项目简介
- YOLOv5 + StrongSORT with OSNet:YOLOv5检测器 + StrongSORT跟踪算法 + OSNet行人重识别模型
- 项目地址:https://github.com/mikel-brostrom/Yolov5_StrongSORT_OSNet
环境安装
1.Conda建立虚拟环境
conda create -n yolov5 python=3.8
2.安装PyTroch和TorchVision
本文Pytorch安装的版本为1.8.0,torchvision对应的版本为0.9.0
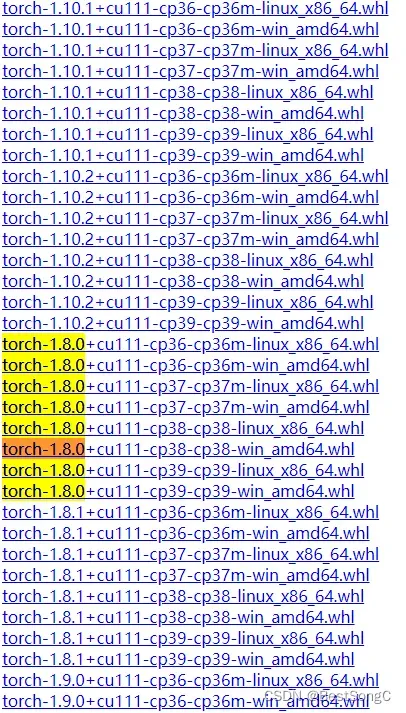
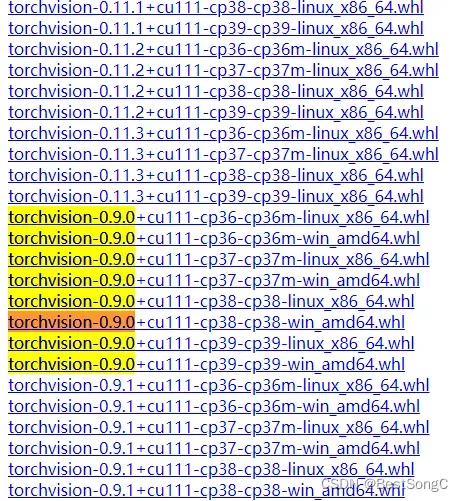
注意:cp对应Python包版本,linux对应lLinux版本,win对应Windows版本
当whl文件下载到本地后,进入包下载命令,使用pip install 包名来安装:
pip install torch-1.8.0+cu111-cp38-cp38-win_amd64.whl
pip install torchvision-0.9.0+cu111-cp38-cp38-win_amd64.whl
3.安装Torchreid
# cd to your preferred directory and clone this repo
git clone https://github.com/KaiyangZhou/deep-person-reid.git
# create environment
cd deep-person-reid/
# 环境上面已建立,使用yolov5虚拟环境
# conda create --name torchreid python=3.7
# conda activate torchreid
# install dependencies
# make sure `which python` and `which pip` point to the correct path
pip install -r requirements.txt
# install torch and torchvision (select the proper cuda version to suit your machine)
# conda install pytorch torchvision cudatoolkit=9.0 -c pytorch
# install torchreid (don't need to re-build it if you modify the source code)
python setup.py develop
pip install -r requirements.txt本地安装记录:
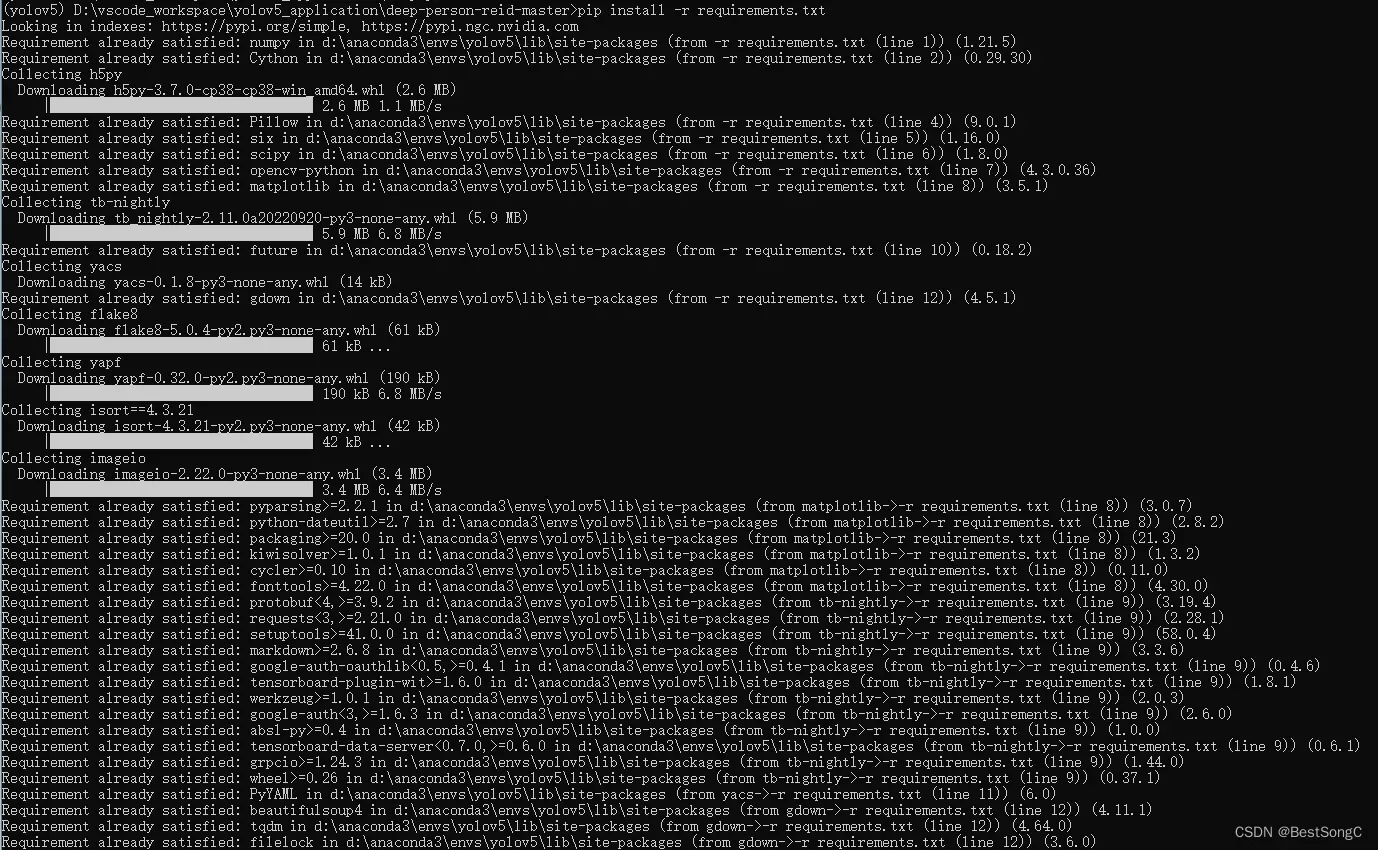
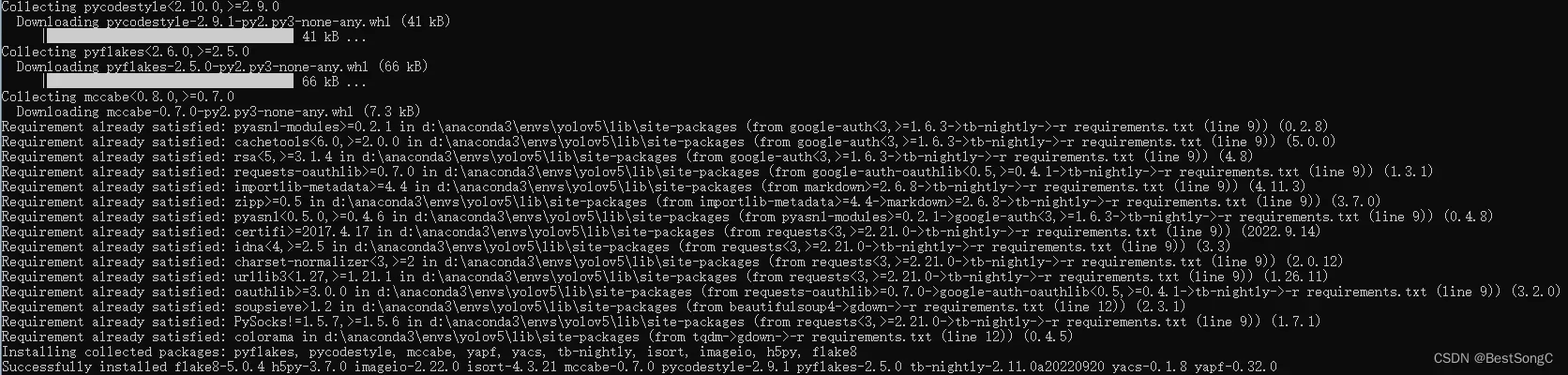
最后执行python setup.py develop,一顿操作后得到下面的提示:
输入conda list确定本机基本环境:
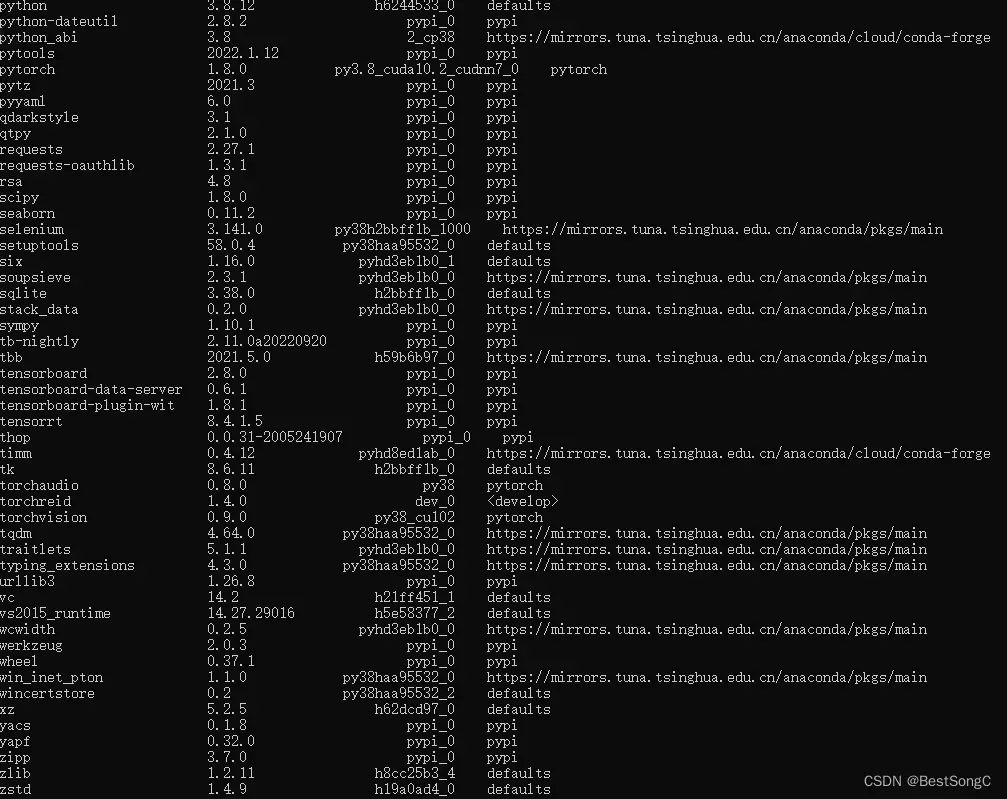
python:3.8
pytorch:1.8.0
torchvision:0.9.0
torchreid:1.4.0
注:本环境下的一些包安装这个是没有的,这些是之前安装另一个项目留下的(主要是一些导出包)
4.安装项目其他依赖包
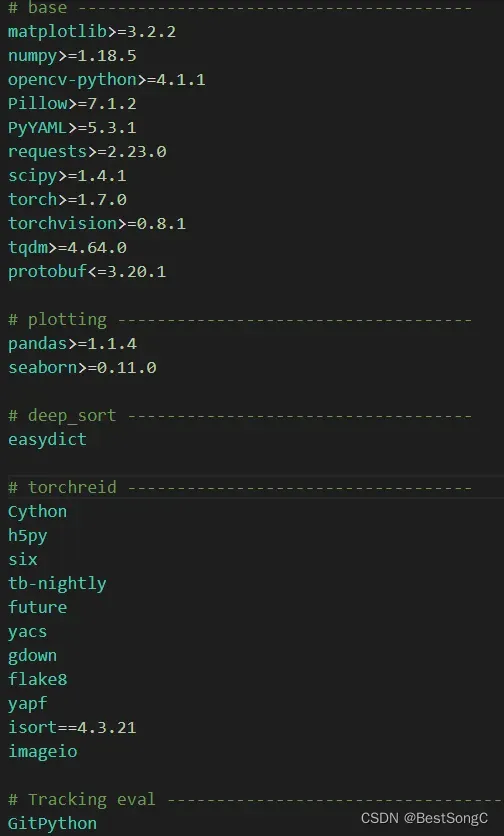
Bug解决
问题描述:在下载源码是选择Download Zip这种方式,默认yolov5文件夹下内容是空的,此时需要点击编号(yolov5@91a81d4)下载yolov5源码放在yolov5目录下
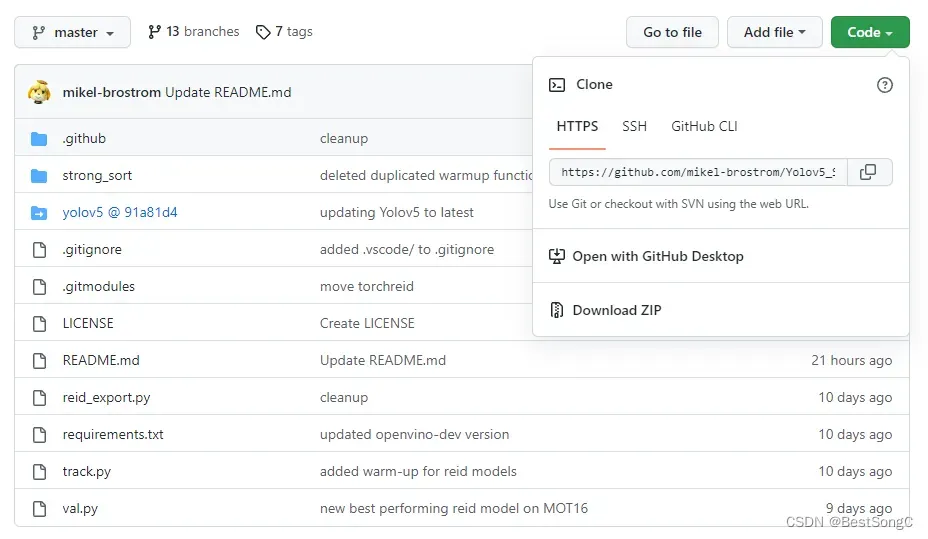
但在我运行python track.py 时程序依然报错:

这是因为在strong_sort/deep/reid目录是空的,下载源码默认是没下载那部分内容的,因此需要和上面一下,将torchreid下载并放入到strong_sort/deep/reid下面
代码运行
python track.py
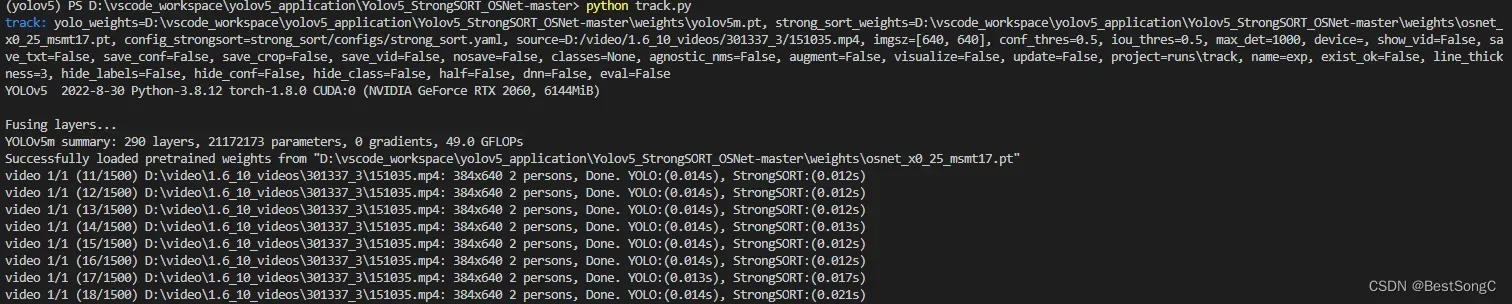

- 默认结果保存在runs/track/exp目录下,之前跑过一次没成功,所以这次结果保存在runs/track/exp2目录下
- 如果使用python track.py运行的话默认是不保存视频的,只能在控制台查看输出结果,如果保存视频,需指定–save-vid参数,使用命令python track.py –save-vid即可
参数解析
track.py
parser.add_argument('--yolo-weights', nargs='+', type=Path, default=WEIGHTS / 'yolov5m.pt', help='model.pt path(s)')
parser.add_argument('--strong-sort-weights', type=Path, default=WEIGHTS / 'osnet_x0_25_msmt17.pt')
parser.add_argument('--config-strongsort', type=str, default='strong_sort/configs/strong_sort.yaml')
parser.add_argument('--source', type=str, default='D:/video/1.6_10_videos/301337_3/151035.mp4', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.5, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--show-vid', action='store_true', help='display tracking video results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--save-vid', action='store_true', help='save video tracking results')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
# class 0 is person, 1 is bycicle, 2 is car... 79 is oven
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/track', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--hide-class', default=False, action='store_true', help='hide IDs')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--eval', action='store_true', help='run evaluation')
- –yolo-weights:YOLO得到的权重模型
- –strong-sort-weights:Reid模型
- –show-vid:python track.py –show-vid:可视化跟踪结果
- –save-vid:python track.py –save-vid:保存跟踪结果
- –classes:指定类别检测跟踪
彩蛋
本文对构建YOLOAir库环境进行详细阐述,笔者以后会定期分享关于项目的其他模块和相关技术,笔者也建立了一个关于目标检测的交流群:781334731,欢迎大家踊跃加入,一起学习鸭!
笔者也持续更新一个微信公众号:Nuist计算机视觉与模式识别,大家帮忙点个关注谢谢
文章出处登录后可见!
已经登录?立即刷新