众所周知,Stable Diffusion扩散模型的训练和推理非常消耗显卡资源,我之前也是因为资源原因一直没有复现成功。
而最近我在网上搜索发现,亚马逊云科技最近推出了一个【云上探索实验室】刚好有复现Stable Diffusion的活动,其使用亚马逊AWS提供的Amazon SageMaker机器学习平台,为快速构建、训练和部署机器学习模型提供了许多便利的工具和服务,我也是深入体验了一番。
通过使用,从资源量、下载速度、安装速度、复现便捷性、文档、服务上的体验感都是非常不错,下面分享这篇复现博客给大家。
一、介绍
1.1、文本生成图像工作简述
如果我们的计算机视觉系统要真正理解视觉世界,它们不仅必须能够识别图像,而且必须能够生成图像。文本到图像的 AI 模型仅根据简单的文字输入就可以生成图像。
用户可以输入他们喜欢的任何文字提示——比如,“一只可爱的柯基犬住在一个用寿司做的房子里”——然后,AI就像施了魔法一样,会产生相应的图像。文本生成图像(text-to-image)即根据给定文本生成符合描述的真实图像,其是多模态机器学习的任务之一,具有巨大的应用潜力🔥,如视觉推理、图像编辑、视频游戏、动画制作和计算机辅助设计。
1.2、Stable Diffusion 模型原理分析
文本生成图像中的扩散模型是一种将文本转化为图像的重要框架,它结合了分数阶扩散方程和卷积神经网络(CNN)的思想。这个方法的核心思想是将文本作为扩散源,通过扩散过程将文本信息传递到整个图像中,从而生成一张图像。
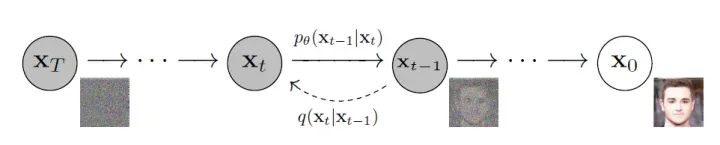
具体来说,文本生成图像中的扩散模型首先将文本转化为一个初始的激活图像,然后使用分数阶扩散方程描述扩散过程。在这个模型中,扩散过程可以理解为从激活图像的中心开始向周围扩散,每个像素点的扩散速度取决于该像素点与中心的距离和文本信息的权重。通过不断迭代扩散过程,激活图像逐渐扩散到整张图像中,从而生成一张与文本相关的图像。
而Stable Diffusion是Diffusion Model的一次巨大飞跃,Stable Diffusion扩散模型是一种基于稳定分布的扩散过程模型。它是基于分数阶偏微分方程(Fractional Partial Differential Equation, FPDE)的扩散方程,其中分数阶导数表示了非局部扩散性质。Stable Diffusion扩散模型采用了分数阶导数运算,相比传统的整数阶导数运算,它更加适用于描述具有长尾分布的数据。分数阶导数具有记忆效应,即某个时刻的扩散速度受到之前所有时刻扩散速度的影响,这使得stable扩散模型可以更好地描述扩散过程中的长时间记忆效应。
1.3、Amazon SageMaker机器学习平台
Amazon SageMaker机器学习平台提供了一系列工具和服务能够快速构建、训练和部署机器学习模型,使机器学习工作流程更加高效、易用和可扩展,从而降低了机器学习的入门门槛,使更多的开发人员能够从中受益,而且其可以免费试用,经过体验后,我总结了以下几点:
快速建模和训练🚀:Amazon SageMaker提供了一些内置的算法和预置的机器学习环境,使开发人员可以快速构建和训练自己的模型,无需关注底层的计算和数据管理。
高度可扩展🍒:Amazon SageMaker支持水平扩展和自动缩放,可以处理大规模数据集和高并发的请求,从而保证了系统的可用性和性能。
丰富的工具和服务👑:Amazon SageMaker提供了一系列的工具和服务,例如自动调参、模型解释、端点部署等,使开发人员能够更加轻松地管理和监控他们的机器学习工作流程。
易于集成🌷:Amazon SageMaker可以轻松地与其他AWS服务集成,例如Amazon S3、Amazon Cloud9、Amazon Lambda等,从而使开发人员可以更加便捷地进行数据管理和自动化部署。
可扩展的部署选项🍎:Amazon SageMaker提供了多种部署选项,包括托管式终端节点、自定义容器和本地部署,可以根据不同的场景和需求进行选择。
二、实验一:基于 Amazon SageMaker 复现Stable Diffusion
2.1、创建Amazon SageMaker实例
之前没有接触过AWS的同学可以查看:实验手册
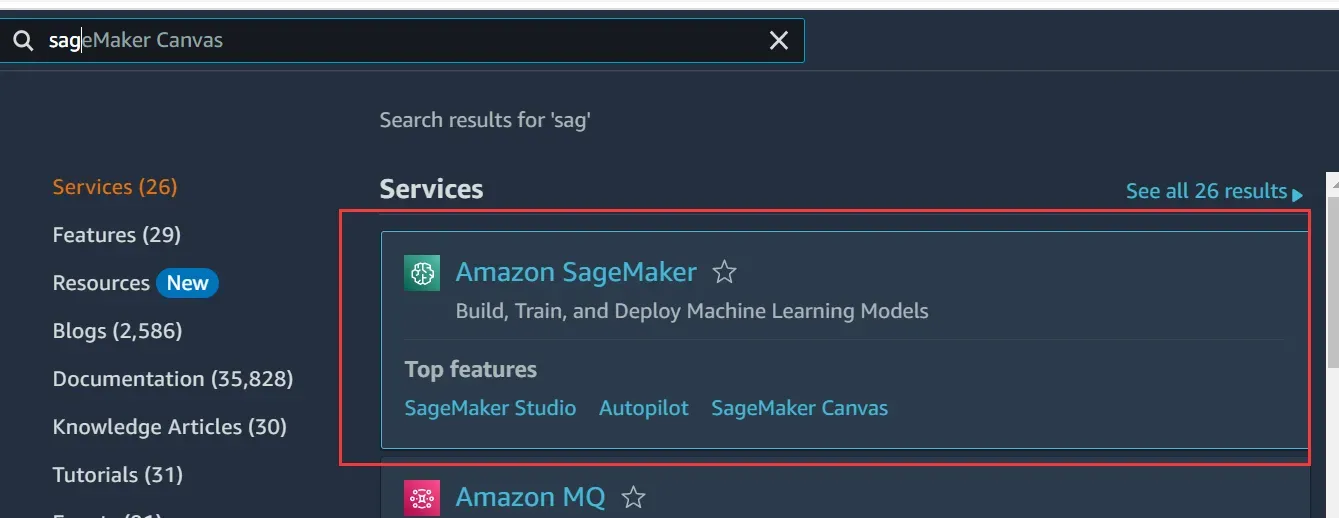
1、首先打开亚马逊云控制台,在查找服务处搜索关键词SageMaker,进入Amazon SageMaker环境:
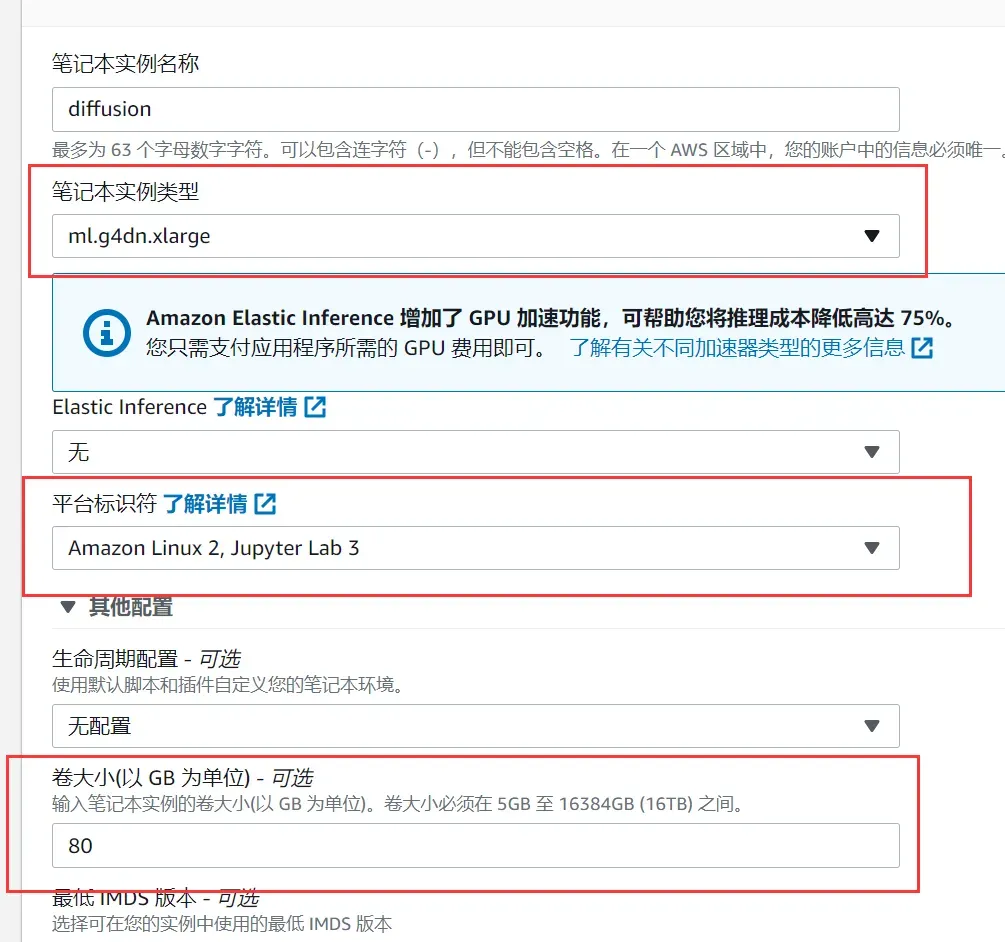
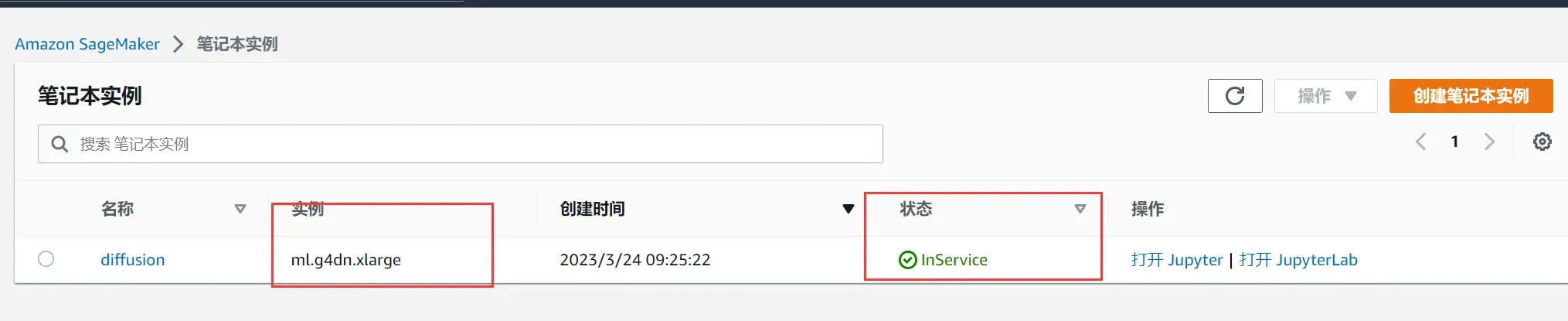
2、在左侧找到笔记本,点击笔记本–笔记本实例–创建笔记本实例,进入以下选项,笔记本实例类型是需要申请的资源类型,可以看到Amazon SageMaker给我们提供了很多类型资源,我们选择加速型g4dn.xlarge,在平台上我们选择熟悉的Linux和Jupyter,卷大小也就是存储空间,可以随意选择但不宜小于20GB。
3、创建好后,我们在列表中就可以看到对应实例了,跟我们在其他云服务器中使用差不多,Amazon SageMaker也给我们提供了熟悉的Jupyter notebook。
2.2、配置代码与环境
我们点击打开Jupyter页面,进入对应实例,选择右侧upload,上传Notebook代码,代码下载链接:
https://static.us-east-1.prod.workshops.aws/public/73ea3a9f-37c8-4d01-ae4e-07cf6313adac/static/code/notebook-stable-diffusion-ssh-inference.ipynb,先下载到本机,再上传到笔记本实例当中,上传成功后,点击打开:

在第一次进入时,系统会自动跳出提示,让你选择对应kernel,我们选择conda_pytorch_p39核,并点击set kernel
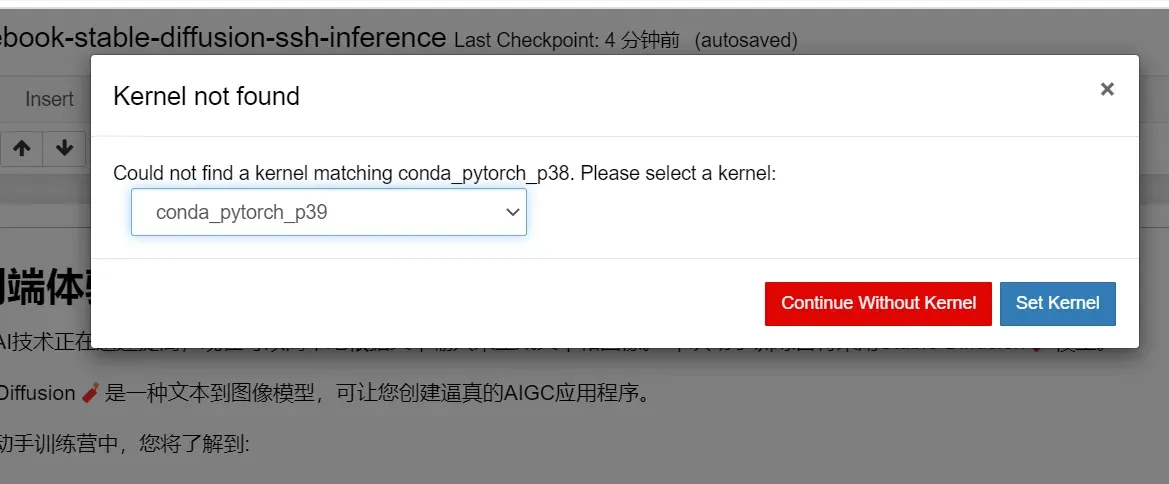
由于这个Diffusion Model的Amazon SageMaker Jupyter文件已经为我们写好了所有配置步骤,环境安装,我们直接点击Run
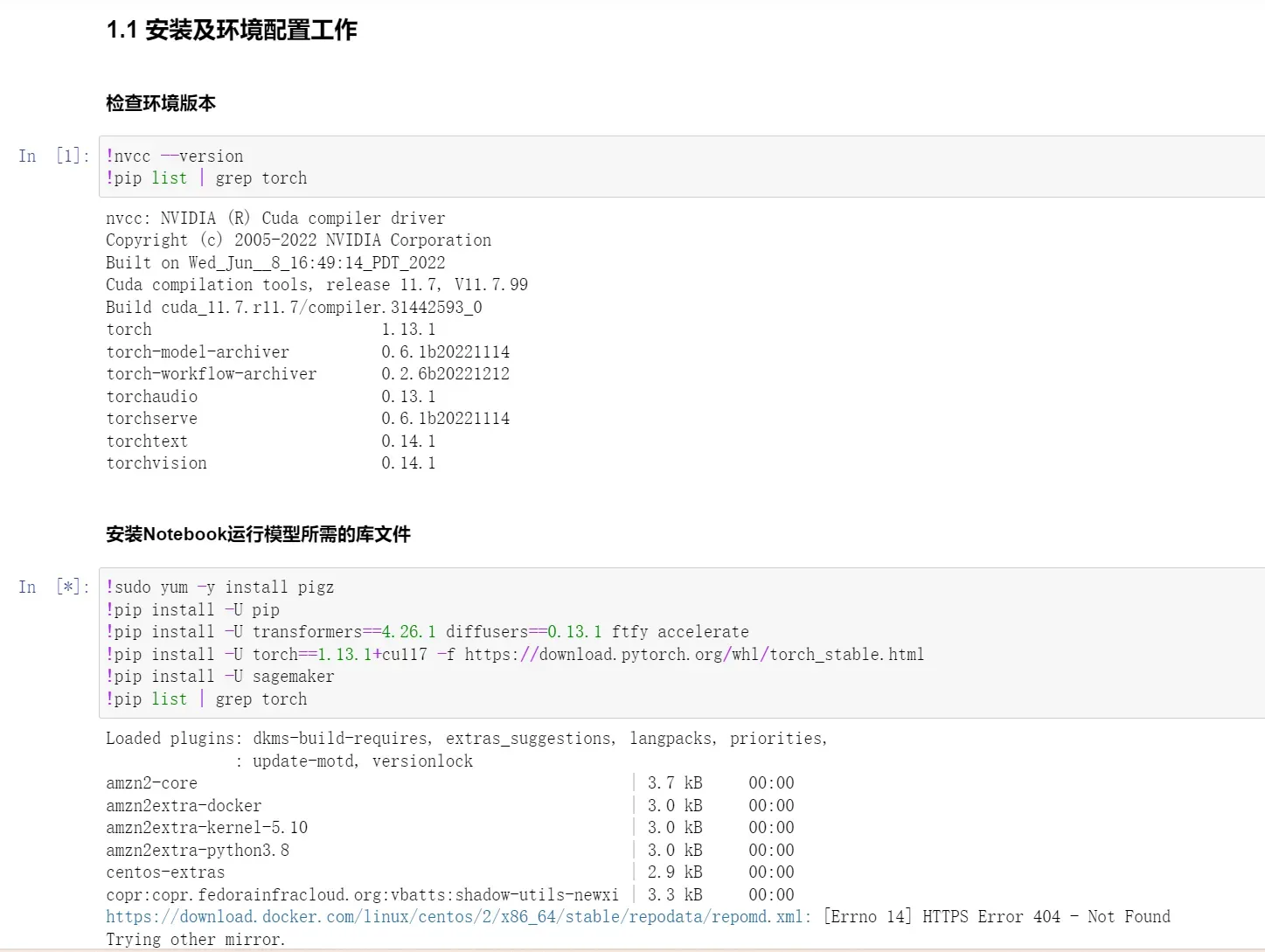
分析一下,该代码文件包含以下内容:
在笔记本实例中下载并测试AIGC模型文件
编写模型推理入口代码,打包模型文件,并上传至S3桶
使用代码部署模型至Amazon SageMaker Inference Endpoint
(可选)使用会话管理器连接至Amazon SageMaker Inference Endpoint进行远程调试
2.3、复现Stable Diffusion
通过上面的运行,已经将代码部署模型至Amazon SageMaker Inference Endpoint,从而可以基于推理终端节点生成自定义图片,我们在juypter notebook的最后,加上这样一段代码,我们将想要生成的句子可以写在prompt里面。
from PIL import Image
from io import BytesIO
import base64
# helper decoder
def decode_base64_image(image_string):
base64_image = base64.b64decode(image_string)
buffer = BytesIO(base64_image)
return Image.open(buffer)
#run prediction
response = predictor[SD_MODEL].predict(data={
"prompt": [
"A cute panda is sitting on the sofa",
"a photograph of an astronaut riding a horse",
],
"height" : 512,
"width" : 512,
"num_images_per_prompt":1
}
)
#decode images
decoded_images = [decode_base64_image(image) for image in response["generated_images"]]
#visualize generation
for image in decoded_images:
display(image)如上,我们试着生成一张可爱的熊猫坐在沙发上面,一个宇航员在骑马,等待几秒钟后,推理完成,得到如下结果:


三、实验二:基于Vue3 +AWS Cloud9搭建一款文本生成图像Web应用
通过上面的实践,通过Amazon SageMaker的强大算力加持,我们已经成功训练好了Diffusion Model模型并保存了推理入口,但是光光只能在代码中调用不够,下面我们通过Vue3+Flask通过调用模型来搭建一款简单的文本生成图像demo。
3.1、在 AWS Cloud9 创建后端 Flask服务
亚马逊为我们提供了一种和VScode Web版相同的基于云的集成开发环境 (IDE):AWS Cloud9,我们首先在搜索栏搜索到Cloud9,点击新建一个云环境:
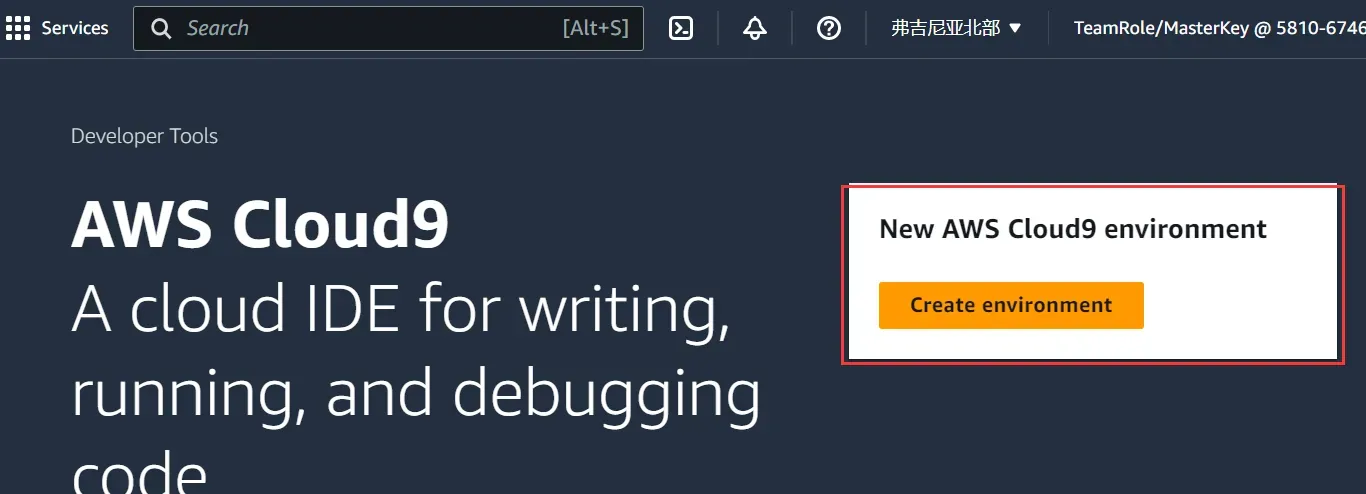
创建好之后,我们可以在Environments中打开Cloud9IDE
与VS Code Web类似,AWS Cloud9包括一个代码编辑器、调试程序和终端,并且预封装了适用于 JavaScript、Python、PHP 等常见编程语言的基本工具,无需安装文件或配置开发计算机,即可开始新的项目。
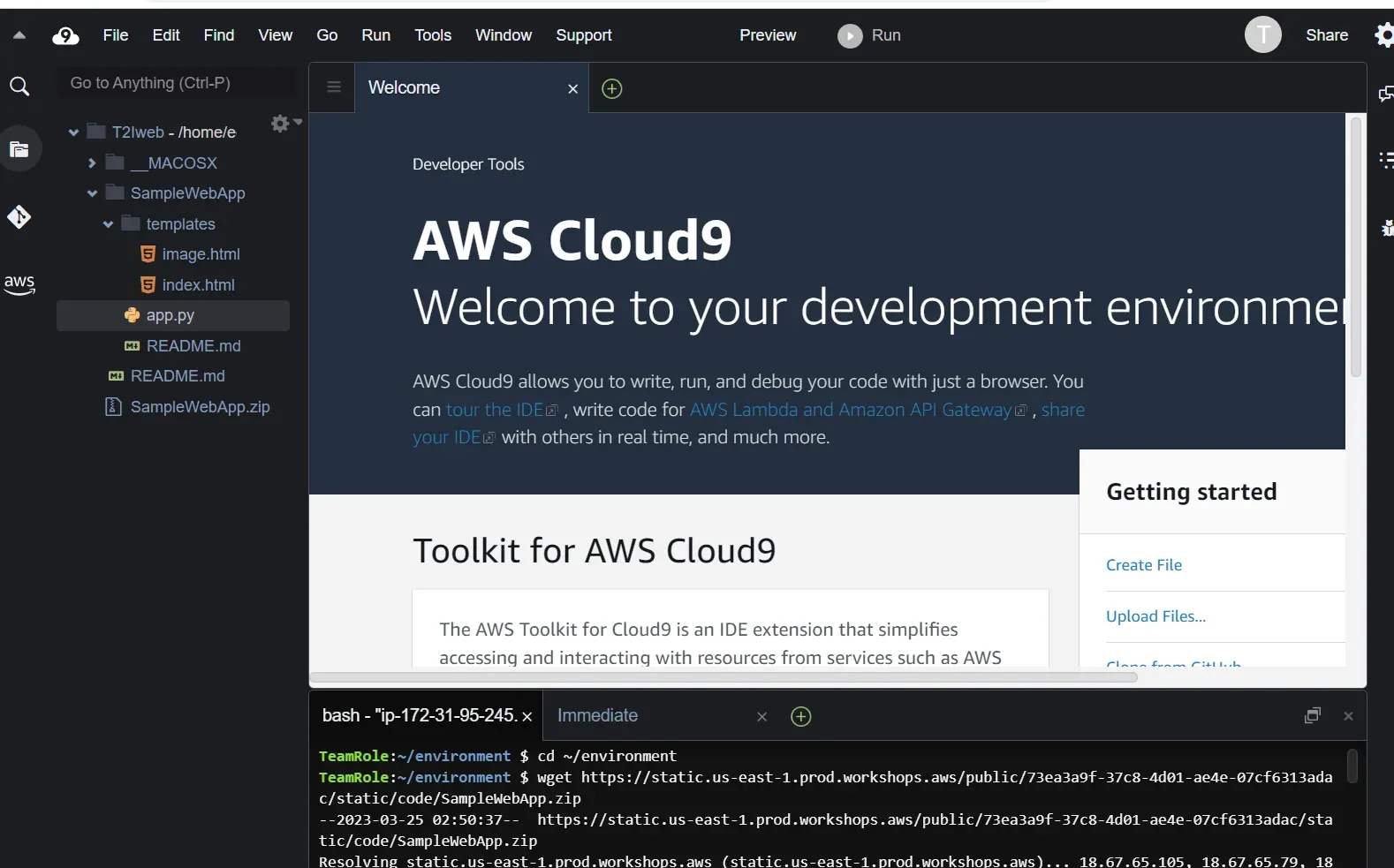
在下面的终端,我们输入以下代码,下载并解压SampleWebApp文件夹
cd ~/environment
wget https://static.us-east-1.prod.workshops.aws/public/73ea3a9f-37c8-4d01-ae4e-07cf6313adac/static/code/SampleWebApp.zip
unzip SampleWebApp.zip该文件夹包含以下内容:
后端代码 app.py:接收前端请求并调用 SageMaker Endpoint 将文字生成图片。
两个前端html文件 image.html 和 index.html。
要运行此后端服务,首先需要安装相应环境,使用pip3安装Flask和boto3环境:
pip3 install Flask
pip3 install boto3安装成功之后,点击左侧的app.py文件,点击 AWS Cloud9 上方的 Run 按钮运行代码,这样代码就可以调用Amazon Simple Storage Service (Amazon S3)中已经保存好的endpoint进行文本生成图像推理,运行如下:
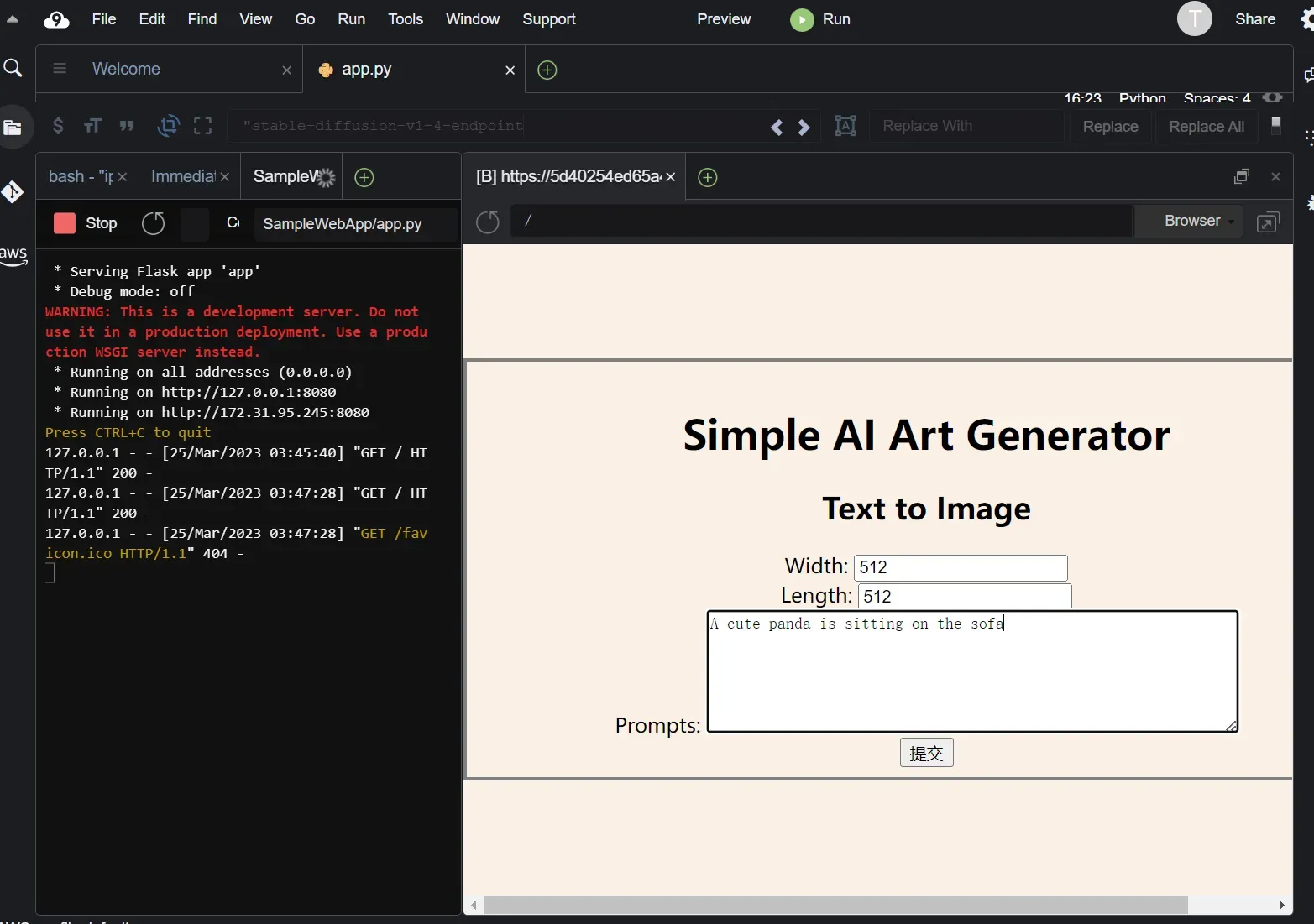
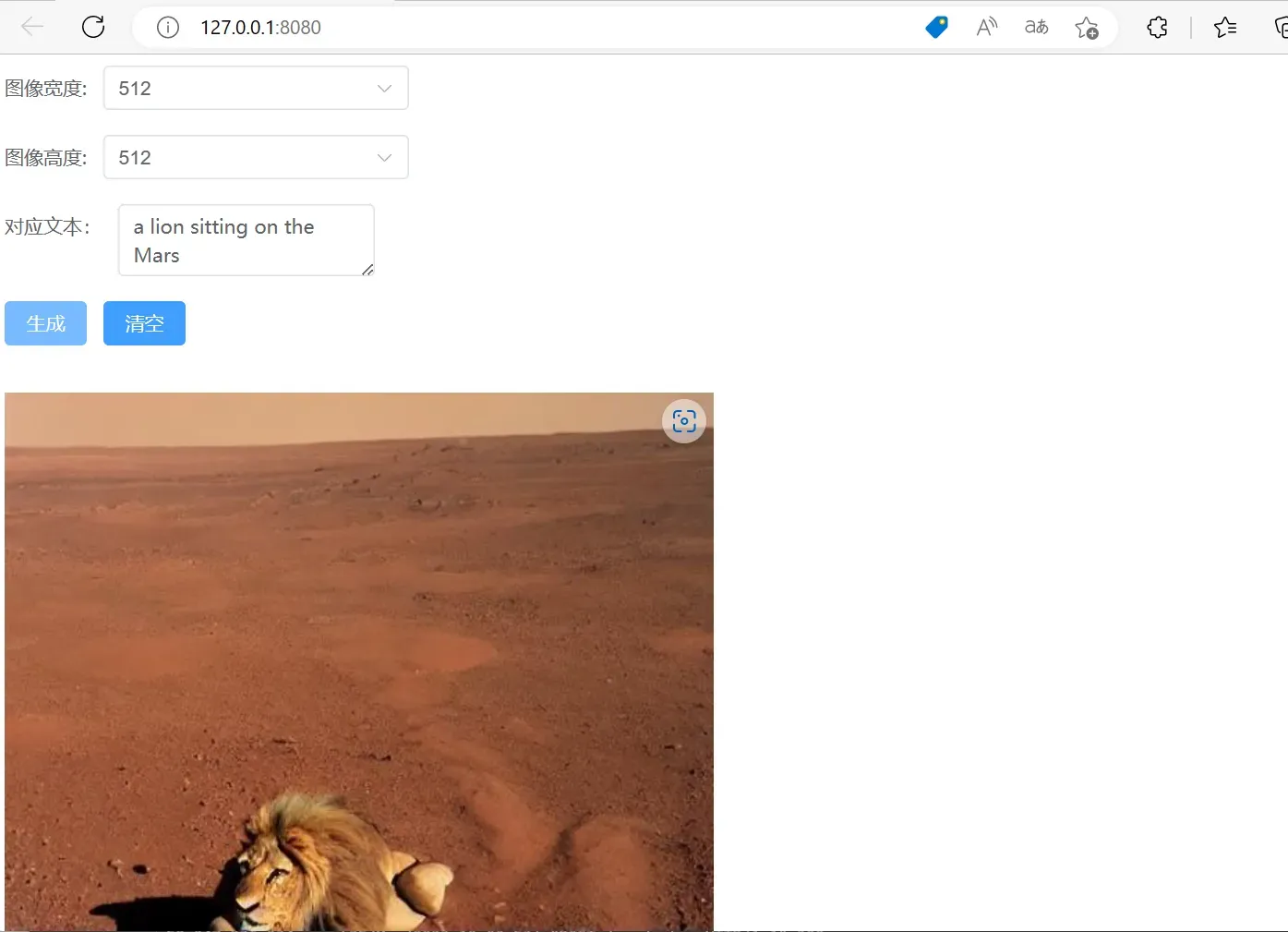
左侧可以看到后台为前端提供了8080端口,右侧前端页面提供了简单的demo,width和length代表输出图像的长宽,prompt为输入的文本,同样测试A cute panda is sitting on the sofa这条语句,成功输出:

3.2、在本机使用前端Vue搭建Web demo
光在服务器调用不过瘾,我们尝试在本机搭建一款Vue demo,然后调用AWS Cloud9的Flask服务。如果你不想从零开始搭建,可以使用git clone,克隆我上传的这个项目,然后直接跳到3.3继续实验流程。
git clone https://github.com/Heavenhjs/t2iweb-demo.git首先我们打开VSCode,输入npm create vite@latest用vite初始化一款Vue项目,分别选择Vue、TS作为技术栈:
初始化好后,输入npm i安装相应依赖,然后输入npm install element-plus –save和npm install axios安装element-plus、axios依赖

然后输入npm run dev启动项目,一个初始化项目就建好了:
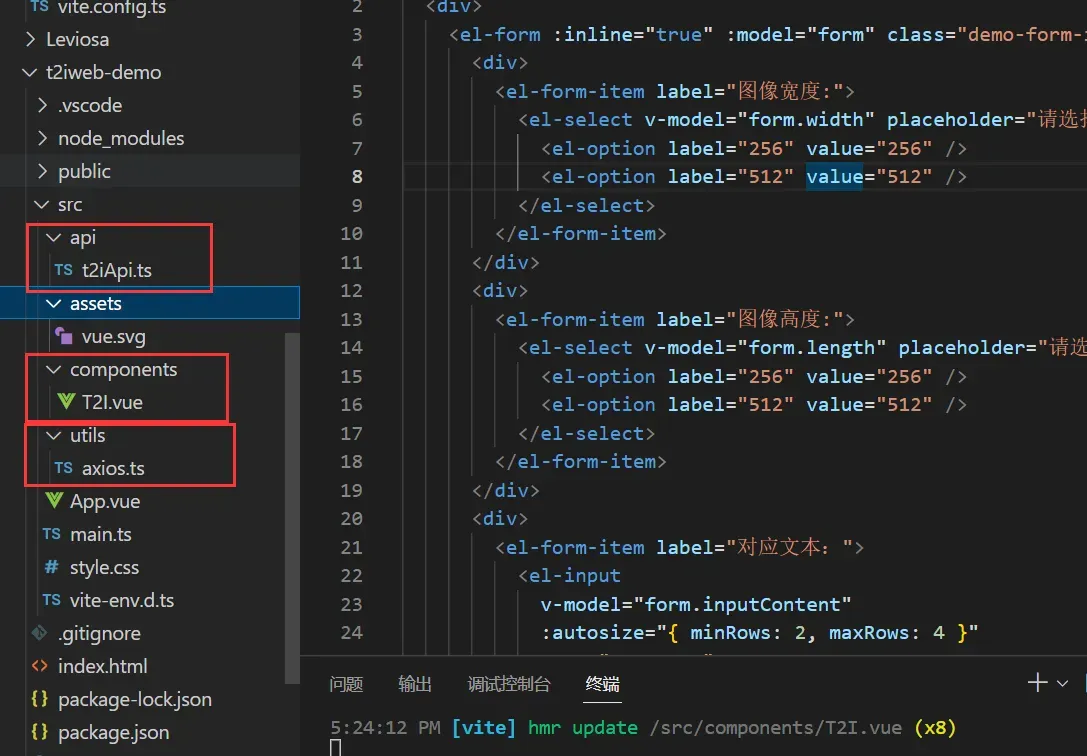
接下来,我们把原始给的东西清理一下,然后开始写一个demo,需要设计一个表单,然后在表单下方设计一个值专门用于渲染后端传回来的html富文本,项目结构设计的比较简单如下所示,api放的是调用后台flask服务的接口,components里做了一个T2I的组件,utils里是封装的axios服务,另外还需要在vite.config.ts里配置跨域。
主要代码如下:
// T2I.VUE
<template>
<div>
<el-form :inline="true" :model="form" class="demo-form-inline">
<div>
<el-form-item label="图像宽度:">
<el-select v-model="form.width" placeholder="请选择">
<el-option label="256" value="256" />
<el-option label="512" value="512" />
</el-select>
</el-form-item>
</div>
<div>
<el-form-item label="图像高度:">
<el-select v-model="form.length" placeholder="请选择">
<el-option label="256" value="256" />
<el-option label="512" value="512" />
</el-select>
</el-form-item>
</div>
<div>
<el-form-item label="对应文本:">
<el-input
v-model="form.inputContent"
:autosize="{ minRows: 2, maxRows: 4 }"
type="textarea"
placeholder="请输入想要生成的文本"
/>
</el-form-item>
</div>
<el-form-item>
<el-button type="primary" @click="onSubmit">生成</el-button>
<el-button type="primary" @click="onClean">清空</el-button>
</el-form-item>
</el-form>
</div>
<p v-html="image"></p>
</template>
<script setup lang="ts">
import { reactive, ref } from "vue";
import { T2I } from "../api/t2iApi";
const form = reactive({
inputContent: "",
width: "",
length: "",
});
let image = ref("<p>请输入信息后,点击生成</p>");
const onSubmit = () => {
console.log("submit!");
T2I(form).then((res: any) => {
console.log(res.data);
image.value = res.data;
});
};
const onClean = () => {
form.inputContent = "";
form.length = "";
form.width = "";
image.value = "<p>请输入信息后,点击生成</p>";
};
</script>
<style lang="less"></style>// t2iApi.ts
import axios from "../utils/axios";
/**
* @name 用户管理模块
*/
// 获取用户列表
const PORT1 = "/api";
// T2I
export const T2I = (parms: any) => {
const form = new FormData();
form.append("inputContent", parms.inputContent);
form.append("width", parms.width);
form.append("length", parms.length);
return axios.post(PORT1 + `/predictor`, form);
};3.3、使用Axios请求Cloud9的文本生成图像服务
为了安全,AWS Cloud9 分配给环境的预览标签页中的 URL,只能在当环境的 IDE 处于打开状态并且应用程序正在同一个 Web 浏览器中运行时才有用,所以我们要通过公网ip和端口号的方式暴露接口。
为此首先我们要为实例修改安全组,打开8080端口,允许其传输数据,这样才可以访问到后端写好的Flask服务,具体步骤可以看手册这一章:https://docs.aws.amazon.com/zh_cn/cloud9/latest/user-guide/app-preview.html
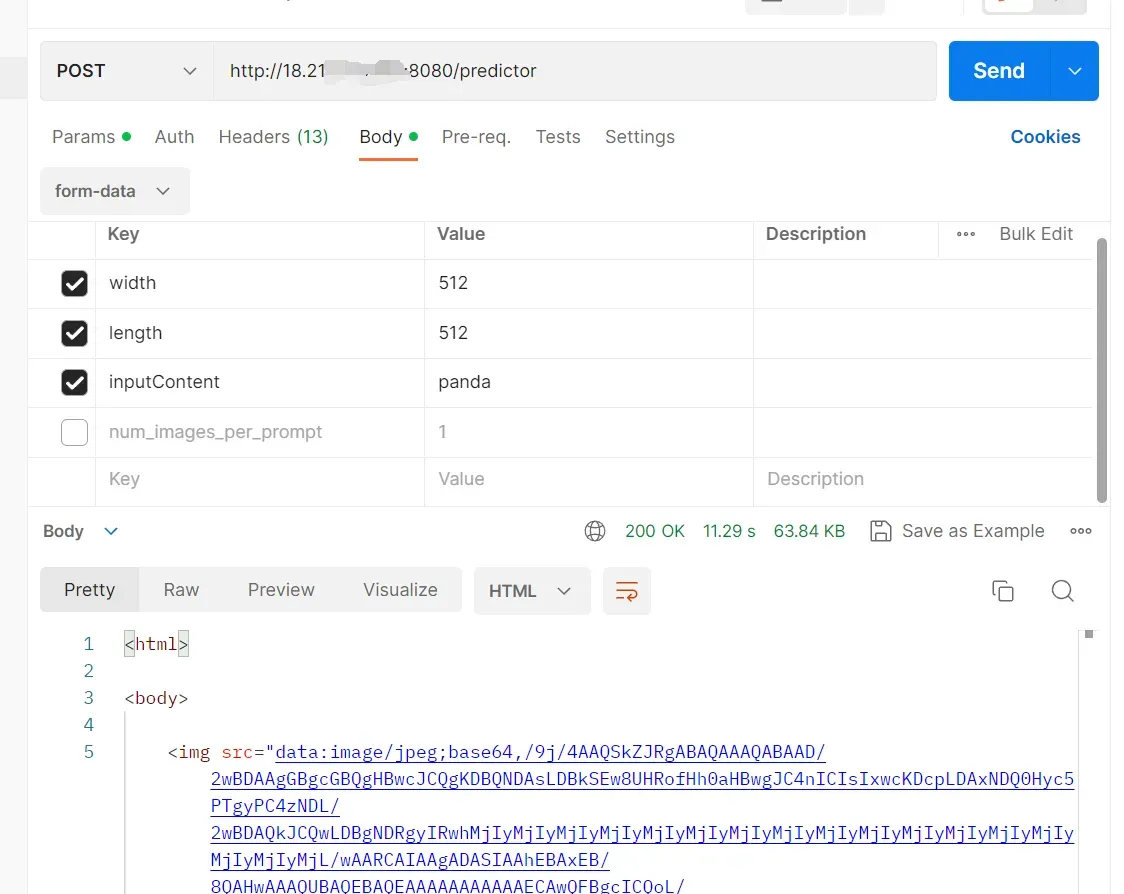
打开8080端口后,可以用Postman测试一下,在body里面,加入form-data,并输入对应的key和value,点击send发送,显示200,下方栏返回html且img当中有值,则配置成功:
成功之后,我们就可以使用Axios来请求Cloud9的服务,这就需要在前端配置一下接口的ip,打开vite.config.ts,其中target 需要改为自己ACL的公网ip+端口号,这样就可以在本机上调用到flask的服务啦!
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
// https://vitejs.dev/config/
export default defineConfig({
plugins: [vue()],
server: {
//服务器主机名
port: 8080,
open: true,
hmr: {
host: "127.0.0.1",
port: 5173,
},
// 代理跨域
proxy: {
"/api": {
target : "这里输入亚马逊网络对应ACL的公网ip+端口号如:http://18.222.222.222:8080",
changeOrigin: true,
// 将/api去掉
rewrite: (path: string) => path.replace(/^\/api/, ""),
},
},
},
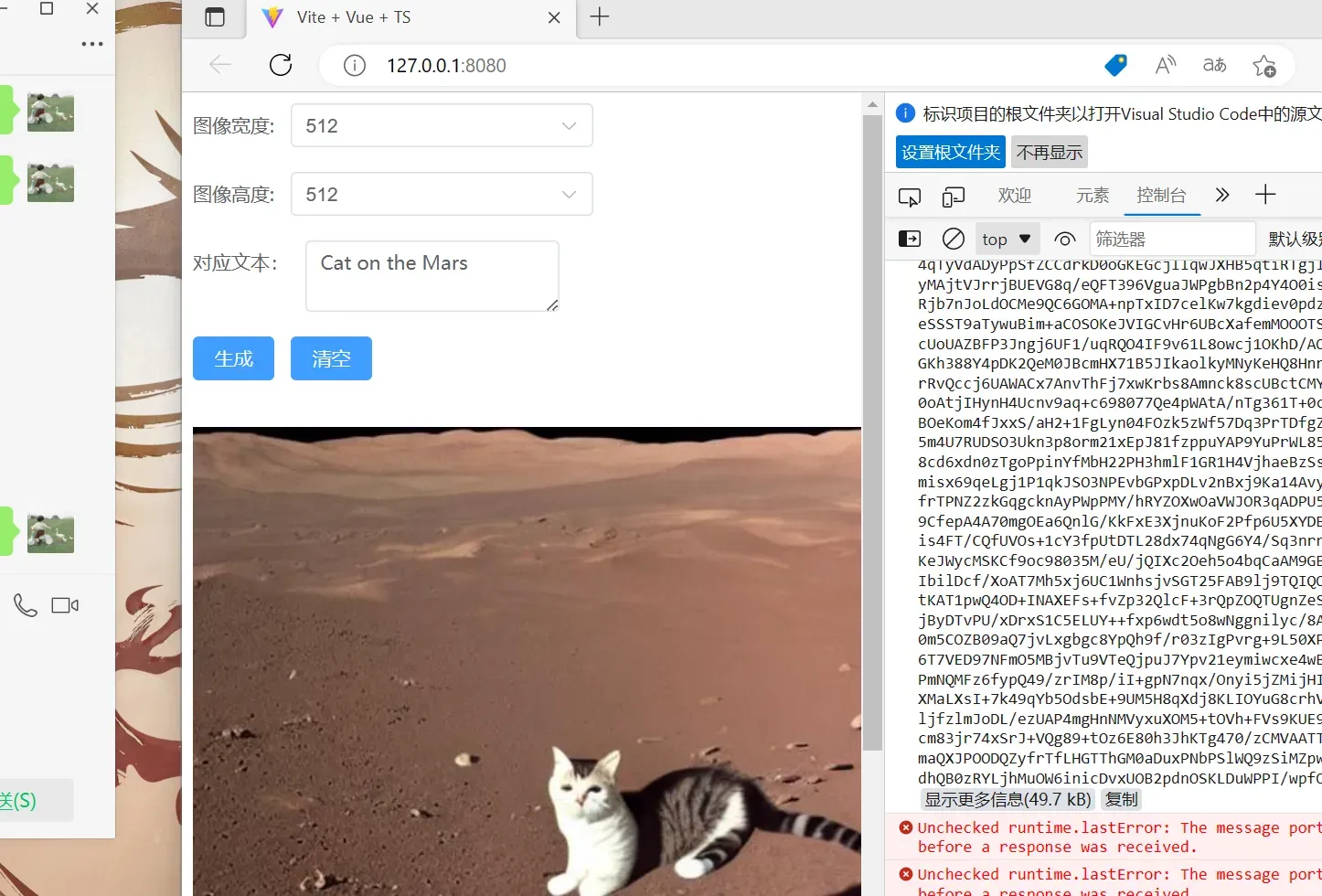
});最后输入”npm run dev”运行项目,效果如下:
3.4、避坑指南——注意事项和经验总结
问题1:配额不足或者无法申请配额
您的请求有问题。请参阅以下详细信息。User: arn:aws:sts::581067464334:assumed-role/TeamRole/MasterKey is not authorized to perform: servicequotas:ListAWSDefaultServiceQuotas with an explicit deny in an identity-based policy
解决方案:更换地区为美国东部
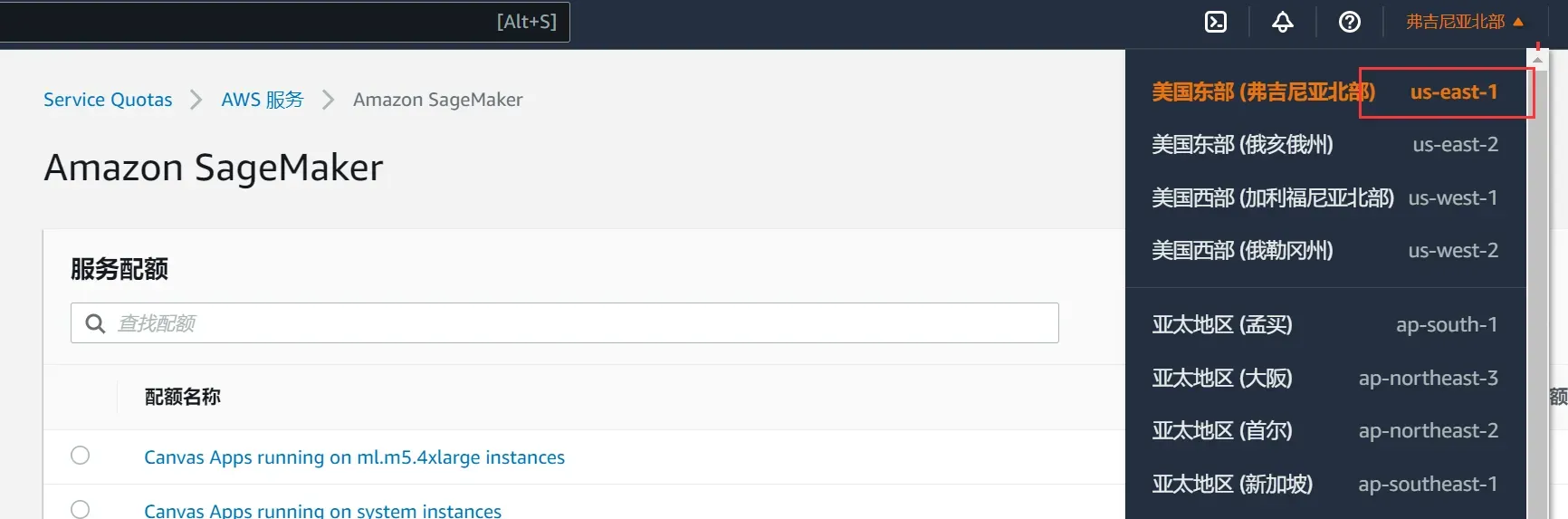
点击链接https://ap-northeast-1.console.aws.amazon.com/servicequotas/home/services/sagemaker/quotas进入配额列表,搜索:ml.g4dn.xlarge for endpoint usage,点击请求申请增加配额。

问题2:404错误
可能是公网ip和端口号不对,可能是安全组的准入规则没有设置对,认真看一下手册,打开8080端口或者更换其他端口。
问题3:500 Bad Request
Request传入的参数不对,检查一下表单输入的值和传输过去的数据是否符合规范,也有可能是后端flask服务断联了,重启一下flask服务就好了。
其他问题可以参考实验手册:https://dev.amazoncloud.cn/activity/activityDetail?id=638ea0193b67dd77d6cdb221&catagoryName=buildOn
四、 总结
4.1、Stable Diffusion模型的表现和局限性
经过体验,Stable Diffusion的效果着实惊艳到我,Stable Diffusion模型可以生成高质量的图像和文本,表现出色。它能够通过对初始随机噪声的迭代扩散,逐步生成细节更加丰富、更加逼真的样本。而在多样化方面,即使在输入的条件相同的情况下也能够产生不同的输出,这是由于Stable Diffusion模型使用的扩散过程是随机的,每次迭代生成的噪声都是不同的,这就给了其丰富的商业价值和艺术空间。
但是尽管Stable Diffusion模型有许多优点,但它也存在一些局限性:
计算资源消耗大:Stable Diffusion模型需要大量的计算资源来训练和生成样本。对于大规模的数据集和复杂的生成任务,需要更多的计算资源来保证模型的表现,幸运的是,Amazon SageMaker为我们提供了非常理想和便捷的计算资源,在体验过程中,着实为我解决了计算资源这一难题。
训练时间长:与其他生成模型相比,Stable Diffusion模型的训练时间较长,因为它需要在多个时间步骤上运行随机游走和扩散过程。这也会导致模型的可扩展性和实时性受到限制。
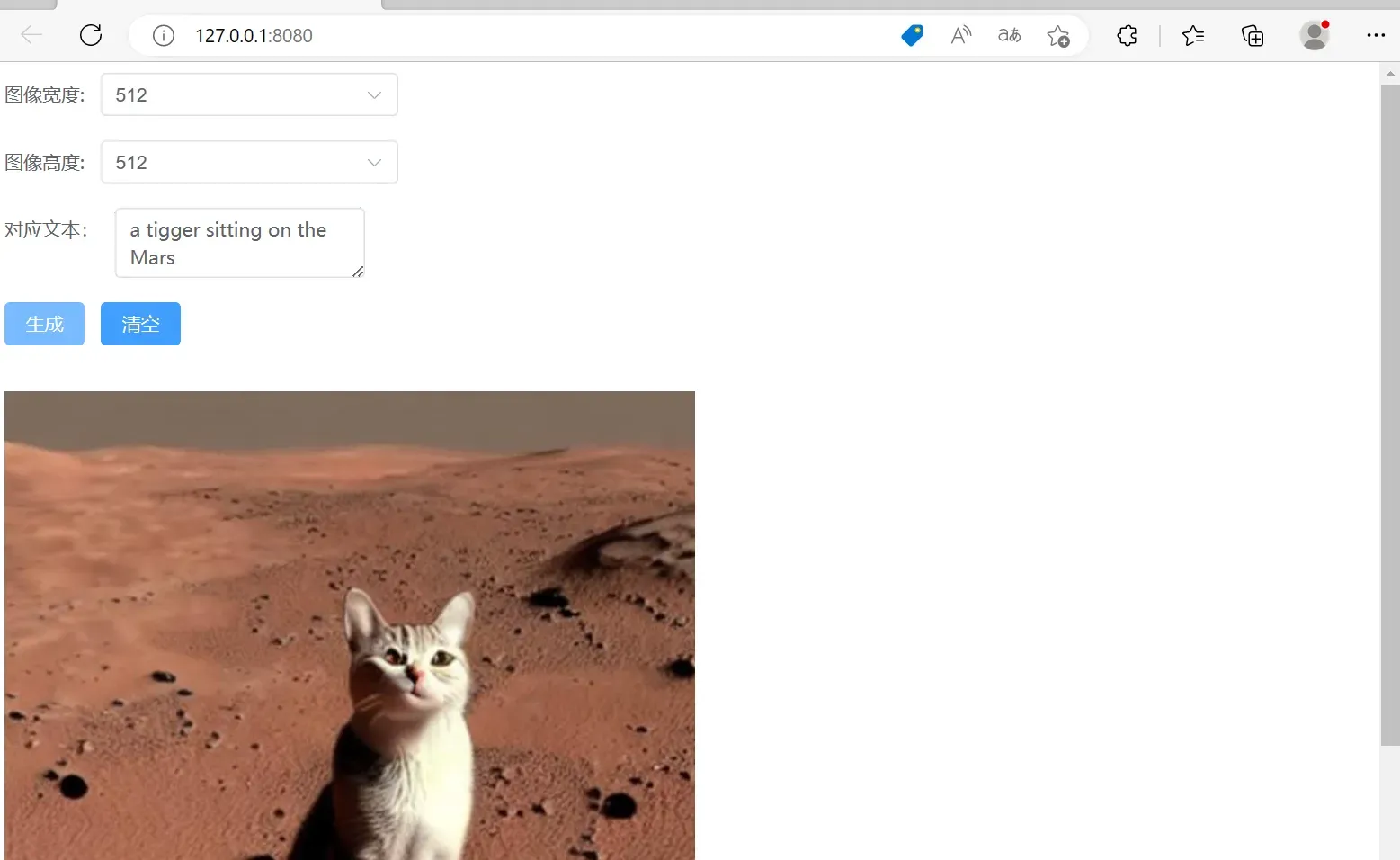
对噪声敏感:Stable Diffusion模型在生成样本时会受到噪声的影响,这可能导致生成的样本不够准确或存在不合理的部分。因此,需要对输入数据进行预处理和噪声消除来提高模型的性能。比如下面这一张,猫的脸部输出比较奇怪,扭曲在一起,图片也像是背景与前景的拼接,不太真实,这也是未来可以发展研究的重要方向之一。
4.2、Amazon SageMaker机器学习平台实践体验
Amazon SageMaker是AWS(亚马逊云服务)提供的一个全面托管的机器学习平台,其提供了许多便利的工具和服务,帮助开发人员快速构建、训练和部署机器学习模型。通过亲身实践,我有如下体验:
高速下载和库安装🔥:在使用Amazon SageMaker的过程中,我们可以明显地感受到其下载速度非常快,这可以极大地提高我们的工作效率。同时,在使用Amazon SageMaker安装库时,我们也可以感受到它的速度非常快,这让我们可以更加专注于模型的构建和训练,而不必耗费大量的时间在等待安装库上。
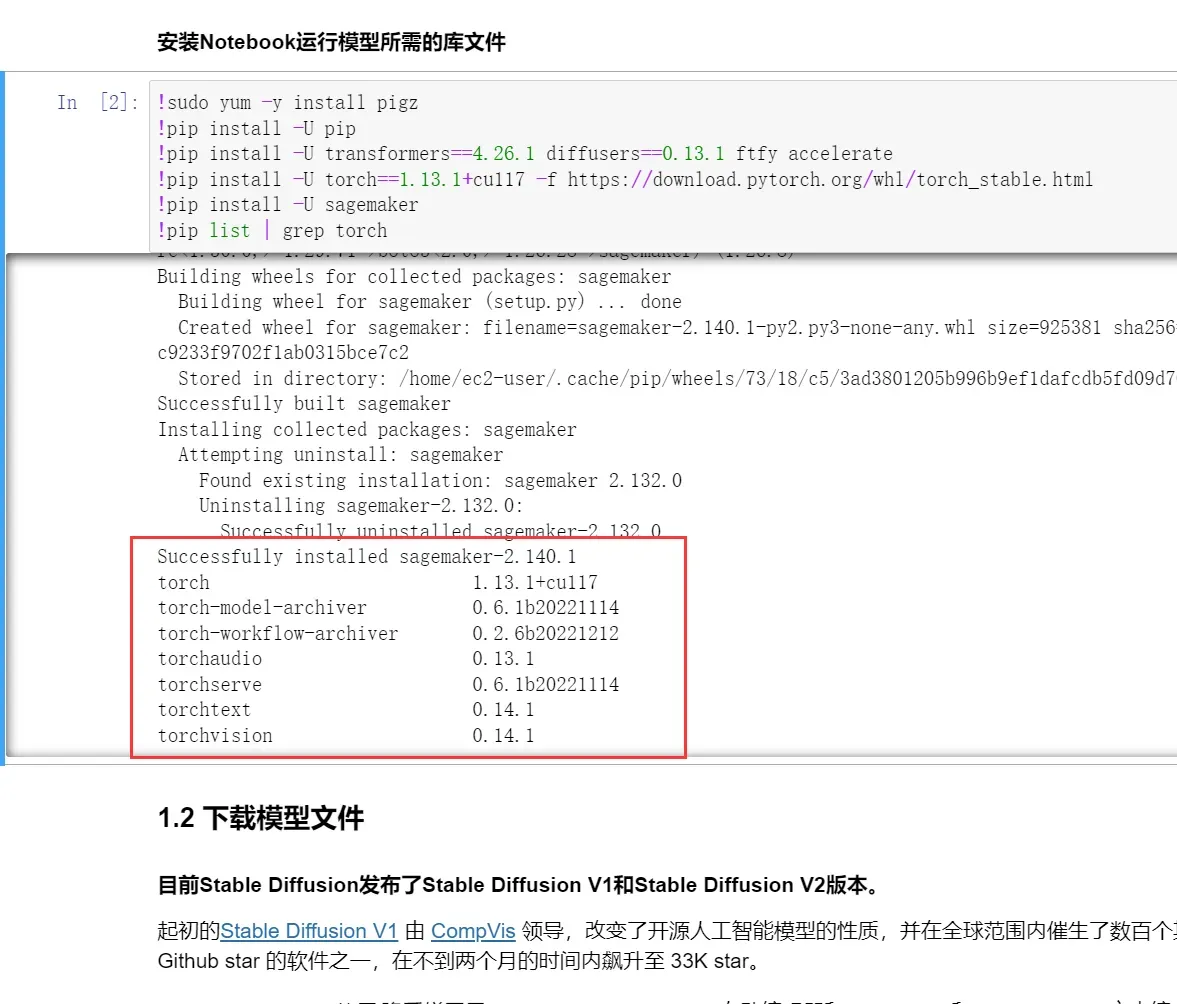
丰富的计算资源和配置💕:Amazon SageMaker提供了许多丰富的计算资源和配置选项,以满足不同规模和需求的机器学习项目。无论是小规模的数据集还是大规模的数据集,Amazon SageMaker都可以提供足够的计算资源,以支持训练大模型。同时,Amazon SageMaker也提供了各种配置选项,可以根据具体的项目需求进行灵活的设置。
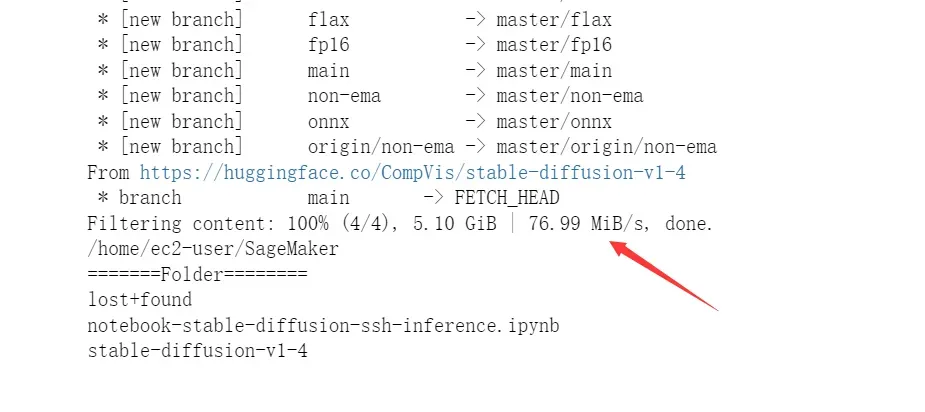
惊人的文件读写速度✈:Amazon SageMaker提供了高效的文件系统和存储选项,在使用中,仅仅不到两分钟,Amazon SageMaker就成功写入并保存了4.57GB的模型。此外,Amazon SageMaker还支持多种数据源和格式,包括Amazon S3、Amazon EBS和Amazon FSx,使数据管理和访问变得更加方便和灵活。

丰富的工具和服务🎯:Amazon SageMaker提供了许多强大的工具和服务,以帮助开发人员更加高效地管理和监控机器学习工作流程。例如,Amazon SageMaker提供了自动调参、模型解释、端点部署等功能,这些功能可以大大提高我们的工作效率和模型的准确性。
与其他AWS服务的完美集成🍭:Amazon SageMaker可以与其他AWS服务(如S3、Cloud9等)完美集成,以便更加方便地管理数据和进行自动化部署。这意味着我们可以将数据从S3传输到Amazon SageMaker中,使用Cloud9进行代码开发,然后将训练后的模型部署到Amazon SageMaker的终端节点中,这一切都可以在Amazon SageMaker平台上方便地完成。
五、云上探索实验室
AWS正在开展云上探索实验室活动,云上探索实验室是为开发者打造的一项创新性云计算产品体验,旨在帮助开发者更好地了解和应用云计算技术,通过云上探索实验室,开发者可以学习实践云上技术,不仅是一个很好的体验空间,更是一个非常好的分享平台,正好其中有很多AIGC实例和视频教程,想要体验的朋友们,不容错过!
活动链接:https://dev.amazoncloud.cn/experience

文章出处登录后可见!