模型训练时测试集上正确率大于训练集
参考
一、问题
近日再进行Point Cloud Transformer的消融实验时,发现一个问题:模型训练时测试集上的正确率大于训练集正确率,如下图。当时觉得很神奇,这个模型能未卜先知了?
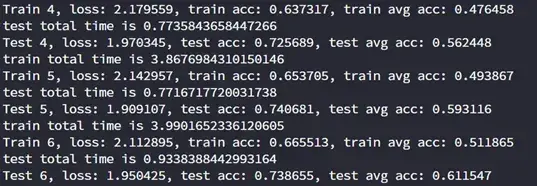
在模型训练过程中突然发现,模型的准确率在测试集上居然比在训练集上还要高。但是我们知道,我们训练模型的方式就是在训练集上最小化损失。因此,模型在训练集上有着更好的表现,才应该是正常的现象。
然后去看了看别人的讲解,大致明白了一些
二、原因
1. 数据集太小
这样会导致数据集切分的时候不均匀,也就是说训练集和测试集的分布不均匀,如果模型能够正确地捕捉到数据内部的分布模式的话,就有可能造成训练集的内部方差大于验证集,会造成训练集的误差更大,这个时候就需要重新划分数据集,使其分布一样。
2. 模型正则化过多
比如训练时Dropout过多,和验证时的模型相差较大,验证时是不会有Dropout的。Dropout能基本上确保测试集的准确性最好,优于训练集的准确性。Dropout迫使神经网络成为一个非常大的弱分类器集合,这就意味着,一个单独的分类器没有太高的分类准确性,只有当把他们串在一起的时候他们才会变得更强大。而且在训练期间,Dropout将这些分类器的随机集合切掉,因此,训练准确率将受到影响;在测试期间,Dropout将自动关闭,并允许使用神经网络中的所有弱分类器,因此,测试精度提高。
3. 小批量统计的滞后性
训练集的准确率是每个batch之后产生的,而验证集的准确率一般是一个epoch后产生的,验证时的模型是训练一个个batch之后的,有一个滞后性,可以说就是用训练得差不多的模型用来验证,当然准确率要高一点。
4.数据预处理
训练集的数据做了一系列的预处理,如旋转、仿射、模糊、添加噪点等操作,过多的预处理导致训练集的分布产生了变化,所以使得训练集的准确率低于验证集
5. 欠拟合
前几次一直在欠拟合,随着训练周期的增加,在训练集上的准确率又超过了测试集上的。
三、测试
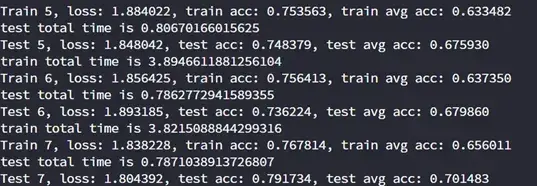
我将模型中的Dropout去掉之后,两个正确率相差明显下降了
文章出处登录后可见!