sort_index和sort_values既是Series类型数据自带的方法,也是DataFrame数据自带的方法。本篇博客以DataFrame为例进行讲述。
1 概览
sort_index和sort_values可以将DataFrame中的数据按照索引及值的大小进行排序。这两个方法所包含的参数及其作用都基本一致。如下表所示:
| 参数 | 作用 |
|---|---|
| by | sort_values方法独有的参数;指定排序列名或索引; |
| level | sort_index方法独有的参数;指定排序索引所在的层级; |
| axis | 指定排序的轴; |
| ascending | 升序(True)或者降序(False); |
| inplace | 是否本地置换,参考博客:Pandas和Numpy:常见函数参数inplace的作用_Sun_Sherry的博客-CSDN博客_inplace函数 |
| kind | 指定排序算法:’quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’; |
| na_position | 指定空值数据放置的位置:’first’、’last’; |
| ignore_index | 是否重新生成索引;新索引为0,1,……, |
| key | 自定义排序方法; |
| sort_remaining | sort_index方法独有的参数;目前作用还不太明白 |
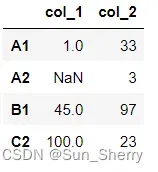
为了方便说明,先创建如下DataFrame变量:
import pandas as pd
data=pd.DataFrame([[1,33],[None,3],[45,97],[100,23]],
columns=['col_1','col_2'],
index=['A1','A2','B1','C2'])其结果如下:
1.1 sort_index用法
顾名思义,sort_index可以将DataFrame按照索引的大小顺序重新排列。其用法如下:
data_1=data.sort_index(ascending=False,ignore_index=True)其结果如下:
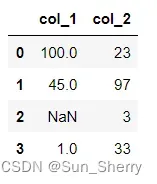
先将data按其索引的逆序排序重新进行排列,逆序排列后的索引顺序为:C2->B1->A2->A1,并抛弃原有的索引(因为设置了ignore_index参数)即可得到上述结果。
1.2 sort_values用法
同样,sort_values可以将DataFrame按指定值的大小顺序重新排列,其用法如下:
data_2=data.sort_values(by='col_2',ascending=False,na_position='first',axis=0)
#按对应值与7运算余数大小来排列
data_3=data.sort_values(by='col_2',,ascending=False,key=lambda x:x%7) 其结果如下:
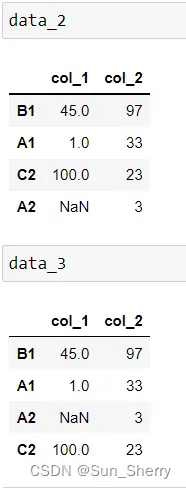
这里有以下几点需要说明:
- data_2中的na_position指定的是排序列(本例中为col_2)中的空值对应的数据的存放位置,对其他列中的空值不施加任何影响;
- data_3的排序结果说明:col_2列中的每个值进行key中指定的操作得到:key(97)=6, key(33)=5, key(3)=3, key(23)=2。然后按照这个大小顺序进行排列。
- 要注意自定义排序方法key中匿名函数的写法。该匿名函数中x对应的是DataFrame中指定排序列中的每一个具体元素,比如97,33等;
2 其他参数用法
第1部分介绍了sort_index和sort_values的主要参数及其常规用法。这一部分主要介绍其他参数的用法。
2.1 level:使用某一层级的索引来排序
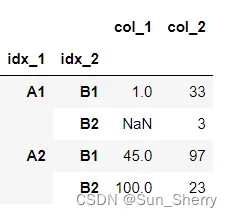
当DataFrame中的索引为复合索引(MultiIndex)时,需要按照某个指定层级的索引对DataFrame进行排序时,可以通过设置level来实现。先使用如下代码修改data的索引:
data.index=pd.MultiIndex.from_product([['A1','A2'],['B1','B2']],names=['idx_1','idx_2'])修改后的data结果如下:
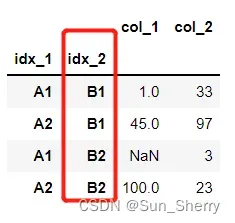
当需要使用idx_2对应的索引对DataFrame进行排序时,可以使用参数level。具体如下:
data_4=data.sort_index(level=1) #也可以写作level='idx_2'data_4结果如下:
2.2 axis轴
为了方便后续说明,先构建如下数据:
import pandas as pd
import numpy as np
data=pd.DataFrame(np.random.randint(10,100,size=(6,6)),
columns=pd.MultiIndex.from_product([['col_1','col_2'],['C1','C2','C3']],
names=['L_CF','L_CS']),
index=pd.MultiIndex.from_product([['idx_1','idx_2'],['R1','R2','R3']],
names=['L_IF','L_IS']))data结果如下:

2.2.1 set_index中的axis
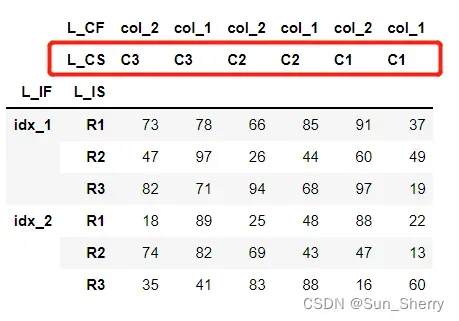
当set_index中的参数axis=1时,可以将DataFrame中的列按照其列名的大小顺序重新进行排列。具体如下:
data_5=data.sort_index(axis=1,ascending=False,level=1)其结果如下(图中红框中的即为进行排序操作的值,level=1):
2.2.2 set_values中的axis
set_values方法中的axis情况需要分别讨论。具体如下:
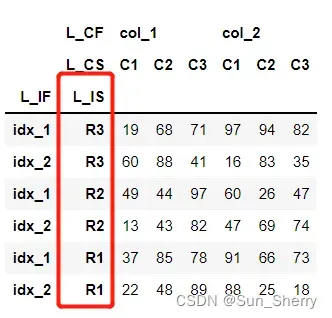
- axis=0中可以将DataFrame按索引的大小顺序重新对数据进行排列。
data_6=data.sort_values(axis=0,by='L_IS',ascending=False)其结果如下:
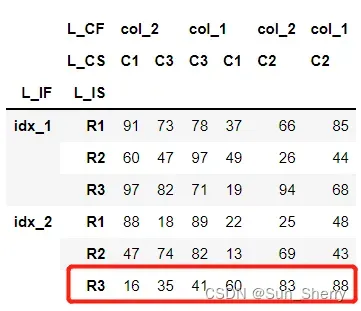
- 当axis=1时可以将DataFrame按指定某一行的元素大小进行重排。
data_7=data.sort_values(axis=1,by=[('idx_2','R3')])
其结果如下(此时by中要写入排序行的索引):
2.2.3 总结
关于set_index和sort_values中的axis轴参数引发的一些思考,总结如下:
- 关于index:以前关于DataFrame中的index只是片面地认为就是行索引,但是DataFrame的列名也可以被称为索引。比如data的定义中其二级列明的定义使用的仍然时pd.MultiIndex方法。同样,对于value也是类似。
文章出处登录后可见!