disabled in Google Colab environments'
cv2.imshow('test', np.zeros((1, 1, 3)))
cv2.waitKey(1)
cv2.destroyAllWindows()
cv2.waitKey(1)
return True
except Exception as e:
print(f'WARNING: Environment does not support cv2.imshow() or PIL Image.show() image displays\n{e}')
return False
def check_suffix(file='yolov5s.pt', suffix=('.pt',), msg=''):
# Check file(s) for acceptable suffix
if file and suffix:
if isinstance(suffix, str):
suffix = [suffix]
for f in file if isinstance(file, (list, tuple)) else [file]:
s = Path(f).suffix.lower() # file suffix
if len(s):
assert s in suffix, f"{msg}{f} acceptable suffix is {suffix}"
def check_yaml(file, suffix=('.yaml', '.yml')):
# Search/download YAML file (if necessary) and return path, checking suffix
return check_file(file, suffix)
def check_file(file, suffix=''):
# Search/download file (if necessary) and return path
check_suffix(file, suffix) # optional
file = str(file) # convert to str()
if Path(file).is_file() or file == '': # exists
return file
elif file.startswith(('http:/', 'https:/')): # download
url = str(Path(file)).replace(':/', '://') # Pathlib turns :// -> :/
file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
print(f'Downloading {url} to {file}...')
torch.hub.download_url_to_file(url, file)
assert Path(file).exists() and Path(file).stat().st_size > 0, f'File download failed: {url}' # check
return file
else: # search
files = []
for d in 'data', 'models', 'utils': # search directories
files.extend(glob.glob(str(ROOT / d / '**' / file), recursive=True)) # find file
assert len(files), f'File not found: {file}' # assert file was found
assert len(files) == 1, f"Multiple files match '{file}', specify exact path: {files}" # assert unique
return files[0] # return file
def check_dataset(data, autodownload=True):
# Download and/or unzip dataset if not found locally
# Usage: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128_with_yaml.zip
# Download (optional)
extract_dir = ''
if isinstance(data, (str, Path)) and str(data).endswith('.zip'): # i.e. gs://bucket/dir/coco128.zip
download(data, dir='../datasets', unzip=True, delete=False, curl=False, threads=1)
data = next((Path('../datasets') / Path(data).stem).rglob('*.yaml'))
extract_dir, autodownload = data.parent, False
# Read yaml (optional)
if isinstance(data, (str, Path)):
with open(data, errors='ignore') as f:
data = yaml.safe_load(f) # dictionary
# Parse yaml
path = extract_dir or Path(data.get('path') or '') # optional 'path' default to '.'
for k in 'train', 'val', 'test':
if data.get(k): # prepend path
data[k] = str(path / data[k]) if isinstance(data[k], str) else [str(path / x) for x in data[k]]
assert 'nc' in data, "Dataset 'nc' key missing."
if 'names' not in data:
data['names'] = [f'class{i}' for i in range(data['nc'])] # assign class names if missing
train, val, test, s = [data.get(x) for x in ('train', 'val', 'test', 'download')]
if val:
val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
if not all(x.exists() for x in val):
print('\nWARNING: Dataset not found, nonexistent paths: %s' % [str(x) for x in val if not x.exists()])
if s and autodownload: # download script
root = path.parent if 'path' in data else '..' # unzip directory i.e. '../'
if s.startswith('http') and s.endswith('.zip'): # URL
f = Path(s).name # filename
print(f'Downloading {s} to {f}...')
torch.hub.download_url_to_file(s, f)
Path(root).mkdir(parents=True, exist_ok=True) # create root
ZipFile(f).extractall(path=root) # unzip
Path(f).unlink() # remove zip
r = None # success
elif s.startswith('bash '): # bash script
print(f'Running {s} ...')
r = os.system(s)
else: # python script
r = exec(s, {'yaml': data}) # return None
print(f"Dataset autodownload {f'success, saved to {root}' if r in (0, None) else 'failure'}\n")
else:
raise Exception('Dataset not found.')
return data # dictionary
def url2file(url):
# Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
file = Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
return file
def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1):
# Multi-threaded file download and unzip function, used in data.yaml for autodownload
def download_one(url, dir):
# Download 1 file
f = dir / Path(url).name # filename
if Path(url).is_file(): # exists in current path
Path(url).rename(f) # move to dir
elif not f.exists():
print(f'Downloading {url} to {f}...')
if curl:
os.system(f"curl -L '{url}' -o '{f}' --retry 9 -C -") # curl download, retry and resume on fail
else:
torch.hub.download_url_to_file(url, f, progress=True) # torch download
if unzip and f.suffix in ('.zip', '.gz'):
print(f'Unzipping {f}...')
if f.suffix == '.zip':
ZipFile(f).extractall(path=dir) # unzip
elif f.suffix == '.gz':
os.system(f'tar xfz {f} --directory {f.parent}') # unzip
if delete:
f.unlink() # remove zip
dir = Path(dir)
dir.mkdir(parents=True, exist_ok=True) # make directory
if threads > 1:
pool = ThreadPool(threads)
pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multi-threaded
pool.close()
pool.join()
else:
for u in [url] if isinstance(url, (str, Path)) else url:
download_one(u, dir)
def make_divisible(x, divisor):
# Returns x evenly divisible by divisor
return math.ceil(x / divisor) * divisor
def clean_str(s):
# Cleans a string by replacing special characters with underscore _
return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
def one_cycle(y1=0.0, y2=1.0, steps=100):
# lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
def colorstr(*input):
# Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
*args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
colors = {'black': '\033[30m', # basic colors
'red': '\033[31m',
'green': '\033[32m',
'yellow': '\033[33m',
'blue': '\033[34m',
'magenta': '\033[35m',
'cyan': '\033[36m',
'white': '\033[37m',
'bright_black': '\033[90m', # bright colors
'bright_red': '\033[91m',
'bright_green': '\033[92m',
'bright_yellow': '\033[93m',
'bright_blue': '\033[94m',
'bright_magenta': '\033[95m',
'bright_cyan': '\033[96m',
'bright_white': '\033[97m',
'end': '\033[0m', # misc
'bold': '\033[1m',
'underline': '\033[4m'}
return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
def labels_to_class_weights(labels, nc=80):
# Get class weights (inverse frequency) from training labels
if labels[0] is None: # no labels loaded
return torch.Tensor()
labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
classes = labels[:, 0].astype(np.int) # labels = [class xywh]
weights = np.bincount(classes, minlength=nc) # occurrences per class
# Prepend gridpoint count (for uCE training)
# gpi = ((320 / 32 * np.array([1, 2, 4])) ** 2 * 3).sum() # gridpoints per image
# weights = np.hstack([gpi * len(labels) - weights.sum() * 9, weights * 9]) ** 0.5 # prepend gridpoints to start
weights[weights == 0] = 1 # replace empty bins with 1
weights = 1 / weights # number of targets per class
weights /= weights.sum() # normalize
return torch.from_numpy(weights)
def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
# Produces image weights based on class_weights and image contents
class_counts = np.array([np.bincount(x[:, 0].astype(np.int), minlength=nc) for x in labels])
image_weights = (class_weights.reshape(1, nc) * class_counts).sum(1)
# index = random.choices(range(n), weights=image_weights, k=1) # weight image sample
return image_weights
def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
# https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
# a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
# b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
# x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
# x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
return x
def xyxy2xywh(x):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
y[:, 2] = x[:, 2] - x[:, 0] # width
y[:, 3] = x[:, 3] - x[:, 1] # height
return y
def xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
# Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
return y
def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
if clip:
clip_coords(x, (h - eps, w - eps)) # warning: inplace clip
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
return y
def xyn2xy(x, w=640, h=640, padw=0, padh=0):
# Convert normalized segments into pixel segments, shape (n,2)
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = w * x[:, 0] + padw # top left x
y[:, 1] = h * x[:, 1] + padh # top left y
return y
def segment2box(segment, width=640, height=640):
# Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
x, y = segment.T # segment xy
inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
x, y, = x[inside], y[inside]
return np.array([x.min(), y.min(), x.max(), y.max()]) if any(x) else np.zeros((1, 4)) # xyxy
def segments2boxes(segments):
# Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
boxes = []
for s in segments:
x, y = s.T # segment xy
boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
return xyxy2xywh(np.array(boxes)) # cls, xywh
def resample_segments(segments, n=1000):
# Up-sample an (n,2) segment
for i, s in enumerate(segments):
x = np.linspace(0, len(s) - 1, n)
xp = np.arange(len(s))
segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)]).reshape(2, -1).T # segment xy
return segments
def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
coords[:, [0, 2]] -= pad[0] # x padding
coords[:, [1, 3]] -= pad[1] # y padding
coords[:, :4] /= gain
clip_coords(coords, img0_shape)
return coords
def clip_coords(boxes, shape):
# Clip bounding xyxy bounding boxes to image shape (height, width)
if isinstance(boxes, torch.Tensor): # faster individually
boxes[:, 0].clamp_(0, shape[1]) # x1
boxes[:, 1].clamp_(0, shape[0]) # y1
boxes[:, 2].clamp_(0, shape[1]) # x2
boxes[:, 3].clamp_(0, shape[0]) # y2
else: # np.array (faster grouped)
boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
#非极大值抑制
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False,
labels=(), max_det=300):
"""Runs Non-Maximum Suppression (NMS) on inference results
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
nc = prediction.shape[2] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Checks
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {time_limit}s exceeded')
break # time limit exceeded
return output
def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_optimizer()
# Strip optimizer from 'f' to finalize training, optionally save as 's'
x = torch.load(f, map_location=torch.device('cpu'))
if x.get('ema'):
x['model'] = x['ema'] # replace model with ema
for k in 'optimizer', 'training_results', 'wandb_id', 'ema', 'updates': # keys
x[k] = None
x['epoch'] = -1
x['model'].half() # to FP16
for p in x['model'].parameters():
p.requires_grad = False
torch.save(x, s or f)
mb = os.path.getsize(s or f) / 1E6 # filesize
print(f"Optimizer stripped from {f},{(' saved as %s,' % s) if s else ''} {mb:.1f}MB")
def print_mutation(results, hyp, save_dir, bucket):
evolve_csv, results_csv, evolve_yaml = save_dir / 'evolve.csv', save_dir / 'results.csv', save_dir / 'hyp_evolve.yaml'
keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
'val/box_loss', 'val/obj_loss', 'val/cls_loss') + tuple(hyp.keys()) # [results + hyps]
keys = tuple(x.strip() for x in keys)
vals = results + tuple(hyp.values())
n = len(keys)
# Download (optional)
if bucket:
url = f'gs://{bucket}/evolve.csv'
if gsutil_getsize(url) > (os.path.getsize(evolve_csv) if os.path.exists(evolve_csv) else 0):
os.system(f'gsutil cp {url} {save_dir}') # download evolve.csv if larger than local
# Log to evolve.csv
s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n') # add header
with open(evolve_csv, 'a') as f:
f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
# Print to screen
print(colorstr('evolve: ') + ', '.join(f'{x.strip():>20s}' for x in keys))
print(colorstr('evolve: ') + ', '.join(f'{x:20.5g}' for x in vals), end='\n\n\n')
# Save yaml
with open(evolve_yaml, 'w') as f:
data = pd.read_csv(evolve_csv)
data = data.rename(columns=lambda x: x.strip()) # strip keys
i = np.argmax(fitness(data.values[:, :7])) #
f.write('# YOLOv5 Hyperparameter Evolution Results\n' +
f'# Best generation: {i}\n' +
f'# Last generation: {len(data)}\n' +
'# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) + '\n' +
'# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
yaml.safe_dump(hyp, f, sort_keys=False)
if bucket:
os.system(f'gsutil cp {evolve_csv} {evolve_yaml} gs://{bucket}') # upload
def apply_classifier(x, model, img, im0):
# Apply a second stage classifier to yolo outputs
im0 = [im0] if isinstance(im0, np.ndarray) else im0
for i, d in enumerate(x): # per image
if d is not None and len(d):
d = d.clone()
# Reshape and pad cutouts
b = xyxy2xywh(d[:, :4]) # boxes
b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # rectangle to square
b[:, 2:] = b[:, 2:] * 1.3 + 30 # pad
d[:, :4] = xywh2xyxy(b).long()
# Rescale boxes from img_size to im0 size
scale_coords(img.shape[2:], d[:, :4], im0[i].shape)
# Classes
pred_cls1 = d[:, 5].long()
ims = []
for j, a in enumerate(d): # per item
cutout = im0[i][int(a[1]):int(a[3]), int(a[0]):int(a[2])]
im = cv2.resize(cutout, (224, 224)) # BGR
# cv2.imwrite('example%i.jpg' % j, cutout)
im = im[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
im = np.ascontiguousarray(im, dtype=np.float32) # uint8 to float32
im /= 255.0 # 0 - 255 to 0.0 - 1.0
ims.append(im)
pred_cls2 = model(torch.Tensor(ims).to(d.device)).argmax(1) # classifier prediction
x[i] = x[i][pred_cls1 == pred_cls2] # retain matching class detections
return x
def save_one_box(xyxy, im, file='image.jpg', gain=1.02, pad=10, square=False, BGR=False, save=True):
# Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
xyxy = torch.tensor(xyxy).view(-1, 4)
b = xyxy2xywh(xyxy) # boxes
if square:
b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
xyxy = xywh2xyxy(b).long()
clip_coords(xyxy, im.shape)
crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
if save:
cv2.imwrite(str(increment_path(file, mkdir=True).with_suffix('.jpg')), crop)
return crop
def increment_path(path, exist_ok=False, sep='', mkdir=False):
# Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
path = Path(path) # os-agnostic
if path.exists() and not exist_ok:
suffix = path.suffix
path = path.with_suffix('')
dirs = glob.glob(f"{path}{sep}*") # similar paths
matches = [re.search(rf"%s{sep}(\d+)" % path.stem, d) for d in dirs]
i = [int(m.groups()[0]) for m in matches if m] # indices
n = max(i) + 1 if i else 2 # increment number
path = Path(f"{path}{sep}{n}{suffix}") # update path
dir = path if path.suffix == '' else path.parent # directory
if not dir.exists() and mkdir:
dir.mkdir(parents=True, exist_ok=True) # make directory
return path
loss.py 相关损失函数

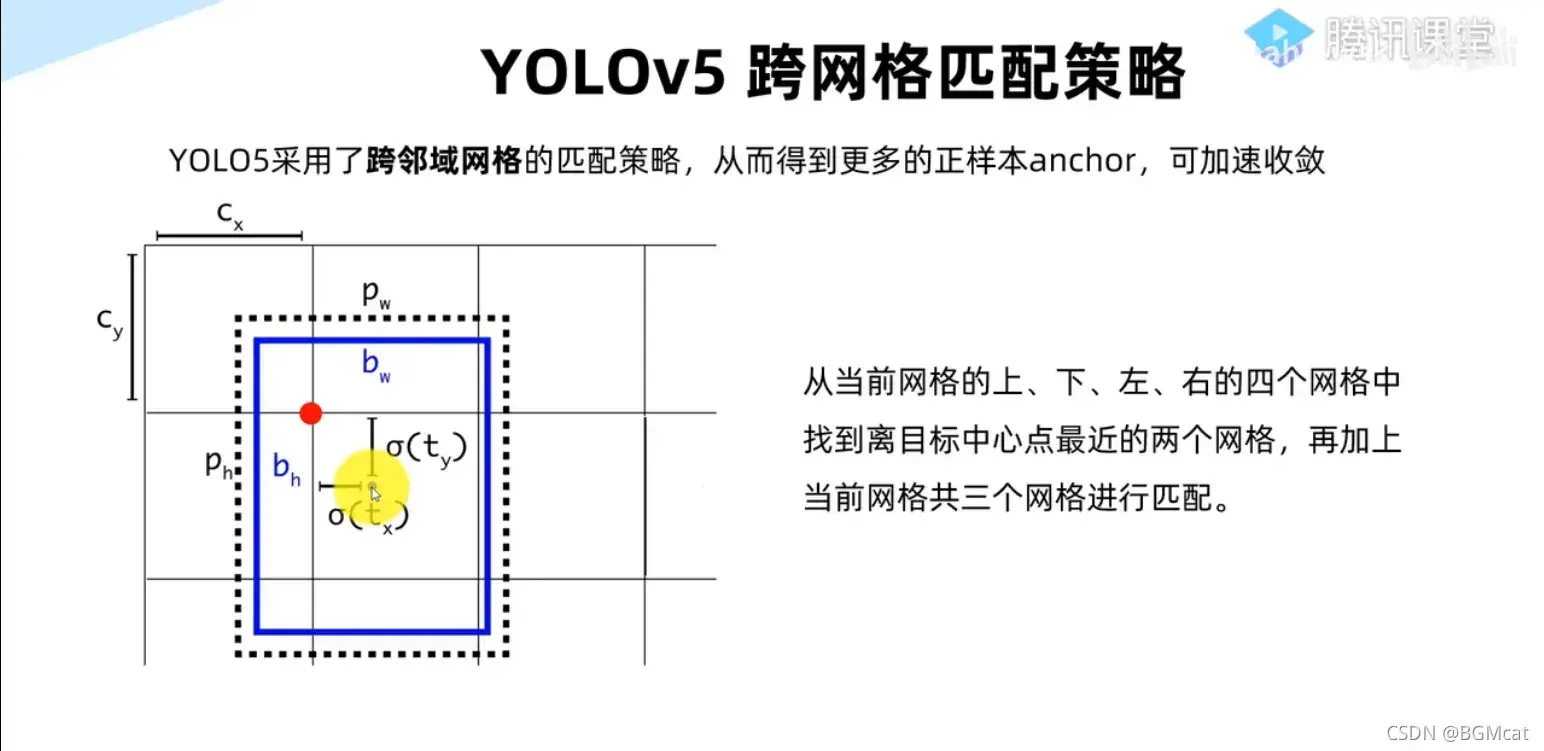
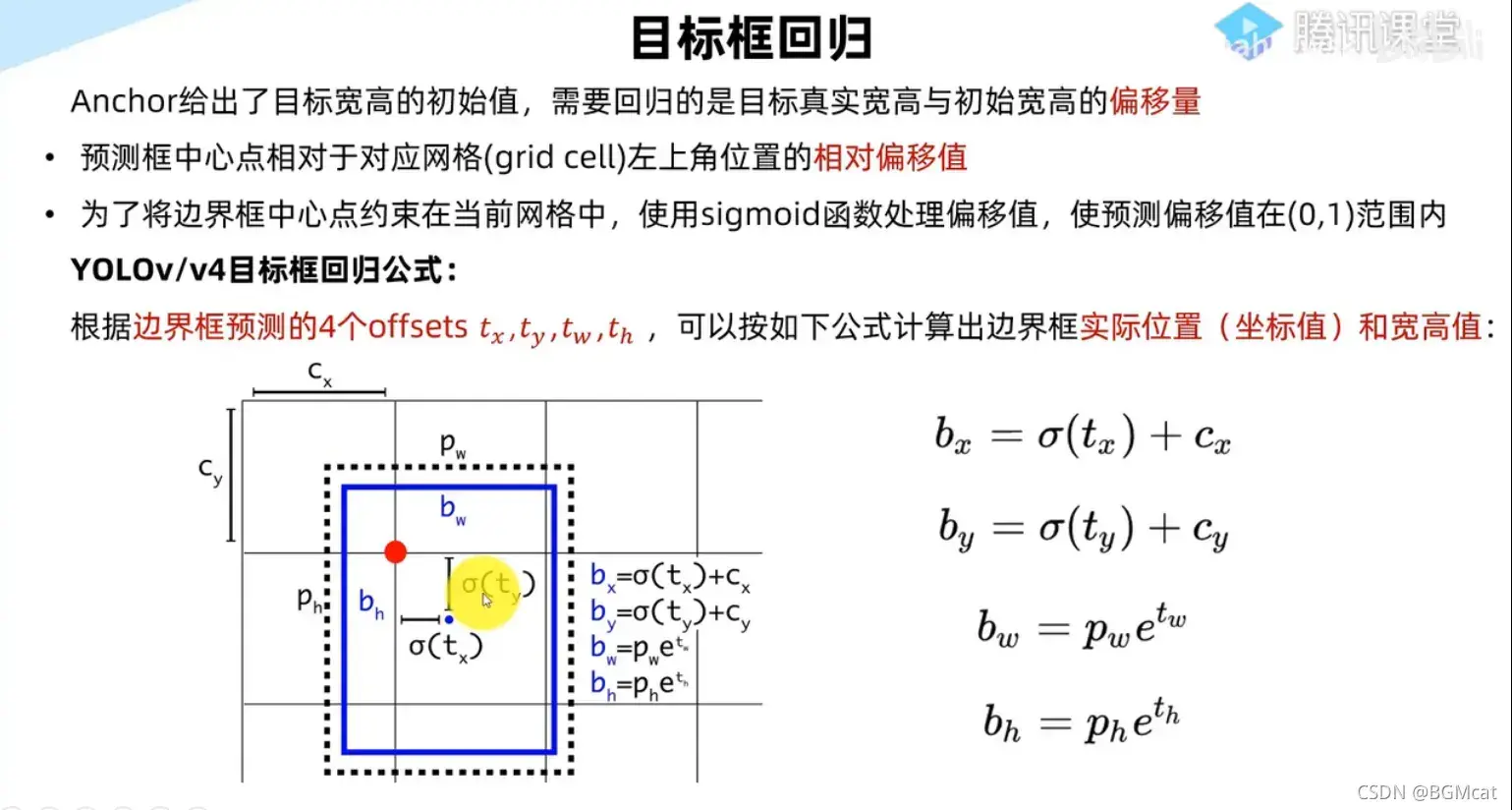
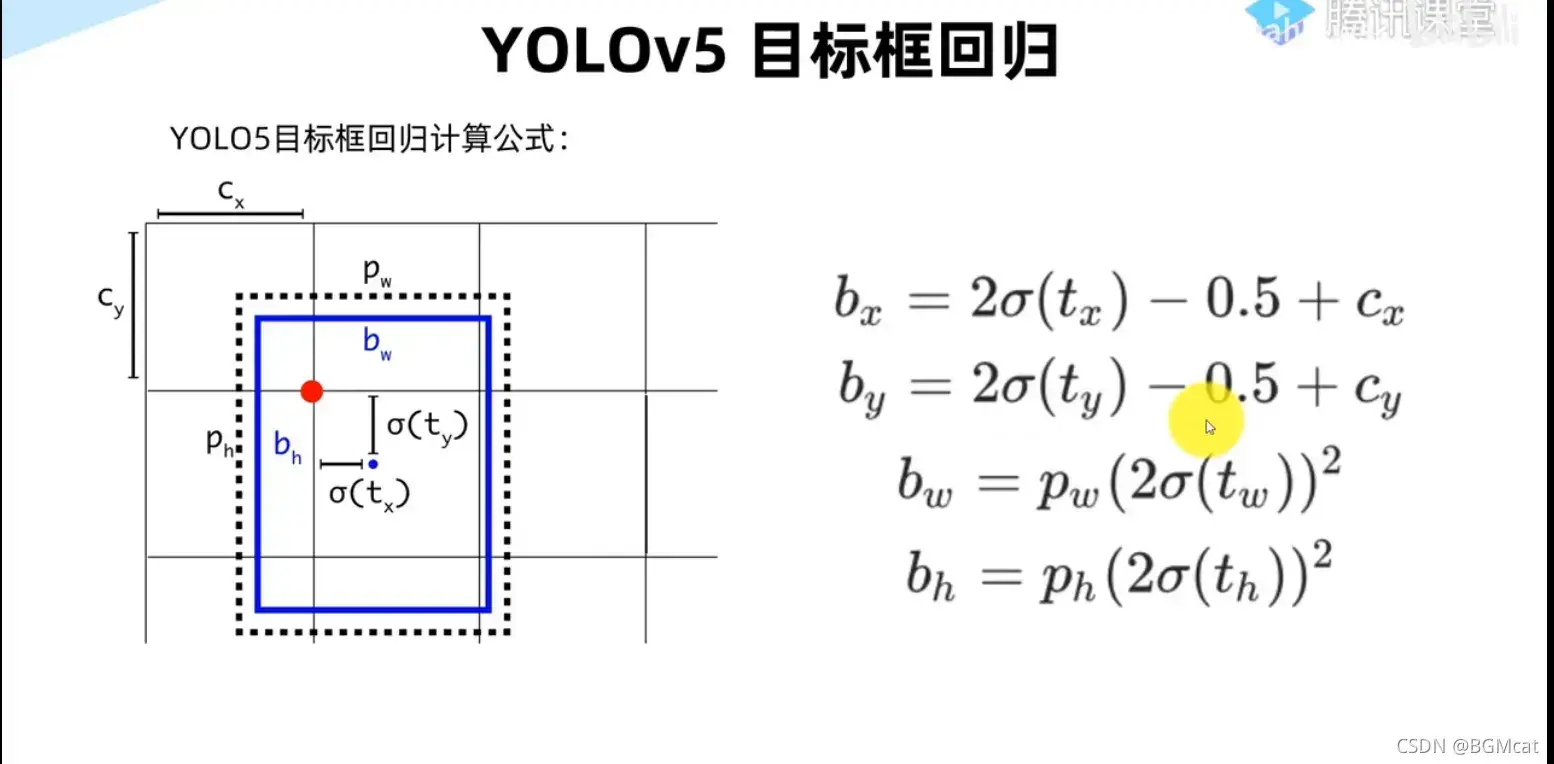
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Loss functions
"""
import torch
import torch.nn as nn
from utils.metrics import bbox_iou
from utils.torch_utils import is_parallel
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# return positive, negative label smoothing BCE targets
return 1.0 - 0.5 * eps, 0.5 * eps
class BCEBlurWithLogitsLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=0.05):
super(BCEBlurWithLogitsLoss, self).__init__()
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
self.alpha = alpha
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred = torch.sigmoid(pred) # prob from logits
dx = pred - true # reduce only missing label effects
# dx = (pred - true).abs() # reduce missing label and false label effects
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
loss *= alpha_factor
return loss.mean()
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(FocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
class QFocalLoss(nn.Module):
# Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(QFocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = torch.abs(true - pred_prob) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
class ComputeLoss:
# Compute losses
def __init__(self, model, autobalance=False):
self.sort_obj_iou = False
#获取设备
device = next(model.parameters()).device # get model device
#获取超参数
h = model.hyp # hyperparameters
# Define criteria
#定义类别和目标性得分函数
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
#标签平滑,esp默认是0,其实没有用到
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
for k in 'na', 'nc', 'nl', 'anchors':
setattr(self, k, getattr(det, k))
def __call__(self, p, targets): # predictions, targets, model
device = targets.device
#初始化各个部分损失
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
#获得标签分类,边框,索引,anchors
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
#根据indices 获取损失,方便找到对于的网格输出
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
#找到对于的网格输出,取出对应的位置预测值
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression
#对输出的xywh做反算
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
#计算边框损失,注意这个CIOu = True,计算的是ciou损失
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness
#根据model.gr设置objectness的标签值,有目标的conf分支权重
#不同的anchor和gt bbox匹配度不一样,预测框和gt bbox 的匹配度也不一样,如果权重设置一样肯定不是最优的
#故将预测框和被剥削的iou作为权重乘到conf分支,用来表征测量质量
score_iou = iou.detach().clamp(0).type(tobj.dtype)
if self.sort_obj_iou:
sort_id = torch.argsort(score_iou)
b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
# Classification
#设置如果类别数大于1,才计算分类损失
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCE,每个类单独计算loss
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
#计算objectness的损失
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
#根据超参数设置的各个部分的损失系数获取最终的损失
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
'''
build_target函数用于在获得训练时计算loss函数所需要的的目标框,即被认为是正样本
v5支持跨网络预测
对于任何一个box,三个预测输入框层都有可能与先验框匹配
该函数的输出正样本相比于传入的target数目多
'''
def build_targets(self, p, targets):
'''
:param p: 网络输出
:param targets: GT框,targets.shape= (nt,6),6:icxywh,i表示第i+1张图片,c表示类别,坐标xywh
:return:
'''
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
#anchor数量和标签框的数量
#target nx6, 其中n 是batch内所有皂片label拼接成的
#6的第0维表示当前是第几张图片的label = index,后面是classid_xywh
na, nt = self.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
#ai.shape = (na,nt) 生成anchor的所有
#anchor索引,后面有用,用于表示当前bbox和当前层的哪个anchor匹配
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
#先respeat targets 当前层anchor个数一样,相当于每个bbox变成了三个,然后和3个anchor单独匹配
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
#设置网络中心偏移量
g = 0.5 # bias
#附近4个网络
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
#对每个检查层进行处理
for i in range(self.nl):
anchors = self.anchors[i]
#p 是网络输出值
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
#将标签框的xywh从基于0-1映射到基于特征图:target的xywh本身是归一化尺度,故需要变成特征图尺度
t = targets * gain
#对每个输出层单独匹配
#首先将targets变成anchor尺度,方便计算
if nt:
# Matches
#预测的wh与anchor的wh做匹配,筛选掉比值大于hyp['anchor_t']的,从而更好的回归
#作者采用更好的回归方式:(wh.sigmoid() * 2)** 2 * anchors[i]
#原来的为 anchors[i] *exp(wh)
#将标签框与anchor的倍数控制在0-4之间,hyp.scratch.yaml中的超参数anchors_t =4 ,用于判定anchorS与标签框的契合度
#计算当前的target的wh 和anchor的wh比例值
#如果最大比例大于阈值model.hyp['anchor_t']=4,则当前target和anchor的匹配度不够高,不强制回归,而将target丢弃
#计算比值ratio
r = t[:, :, 4:6] / anchors[:, None] # wh ratio ,不考虑xy坐标
#筛选满足 1/ hyp['anchor_t'] < targets_wh / anchor_wh <hyp['anchor_t']的框
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
#筛选过后的t.shape = (M,7),M,为过滤后的数量
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy label的中心坐标
#得到中心坐标相对于当前特征图的坐标, (M,2)
gxi = gain[[2, 3]] - gxy # inverse
#对于筛选后的bbox,计算其落在哪个网格内,同时找出紧邻的网格,将这些网格都认为是负责预测该bbox的网格
#浮点数取模的数学定义,对于两个浮点数a和b,a%b = a - n*b,其中n为不超过a/b 的最大整数
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
#j.shape = (5,M)
j = torch.stack((torch.ones_like(j), j, k, l, m))
#预设的off = 5
t = t.repeat((5, 1, 1))[j]
#添加偏移量
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]#选出5个最近的,包括自己
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy label中心点坐标
#宽高回归标签
gwh = t[:, 4:6] # grid wh
#当前label落在哪一个标签上
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices(索引值)
# Append
a = t[:, 6].long() # anchor indices,anchor的索引
#添加索引方便,计算损失的时候取出对于位置的坐标
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box 坐标值
anch.append(anchors[a]) # anchors 尺寸
tcls.append(c) # class
return tcls, tbox, indices, anch
metrics.py 计算性能指标的相关函数
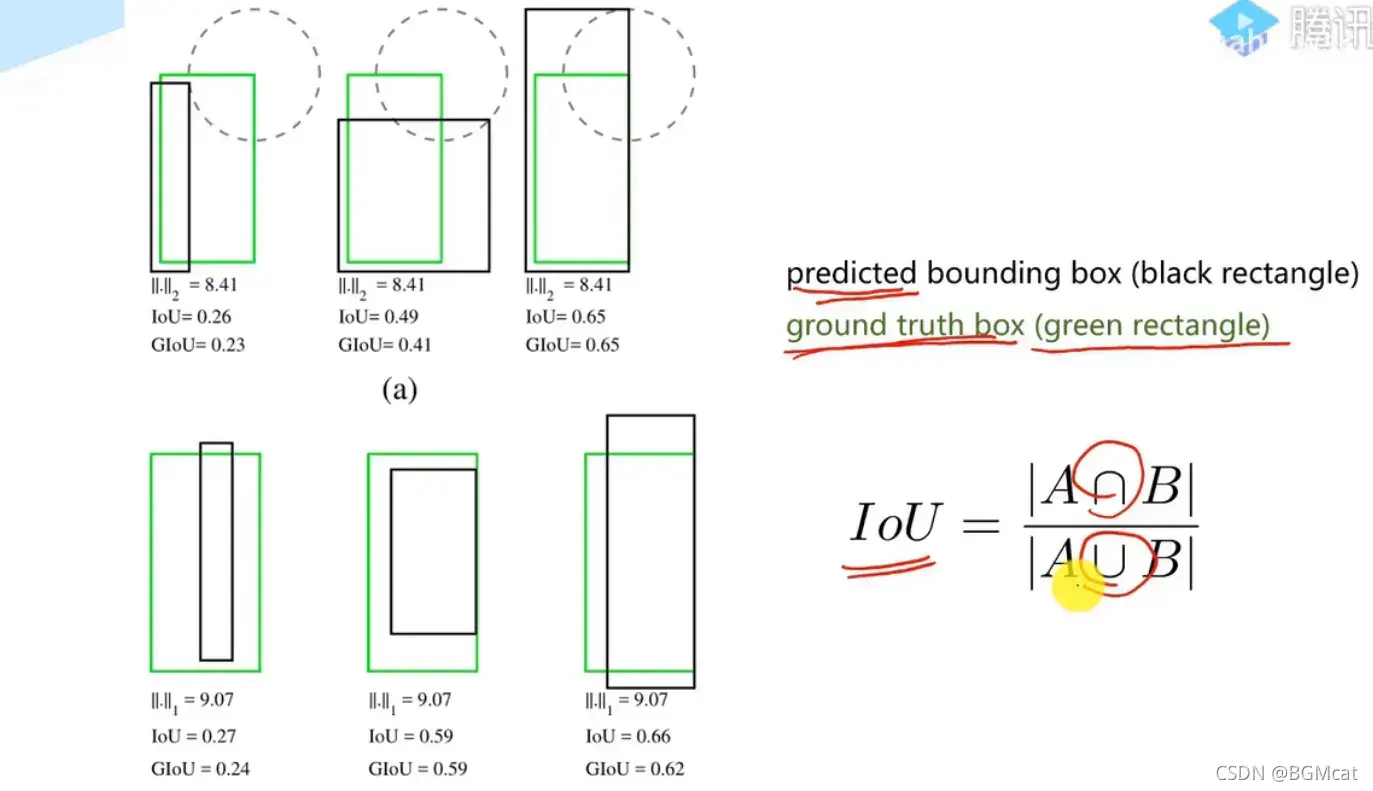
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Model validation metrics
"""
import math
import warnings
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
def fitness(x):
# Model fitness as a weighted combination of metrics
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
return (x[:, :4] * w).sum(1)
#计算类别的ap(p,r,f1)
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=()):
""" Compute the average precision, given the recall and precision curves.
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
# Arguments
tp: True positives (nparray, nx1 or nx10).
conf: Objectness value from 0-1 (nparray).
pred_cls: Predicted object classes (nparray).
target_cls: True object classes (nparray).
plot: Plot precision-recall curve at mAP@0.5
save_dir: Plot save directory
# Returns
The average precision as computed in py-faster-rcnn.
"""
# Sort by objectness
i = np.argsort(-conf)
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes
unique_classes = np.unique(target_cls)
nc = unique_classes.shape[0] # number of classes, number of detections
# Create Precision-Recall curve and compute AP for each class
px, py = np.linspace(0, 1, 1000), [] # for plotting
ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
for ci, c in enumerate(unique_classes):
i = pred_cls == c
n_l = (target_cls == c).sum() # number of labels
n_p = i.sum() # number of predictions
if n_p == 0 or n_l == 0:
continue
else:
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum(0)
tpc = tp[i].cumsum(0)
# Recall
recall = tpc / (n_l + 1e-16) # recall curve
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
# Precision
precision = tpc / (tpc + fpc) # precision curve
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
# AP from recall-precision curve
for j in range(tp.shape[1]):
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
if plot and j == 0:
py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
# Compute F1 (harmonic mean of precision and recall)
f1 = 2 * p * r / (p + r + 1e-16)
names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
names = {i: v for i, v in enumerate(names)} # to dict
if plot:#绘制p-r曲线
plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
i = f1.mean(0).argmax() # max F1 index
return p[:, i], r[:, i], ap, f1[:, i], unique_classes.astype('int32')
#上面函数的一部分,根据PR曲线计算ap
def compute_ap(recall, precision):
""" Compute the average precision, given the recall and precision curves
# Arguments
recall: The recall curve (list)
precision: The precision curve (list)
# Returns
Average precision, precision curve, recall curve
"""
# Append sentinel values to beginning and end
#把recall开放的部分补充成闭合区间
mrec = np.concatenate(([0.0], recall, [1.0]))
#mpre做相应的补充
mpre = np.concatenate(([1.0], precision, [0.0]))
# Compute the precision envelope
#人为的把pre-rec曲线变得单调递减,把整个曲线给填鼓起来
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# Integrate area under curve
method = 'interp' # methods: 'continuous', 'interp'
if method == 'interp':
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
else: # 'continuous'
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
return ap, mpre, mrec
#定义混淆矩阵
class ConfusionMatrix:
# Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
def __init__(self, nc, conf=0.25, iou_thres=0.45):
self.matrix = np.zeros((nc + 1, nc + 1))
self.nc = nc # number of classes
self.conf = conf
self.iou_thres = iou_thres
def process_batch(self, detections, labels):
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
labels (Array[M, 5]), class, x1, y1, x2, y2
Returns:
None, updates confusion matrix accordingly
"""
detections = detections[detections[:, 4] > self.conf]
gt_classes = labels[:, 0].int()
detection_classes = detections[:, 5].int()
iou = box_iou(labels[:, 1:], detections[:, :4])
x = torch.where(iou > self.iou_thres)
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
else:
matches = np.zeros((0, 3))
n = matches.shape[0] > 0
m0, m1, _ = matches.transpose().astype(np.int16)
for i, gc in enumerate(gt_classes):
j = m0 == i
if n and sum(j) == 1:
self.matrix[detection_classes[m1[j]], gc] += 1 # correct
else:
self.matrix[self.nc, gc] += 1 # background FP
if n:
for i, dc in enumerate(detection_classes):
if not any(m1 == i):
self.matrix[dc, self.nc] += 1 # background FN
def matrix(self):
return self.matrix
def plot(self, normalize=True, save_dir='', names=()):
try:
import seaborn as sn
array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-6) if normalize else 1) # normalize columns
array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
fig = plt.figure(figsize=(12, 9), tight_layout=True)
sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
xticklabels=names + ['background FP'] if labels else "auto",
yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
fig.axes[0].set_xlabel('True')
fig.axes[0].set_ylabel('Predicted')
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
plt.close()
except Exception as e:
print(f'WARNING: ConfusionMatrix plot failure: {e}')
def print(self):
for i in range(self.nc + 1):
print(' '.join(map(str, self.matrix[i])))
#计算两个框的特定iou(DIOU,CIOU,GIOU)
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
box2 = box2.T
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if DIoU:
return iou - rho2 / c2 # DIoU
elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
else:
return iou # IoU
def box_iou(box1, box2):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
def box_area(box):
# box = 4xn
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.T)
area2 = box_area(box2.T)
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
def bbox_ioa(box1, box2, eps=1E-7):
""" Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
box1: np.array of shape(4)
box2: np.array of shape(nx4)
returns: np.array of shape(n)
"""
box2 = box2.transpose()
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
# Intersection area
inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
(np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
# box2 area
box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
# Intersection over box2 area
return inter_area / box2_area
#计算iou矩阵
def wh_iou(wh1, wh2):
# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
wh1 = wh1[:, None] # [N,1,2]
wh2 = wh2[None] # [1,M,2]
inter = torch.min(wh1, wh2).prod(2) # [N,M]
return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
# Plots ----------------------------------------------------------------------------------------------------------------
def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
# Precision-recall curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
py = np.stack(py, axis=1)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py.T):
ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
else:
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
ax.set_xlabel('Recall')
ax.set_ylabel('Precision')
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
fig.savefig(Path(save_dir), dpi=250)
plt.close()
def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
# Metric-confidence curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py):
ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
else:
ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
y = py.mean(0)
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
fig.savefig(Path(save_dir), dpi=250)
plt.close()
plots.py
general.py
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
General utils
"""
import contextlib
import glob
import logging
import math
import os
import platform
import random
import re
import signal
import time
import urllib
from itertools import repeat
from multiprocessing.pool import ThreadPool
from pathlib import Path
from subprocess import check_output
from zipfile import ZipFile
import cv2
import numpy as np
import pandas as pd
import pkg_resources as pkg
import torch
import torchvision
import yaml
from utils.downloads import gsutil_getsize
from utils.metrics import box_iou, fitness
# Settings
torch.set_printoptions(linewidth=320, precision=5, profile='long')
np.set_printoptions(linewidth=320, formatter={'float_kind': '{:11.5g}'.format}) # format short g, %precision=5
pd.options.display.max_columns = 10
#禁止OpenCV的多线程,使用torch的所线程
cv2.setNumThreads(0) # prevent OpenCV from multithreading (incompatible with PyTorch DataLoader)
os.environ['NUMEXPR_MAX_THREADS'] = str(min(os.cpu_count(), 8)) # NumExpr max threads
FILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
class Profile(contextlib.ContextDecorator):
# Usage: @Profile() decorator or 'with Profile():' context manager
def __enter__(self):
self.start = time.time()
def __exit__(self, type, value, traceback):
print(f'Profile results: {time.time() - self.start:.5f}s')
class Timeout(contextlib.ContextDecorator):
# Usage: @Timeout(seconds) decorator or 'with Timeout(seconds):' context manager
def __init__(self, seconds, *, timeout_msg='', suppress_timeout_errors=True):
self.seconds = int(seconds)
self.timeout_message = timeout_msg
self.suppress = bool(suppress_timeout_errors)
def _timeout_handler(self, signum, frame):
raise TimeoutError(self.timeout_message)
def __enter__(self):
signal.signal(signal.SIGALRM, self._timeout_handler) # Set handler for SIGALRM
signal.alarm(self.seconds) # start countdown for SIGALRM to be raised
def __exit__(self, exc_type, exc_val, exc_tb):
signal.alarm(0) # Cancel SIGALRM if it's scheduled
if self.suppress and exc_type is TimeoutError: # Suppress TimeoutError
return True
def try_except(func):
# try-except function. Usage: @try_except decorator
def handler(*args, **kwargs):
try:
func(*args, **kwargs)
except Exception as e:
print(e)
return handler
def methods(instance):
# Get class/instance methods
return [f for f in dir(instance) if callable(getattr(instance, f)) and not f.startswith("__")]
#设置日志的保存级别
def set_logging(rank=-1, verbose=True):
logging.basicConfig(
format="%(message)s",
level=logging.INFO if (verbose and rank in [-1, 0]) else logging.WARN)
def print_args(name, opt):
# Print argparser arguments
print(colorstr(f'{name}: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items()))
#初始化随机数种子
def init_seeds(seed=0):
# Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
# cudnn seed 0 settings are slower and more reproducible, else faster and less reproducible
import torch.backends.cudnn as cudnn
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
cudnn.benchmark, cudnn.deterministic = (False, True) if seed == 0 else (True, False)
# 获取最近训练的权重文件,last.pt
def get_latest_run(search_dir='.'):
# Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
return max(last_list, key=os.path.getctime) if last_list else ''
def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
# Return path of user configuration directory. Prefer environment variable if exists. Make dir if required.
env = os.getenv(env_var)
if env:
path = Path(env) # use environment variable
else:
cfg = {'Windows': 'AppData/Roaming', 'Linux': '.config', 'Darwin': 'Library/Application Support'} # 3 OS dirs
path = Path.home() / cfg.get(platform.system(), '') # OS-specific config dir
path = (path if is_writeable(path) else Path('/tmp')) / dir # GCP and AWS lambda fix, only /tmp is writeable
path.mkdir(exist_ok=True) # make if required
return path
def is_writeable(dir, test=False):
# Return True if directory has write permissions, test opening a file with write permissions if test=True
if test: # method 1
file = Path(dir) / 'tmp.txt'
try:
with open(file, 'w'): # open file with write permissions
pass
file.unlink() # remove file
return True
except IOError:
return False
else: # method 2
return os.access(dir, os.R_OK) # possible issues on Windows
def is_docker():
# Is environment a Docker container?
return Path('/workspace').exists() # or Path('/.dockerenv').exists()
def is_colab():
# Is environment a Google Colab instance?
try:
import google.colab
return True
except ImportError:
return False
def is_pip():
# Is file in a pip package?
return 'site-packages' in Path(__file__).resolve().parts
def is_ascii(s=''):
# Is string composed of all ASCII (no UTF) characters? (note str().isascii() introduced in python 3.7)
s = str(s) # convert list, tuple, None, etc. to str
return len(s.encode().decode('ascii', 'ignore')) == len(s)
def is_chinese(s='人工智能'):
# Is string composed of any Chinese characters?
return re.search('[\u4e00-\u9fff]', s)
def emojis(str=''):
# Return platform-dependent emoji-safe version of string
return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
def file_size(path):
# Return file/dir size (MB)
path = Path(path)
if path.is_file():
return path.stat().st_size / 1E6
elif path.is_dir():
return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / 1E6
else:
return 0.0
def check_online():
# Check internet connectivity
import socket
try:
socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
return True
except OSError:
return False
@try_except
#检查当前的分支和Git上的版本是否一致,否则提醒用户
def check_git_status():
# Recommend 'git pull' if code is out of date
msg = ', for updates see https://github.com/ultralytics/yolov5'
print(colorstr('github: '), end='')
assert Path('.git').exists(), 'skipping check (not a git repository)' + msg
assert not is_docker(), 'skipping check (Docker image)' + msg
assert check_online(), 'skipping check (offline)' + msg
cmd = 'git fetch && git config --get remote.origin.url'
url = check_output(cmd, shell=True, timeout=5).decode().strip().rstrip('.git') # git fetch
branch = check_output('git rev-parse --abbrev-ref HEAD', shell=True).decode().strip() # checked out
n = int(check_output(f'git rev-list {branch}..origin/master --count', shell=True)) # commits behind
if n > 0:
s = f"⚠️ YOLOv5 is out of date by {n} commit{'s' * (n > 1)}. Use `git pull` or `git clone {url}` to update."
else:
s = f'up to date with {url} ✅'
print(emojis(s)) # emoji-safe
def check_python(minimum='3.6.2'):
# Check current python version vs. required python version
check_version(platform.python_version(), minimum, name='Python ')
def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False):
# Check version vs. required version
current, minimum = (pkg.parse_version(x) for x in (current, minimum))
result = (current == minimum) if pinned else (current >= minimum)
assert result, f'{name}{minimum} required by YOLOv5, but {name}{current} is currently installed'
@try_except
def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), install=True):
# Check installed dependencies meet requirements (pass *.txt file or list of packages)
prefix = colorstr('red', 'bold', 'requirements:')
check_python() # check python version
if isinstance(requirements, (str, Path)): # requirements.txt file
file = Path(requirements)
assert file.exists(), f"{prefix} {file.resolve()} not found, check failed."
requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(file.open()) if x.name not in exclude]
else: # list or tuple of packages
requirements = [x for x in requirements if x not in exclude]
n = 0 # number of packages updates
for r in requirements:
try:
pkg.require(r)
except Exception as e: # DistributionNotFound or VersionConflict if requirements not met
s = f"{prefix} {r} not found and is required by YOLOv5"
if install:
print(f"{s}, attempting auto-update...")
try:
assert check_online(), f"'pip install {r}' skipped (offline)"
print(check_output(f"pip install '{r}'", shell=True).decode())
n += 1
except Exception as e:
print(f'{prefix} {e}')
else:
print(f'{s}. Please install and rerun your command.')
if n: # if packages updated
source = file.resolve() if 'file' in locals() else requirements
s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
print(emojis(s))
#检查图像的尺寸是否是32的整数倍。否则调整
def check_img_size(imgsz, s=32, floor=0):
# Verify image size is a multiple of stride s in each dimension
if isinstance(imgsz, int): # integer i.e. img_size=640
new_size = max(make_divisible(imgsz, int(s)), floor)
else: # list i.e. img_size=[640, 480]
new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
if new_size != imgsz:
print(f'WARNING: --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
return new_size
def check_imshow():
# Check if environment supports image displays
try:
assert not is_docker(), 'cv2.imshow() is disabled in Docker environments'
assert not is_colab(), 'cv2.imshow() is disabled in Google Colab environments'
cv2.imshow('test', np.zeros((1, 1, 3)))
cv2.waitKey(1)
cv2.destroyAllWindows()
cv2.waitKey(1)
return True
except Exception as e:
print(f'WARNING: Environment does not support cv2.imshow() or PIL Image.show() image displays\n{e}')
return False
def check_suffix(file='yolov5s.pt', suffix=('.pt',), msg=''):
# Check file(s) for acceptable suffix
if file and suffix:
if isinstance(suffix, str):
suffix = [suffix]
for f in file if isinstance(file, (list, tuple)) else [file]:
s = Path(f).suffix.lower() # file suffix
if len(s):
assert s in suffix, f"{msg}{f} acceptable suffix is {suffix}"
def check_yaml(file, suffix=('.yaml', '.yml')):
# Search/download YAML file (if necessary) and return path, checking suffix
return check_file(file, suffix)
def check_file(file, suffix=''):
# Search/download file (if necessary) and return path
check_suffix(file, suffix) # optional
file = str(file) # convert to str()
if Path(file).is_file() or file == '': # exists
return file
elif file.startswith(('http:/', 'https:/')): # download
url = str(Path(file)).replace(':/', '://') # Pathlib turns :// -> :/
file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
print(f'Downloading {url} to {file}...')
torch.hub.download_url_to_file(url, file)
assert Path(file).exists() and Path(file).stat().st_size > 0, f'File download failed: {url}' # check
return file
else: # search
files = []
for d in 'data', 'models', 'utils': # search directories
files.extend(glob.glob(str(ROOT / d / '**' / file), recursive=True)) # find file
assert len(files), f'File not found: {file}' # assert file was found
assert len(files) == 1, f"Multiple files match '{file}', specify exact path: {files}" # assert unique
return files[0] # return file
def check_dataset(data, autodownload=True):
# Download and/or unzip dataset if not found locally
# Usage: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128_with_yaml.zip
# Download (optional)
extract_dir = ''
if isinstance(data, (str, Path)) and str(data).endswith('.zip'): # i.e. gs://bucket/dir/coco128.zip
download(data, dir='../datasets', unzip=True, delete=False, curl=False, threads=1)
data = next((Path('../datasets') / Path(data).stem).rglob('*.yaml'))
extract_dir, autodownload = data.parent, False
# Read yaml (optional)
if isinstance(data, (str, Path)):
with open(data, errors='ignore') as f:
data = yaml.safe_load(f) # dictionary
# Parse yaml
path = extract_dir or Path(data.get('path') or '') # optional 'path' default to '.'
for k in 'train', 'val', 'test':
if data.get(k): # prepend path
data[k] = str(path / data[k]) if isinstance(data[k], str) else [str(path / x) for x in data[k]]
assert 'nc' in data, "Dataset 'nc' key missing."
if 'names' not in data:
data['names'] = [f'class{i}' for i in range(data['nc'])] # assign class names if missing
train, val, test, s = [data.get(x) for x in ('train', 'val', 'test', 'download')]
if val:
val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
if not all(x.exists() for x in val):
print('\nWARNING: Dataset not found, nonexistent paths: %s' % [str(x) for x in val if not x.exists()])
if s and autodownload: # download script
root = path.parent if 'path' in data else '..' # unzip directory i.e. '../'
if s.startswith('http') and s.endswith('.zip'): # URL
f = Path(s).name # filename
print(f'Downloading {s} to {f}...')
torch.hub.download_url_to_file(s, f)
Path(root).mkdir(parents=True, exist_ok=True) # create root
ZipFile(f).extractall(path=root) # unzip
Path(f).unlink() # remove zip
r = None # success
elif s.startswith('bash '): # bash script
print(f'Running {s} ...')
r = os.system(s)
else: # python script
r = exec(s, {'yaml': data}) # return None
print(f"Dataset autodownload {f'success, saved to {root}' if r in (0, None) else 'failure'}\n")
else:
raise Exception('Dataset not found.')
return data # dictionary
def url2file(url):
# Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
file = Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
return file
def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1):
# Multi-threaded file download and unzip function, used in data.yaml for autodownload
def download_one(url, dir):
# Download 1 file
f = dir / Path(url).name # filename
if Path(url).is_file(): # exists in current path
Path(url).rename(f) # move to dir
elif not f.exists():
print(f'Downloading {url} to {f}...')
if curl:
os.system(f"curl -L '{url}' -o '{f}' --retry 9 -C -") # curl download, retry and resume on fail
else:
torch.hub.download_url_to_file(url, f, progress=True) # torch download
if unzip and f.suffix in ('.zip', '.gz'):
print(f'Unzipping {f}...')
if f.suffix == '.zip':
ZipFile(f).extractall(path=dir) # unzip
elif f.suffix == '.gz':
os.system(f'tar xfz {f} --directory {f.parent}') # unzip
if delete:
f.unlink() # remove zip
dir = Path(dir)
dir.mkdir(parents=True, exist_ok=True) # make directory
if threads > 1:
pool = ThreadPool(threads)
pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multi-threaded
pool.close()
pool.join()
else:
for u in [url] if isinstance(url, (str, Path)) else url:
download_one(u, dir)
def make_divisible(x, divisor):
# Returns x evenly divisible by divisor
return math.ceil(x / divisor) * divisor
def clean_str(s):
# Cleans a string by replacing special characters with underscore _
return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
def one_cycle(y1=0.0, y2=1.0, steps=100):
# lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
def colorstr(*input):
# Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
*args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
colors = {'black': '\033[30m', # basic colors
'red': '\033[31m',
'green': '\033[32m',
'yellow': '\033[33m',
'blue': '\033[34m',
'magenta': '\033[35m',
'cyan': '\033[36m',
'white': '\033[37m',
'bright_black': '\033[90m', # bright colors
'bright_red': '\033[91m',
'bright_green': '\033[92m',
'bright_yellow': '\033[93m',
'bright_blue': '\033[94m',
'bright_magenta': '\033[95m',
'bright_cyan': '\033[96m',
'bright_white': '\033[97m',
'end': '\033[0m', # misc
'bold': '\033[1m',
'underline': '\033[4m'}
return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
def labels_to_class_weights(labels, nc=80):
# Get class weights (inverse frequency) from training labels
if labels[0] is None: # no labels loaded
return torch.Tensor()
labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
classes = labels[:, 0].astype(np.int) # labels = [class xywh]
weights = np.bincount(classes, minlength=nc) # occurrences per class
# Prepend gridpoint count (for uCE training)
# gpi = ((320 / 32 * np.array([1, 2, 4])) ** 2 * 3).sum() # gridpoints per image
# weights = np.hstack([gpi * len(labels) - weights.sum() * 9, weights * 9]) ** 0.5 # prepend gridpoints to start
weights[weights == 0] = 1 # replace empty bins with 1
weights = 1 / weights # number of targets per class
weights /= weights.sum() # normalize
return torch.from_numpy(weights)
def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
# Produces image weights based on class_weights and image contents
class_counts = np.array([np.bincount(x[:, 0].astype(np.int), minlength=nc) for x in labels])
image_weights = (class_weights.reshape(1, nc) * class_counts).sum(1)
# index = random.choices(range(n), weights=image_weights, k=1) # weight image sample
return image_weights
def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
# https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
# a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
# b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
# x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
# x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
return x
def xyxy2xywh(x):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
y[:, 2] = x[:, 2] - x[:, 0] # width
y[:, 3] = x[:, 3] - x[:, 1] # height
return y
def xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
# Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
return y
def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
if clip:
clip_coords(x, (h - eps, w - eps)) # warning: inplace clip
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
return y
def xyn2xy(x, w=640, h=640, padw=0, padh=0):
# Convert normalized segments into pixel segments, shape (n,2)
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = w * x[:, 0] + padw # top left x
y[:, 1] = h * x[:, 1] + padh # top left y
return y
def segment2box(segment, width=640, height=640):
# Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
x, y = segment.T # segment xy
inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
x, y, = x[inside], y[inside]
return np.array([x.min(), y.min(), x.max(), y.max()]) if any(x) else np.zeros((1, 4)) # xyxy
def segments2boxes(segments):
# Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
boxes = []
for s in segments:
x, y = s.T # segment xy
boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
return xyxy2xywh(np.array(boxes)) # cls, xywh
def resample_segments(segments, n=1000):
# Up-sample an (n,2) segment
for i, s in enumerate(segments):
x = np.linspace(0, len(s) - 1, n)
xp = np.arange(len(s))
segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)]).reshape(2, -1).T # segment xy
return segments
def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
coords[:, [0, 2]] -= pad[0] # x padding
coords[:, [1, 3]] -= pad[1] # y padding
coords[:, :4] /= gain
clip_coords(coords, img0_shape)
return coords
def clip_coords(boxes, shape):
# Clip bounding xyxy bounding boxes to image shape (height, width)
if isinstance(boxes, torch.Tensor): # faster individually
boxes[:, 0].clamp_(0, shape[1]) # x1
boxes[:, 1].clamp_(0, shape[0]) # y1
boxes[:, 2].clamp_(0, shape[1]) # x2
boxes[:, 3].clamp_(0, shape[0]) # y2
else: # np.array (faster grouped)
boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
#非极大值抑制
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False,
labels=(), max_det=300):
"""Runs Non-Maximum Suppression (NMS) on inference results
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
nc = prediction.shape[2] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Checks
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {time_limit}s exceeded')
break # time limit exceeded
return output
def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_optimizer()
# Strip optimizer from 'f' to finalize training, optionally save as 's'
x = torch.load(f, map_location=torch.device('cpu'))
if x.get('ema'):
x['model'] = x['ema'] # replace model with ema
for k in 'optimizer', 'training_results', 'wandb_id', 'ema', 'updates': # keys
x[k] = None
x['epoch'] = -1
x['model'].half() # to FP16
for p in x['model'].parameters():
p.requires_grad = False
torch.save(x, s or f)
mb = os.path.getsize(s or f) / 1E6 # filesize
print(f"Optimizer stripped from {f},{(' saved as %s,' % s) if s else ''} {mb:.1f}MB")
def print_mutation(results, hyp, save_dir, bucket):
evolve_csv, results_csv, evolve_yaml = save_dir / 'evolve.csv', save_dir / 'results.csv', save_dir / 'hyp_evolve.yaml'
keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
'val/box_loss', 'val/obj_loss', 'val/cls_loss') + tuple(hyp.keys()) # [results + hyps]
keys = tuple(x.strip() for x in keys)
vals = results + tuple(hyp.values())
n = len(keys)
# Download (optional)
if bucket:
url = f'gs://{bucket}/evolve.csv'
if gsutil_getsize(url) > (os.path.getsize(evolve_csv) if os.path.exists(evolve_csv) else 0):
os.system(f'gsutil cp {url} {save_dir}') # download evolve.csv if larger than local
# Log to evolve.csv
s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n') # add header
with open(evolve_csv, 'a') as f:
f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
# Print to screen
print(colorstr('evolve: ') + ', '.join(f'{x.strip():>20s}' for x in keys))
print(colorstr('evolve: ') + ', '.join(f'{x:20.5g}' for x in vals), end='\n\n\n')
# Save yaml
with open(evolve_yaml, 'w') as f:
data = pd.read_csv(evolve_csv)
data = data.rename(columns=lambda x: x.strip()) # strip keys
i = np.argmax(fitness(data.values[:, :7])) #
f.write('# YOLOv5 Hyperparameter Evolution Results\n' +
f'# Best generation: {i}\n' +
f'# Last generation: {len(data)}\n' +
'# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) + '\n' +
'# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
yaml.safe_dump(hyp, f, sort_keys=False)
if bucket:
os.system(f'gsutil cp {evolve_csv} {evolve_yaml} gs://{bucket}') # upload
def apply_classifier(x, model, img, im0):
# Apply a second stage classifier to yolo outputs
im0 = [im0] if isinstance(im0, np.ndarray) else im0
for i, d in enumerate(x): # per image
if d is not None and len(d):
d = d.clone()
# Reshape and pad cutouts
b = xyxy2xywh(d[:, :4]) # boxes
b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # rectangle to square
b[:, 2:] = b[:, 2:] * 1.3 + 30 # pad
d[:, :4] = xywh2xyxy(b).long()
# Rescale boxes from img_size to im0 size
scale_coords(img.shape[2:], d[:, :4], im0[i].shape)
# Classes
pred_cls1 = d[:, 5].long()
ims = []
for j, a in enumerate(d): # per item
cutout = im0[i][int(a[1]):int(a[3]), int(a[0]):int(a[2])]
im = cv2.resize(cutout, (224, 224)) # BGR
# cv2.imwrite('example%i.jpg' % j, cutout)
im = im[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
im = np.ascontiguousarray(im, dtype=np.float32) # uint8 to float32
im /= 255.0 # 0 - 255 to 0.0 - 1.0
ims.append(im)
pred_cls2 = model(torch.Tensor(ims).to(d.device)).argmax(1) # classifier prediction
x[i] = x[i][pred_cls1 == pred_cls2] # retain matching class detections
return x
def save_one_box(xyxy, im, file='image.jpg', gain=1.02, pad=10, square=False, BGR=False, save=True):
# Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
xyxy = torch.tensor(xyxy).view(-1, 4)
b = xyxy2xywh(xyxy) # boxes
if square:
b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
xyxy = xywh2xyxy(b).long()
clip_coords(xyxy, im.shape)
crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
if save:
cv2.imwrite(str(increment_path(file, mkdir=True).with_suffix('.jpg')), crop)
return crop
def increment_path(path, exist_ok=False, sep='', mkdir=False):
# Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
path = Path(path) # os-agnostic
if path.exists() and not exist_ok:
suffix = path.suffix
path = path.with_suffix('')
dirs = glob.glob(f"{path}{sep}*") # similar paths
matches = [re.search(rf"%s{sep}(\d+)" % path.stem, d) for d in dirs]
i = [int(m.groups()[0]) for m in matches if m] # indices
n = max(i) + 1 if i else 2 # increment number
path = Path(f"{path}{sep}{n}{suffix}") # update path
dir = path if path.suffix == '' else path.parent # directory
if not dir.exists() and mkdir:
dir.mkdir(parents=True, exist_ok=True) # make directory
return path
torch_utils 辅助程序代码并行计算,早停策略等函数
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
PyTorch utils
"""
import datetime
import logging
import math
import os
import platform
import subprocess
import time
from contextlib import contextmanager
from copy import deepcopy
from pathlib import Path
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torchvision
try:
import thop # for FLOPs computation
except ImportError:
thop = None
LOGGER = logging.getLogger(__name__)
@contextmanager
def torch_distributed_zero_first(local_rank: int):
"""
Decorator to make all processes in distributed training wait for each local_master to do something.
"""
if local_rank not in [-1, 0]:
dist.barrier(device_ids=[local_rank])
yield
if local_rank == 0:
dist.barrier(device_ids=[0])
def date_modified(path=__file__):
# return human-readable file modification date, i.e. '2021-3-26'
t = datetime.datetime.fromtimestamp(Path(path).stat().st_mtime)
return f'{t.year}-{t.month}-{t.day}'
def git_describe(path=Path(__file__).parent): # path must be a directory
# return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
s = f'git -C {path} describe --tags --long --always'
try:
return subprocess.check_output(s, shell=True, stderr=subprocess.STDOUT).decode()[:-1]
except subprocess.CalledProcessError as e:
return '' # not a git repository
#选择设备
def select_device(device='', batch_size=None):
# device = 'cpu' or '0' or '0,1,2,3'
s = f'YOLOv5 🚀 {git_describe() or date_modified()} torch {torch.__version__} ' # string
device = str(device).strip().lower().replace('cuda:', '') # to string, 'cuda:0' to '0'
cpu = device == 'cpu'
if cpu:
os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
elif device: # non-cpu device requested
os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable 设定可用的gpu显卡
assert torch.cuda.is_available(), f'CUDA unavailable, invalid device {device} requested' # check availability
cuda = not cpu and torch.cuda.is_available()
if cuda:
devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
n = len(devices) # device count
if n > 1 and batch_size: # check batch_size is divisible by device_count
assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
space = ' ' * (len(s) + 1)
for i, d in enumerate(devices):
p = torch.cuda.get_device_properties(i)
s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / 1024 ** 2}MB)\n" # bytes to MB
else:
s += 'CPU\n'
LOGGER.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
return torch.device('cuda:0' if cuda else 'cpu')
#时间同步(等待GPU操作完成)
def time_sync():
# pytorch-accurate time
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
def profile(input, ops, n=10, device=None):
# YOLOv5 speed/memory/FLOPs profiler
#
# Usage:
# input = torch.randn(16, 3, 640, 640)
# m1 = lambda x: x * torch.sigmoid(x)
# m2 = nn.SiLU()
# profile(input, [m1, m2], n=100) # profile over 100 iterations
results = []
logging.basicConfig(format="%(message)s", level=logging.INFO)
device = device or select_device()
print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
f"{'input':>24s}{'output':>24s}")
for x in input if isinstance(input, list) else [input]:
x = x.to(device)
x.requires_grad = True
for m in ops if isinstance(ops, list) else [ops]:
m = m.to(device) if hasattr(m, 'to') else m # device
m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
tf, tb, t = 0., 0., [0., 0., 0.] # dt forward, backward
try:
flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
except:
flops = 0
try:
for _ in range(n):
t[0] = time_sync()
y = m(x)
t[1] = time_sync()
try:
_ = (sum([yi.sum() for yi in y]) if isinstance(y, list) else y).sum().backward()
t[2] = time_sync()
except Exception as e: # no backward method
print(e)
t[2] = float('nan')
tf += (t[1] - t[0]) * 1000 / n # ms per op forward
tb += (t[2] - t[1]) * 1000 / n # ms per op backward
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
s_in = tuple(x.shape) if isinstance(x, torch.Tensor) else 'list'
s_out = tuple(y.shape) if isinstance(y, torch.Tensor) else 'list'
p = sum(list(x.numel() for x in m.parameters())) if isinstance(m, nn.Module) else 0 # parameters
print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
results.append([p, flops, mem, tf, tb, s_in, s_out])
except Exception as e:
print(e)
results.append(None)
torch.cuda.empty_cache()
return results
#是否并行计算
def is_parallel(model):
# Returns True if model is of type DP or DDP
return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
def de_parallel(model):
# De-parallelize a model: returns single-GPU model if model is of type DP or DDP
return model.module if is_parallel(model) else model
#查找字典交集
def intersect_dicts(da, db, exclude=()):
# Dictionary intersection of matching keys and shapes, omitting 'exclude' keys, using da values
return {k: v for k, v in da.items() if k in db and not any(x in k for x in exclude) and v.shape == db[k].shape}
#初始化权重
def initialize_weights(model):
for m in model.modules():
t = type(m)
if t is nn.Conv2d:
pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif t is nn.BatchNorm2d:
m.eps = 1e-3
m.momentum = 0.03
elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6]:
m.inplace = True
#找到匹配的module class名字的层索引
def find_modules(model, mclass=nn.Conv2d):
# Finds layer indices matching module class 'mclass'
return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
#计算模型稀疏度
def sparsity(model):
# Return global model sparsity
a, b = 0., 0.
for p in model.parameters():
a += p.numel() #权重总数
b += (p == 0).sum() #为0 的权重数
return b / a
#模型剪枝
def prune(model, amount=0.3):
# Prune model to requested global sparsity
import torch.nn.utils.prune as prune
print('Pruning model... ', end='')
for name, m in model.named_modules():
if isinstance(m, nn.Conv2d):#对卷积层进行剪枝
#将所有卷积层的权重减去30%,减去lowest L1-norm的权重
prune.l1_unstructured(m, name='weight', amount=amount) # prune
prune.remove(m, 'weight') # make permanent
print(' %.3g global sparsity' % sparsity(model))
# 融合conv和bn层
def fuse_conv_and_bn(conv, bn):
# Fuse convolution and batchnorm layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
# prepare filters
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
# prepare spatial bias
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
return fusedconv
def model_info(model, verbose=False, img_size=640):
# Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
n_p = sum(x.numel() for x in model.parameters()) # number parameters
n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
if verbose:
print('%5s %40s %9s %12s %20s %10s %10s' % ('layer', 'name', 'gradient', 'parameters', 'shape', 'mu', 'sigma'))
for i, (name, p) in enumerate(model.named_parameters()):
name = name.replace('module_list.', '')
print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
(i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
try: # FLOPs
from thop import profile
stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32
img = torch.zeros((1, model.yaml.get('ch', 3), stride, stride), device=next(model.parameters()).device) # input
flops = profile(deepcopy(model), inputs=(img,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
img_size = img_size if isinstance(img_size, list) else [img_size, img_size] # expand if int/float
fs = ', %.1f GFLOPs' % (flops * img_size[0] / stride * img_size[1] / stride) # 640x640 GFLOPs
except (ImportError, Exception):
fs = ''
LOGGER.info(f"Model Summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
#加载第二类分类器
def load_classifier(name='resnet101', n=2):
# Loads a pretrained model reshaped to n-class output
model = torchvision.models.__dict__[name](pretrained=True)
# ResNet model properties
# input_size = [3, 224, 224]
# input_space = 'RGB'
# input_range = [0, 1]
# mean = [0.485, 0.456, 0.406]
# std = [0.229, 0.224, 0.225]
# Reshape output to n classes
filters = model.fc.weight.shape[1]
model.fc.bias = nn.Parameter(torch.zeros(n), requires_grad=True)
model.fc.weight = nn.Parameter(torch.zeros(n, filters), requires_grad=True)
model.fc.out_features = n
return model
#根据ratio改变模型尺寸
def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
# scales img(bs,3,y,x) by ratio constrained to gs-multiple
if ratio == 1.0:
return img
else:
h, w = img.shape[2:]
s = (int(h * ratio), int(w * ratio)) # new size
img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
if not same_shape: # pad/crop img
h, w = [math.ceil(x * ratio / gs) * gs for x in (h, w)]
return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
#复制属性值
def copy_attr(a, b, include=(), exclude=()):
# Copy attributes from b to a, options to only include [...] and to exclude [...]
for k, v in b.__dict__.items():
if (len(include) and k not in include) or k.startswith('_') or k in exclude:
continue
else:
setattr(a, k, v)
#早停策略
class EarlyStopping:
# YOLOv5 simple early stopper
def __init__(self, patience=30):
self.best_fitness = 0.0 # i.e. mAP
self.best_epoch = 0
self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
self.possible_stop = False # possible stop may occur next epoch
def __call__(self, epoch, fitness):
if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
self.best_epoch = epoch
self.best_fitness = fitness
delta = epoch - self.best_epoch # epochs without improvement
self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
stop = delta >= self.patience # stop training if patience exceeded
if stop:
LOGGER.info(f'EarlyStopping patience {self.patience} exceeded, stopping training.')
return stop
#模型EMA
class ModelEMA:
""" Model Exponential Moving Average from https://github.com/rwightman/pytorch-image-models
Keep a moving average of everything in the model state_dict (parameters and buffers).
This is intended to allow functionality like
https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
A smoothed version of the weights is necessary for some training schemes to perform well.
This class is sensitive where it is initialized in the sequence of model init,
GPU assignment and distributed training wrappers.
"""
def __init__(self, model, decay=0.9999, updates=0):
# Create EMA
self.ema = deepcopy(model.module if is_parallel(model) else model).eval() # FP32 EMA
# if next(model.parameters()).device.type != 'cpu':
# self.ema.half() # FP16 EMA
self.updates = updates # number of EMA updates
self.decay = lambda x: decay * (1 - math.exp(-x / 2000)) # decay exponential ramp (to help early epochs)
for p in self.ema.parameters():
p.requires_grad_(False)
def update(self, model):
# Update EMA parameters
with torch.no_grad():
self.updates += 1
d = self.decay(self.updates)
msd = model.module.state_dict() if is_parallel(model) else model.state_dict() # model state_dict
for k, v in self.ema.state_dict().items():
if v.dtype.is_floating_point:
v *= d
v += (1. - d) * msd[k].detach() #detach截断反向传播的梯度流
#将某个node变成不需要梯度的varibale,因此当反向传播经过这个node时,梯度不在向前传播
def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
# Update EMA attributes
copy_attr(self.ema, model, include, exclude)
weight文件夹
下载的权重文件,smlx,建议提前到Git上下载好,放在此处,download.py 一般会下载失败
detect.py
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Run inference on images, videos, directories, streams, etc.
Usage:
$ python path/to/detect.py --source path/to/img.jpg --weights yolov5s.pt --img 640
"""
import argparse #参数解析包
import os
import sys
from pathlib import Path
import cv2
import numpy as np
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.experimental import attempt_load
from utils.datasets import LoadImages, LoadStreams,LoadWebcam
from utils.general import apply_classifier, check_img_size, check_imshow, check_requirements, check_suffix, colorstr, \
increment_path, non_max_suppression, print_args, save_one_box, scale_coords, set_logging, \
strip_optimizer, xyxy2xywh
from utils.plots import Annotator, colors
from utils.torch_utils import load_classifier, select_device, time_sync
@torch.no_grad()
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
imgsz=640, # inference size (pixels)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave #and not source.endswith('.txt') # save inference images,不以下txt结尾
webcam = source.isnumeric() or source.lower.startswith(('rtsp://','rtmp://','http://')) or source.endswith('.txt')
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
# Load model
w = str(weights[0] if isinstance(weights, list) else weights)
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes) # check weights have acceptable suffix
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
#classify 设置二级分类,默认不适用
if pt:
model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
if classify: # second-stage classifier
modelc = load_classifier(name='resnet50', n=2) # initialize
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval()
elif onnx:
if dnn:
# check_requirements(('opencv-python>=4.5.4',))
net = cv2.dnn.readNetFromONNX(w)
else:
check_requirements(('onnx', 'onnxruntime-gpu' if torch.has_cuda else 'onnxruntime'))
import onnxruntime
session = onnxruntime.InferenceSession(w, None)
else: # TensorFlow models
check_requirements(('tensorflow>=2.4.1',))
import tensorflow as tf
if pb: # https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
def wrap_frozen_graph(gd, inputs, outputs):
x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped import
return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs),
tf.nest.map_structure(x.graph.as_graph_element, outputs))
graph_def = tf.Graph().as_graph_def()
graph_def.ParseFromString(open(w, 'rb').read())
frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0")
elif saved_model:
model = tf.keras.models.load_model(w)
elif tflite:
interpreter = tf.lite.Interpreter(model_path=w) # load TFLite model
interpreter.allocate_tensors() # allocate
input_details = interpreter.get_input_details() # inputs
output_details = interpreter.get_output_details() # outputs
int8 = input_details[0]['dtype'] == np.uint8 # is TFLite quantized uint8 model
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader,导入数据
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference,前向传播
if pt and device.type != 'cpu':
#进行一次前向推理,测试程序是否正常
model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.parameters()))) # run once
dt, seen = [0.0, 0.0, 0.0], 0
for path, img, im0s, vid_cap in dataset:
print(vid_cap)
t1 = time_sync()
if onnx:
img = img.astype('float32')
else:
#转换视频,图片格式
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
if pt:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(img, augment=augment, visualize=visualize)[0]
elif onnx:
if dnn:
net.setInput(img)
pred = torch.tensor(net.forward())
else:
pred = torch.tensor(session.run([session.get_outputs()[0].name], {session.get_inputs()[0].name: img}))
else: # tensorflow model (tflite, pb, saved_model)
imn = img.permute(0, 2, 3, 1).cpu().numpy() # image in numpy
if pb:
pred = frozen_func(x=tf.constant(imn)).numpy()
elif saved_model:
pred = model(imn, training=False).numpy()
elif tflite:
if int8:
scale, zero_point = input_details[0]['quantization']
imn = (imn / scale + zero_point).astype(np.uint8) # de-scale
interpreter.set_tensor(input_details[0]['index'], imn)
interpreter.invoke()
pred = interpreter.get_tensor(output_details[0]['index'])
if int8:
scale, zero_point = output_details[0]['quantization']
pred = (pred.astype(np.float32) - zero_point) * scale # re-scale
#矩形框
pred[..., 0] *= imgsz[1] # x
pred[..., 1] *= imgsz[0] # y
pred[..., 2] *= imgsz[1] # w
pred[..., 3] *= imgsz[0] # h
#pred[...,,4] 为objectness的置信度
#pred[....,5:-1] 为分类结果
pred = torch.tensor(pred)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
#非极大值抑制处理,pred前向传播结果
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
#判断是否进行二级分类
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process predictions
#对每一张图片进行处理
for i, det in enumerate(pred): # per image
seen += 1
#如果输入原,来自视频
if bs>=1: # batch_size >= 1
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path是,原视频或图片的路径,包含文件名
#设置保存路劲
save_path = str(save_dir / p.name) # img.jpg
# 设置保存框坐标的TXT文件路径
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
#设置打印信息的(图片的宽高)
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
#调整预测框坐标,基于resize+paid的图片坐标,此时的坐标格式为xyxy
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
#打印检测到的类别数目
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
# 保存预测的结果
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
#转换坐标信息,将xyxy转换为xywh格式,并初上w,h做归一化处理
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
#在原图上画框
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
#标签值
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Print time (inference-only)
#打印前向传播+nms的时间
print(f'{s}Done. ({t3 - t2:.3f}s)')
# Stream results
#如果设置展示,则画出图片,或视频
im0 = annotator.result()
if view_img:
# fps = vid_cap.get(cv2.CAP_PROP_FPS)
# cv2.putText(im0, 30, cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
print(str(p))
cv2.imshow(str(p), im0)
key = cv2.waitKey(1)& 0xFF # 1 millisecond
if key == ord('q'):
print(9)
break
# Save results (image with detections)
#保存图片
if save_img:
print('save')
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
print(1)
else: # 'video' or 'stream'
print(1111)
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
print(2)
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# w,h = im0.shape[1], im0.shape[0]
else: # stream
print(3)
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.avi'
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'XVID'), fps, (w,h),0)
vid_writer[i].write(im0)
if key == ord('q'):
cv2.destroyAllWindows()
break
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
print(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
# vid_writer[i]
# E:/project/yolov5/yolov5-master/dataset/images/val/IMG_20211019_173105.jpg
def parse_opt():#根据需要修改run中的参数
parser = argparse.ArgumentParser()
'''
weight:训练权重
source:测试数据,照片和视频,视频摄像头,视频流rtsp
img-size:输入图片大小
conf-thres:置信度阈值
iou-thres:做nms的 iou阈值
device:设置设备
view-img 是否展示预测后的照片和视频
save-TXT 是否将坐标框以txt文本的格式保存
save-dir 视频图片预测后的保存路径
class 设置只保留一部分类别
agnostic-nms 进行nms是否去除不同类别的框
augment 推理的时候进行多尺度,翻转等操作
update 如果为true,对所有模型进行strip—optimizer操作,去除pt文件的优化器等信息
nargs num of args
action 命令行遇到参数时的动作,action = store-true,表示有参数传入时就设置为True
'''
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / './runs/train/exp13/weights/best.pt', help='model path(s)')#权重文件
parser.add_argument('--source', type=str, default=ROOT / '0', help='file/dir/URL/glob, 0 for webcam')#修改要检测的文件类型
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
train.py
其余
详见:https://www.bilibili.com/video/BV19K4y197u8?p=36
文章出处登录后可见!