DRLIE: Flexible Low-Light Image Enhancement via Disentangled Representations
(DRLIE:基于解纠缠表示的柔性弱光图像增强)
解纠缠表示
弱光图像增强(Low-light image enhancement (LIME))是将亮度不理想的图像转化为理想的图像。与现有的不可控亮度控制方法不同,提出了一种灵活的框架,以用户指定的引导图像为参考,提高了实用性。为了实现这一目标,本文从信息解耦的角度,将图像建模为内容和曝光属性两个组成部分的组合。具体来说,我们首先采用内容编码器和属性编码器来解开这两个组件。然后,将弱光图像的场景内容信息与引导图像的曝光属性相结合,通过生成器重构增强图像。
介绍
在低光环境中捕获的I图像表现出一系列视觉退化,例如,低对比度、强噪声和细节丢失。低照度图像不仅会引起令人不快的主观感觉,而且会降低主要为高质量图像设计的计算机视觉系统的性能。因此,普遍需要低光图像增强以在保持成像内容的同时呈现具有期望照明的图像。该过程有助于改善视觉感知,并为许多高级计算机视觉任务(如监控、对象检测、人脸检测和自动驾驶)提供高质量的输入。此外,还期望具有更灵活的照明操纵的实用的低光图像增强(LIME)系统来为用户/应用提供交互式选项,因为不同用户/应用的优选照明水平可能具有很大的多样性。
在过去的几十年中,已经开发了许多低光图像增强技术,包括基于直方图均衡化(HE)的方法、基于物理模型的方法和数据驱动的方法。基于HE的方法通常使用非线性变换来拉伸低光图像的像素强度以增强对比度。这些方法主要包括全局HE和局部HE。全局HE技术从全局角度增强图像,这可能导致一些正常曝光区域存在过饱和的风险。局部HE方法可以在一定程度上克服全局HE的局限性,但滑动窗口策略会增加计算负担。此外,全局HE和局部HE方法都增强了低光图像的对比度,而没有根据用户的偏好来调整结果的交互式选项。基于物理模型的方法假设存在用于低光图像的一些特定物理模型,并且可以推断这些模型的参数以更好地增强图像。Retinex模型和大气散射模型是两种广泛使用的模型。Retinex模型的主要假设是图像可以被分解为反射和亮度两个分量,并且前一个分量可以作为最终的增强结果。早期的尝试,例如单尺度Retinex(SSR)和具有颜色恢复的多尺度Retinex(MSRCR),通过高斯滤波器获得反射和照明图。为了对分解因子给予更实质的物理解释,许多工作致力于引入更鲁棒的先验信息来约束分解。开发了几种创新过滤器来进行该过程。研究人员还注意到,倒置的低光图像具有与模糊图像相似的概率分布。因此,考虑大气散射模型并将其应用于弱光图像增强任务。然而,不能根据用户的偏好灵活地调节照明是基于物理模型的方法的普遍缺点,这限制了它们的实用性。
近年来,深度学习的繁荣也鼓励研究人员探索数据驱动的弱光图像增强方案。一般而言,主流的数据驱动算法可分为两类,即全监督和无监督方法。全监督方法需要大规模数据集为模型训练提供参考。然而,收集成对的低/正常光图像是昂贵的,并且正常光图像的清晰度因人而异。相比之下,无监督方法使用不成对的数据来学习增强模型,这可以避免收集成对图像的繁琐。然而,由于缺乏适当的监督,这种方法通常不能恢复精细细节。然而,目前大多数数据驱动的模型只能合成一个增强结果,不能根据用户的亮度偏好进行定制。
针对不同用户的实际需求,提出了一种基于解纠缠表示的可控亮度引导的弱光图像增强方法。该方法将弱光图像增强定义为内容保持和亮度恢复。后者是可控的,并且由真实定制图像的曝光属性引导。该方法的关键是充分分离内容和暴露属性。针对这一问题,我们采用了一种解纠缠模型来实现这一目的。首先,提出一种内容编码器将源图像映射到领域不变内容空间,并设计一种属性编码器将源图像嵌入到特定领域曝光属性空间。然后,使用生成器来合并这两种类型的表示,并将它们映射回图像空间。因此,该方法可以在保持弱光图像场景内容的同时,分配任意的亮度分布,实现可控的弱光图像增强。图1提供了一个例子,揭示了DRLIE在场景保真度、噪声抑制和可控照明调节能力方面的优越性。值得注意的是,我们的DRLIE可以在不同参考图像的指导下合成不同的增强结果。
贡献
1)提出了一种可控亮度引导的弱光图像增强算法,允许用户根据自己的喜好灵活定制场景亮度。
2)提出了一种图像的解纠缠表示方法,将图像分解为场景内容和曝光属性。据我们所知,这是第一个将解纠缠表示引入到微光图像增强中的工作。
3)所设计的内容特征一致性损失,特别是,L2归一化方法通过驱动内容编码器捕获公共场景信息和平滑内容特征,可以有效地实现信息解纠缠和抑制隐藏在黑暗中的噪声。
4)我们的方法是一个无监督的模型,它不依赖于充分暴露的地面真相。大量的实验表明,与现有的模型相比,该模型具有上级的性能。
相关工作
Low-Light Image Enhancement Methods
低光图像增强技术作为一种重要的图像处理技术,在近几十年受到了广泛的关注。根据所采用的原理,主流的微光图像增强方法可分为以下三类。
1) HE-Based Methods:
基于HE的增强方法通过操纵输入图像的直方图来拉伸对比度,这使得隐藏在黑暗中的信息可见。为了改善增强结果的视觉质量,加权阈值直方图均衡化(WTHE)通过在均衡化之前加权和阈值化来修改图像的概率分布函数。Lee等人通过使用2-D直方图放大层之间的差异来实现对比度增强。此外,Tarik等人在优化过程中加入了更多的正则化约束,如噪声鲁棒性和白色/黑拉伸。一般而言,基于HE的方法通过更多的正则化和约束来提高光照调整的局部自适应性。然而,这些方法仍然不够灵活以调整局部区域的视觉感知,并且导致不自然的局部外观,例如曝光不足/曝光过度。另外,忽略噪声因素导致在图像对比度增强期间噪声被放大。
2) Physical Model-Based Methods:
基于Retinex模型的方法由于分解的不适定性而引入了各种约束和先验。SSR设计了中心/环绕Retinex的实际实现,其反射率被视为最终结果。虽然对数变换符合Weber定律,但将反射率和照度的对数变换用作罚因子是不合适的。因此,Fu等人提出了一种同时估算反射率和照度的加权变分模型。也有许多研究集中在探索更有效的先验信息,以促进反射率和光照更符合视觉感知。例如,LIME 提出通过施加结构感知先验来细化初始照明图。然而,上述方法缺乏对反射率的充分约束,并且隐藏在黑暗中的强噪声可能被放大。Li等人提出了一种鲁棒的Retinex模型,该模型不仅将图像分解为反射率和照度,而且还考虑了噪声图。总的来说,由于相关的先验或约束是手工制作的,基于Retinex理论的方法通常不能满足所有个体的需求,并且可能产生不令人满意的结果。
基于大气散射模型的方法将逆光图像视为霾图像,通过一些去雾技术来提高能见度。然后,将去雾图像反转为增强结果。然而,基于大气散射模型的方法缺乏令人信服的物理解释,不能适应不同用户的视觉感知,并且采用去噪技术作为后处理操作可能导致平滑的结构。
3) Data-Driven Methods:
数据驱动的低光照条件下的图像增强方法已逐渐取代光线增强其优异的特性表征的发展能力。弱光网络(LLNet)是数据驱动的弱光增强方法的先驱,通过堆叠稀疏去噪自动编码器执行对比度增强和去噪。为了处理包括亮度、对比度、伪像和噪声的各种因素,Lv等人将多尺度特征嵌入多分支弱光增强网络(MBLLEN)。Ren等人提出了一种新颖的网络结构,由内容和边缘流同时提取全球内容和凸结构的低光照条件下的图像。RetinexNet、LightenNet、DeepUPE和RDGAN 将Retinex理论集成到深度网络结构的设计中,这使得网络提取的信息在本质上更加物理可定义。
值得注意的是,上述算法不能学习映射函数或训练分解网络没有地面真实。然而,收集成对的低/正常光图像是复杂的。目前获得配对低/正常光图像的方法如下:1)建立退化模型从正常光照图像生成低光照图像,但该方法不能真实地表现低光照图像的自然光照;2)使用相机的不同曝光参数设置拍摄相同真实场景的照片,但是粗略地调整曝光参数可能导致局部曝光不足/过度曝光伪影。为了缓解这一挑战,引入了无监督方法。Zero-DCE 提出了一种零参考方法,通过精心设计的损失函数来规范无监督训练。EnlightenGAN 引入非成对学习来训练增强模型,该模型通过全局和局部鉴别器来实现照明调整。Zero-DCE和EnlightenGAN证明了无配对数据的弱光增强学习的可行性。但缺乏强有力的监管,必然会导致细节缺失、色彩偏差。
Yang等人构建了一种新型的半监督学习框架,用于弱光增强,称为深度递归带网络(DRBN)。不幸的是,它仍然需要成对监督来获得感知质量先验。更重要的是,上面提到的方法中没有一个为用户提供灵活地操纵照明水平的交互式选项。最近,提出了一种称为KinD++ 的框架,其提供了用于灵活地调节光水平的映射功能。然而,KinD++粗糙地应用gamma映射来实现任意的光照调整,并且由于过度抑制噪声而在增强结果中引入虚假纹理。
Disentangled Representation
解纠缠表示理论的本质是对数据变化因素的建模。近年来,人们提出了一系列无监督的方法来学习解纠缠表示。DrNet 利用视频的时间相干性和对抗损失将每一帧分解为静止分量和时间变化部分。Tran等人提出了解纠缠表示学习生成对抗网络,该网络将姿态和身份部分解纠缠,用于姿态不变的人脸识别。Lee等人将图像嵌入到两个独立的空间中,即域不变内容空间和域特定属性空间。随后,通过操纵该属性来实现不同视觉域之间的图像到图像的转换。Lu等人从模糊图像中分离出内容和模糊属性,并将模糊信息明确编码到单幅图像去模糊框架中。Du等人通过解纠缠表示和对抗域自适应从噪声数据中学习不变表示,在有效的自监督约束的辅助下,可以重建具有更清晰细节和更好视觉感知的高质量图像。图像融合的解纠缠表示(DRF)将源图像映射到域不变场景空间和域特定属性空间,并合并两种类型的表示以实现多模态图像融合。
本文将弱光图像增强定义为内容保持和光照处理。通过引入解纠缠表示,将图像的内容表示和曝光属性分离,实现了根据指定的目标曝光属性可控地调节光照。
方法
Problem Analysis
给定一幅低照度图像x和一幅随机的真实感引导图像z,分别在曝光不足域X∈和正常曝光域Z∈
中,增强后的图像可以表示为x的内容特征和z的曝光属性向量的组合。基于解纠缠表示的自定义光照引导的弱光图像增强方法如图2所示。
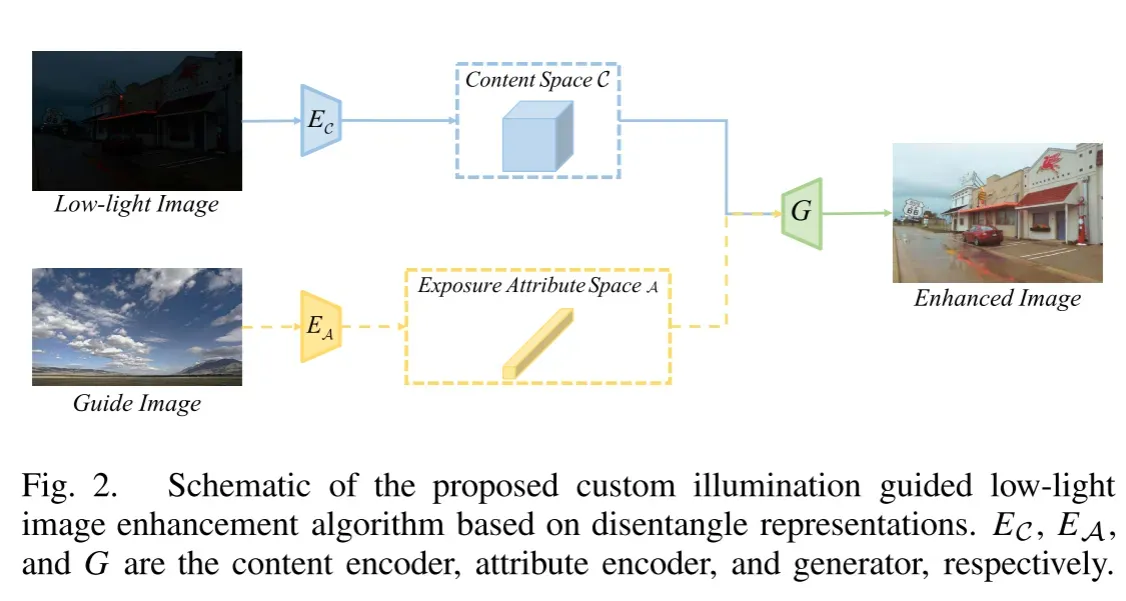
作为图像的两个固有组成部分的内容和曝光属性可以通过内容编码器EC和属性编码器EA从源图像中分离。在分别从弱光图像和向导图像提取内容表示和曝光信息之后,生成器G将内容特征和曝光属性的组合集成到增强图像中。DRLIE的增强过程可以表示为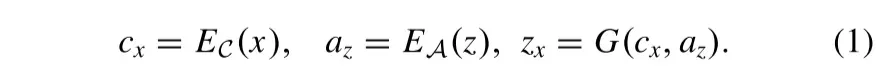
对于两个不同曝光域的图像x和y,我们的算法将它们嵌入到共享内容空间C和唯一曝光属性空间AX和AY中。直观地,内容编码器将各个曝光域之间的公共信息映射到内容空间C,而属性编码器应将域特定的私有信息编码到AX和AY。具体可以表述为:
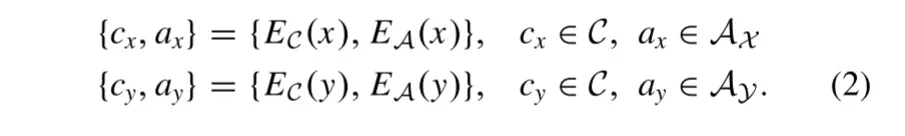
由于内容信息与空间位置直接相关,因此我们以特征地图的形式定义内容表示。此外,曝光属性取决于相机设置和成像条件。因此,向量包含全局曝光属性就足够了。为此,设计了一个共享内容编码器,用于提取不同领域的公共场景信息;设计了一个属性编码器,用于灵活提取不同领域的特定曝光属性。然后,应该存在逆映射以将C和A映射回原始图像空间,以确保原始图像的所有信息可以由两种类型的编码结果表示。针对这一点,我们设计了一个生成器G来学习逆映射。生成器G应当具有融合内容特征和曝光属性并重构图像的能力。因此,生成器G应该具有以下两个能力。
1)首先,生成器需要利用解纠缠后的内容和曝光属性重构原始图像。更具体地,以{cx,ax}和{cy,ay}为条件,重建图像可以被定义为
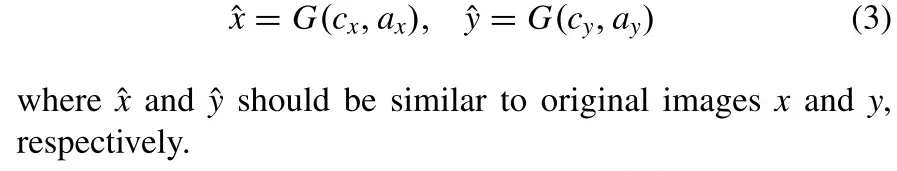
2)其次,内容编码器捕获跨域X和Y的信息,而属性编码器捕获域特定属性而不携带内容相关提示。给定来自不同域的内容和属性,期望由生成器G合成的图像与提供曝光属性的图像一致。生成器应按如下方式实现转换:
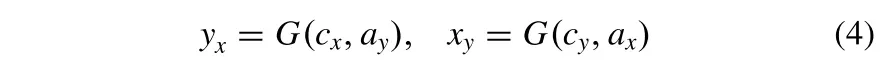
其中yx和xy是平移的图像。此外,使用两个鉴别器来测量平移图像与原始图像在概率分布中的距离,以进一步提高生成器G的性能。
Network Architecture
我们的内容编码器EC、曝光属性编码器EA、生成器G以及鉴别器DX和DY的主要结构都是基于卷积神经网络(CNNs)和ResBlocks,其详细展示如下。
1) Content Encoder, Attribute Encoder, and Generator
Architecture:
内容编码器、属性编码器和生成器的网络体系结构如图4所示。
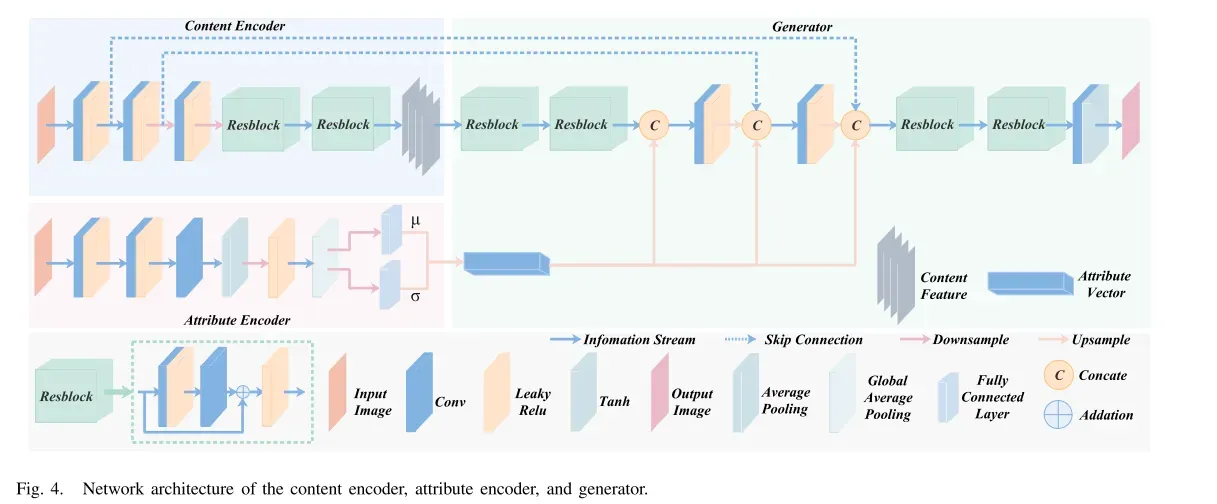
内容编码器EC由五个模块组成,包括三个卷积层和两个残差块。包括三个卷积层和两个残差块。第一卷积层使用7 × 7滤波器获得16个特征图。第二和第三卷积层在空间维度上对特征图进行下采样,并通过3 × 3滤波器增加通道数。对特征映射进行下采样的目的是有助于将内容特征约束在小尺度和高维特征空间内的内容一致性损失。随后,采用两个级联残差块来减轻梯度消失和爆炸难题。
属性编码器EA的前两个模块是具有泄漏校正线性单元(ReLU)激活函数的卷积层,其负责从输入图像中提取足够的曝光信息。第三层由级联卷积层、平均池和Leaky Relu激活函数组成。然后,通过全局平均合并对空间曝光信息进行压缩,并通过全连通层得到曝光属性的均值和标准差。
给定内容特征c ∈C和属性向量a∈ A,生成器G旨在整合各种信息并将它们映射回图像空间。在经过两个残差块之后,内容特征然后与整形的属性向量级联,然后将其馈送到上采样模块。值得强调的是,我们引入了跳跃连接,以避免由于对内容特征进行下采样而导致的纹理细节损失。每个尺度下的特征图与对应的属性特征级联,以将曝光信息与内容特征完全集成。每个尺度下的特征图与对应的属性特征级联,以将曝光信息与内容特征完全集成。然后,利用两个残差块来合并不同的表示。最后一层是卷积层,滤波器大小为1 × 1。内容编码器、属性编码器和生成器中的所有层都采用Leaky ReLU作为激活函数,但生成器的最后一层采用Tanh。
2) Discriminator Architecture:
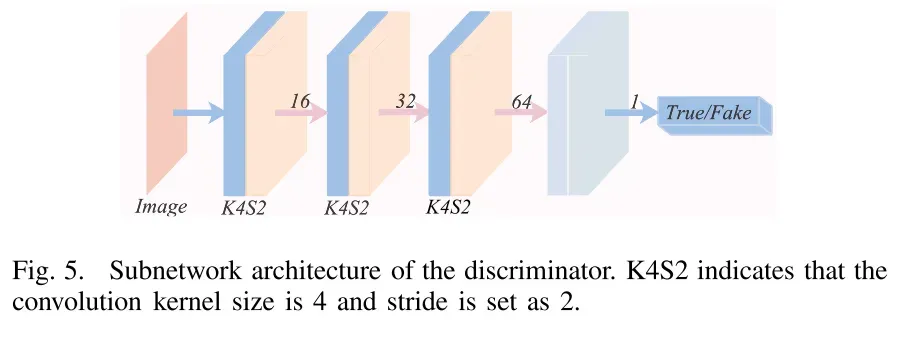
鉴别器DX和DY用于从真实的图像中鉴别由发生器G合成的平移图像。如图5所示,子鉴别器由三个卷积层和一个全连接层组成。所有卷积层使用4 × 4卷积核。完全连接的层将特征映射压缩为标量。值得注意的是,鉴别器包含如上所述的三个子鉴别器,并且三个子网络的输入是源图像的不同分辨率版本。最终概率是三个子网输出的平均值。
Loss Functions
1) Content Feature Consistency Loss:
我们强制来自不同领域的公共信息通过同一个内容编码器映射到内容空间。然而,共享映射函数不能保证内容空间仅包含域不变特征。因此,我们提出了内容特征一致性损失来约束内容编码器在特征层面上。具体地,我们将cx和cy上的内容特征一致性损失定义为
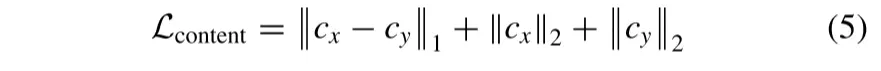
其中||·||1和||·||2分别表示L1规范和L2范数。内容特征一致性损失涉及各种内容特征差异约束和内容特征正则化约束。L1规范强制不同域的内容特征保持一致,L2范数驱动内容编码器捕获公共信息。
2) Attribute Distribution Loss:
属性编码器被期望对来自源图像的曝光信息进行编码,同时抑制内容信息。已有研究表明,Kullback-Leibler(KL)散度促进解纠缠,先验高斯分布适合于约束曝光属性。因此,我们引入属性分布损失来正则化曝光属性向量的分布,期望其接近高斯分布p(z)~N(0,1)。属性分布损失表示如下:
受上述的启发,属性分布损失被重新定义为:
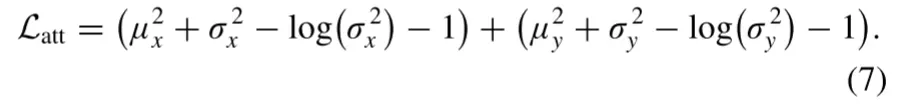
3) Self-Reconstruction Loss:
理论上,解纠缠表示应该包含输入图像的所有信息。因此,我们期望生成器从解纠缠的内容和属性表示中重构源图像。我们将自重建损失具体定义如下,以表示重建图像与原始图像之间的差异:

其中▽表示梯度算子,其测量图像的纹理信息。在此工作中,我们使用Sobel算子来计算梯度。
4) Domain Translation Loss:
我们设计了域平移损失来加强对生成器G的约束。与自重构损失类似,域平移损失定义为
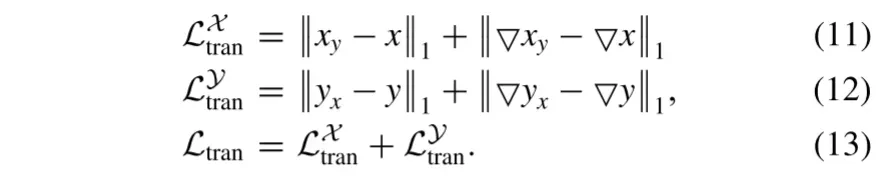
因此,域变换损失可以通过约束变换后的图像来保证生成器G充分聚合内容特征和曝光属性。
5) Domain Adversarial Loss:
除了域平移损失外,我们还引入了域对抗损失,使平移后的图像在分布上与真实图像保持一致,从而使图像更加真实。我们将域名对抗性损失表示为
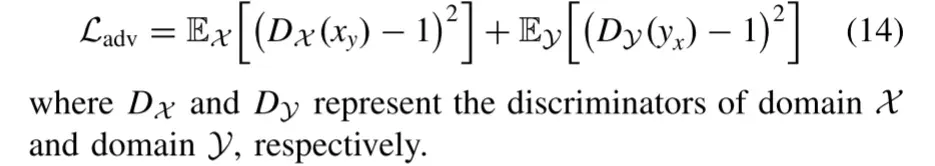
6) Total Generator Loss:
内容编码器、属性编码器和生成器的完整目标函数是从(5)到(13)的所有损失项的加权和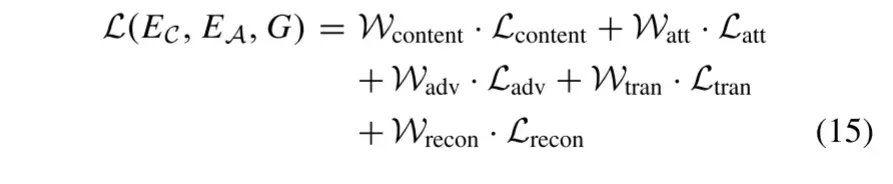
其中Wcontent、Watt、Wadv、Wtran和Wrecon是权衡每个损耗项的超参数。通过最小化损失函数L(EC,EA,G)来优化内容编码器EC、属性编码器EA和生成器G的参数。
7) Discriminator Loss:
为了保证平移后的图像更逼真,我们在生成器G和鉴别器DX和DY之间构造了一个博弈。我们将鉴别器的损失函数表示为
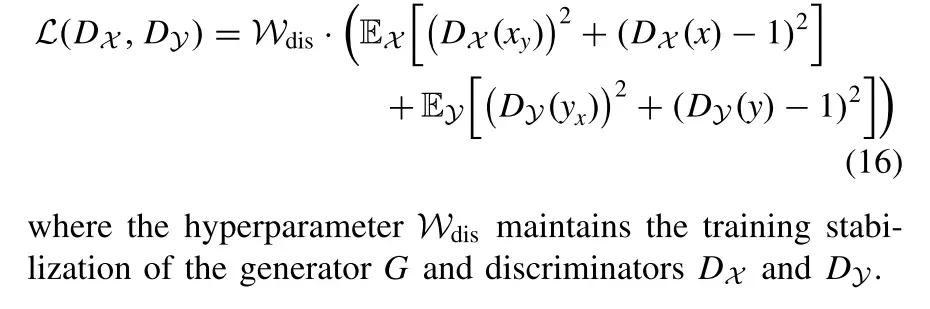
文章出处登录后可见!