一 、前言
yoloV7已经开源有一段时间了,近期已经基于yoloV7-pose的关键点算法进行了研究和修改。目前已经将该工程修改为,多分类+任意数量关键点:修改详细请看博客:基于yoloV7-pose添加任意关键点 + 多类别分类网络修改,修改代码已经开源:github地址,如果对大家有帮助也希望可以帮忙点点☆☆。
好的,接下来我们就开始训练模型。
二 、 数据准备
2.1 数据介绍。
很多小伙伴有点不知道这些关键点怎么设置,我简单说一下逻辑,一般是检测框+关键点的形式,也就是说关键点是伴随框的,首先是希望box框可以收敛,然后再是点的收敛,所以框是必须的,然后点是非必须的,所有有些框可以不需要设置关键点,这里大家可以将关键点的值设置为-1就行,
这种关键点的标记工具可以选择labelme,对目标进行不规则四边形标记。
标记完成后图像可视化应该是这样的:

其中 第一个点是:绿色;第二个点是:蓝色;第三个点是:红色;第四个点是:白色。点的顺序是否需要有标准,我个人觉得是需要的,部分任务可能不需要,但目前我发现都是需要注意点的顺序的。
标记完成的内容,依次转化成txt文档:
# -nfs-阿拉伯车牌字符-沙特阿拉伯卡口车牌-2-沙特阿拉伯卡口车牌-2-image1837.txt
# data.txt 含义分别是: cls x y w h point1x point1y point2x point2y point3x point3y point4x point4y ...
# 类别 目标中心点x 目标中心点y 目标宽w 目标高h 目标点1x坐标 目标点1y坐标 目标点2x坐标 目标点2y坐标 目标点3x坐标 目标点3y坐标 目标点4x坐标 目标点4y坐标 依次类推
0 0.5739299610894941 0.1724137931034483 0.3715953307392996 0.29064039408866993 0.38910505836575876 0.08374384236453201 0.7587548638132295 0.029556650246305417 0.7607003891050583 0.2660098522167488 0.39299610894941633 0.32019704433497537
2 0.5739299610894941 0.1724137931034483 0.3715953307392996 0.29064039408866993 0.38910505836575876 0.08374384236453201 0.7587548638132295 0.029556650246305417 0.7607003891050583 0.2660098522167488 0.39299610894941633 0.32019704433497537
0 0.5739299610894941 0.1724137931034483 0.3715953307392996 0.29064039408866993 0.38910505836575876 0.08374384236453201 0.7587548638132295 0.029556650246305417 0.7607003891050583 0.2660098522167488 0.39299610894941633 0.32019704433497537
注意:
第1个值:类别索引,如果是单类别,这里值都为0
第2个值:目标框的中心点坐标x值,
第3个值:目标框的中心点坐标y值,
第4个值:目标框的宽度w,
第5个值:目标框的高度h,
第6个值:第1个关键点的x坐标,如果该关键点省去,设置坐标为-1
第7个值:第1个关键点的y坐标,如果该关键点省去,设置坐标为-1
第8个值:第2个关键点的x坐标,如果该关键点省去,设置坐标为-1
第9个值:第2个关键点的y坐标,如果该关键点省去,设置坐标为-1
第10个值:第3个关键点的x坐标,如果该关键点省去,设置坐标为-1
第11个值:第3个关键点的y坐标,如果该关键点省去,设置坐标为-1
第12个值:第4个关键点的x坐标,如果该关键点省去,设置坐标为-1
第13个值:第4个关键点的y坐标,如果该关键点省去,设置坐标为-1
…
后面依次是关键点的坐标值
2.1 修改数据yaml文件:
这里是读取数据的txt文档,所以传入图片路径txt文件即可,其中txt文档书写如下:
# train.txt
./train/images/-nfs-阿拉伯车牌字符-沙特阿拉伯卡口车牌-2-沙特阿拉伯卡口车牌-2-image1837.jpeg
./train/images/-nfs-车牌字符-埃及车牌-埃及车牌截图-2021-04-30 11-11-52屏幕截图.png
./train/images/-nfs-车牌字符-埃及车牌-埃及车牌截图-2021-04-30 13-57-27屏幕截图.png
./train/images/-nfs-车牌字符-埃及车牌-埃及车牌截图-2021-04-30 10-19-54屏幕截图.png
./train/images/-nfs-阿拉伯车牌字符-外国车牌现场_20210519_1-外国车牌现场_20210519_1-e0d92b0990a1249388bc77bdfa8e43ed.jpg
./train/images/-nfs-车牌字符-埃及车牌-埃及车牌截图-2021-04-30 13-51-28屏幕截图.png
./train/images/-nfs-车牌字符-约旦车牌-videoplayback-videoplayback_13_1460.jpg
./train/images/-nfs-车牌字符-埃及车牌-埃及车牌截图-2021-04-30 13-56-51屏幕截图.png
./train/images/-nfs-车牌字符-埃及车牌-埃及车牌截图-2021-04-30 10-27-50屏幕截图.png
这里读取数据是 :
txt前面的作为根目录,加上txt文档里面的路径,
所以图片的完整路径是这样存放的:
# txt前面的作为根目录,加上txt文档里面的路径,
# 所以图片的完整路径是这样存放的:
/media/wqg/3e165c12-9862-4867-b333-fbf93befd928/home/wqg/data/官网数据/PLATE/train/images/-nfs-阿拉伯车牌字符-沙特阿拉伯卡口车牌-2-沙特阿拉伯卡口车牌-2-image1837.jpeg
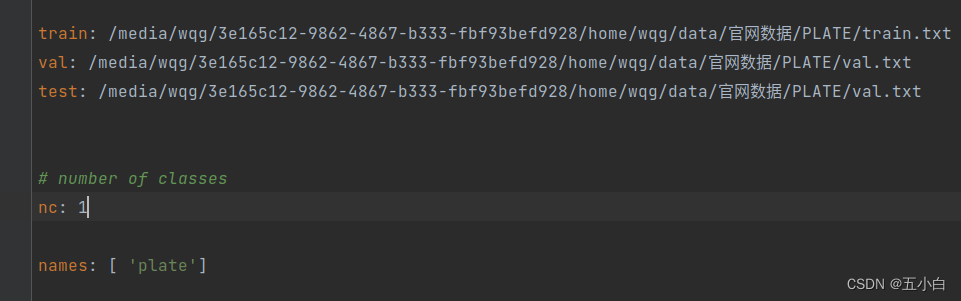
传入txt文档即可开始训练了。记得修改nc的类别数量和对应的名称
三 、开始训练
训练代码使用的是:./yolov7-pose_Npoint_Ncla/train_Ncla_nPoint.py
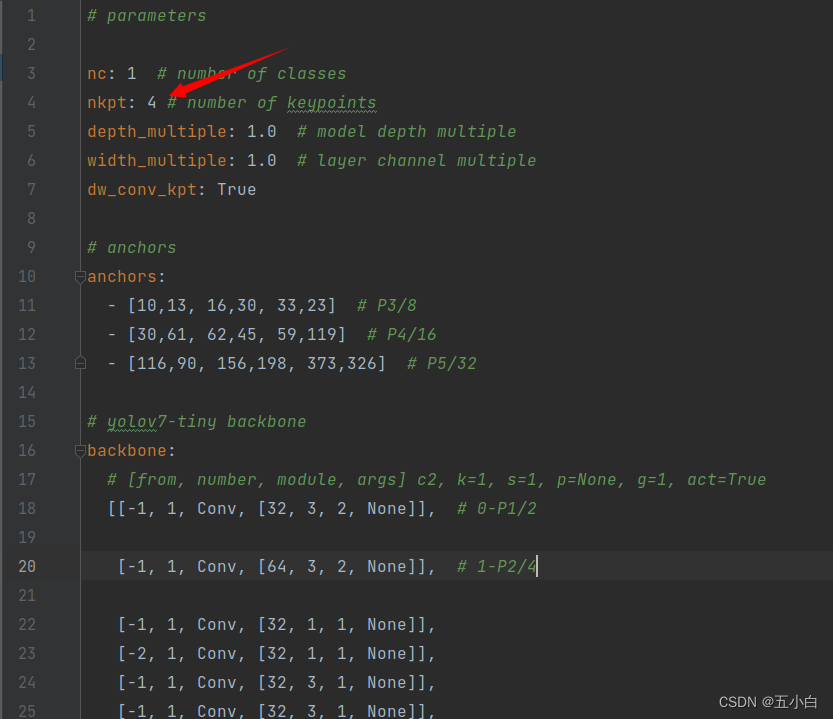
3.1 修改模型结构yaml文件
设置关键点的数量,默认是以4个关键点进行训练,类别数量默认是读取数据文件中的nc值。
3.2 数据准备好了就可以开始训练了
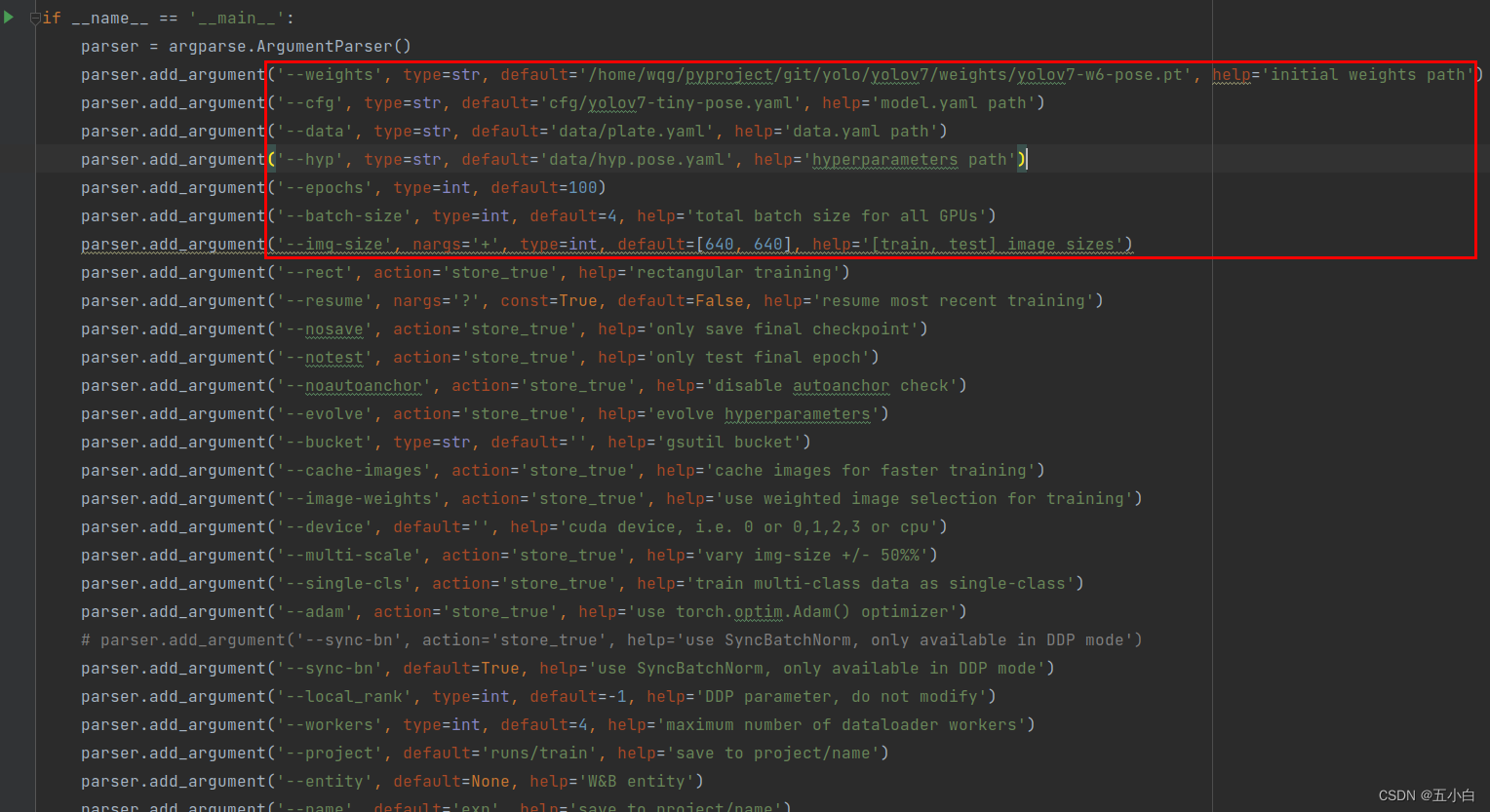
分别传入预训练权重,模型配置文件,修改好的数据文件,hyp文件,训练批次,训练尺寸等等。
- 权重链接:百度云链接 : https://pan.baidu.com/s/1izQzp7G5-tncRKtMTEyrUA 提取码: t82o。
- 建议: hyp文件中大家不要开上下翻转和左右翻转,会有可能导致关键点混乱。左右翻转是按照,1和2,3和4,5和6,7和8进行交换,上下翻转没有写翻转逻辑,建议不用,用的话需要自己修改代码。
训练开始,大家可以看到图像的每个关键点都是正确的:

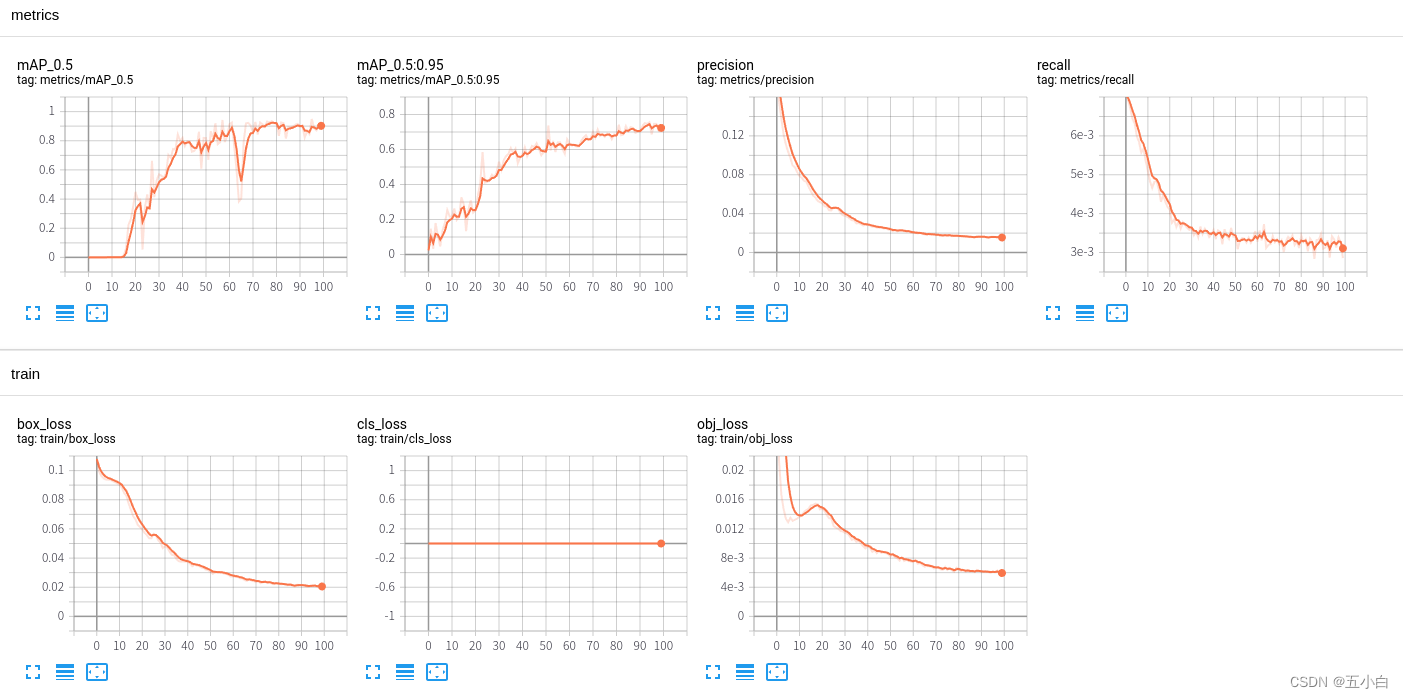
四 、 训练结果
这里我只是训练了100个eopch,数据也只是添加了500多张,
-
可以使用 tensorboard查看训练日志
-
训练推理结果:
推理代码:./yolov7-pose_Npoint_Ncla/detect.py

五、常见问题(粉丝问题)
数据增强部分索引错误
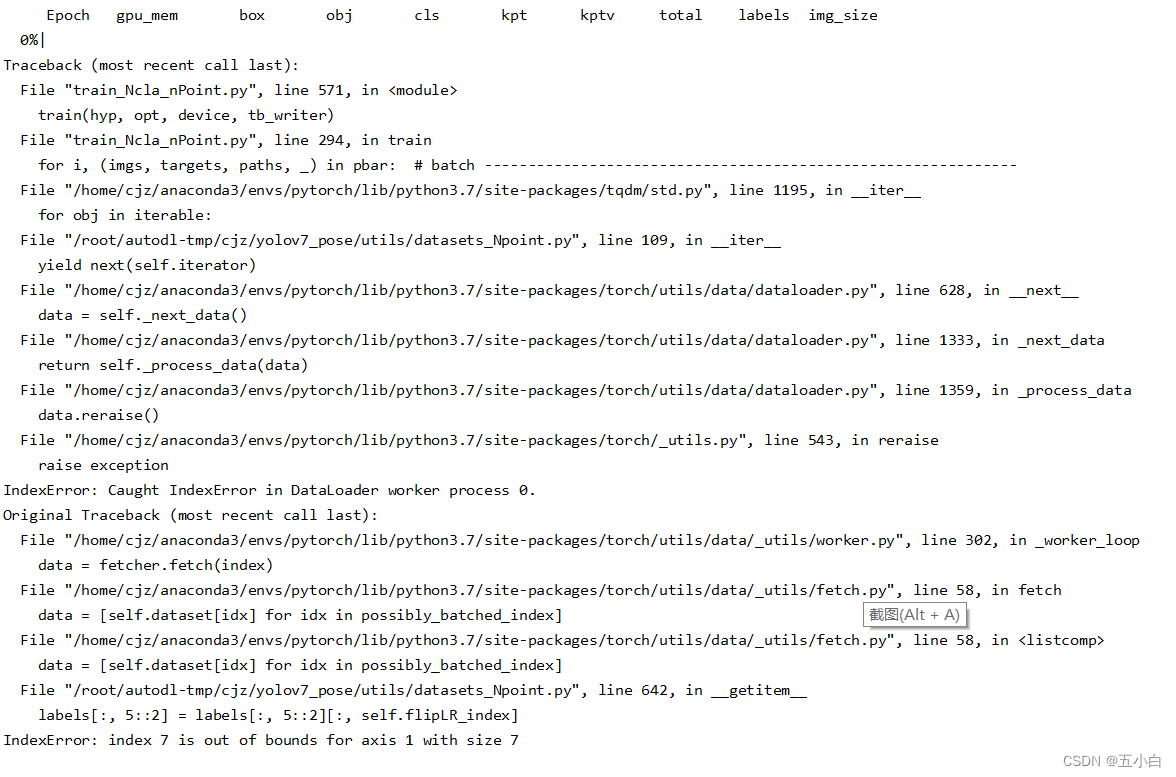
- 关键点的数量建议是偶数个,如果是基数个,需要改一下代码,或者去掉左右翻转和上下翻转。
文章出处登录后可见!