AC算法
我们之前讲过基于价值的强化学习,我们也讲过基于策略的强化学习,这节课所讲的AC系列算法就是同时使用了这两种方法包含有:AC——Actor Critic、A2C——Advantage Actor Critic、A3C——Asynchronous Advantage Actor Critic。
AC
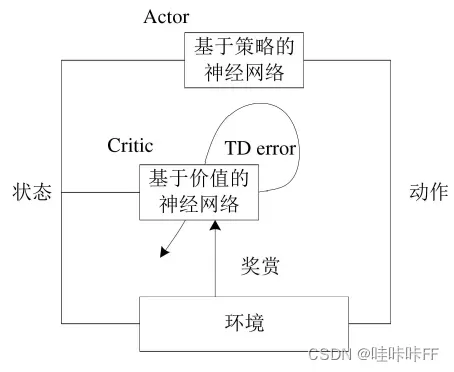
Actor-Critic算法分为两部分,Actor用的是policy gradient,它可以在连续动作空间内选择合适的动作,Critic用的是Q-learning,它可以解决离散动作空间的问题。除了这个,又因为Actor只能在一个回合之后进行更新,导致学习效率较慢,Critic的加入就可以使用TD方法实现单步更新。这样两种算法相辅相成就形成了我们的Actor-Critic。
Actor输出每个Action的概率,有多少个Action就有多少个输出。Critic 基于 Actor 输出的行为评判得分, Actor 再根据 Critic 的评分修改选行为的概率。这是两个神经网络。因此策略梯度可以写成:
公式里的π指的就是Actor的策略,指的就是Critic,评估Actor策略的好坏,它可以表示成很多种形式:
(1):一个轨迹中的Reward相加;
(2):动作后的Reward(从该动作往后算,可以看成前期的对后面没有影响);
(3):动作后的总汇报相加后的Reward减去一个baseline;
(4):用行为价值函数Q计算;
(5):用优势函数A计算;
(6):用TD-error,计算新的状态价值减去原本的状态价值;
前三个都是直接应用轨迹的回报累计回报,这样计算出来的策略梯度不会存在偏差,但是因为需要累计多步的回报,所以方差会很大。
后三个是利用动作价值函数,优势函数和TD偏差代替累计回报,其优点是方差小,但是三种方法中都用到了逼近方法,因此计算出来的策略梯度都存在偏差。这三种方法是以牺牲偏差来换取小的方差。
算法结构图如下:
A2C
A2C即Advantage Actor-Critic此算法的出现是为了应对AC方法高方差的问题,为什么会有这个问题呢,是因为一个动作轨迹中假如所有的动作回报都为正的这并不代表所有动作都是好的,他可能只是个次优的动作。因此我们采用引入基线的方式来解决这个问题,基线函数的特点是能在不改变策略梯度的同时降低其方差。这里的基线baseline一般由来代替,原来的Q值就变成了:
A3C
A3C即Asynchronous Advantage Actor Critic,在讲DQN算法时我们讲过神经网络训练时,需要的数据是独立同分布的,否则Agent很容易学习到一种固定的策略,DQN采用的是经验回放机制解决这个问题的,但这种机制存在两个问题:
(1)Agent每次交互的时候都需要更多的内存和计算;
(2)经验回放机制要求 Agent 采用离策略(off-policy)方法来进行学习,而同样的条件下,离线策略算法不如在线策略算法稳定;
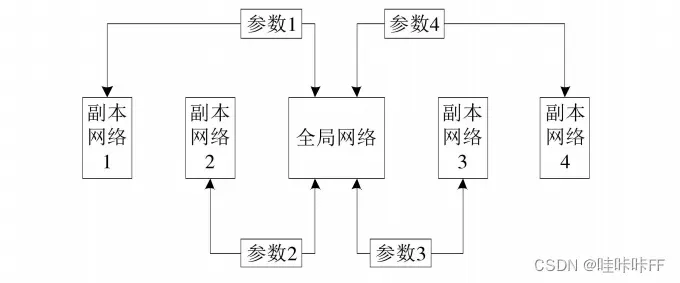
打破数据的相关性,经历回放并非是唯一方法。另一种为异步的方法,通过在多个环境实例中并行地执行多个智能体,由于探索的随机性,所以产生的数据是各不相同的。并行的交互采样和训练。在异步方法中,同时启动多个线程,智能体将在多个线程中同时进行环境交互。
A3C算法就是采用多线程进行训练,采用几个独立的副本网络去单独学习训练,然后将学到的神经网络参数上传到全局的网络,全局的网络再适时的将最新的参数分发给各个副本网络,使其拥有最新的知识。通过多个副本独立训练打破了数据的相关性。A3C网络结构如图:
文章出处登录后可见!