网络爬虫——BeautifulSoup详讲与实战
前言: 📝📝此专栏文章是专门针对网络爬虫基础,欢迎免费订阅!
📝📝第一篇文章《1.认识网络爬虫》获得全站热搜第一,python领域热搜第一, 第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热搜第八,欢迎阅读! 🎈🎈欢迎大家一起学习,一起成长!!
💕💕:悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。

BeautifulSoup简介:
- Beautiful Soup 简称 BS4(其中 4
表示版本号)BeautifulSoup是一个Python库,用于从HTML和XML文件中提取数据。它提供了一些简单的方式来遍历文档树和搜索文档树中的特定元素。 - BeautifulSoup可以解析HTML和XML文档,并将其转换为Python对象,使得我们可以使用Python的操作来进行数据提取和处理。它还可以处理不完整或有误的标记,并使得标记更加容易阅读。
- BeautifulSoup是一个流行的Web爬虫工具,被广泛应用于数据抓取、数据清洗和数据分析等领域。
BS4下载安装
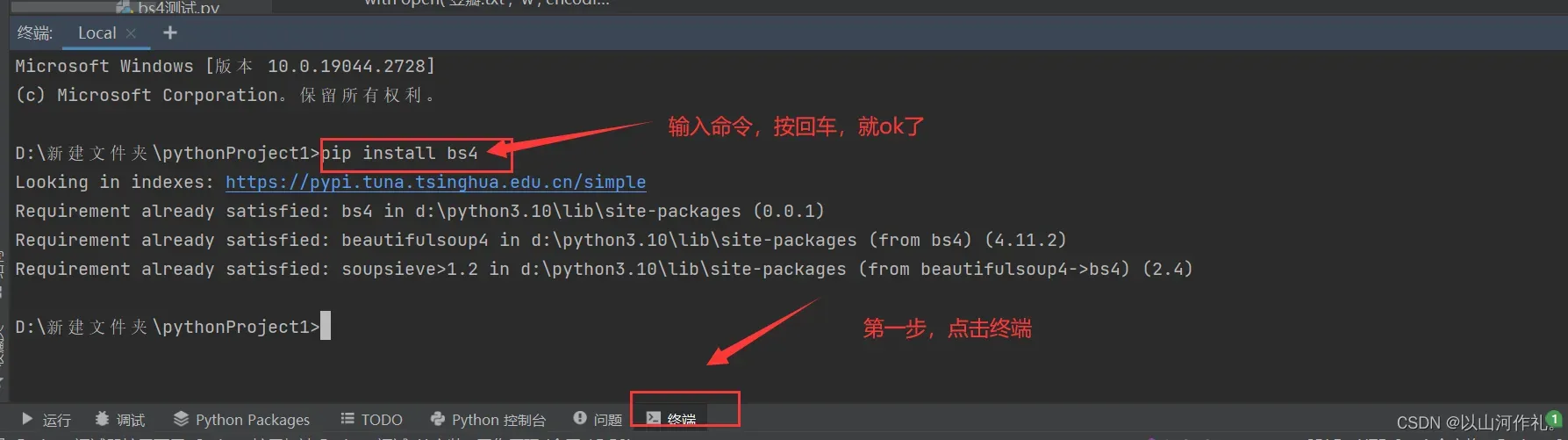
由于 Bautiful Soup 是第三方库,因此需要单独下载,下载方式非常简单,执行以下命令即可安装:
pip install bs4
BS4解析对象
BeautifulSoup4(BS4)对象是BeautifulSoup库解析HTML或XML文档并创建的Python对象。它是一个树形结构,其中包含了文档中的节点,例如标签、字符串和注释。BS4对象可以解析HTML和XML文档,并提供了许多方法来完成对节点的查找、筛选和修改的操作。
例如,可以使用
.find()方法查找包含特定文本的标签,使用.select()方法根据CSS选择器选择元素,使用.text
属性获取标签的文本内容等等。所有这些方法都是BS4对象中提供的。
创建 BS4 解析对象是万事开头的第一步,这非常地简单,语法格式如下所示:
#导入解析包
from bs4 import BeautifulSoup
#创建beautifulsoup解析对象
soup = BeautifulSoup(html_doc, 'html.parser') # html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 'lxml' 或者 'html5lib'
#prettify()用于格式化输出html/xml文档
print(soup.prettify())
完整代码:
# 导入解析包
from bs4 import BeautifulSoup
import requests
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
# 创建beautifulsoup解析对象
soup = BeautifulSoup(html.text,
'html.parser') # html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 'lxml' 或者 'html5lib'
# prettify()用于格式化输出html/xml文档
print(soup.prettify())
这段代码使用了Python中的BeautifulSoup库和requests库,对指定网页进行了请求并用BeautifulSoup解析了返回的HTML文档。最后使用prettify()方法格式化输出解析后的文档。
运行结果:
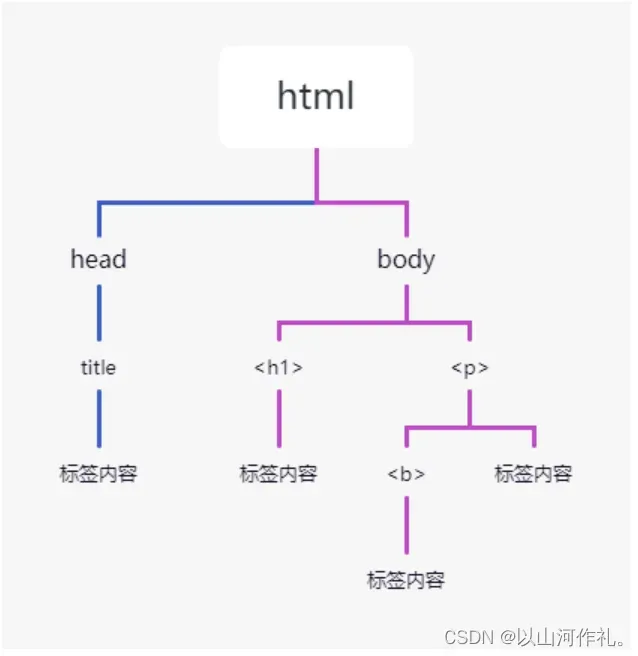
Beautiful Soup 将 HTML 文档转换成一个树形结构,该结构有利于快速地遍历和搜索 HTML 文档。下面使用树状结构来描述一段 HTML 文档:
<html>
<head>
<title>中文</title>
</head>
<body>
<h1>net</h1>
<p>
<b>编程</b>
</p>
</body>
</html>
树状图如下所示:
文档树中的每个节点都是 Python 对象,这些对象大致分为四类:Tag , NavigableString , BeautifulSoup
, Comment 。其中使用最多的是 Tag 和 NavigableString。
- Tag:标签类,HTML 文档中所有的标签都可以看做 Tag 对象。
- NavigableString:字符串类,指的是标签中的文本内容,使用 text、string、strings 来获取文本内容。
- BeautifulSoup:表示一个 HTML 文档的全部内容,您可以把它当作一个人特殊的 Tag 对象。
- Comment:表示 HTML 文档中的注释内容以及特殊字符串,它是一个特殊的 NavigableString 。
Tag节点
标签(Tag)是组成 HTML 文档的基本元素。在 BS4 中,通过标签名和标签属性可以提取出想要的内容。看一组简单的示例
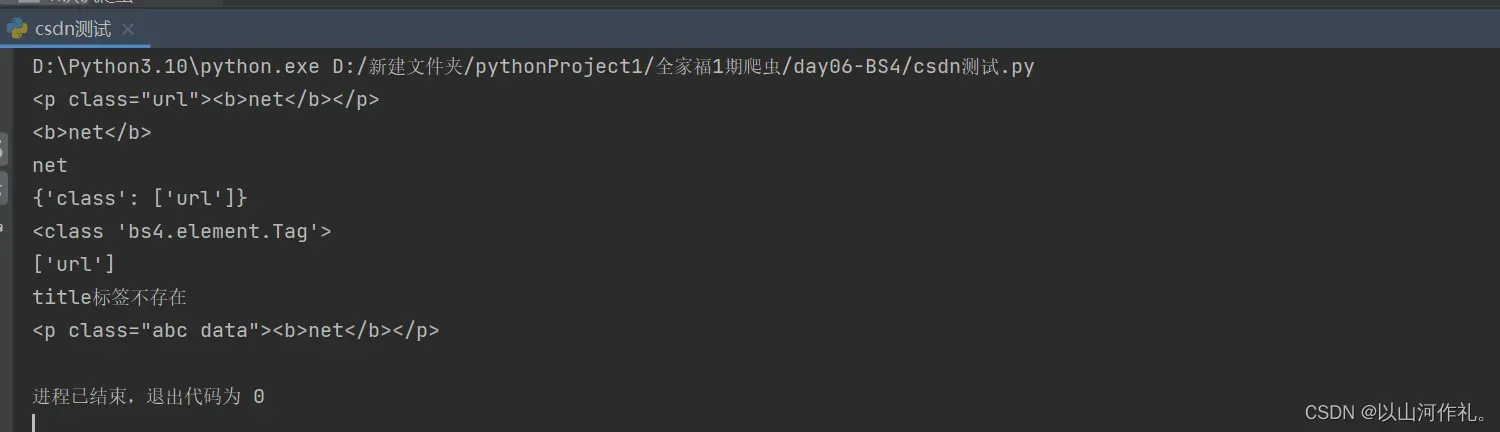
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p class="url"><b>net</b></p>', 'html.parser')
# 获取第一个p标签的html代码
print(soup.p)
# 获取b标签
print(soup.p.b)
# 获取p标签内容,使用NavigableString类中的string、text、get_text()
print(soup.p.text)
# 返回一个字典,里面是多有属性和值
print(soup.p.attrs)
# 查看返回的数据类型
print(type(soup.p))
# 根据属性,获取标签的属性值,返回值为列表 不存在就报错
print(soup.p['class'])
# 获取具体属性 获取最近的第一个属性 不存在就返回None
if soup.title:
print(soup.title.get('class'))
else:
print('title标签不存在')
# 给class属性赋值,此时属性值由列表转换为字符串
soup.p['class'] = ['abc', 'data']
print(soup.p)
遍历节点
Tag 对象提供了许多遍历 tag 节点的属性,比如 contents、children 用来遍历子节点;parent 与 parents 用来遍历父节点;示例如下:
from bs4 import BeautifulSoup
import requests
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'html.parser')
# 查找第一个符合条件的标签
print(soup.find('span', class_='year'))
# 查找所有符合条件的标签
for item in soup.find_all('span', class_='rating_num'):
print(item.text)
# 使用CSS选择器查找标签
print(soup.select('#content > h1 > span:nth-child(1)'))
# 遍历所有文本内容
for string in soup.stripped_strings:
print(string)

上述代码中,我们首先使用requests库获取了指定网页的HTML文档,然后使用BeautifulSoup库解析HTML文档,并使用不同的方法遍历了节点,包括:
-
使用find()方法查找第一个符合条件的标签,其中class_参数用于指定class属性的值。
-
使用find_all()方法查找所有符合条件的标签,返回一个列表。
-
使用select()方法使用CSS选择器查找标签,返回一个列表。
-
使用stripped_strings属性遍历所有文本内容,返回一个生成器。需要注意的是,stripped_strings返回的是去除空白字符后的文本内容。
find_all()与find()
find_all()与find()都是BeautifulSoup对象的方法,用于在HTML文档中查找符合条件的标签。
find_all()
find_all():返回所有符合条件的标签,结果是一个列表。如果没有符合条件的标签,则返回空列表。
find_all()是BeautifulSoup对象的方法,用于在HTML文档中查找符合条件的标签。
该方法的语法格式为:soup.find_all(name, attrs, recursive, string, limit,
**kwargs),其中各参数的含义如下:
- name:标签名。可以传入一个标签名的字符串,如’a’、’div’等,也可以传入一个列表,如[‘a’,
‘div’],表示查找多个标签名的标签。如果不指定该参数,则返回所有标签。 - attrs:标签属性。可以传入一个字典,其中键表示属性名,值表示属性值,如{‘class’:
‘movie’},表示查找class属性值为’movie’的标签。也可以传入一个字符串,如’class=“movie”’,表示查找class属性值为’movie’的标签。默认值为None。 - recursive:是否递归查找。默认值为True,表示递归查找所有子孙节点;如果设置为False,则只查找直接子节点。
- string:文本内容。可以传入一个字符串,表示查找指定文本内容的标签。
- limit:结果数量。可以传入一个整数,表示最多返回的结果数量。默认值为None,表示返回所有结果。
- **kwargs:其他属性。可以传入其他属性,如id、class等,表示查找具有指定属性的标签。
下面是一个示例代码,演示如何使用find_all()方法查找符合条件的标签:
from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>电影列表</title>
</head>
<body>
<h1>电影列表</h1>
<div class="movie">
<h2>黑白迷宫</h2>
<p>导演:张艺谋</p>
<p>主演:李连杰、章子怡</p>
<p>评分:<span class="rating">8.9</span></p>
</div>
<div class="movie">
<h2>西游记之大圣归来</h2>
<p>导演:田晓鹏</p>
<p>主演:张磊、石磊、杨晓婧</p>
<p>评分:<span class="rating">9.2</span></p>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 查找所有div标签
div_list = soup.find_all('div')
print(div_list)
# 查找class属性值为"movie"的div标签
movie_list = soup.find_all('div', class_='movie')
print(movie_list)
# 查找评分大于9.0的电影
rating_list = soup.find_all('span', class_='rating', string=lambda x: float(x) > 9.0)
print(rating_list)
# 查找第一个电影的导演名
director = soup.find('div', class_='movie').find('p').next_sibling.string
print(director)
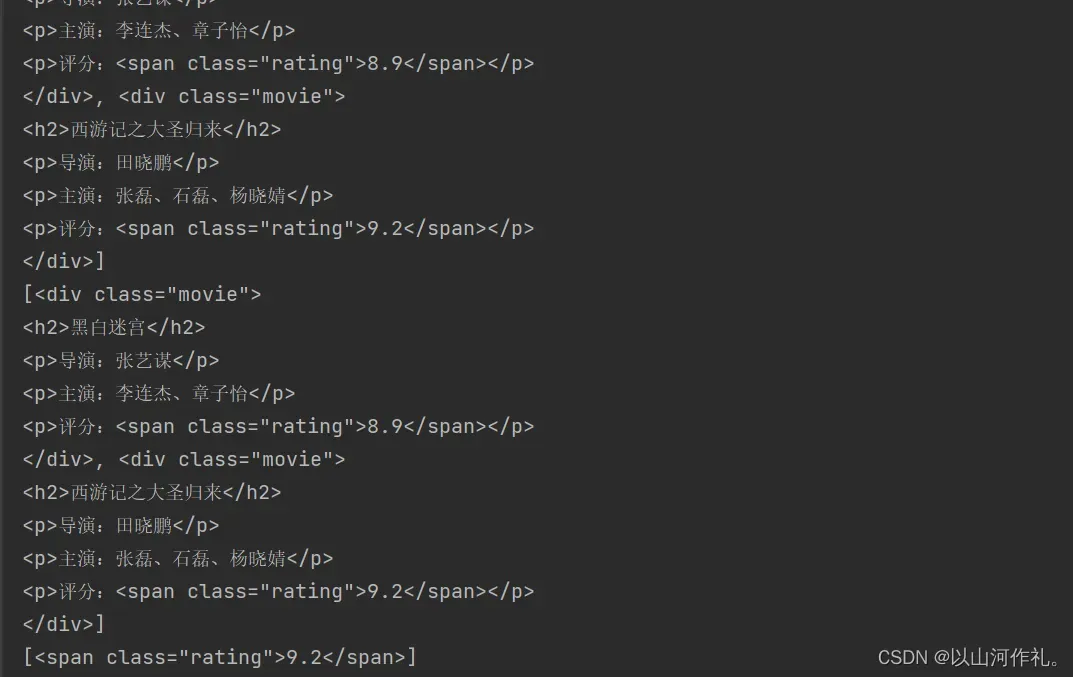
上述代码中,我们首先定义了一个HTML文档字符串,然后使用BeautifulSoup库解析HTML文档,并使用find_all()方法查找了符合条件的标签。
具体来说:
- 使用
find_all('div')方法查找所有div标签,并将结果存储在div_list列表中。 - 使用
find_all('div',class_='movie')方法查找所有class属性值为”movie”的div标签,并将结果存储在movie_list列表中。 - 使用
find_all('span', class_='rating', string=lambda x: float(x) > 9.0)方法查找所有class属性值为”rating”且文本内容大于9.0的span标签,并将结果存储在rating_list列表中。注意这里使用了lambda表达式作为string参数的值,表示只返回文本内容大于9.0的标签。 - 使用
find('div',class_='movie').find('p').next_sibling.string方法查找第一个class属性值为”movie”的div标签中第一个p标签的下一个兄弟节点的文本内容,即导演名。需要注意的是,next_sibling属性返回下一个兄弟节点,可能是空白字符节点,因此需要使用string属性获取文本内容。
find()
find():返回第一个符合条件的标签,结果是一个Tag对象。如果没有符合条件的标签,则返回None。
find()是BeautifulSoup对象的方法,用于在HTML文档中查找第一个符合条件的标签。
该方法的语法格式为:soup.find(name, attrs, recursive, string,
**kwargs),其中各参数的含义与find_all()方法相同。与find_all()方法不同的是,find()只返回第一个符合条件的标签,并且返回的是一个Tag对象,而不是一个列表。如果没有找到符合条件的标签,则返回None。
下面是一个示例代码,演示如何使用find()方法查找符合条件的标签:
from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>电影列表</title>
</head>
<body>
<h1>电影列表</h1>
<div class="movie">
<h2>黑白迷宫</h2>
<p>导演:张艺谋</p>
<p>主演:李连杰、章子怡</p>
<p>评分:<span class="rating">8.9</span></p>
</div>
<div class="movie">
<h2>西游记之大圣归来</h2>
<p>导演:田晓鹏</p>
<p>主演:张磊、石磊、杨晓婧</p>
<p>评分:<span class="rating">9.2</span></p>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 查找第一个div标签
div = soup.find('div')
print(div)
# 查找class属性值为"movie"的第一个div标签
movie = soup.find('div', class_='movie')
print(movie)
# 查找评分大于9.0的第一个电影
rating = soup.find('span', class_='rating', string=lambda x: float(x) > 9.0)
print(rating)
# 查找第一个电影的导演名
director = soup.find('div', class_='movie').find('p').next_sibling.string
print(director)
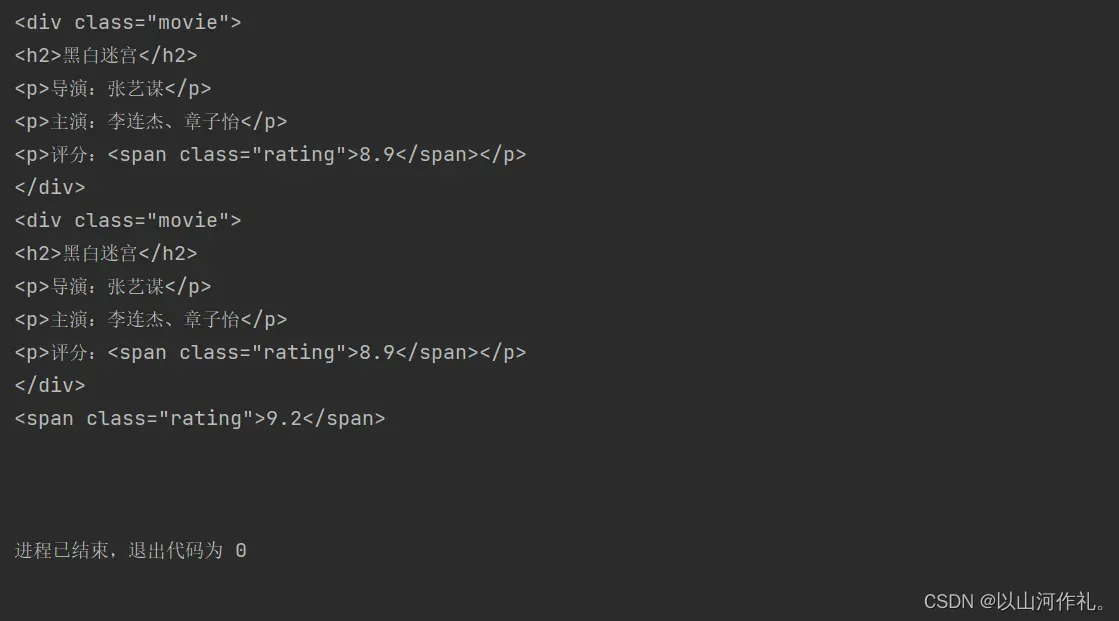
上述代码中,我们使用find()方法查找了符合条件的标签,并返回了一个Tag对象。
具体来说:
- 使用
find('div')方法查找第一个div标签,并将结果存储在div变量中。 - 使用
find('div', class_='movie')方法查找第一个class属性值为”movie”的div标签,并将结果存储在movie变量中。 - 使用
find('span', class_='rating', string=lambda x: float(x) > 9.0)方法查找class属性值为”rating”且文本内容大于9.0的第一个span标签,并将结果存储在rating变量中。注意这里使用了lambda表达式作为string参数的值,表示只返回文本内容大于9.0的标签。 - 使用
find('div',class_='movie').find('p').next_sibling.string方法查找第一个class属性值为”movie”的div标签中第一个p标签的下一个兄弟节点的文本内容,即导演名。
豆瓣电影实战
本次实战目的是获取方框内内容,使用学过的bs4来操作
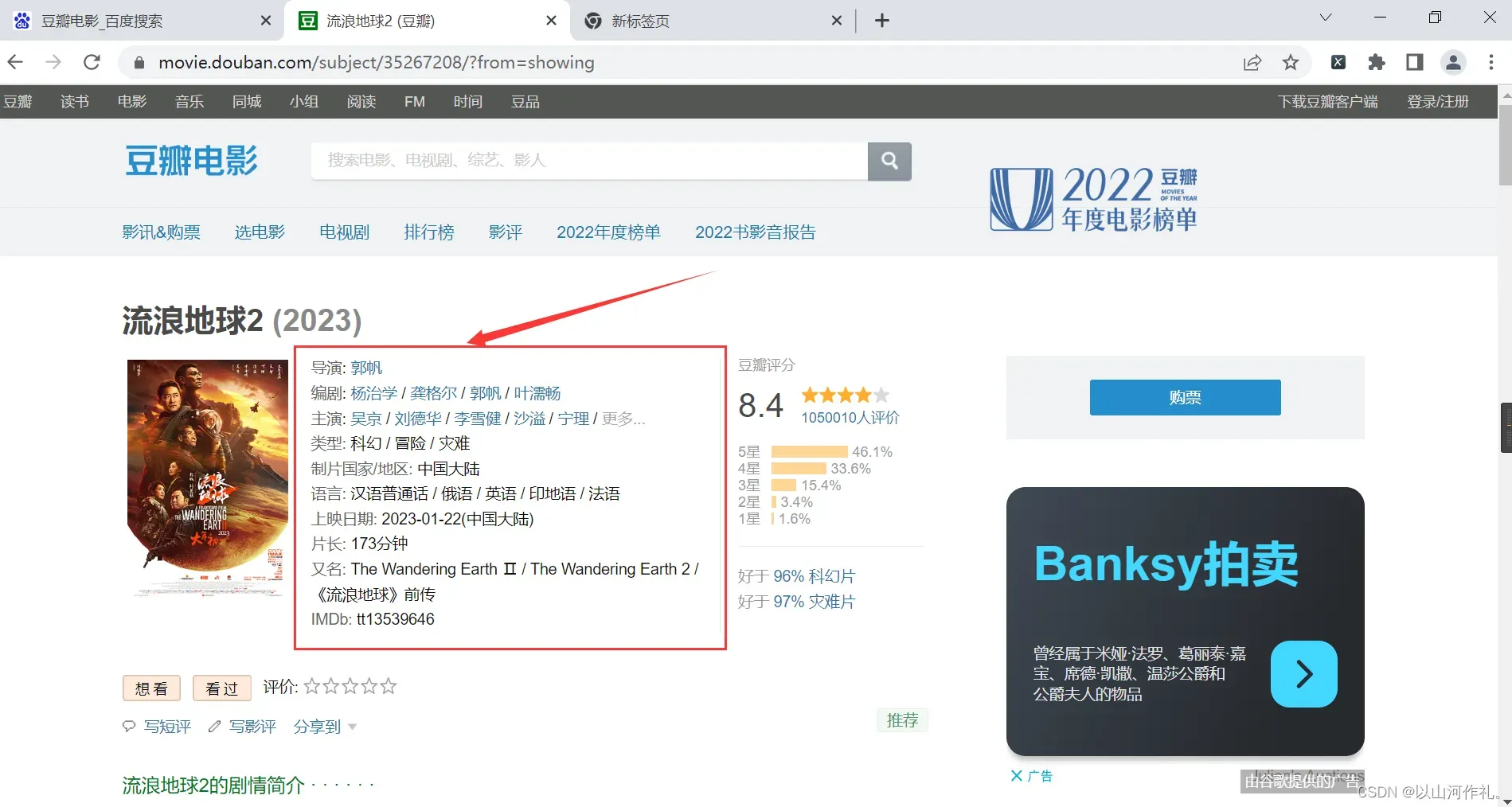
首先点击检查,鼠标附魔,查看数据是否在代码中。
通过附魔后,查看代码,发现数据在代码中,接下来我们通过get请求获取网页全部代码:
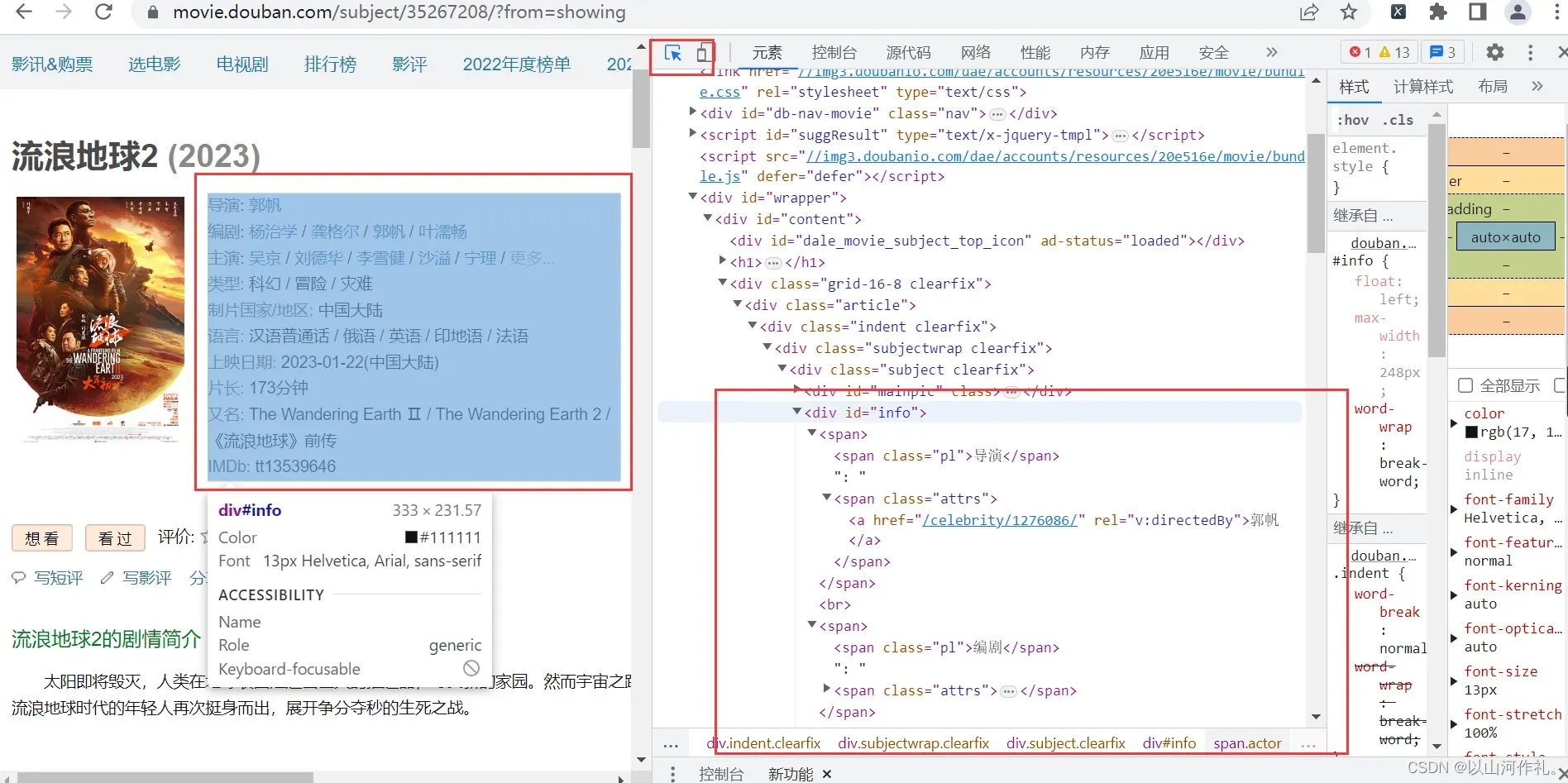
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
print(html.text)
接下来使用BS4来解析数据,并把它提取出来,放在txt文件夹里面。
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
print(html.text)
data = BeautifulSoup(html.text, 'lxml') # 第一个参数是要解析的html文本,第二个参数是使用那种解析器
obj = data.find(id="info")
print(obj.get_text())
with open('豆瓣.txt', 'w', encoding='utf-8') as f:
f.write(obj.get_text())

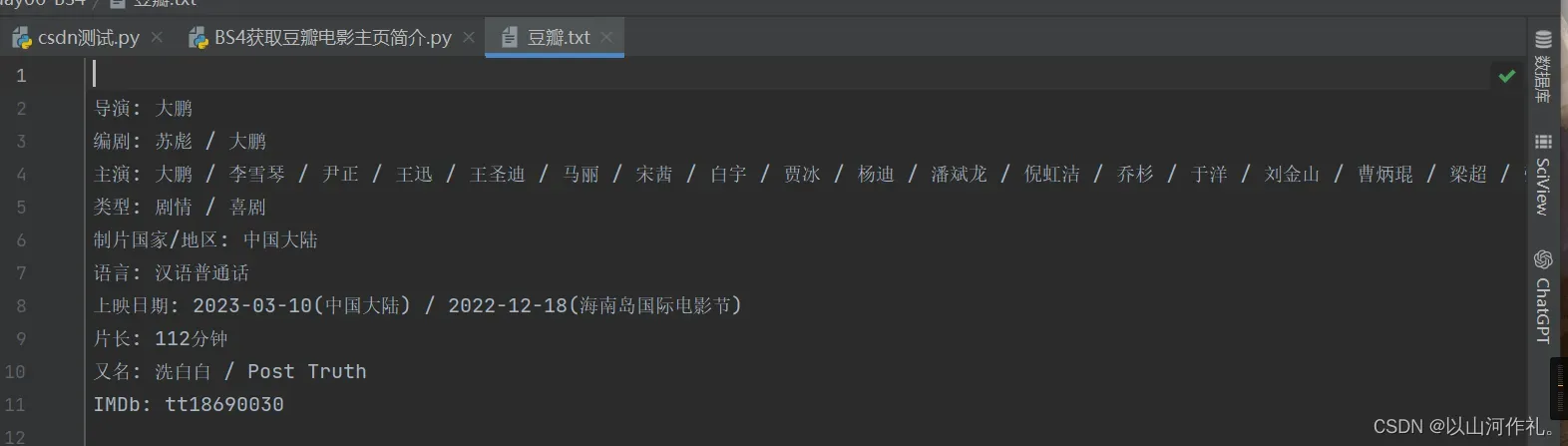
任务完成!!!

🍁 🍁今日学习笔记到此结束,感谢你的阅读,如有疑问或者问题欢迎私信,我会帮忙解决,如果没有回,那我就是在教室上课,抱歉。
🍂🍂🍂🍂
文章出处登录后可见!