当今时代,数据分析和处理已经成为了各行各业中不可或缺的一环。Python作为一种非常流行的编程语言,为我们提供了许多强大的工具和库来处理不同类型的数据。
在这篇文章中,我将向您介绍七个非常有用的Python库,这些库各自有着独特的功能和用途,可以帮助你处理和分析不同类型的数据,提高你的数据分析和处理效率。
无论你是数据分析初学者,还是经验丰富的数据科学家,本文都会为你提供有价值的信息和入门案例。让我们一起深入了解这些强大的 Python 库吧!
1.Memray

memray 是一个Python库,它提供了一种可视化内存管理工具,可以帮助Python开发人员更好地理解和优化他们的代码中的内存使用情况。
它是由彭博社开发的,可用于分析Python程序中的内存泄漏和其他内存问题。以下是memray库的使用场景和入门案例:
使用场景:
- 优化内存使用:当你的Python程序使用大量内存时,可以使用memray库来识别哪些变量和对象正在占用大量内存,以便优化你的代码。
- 调试内存泄漏:当你的Python程序出现内存泄漏时,可以使用memray库来识别哪些变量和对象正在泄漏内存,以便进行调试。
- 分析对象引用:当你需要了解Python对象之间的引用关系时,可以使用memray库来分析对象之间的引用链,以便更好地理解代码。
如何使用:
假设你有一个Python程序,它读取大量的数据并处理它们。你发现这个程序在处理大量数据时会使用大量的内存。你想了解哪些变量和对象正在占用大量内存。
以下是使用memray库进行内存分析的入门案例:
首先,安装memray库:
pip install memray
然后,在你的Python程序中引入memray库并运行你的代码。当你的程序开始使用大量内存时,你可以使用memray库来识别内存占用情况。例如,你可以使用以下代码来获取程序中最大的内存使用量:
import memray
memray.print_max_usage()
这将打印出程序的最大内存使用量和使用最多内存的对象的信息。你可以使用这些信息来优化你的代码并减少内存使用。
此外,你可以使用memray库来分析对象之间的引用关系。例如,你可以使用以下代码来获取一个对象及其所有引用的对象的信息:
import memray
my_object = ...
memray.print_object_summary(my_object)
这将打印出my_object及其引用的所有对象的信息。你可以使用这些信息来更好地理解你的代码并优化内存使用。
总之,memray是一个非常有用的Python库,可以帮助开发人员更好地理解和优化他们的代码中的内存使用情况。它提供了一些实用的工具来识别内存占用情况、调试内存泄漏和分析对象引用关系。
https://github.com/bloomberg/memray
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
本文来自技术群粉丝分享整理,文章源码、数据、技术交流,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自CSDN +备注来意
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
2.Scrapy
==========
https://github.com/scrapy/scrap
scrapy是一个Python爬虫框架,它提供了一种简单、可扩展、高效的方式来爬取Web页面并提取有用的信息。以下是scrapy库的使用场景和入门案例:
使用场景:
- 爬取数据:当你需要从Web页面中获取数据时,可以使用scrapy框架来快速爬取和提取数据。
- 构建搜索引擎:当你需要构建一个搜索引擎时,可以使用scrapy框架来爬取和索引Web页面,以便提供搜索结果。
- 数据挖掘:当你需要对Web页面中的数据进行挖掘和分析时,可以使用scrapy框架来获取数据并进行处理。
如何使用:
假设你想从一个网站上获取所有文章的标题、作者和发布日期。以下是使用scrapy框架进行爬虫的入门案例:
首先,安装scrapy库:pip install scrapy
然后,在终端中进入一个你想要爬取的目录,并使用以下命令创建一个scrapy项目:
scrapy startproject myproject
这将在当前目录下创建一个名为“myproject”的目录,其中包含一个基本的scrapy项目结构。
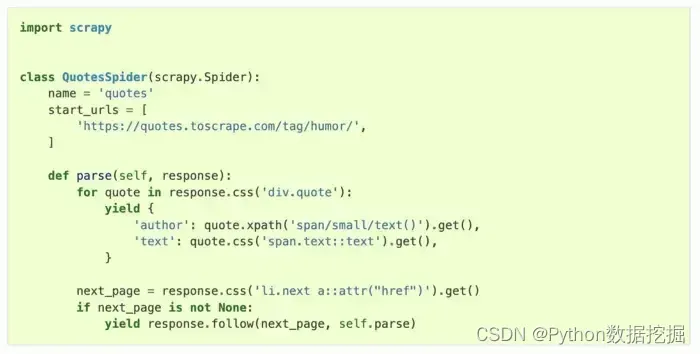
接下来,在myproject/spiders目录下创建一个名为“my_spider.py”的文件,并在该文件中定义一个Spider类来实现爬虫逻辑。以下是一个示例:
import scrapy
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = ["<http://www.example.com>"]
def parse(self, response):
for article in response.css(".article"):
yield {
"title": article.css("h2 a::text").get(),
"author": article.css(".author::text").get(),
"date": article.css(".date::text").get(),
}
next_page = response.css(".next-page a::attr(href)").get()
if next_page:
yield response.follow(next_page, self.parse)
在这个示例中,我们定义了一个名为“myspider”的Spider类,它的start_urls为”http://www.example.com”,我们使用response.css()方法来选择要提取的元素,使用yield语句来返回提取的数据,使用response.follow()方法来获取下一页的链接并递归调用,我们需要在终端中进入myproject目录,并运行以下命令来运行爬虫:
scrapy crawl myspider -o output.json
这将启动名为“myspider”的爬虫,并将结果保存到一个名为“output.json”的文件中。在运行完命令后,你可以在myproject目录中找到生成的output.json文件,并查看爬取到的数据。
以上是一个简单的scrapy爬虫入门案例,你可以通过修改Spider类来自定义爬虫逻辑,并使用其他scrapy组件来实现更复杂的爬虫功能。
3.Networkx
如其名称所示,如果你想分析你的网络,那么这是一个好的资源。这是一个用于创建、操作和研究复杂网络的结构、动态和功能的库。它支持各种各样的特性,例如从各种数据源创建图形、测量网络属性等。它还提供了各种算法来分析和操作图形,例如中心度测量、最短路径算法等。它在 GitHub 上拥有超过 12k 个星。
使用场景:
- 分析社交网络:当你需要对社交网络进行分析时,可以使用networkx来构建网络图并计算网络的度、聚类系数、中心性等统计指标。
- 分析交通网络:当你需要对交通网络进行分析时,可以使用networkx来构建路网图并计算最短路径、最小生成树等路网指标。
- 分析生物网络:当你需要对生物网络进行分析时,可以使用networkx来构建蛋白质相互作用网络、代谢网络等生物网络,并计算网络的模块性、关键基因等生物学指标。
如何使用:
假设你想创建一个简单的网络图,并计算网络的一些基本指标,如节点度、平均路径长度和聚类系数。以下是使用networkx库进行网络分析的入门案例:
首先,安装networkx库:pip install networkx
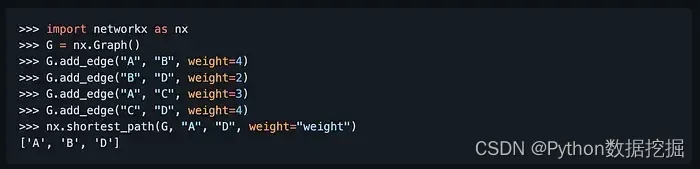
然后,在Python交互式环境中导入networkx库,并创建一个简单的无向图:
import networkx as nx
G = nx.Graph()
G.add_nodes_from([1, 2, 3, 4, 5])
G.add_edges_from([(1, 2), (1, 3), (2, 4), (3, 4), (4, 5)])
在这个示例中,我们创建了一个包含5个节点和5条边的无向图。接下来,我们可以使用networkx提供的函数来计算图的一些基本指标:
print(nx.degree(G)) # 计算每个节点的度
print(nx.average_shortest_path_length(G)) # 计算图的平均路径长度
print(nx.average_clustering(G)) # 计算图的聚类系数
以上代码将分别输出每个节点的度,图的平均路径长度和聚类系数。你可以根据需要修改图的结构和指标的计算方法,以满足你的具体需求。
以上是一个简单的networkx入门案例,你可以通过修改图的结构和使用其他networkx函数来实现更复杂的网络分析功能。
https://github.com/networkx/network
4.Schedule

这是一个人性化的 Python 作业调度库。它使用友好的语法定期运行 Python 函数(或任何其他可调用函数)。它包括许多特性,例如用于定期作业的进程内调度程序(无需额外的进程)、非常轻量级且没有外部依赖项、具有极好的测试覆盖率等等。这个库在 GitHub 上拥有超过 10.5k 个
使用场景:
- 执行定时任务:当你需要按照指定的时间间隔执行任务时,可以使用schedule来定期运行Python函数,例如每隔一段时间执行一次数据备份任务。
- 执行周期性任务:当你需要按照指定的时间规律执行任务时,可以使用schedule来按照指定的周期性运行Python函数,例如每周日晚上执行一次数据库清理任务。
如何使用:
假设你想使用schedule定期运行一个Python函数,以下是使用schedule库的入门案例:
首先,安装schedule库:pip install schedule
然后,在Python脚本中导入schedule库,并定义一个Python函数来执行任务:
import schedule
import time
def job():
print("I'm working...")
schedule.every(10).seconds.do(job) # 每10秒执行一次任务
while True:
schedule.run_pending()
time.sleep(1)
在这个示例中,我们定义了一个名为job的函数,它会在每10秒钟执行一次,并输出一条消息。我们使用schedule库中的every函数来指定任务的执行时间,使用do函数来指定要执行的任务。
最后,我们使用一个while循环来不断地检查是否有任务需要执行,并使用time.sleep函数来让程序休眠1秒钟,以便减少CPU的占用率。
以上是一个简单的schedule入门案例,你可以根据需要修改任务的执行时间和要执行的任务,以实现更复杂的定时任务功能。
https://github.com/dbader/schedule
5.Word Cloud

如你所猜测的那样,如果你想生成一个词云图,那么这是一个好的资源。词云是一种显示文本中单词频率的图像,图像中单词的大小表示其在文本中的频率。
它提供了一个简单直观的 API,从文本数据生成词云,使其成为一种有用的工具,用于可视化文本数据并探索单词之间的关系。它在 GitHub 上拥有超过 9k 个星。
使用场景:
word_cloud 库通常应用于以下场景:
- 文本数据分析和可视化:词云图可以直观地反映文本数据中的热点、关键词等信息。
- 设计和排版:词云图可以作为设计元素,用于海报、卡片、书籍封面等排版。
如何使用:
下面是一个简单的入门案例,以演示如何使用word_cloud库生成一个词云图:
# 导入需要的库
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 准备文本数据
text = "Hello world! Hello everyone! This is an example of word cloud."
# 创建 WordCloud 对象
wordcloud = WordCloud().generate(text)
# 将词云图显示出来
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
以上代码的执行结果是生成一个简单的词云图,如下图所示:

在这个例子中,我们首先导入了需要的库,包括wordcloud和matplotlib.pyplot。然后,我们准备了一个简单的文本数据,用于生成词云图。
接着,我们创建了一个WordCloud对象,并通过generate()方法将文本数据转化为词云图。最后,我们使用matplotlib.pyplot中的imshow()方法将词云图显示出来,并通过axis(“off”)方法去掉坐标轴。
当然,我们还可以通过WordCloud对象的各种参数来调整词云图的外观和效果,例如:
# 创建 WordCloud 对象,并设置参数
wordcloud = WordCloud(background_color="white", max_words=100, contour_width=3, contour_color='steelblue').generate(text)
# 将词云图显示出来
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
这里我们增加了一些参数,例如background_color设置背景颜色为白色,max_words设置最多显示100个词语,contour_width和contour_color设置词云图的轮廓线宽度和颜色。
以上就是一个简单的使用word_cloud库的入门案例。当然,在实际应用中,我们可以根据不同的需求和场景,进一步调整和优化词云图的效果,例如设置字体、颜色、大小、布局等等。
https://github.com/amueller/word\_cloud
6.PySimpleGUI
该库将帮助您轻松创建复杂和多窗口应用程序。您可以使用包含小部件的“布局”指定 GUI 窗口(在 PySimpleGUI 中称为“元素”)。使用您的布局创建窗口,使用 4 个支持的框架之一来显示和与您的窗口交互。支持的框架包括 tkinter、Qt、WxPython 或 Remi。它包括 325+ 演示程序和快速入门指南。这个库在 GitHub 上拥有超过 11k 个星。
使用场景:
PySimpleGUI 库通常应用于以下场景:
- 交互式应用程序:可以使用PySimpleGUI创建交互式的图形用户界面,例如文本编辑器、计算器、数据可视化应用等。
- 嵌入式应用程序:PySimpleGUI也可以嵌入到其他应用程序中,例如在机器学习应用中显示模型预测结果。
- 个人和小型项目:由于PySimpleGUI易于学习和使用,因此可以用于个人或小型项目的图形用户界面开发。
如何使用:
下面是一个简单的入门案例,以演示如何使用PySimpleGUI库创建一个简单的GUI程序:
# 导入需要的库
import PySimpleGUI as sg
# 创建GUI布局
layout = [[sg.Text('Hello World')], [sg.Button('OK')]]
# 创建窗口
window = sg.Window('My first GUI program', layout)
# 循环获取事件
while True:
event, values = window.read()
if event == sg.WIN_CLOSED or event == 'OK':
break
# 关闭窗口
window.close()
以上代码的执行结果是创建一个窗口,其中包含一个文本标签和一个按钮,如下图所示:
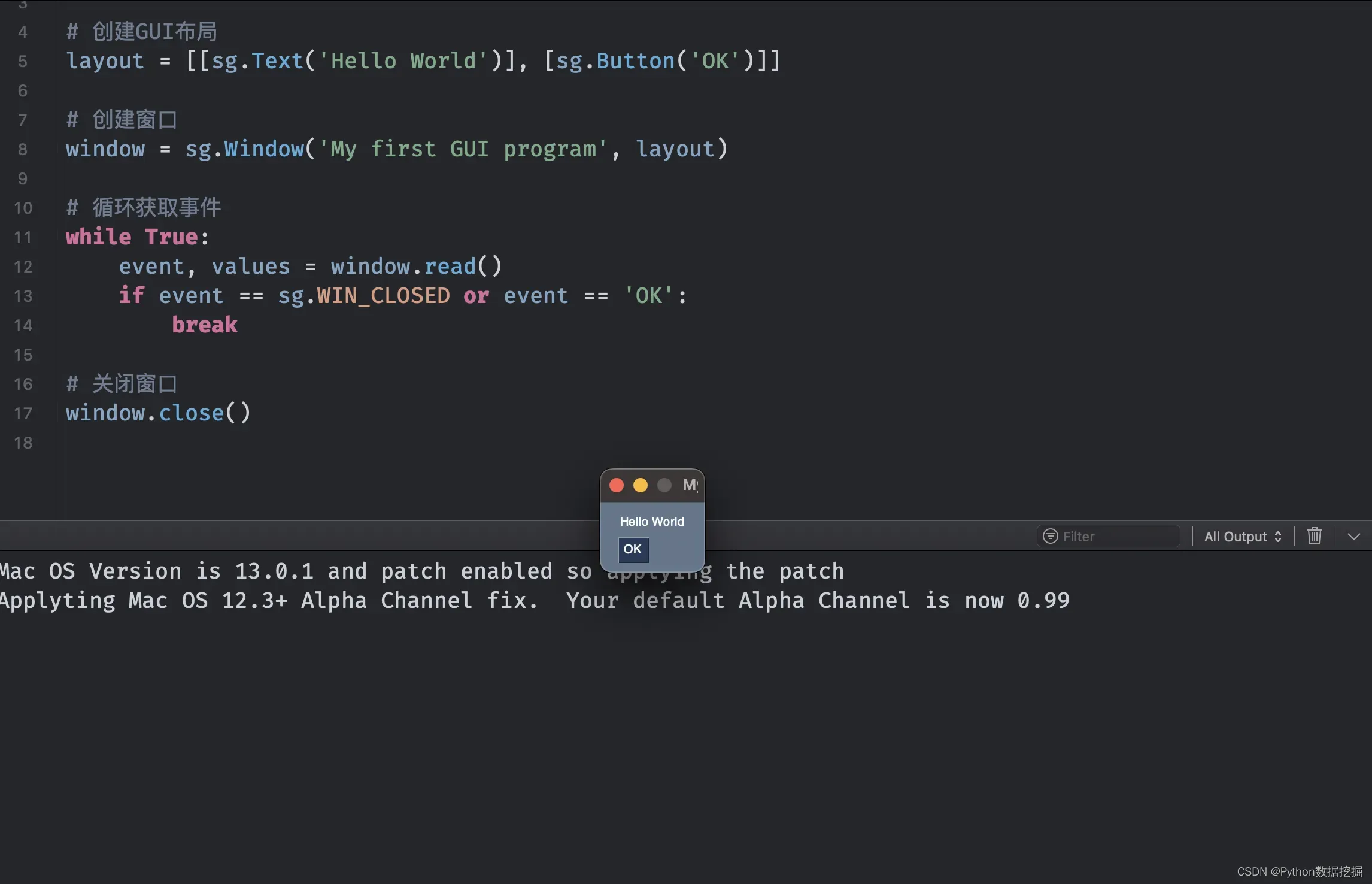
在这个例子中,我们首先导入了需要的库,包括PySimpleGUI。然后,我们创建了一个GUI布局,包含一个文本标签和一个按钮。接着,我们创建了一个窗口,并将GUI布局传递给窗口。
在窗口创建后,我们进入一个循环中,使用window.read()方法不断获取事件和值,如果事件是窗口关闭事件或者按钮点击事件,就退出循环。最后,我们使用window.close()方法关闭窗口。
当然,我们还可以通过PySimpleGUI库的各种功能和组件来进一步定制和优化GUI程序,例如添加菜单、滚动条、图像等等。此外,PySimpleGUI还支持多种主题和风格,可以根据不同的需求和场景进行选择和调整。
https://github.com/PySimpleGUI/PySimpleGUI
7.Shap
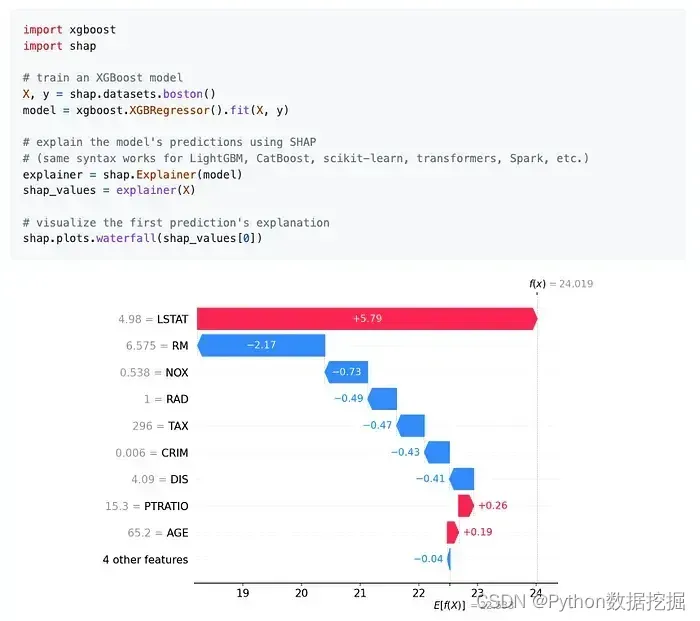
shap是一个用于可解释机器学习的Python库,它提供了一些可视化工具和计算方法来解释和理解机器学习模型的预测结果。下面我将按照使用场景和入门案例的结构来介绍该库。
使用场景:
shap 库通常应用于以下场景:
- 可解释机器学习:使用 shap 可以更好地理解和解释机器学习模型的预测结果,从而提高模型的可解释性和可信度。
- 特征重要性评估:shap可以计算出每个特征对模型预测的贡献度,从而评估特征的重要性,这对于特征选择和特征工程有很大的帮助。
- 模型优化和改进:通过分析 shap 值,我们可以发现模型预测中存在的错误和偏差,并针对性地进行优化和改进。
如何使用:
下面是一个简单的入门案例,以演示如何使用shap库解释和理解机器学习模型的预测结果:
# 导入需要的库和数据集
import xgboost
import shap
import pandas as pd
X,y = shap.datasets.iris()
# 训练一个XGBoost分类器
model = xgboost.train({"learning_rate": 0.01}, xgboost.DMatrix(X, label=y), 100)
# 计算特征重要性和shap值
explainer = shap.Explainer(model)
shap_values = explainer(X)
# 可视化shap值
shap.plots.beeswarm(shap_values)
以上代码的执行结果是计算并可视化shap值,如下图所示:
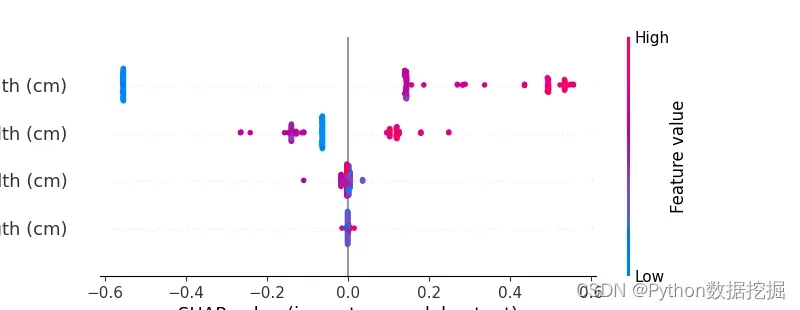
在这个例子中,我们首先导入需要的库和数据集,包括xgboost、shap和iris数据集。然后,我们训练了一个XGBoost分类器,并使用shap.Explainer计算出特征重要性和shap值。最后,我们使用shap.plots.beeswarm方法可视化shap值,其中每个点表示一个样本,横坐标表示特征的shap值,纵坐标表示样本在数据集中的索引。
通过这个例子,我们可以看到shap库可以非常方便地计算和可视化机器学习模型的可解释性信息,例如特征重要性和shap值。此外,shap还提供了许多其他的可视化和计算方法,例如force plot和dependence plot,可以进一步帮助我们理解和解释机器学习模型的预测结果。
https://github.com/slundberg/shap
结束
到这里,本篇文章就介绍完了,这七个库的使用场景各不相同,但都有着很高的实用价值和广泛的应用范围。如果你正在寻找Python库来帮助你解决不同的数据分析和处理问题,那么这些库肯定值得你一试。
文章出处登录后可见!