一、功能(解决问题)
1.根据文字生成图片

2.根据给定的图片生成相似风格画作

3.图片延展
二、发展过程
1.2015年斯坦福大学四位研究者提出
2.2020年底加州伯克利学者改进
3.2021年OpenAI结合CLIP做了进一步优化,实现了诸多AI作画功能
三、应用:Dalle2(2021-2022)
目前非常火爆的AI作画工具。
四、类比(图像生成模型)
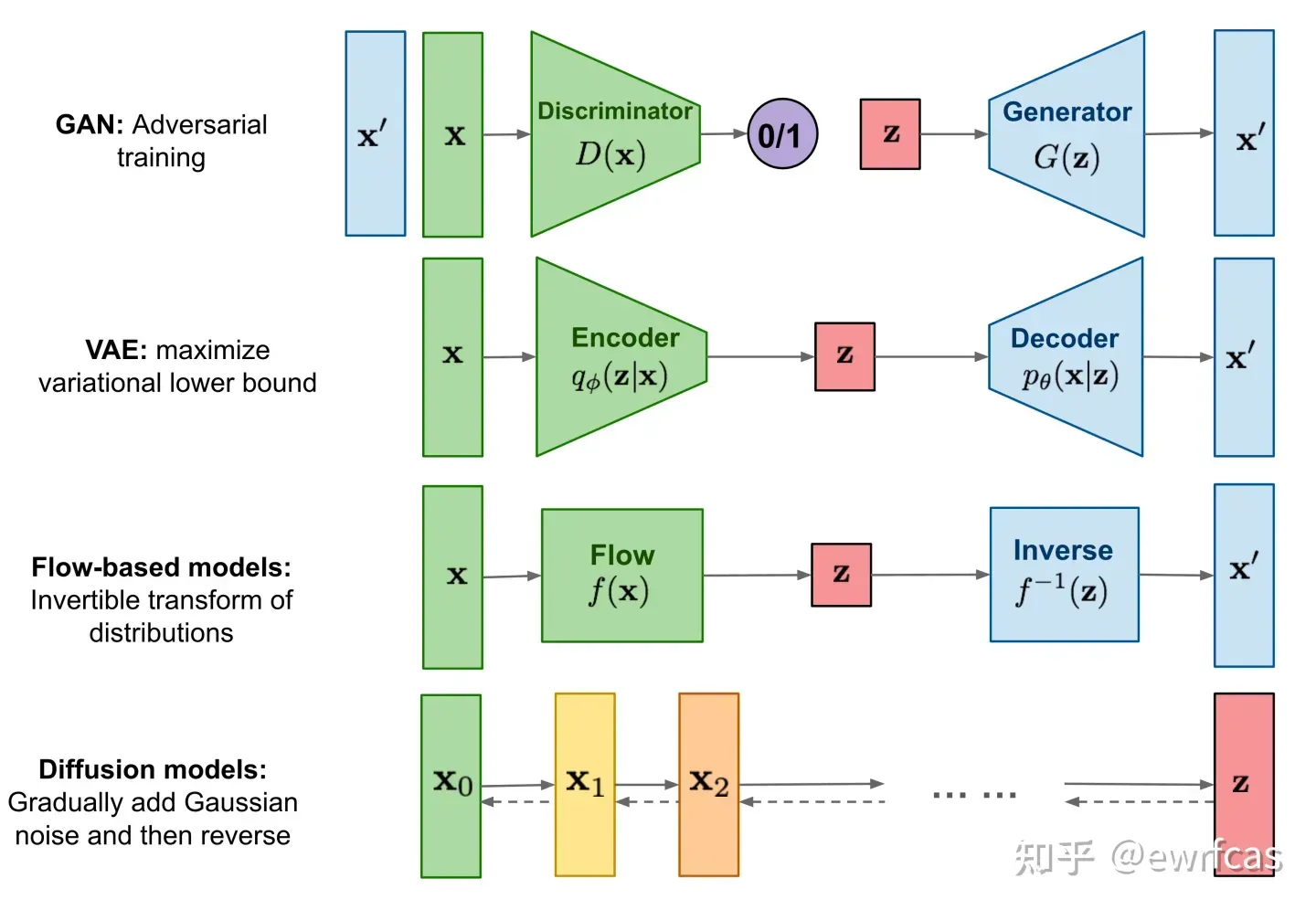
当前有四大生成模型:生成对抗模型、变微分自动编码器、流模型以及扩散模型。扩散模型(diffusion models)是当前深度生成模型中新SOTA(State of the art)。扩散模型在图片生成任务中超越了原SOTA:GAN,并且在诸多应用领域都有出色的表现。
1.生成对抗网络(GAN)【生成器+判别器】
主要和GAN做一个对比,目前主流的为Diffusion,原因如下。
1)GAN要训练双网络,难度较大,容易不收敛,多样性差(训练生成器),关注方向为骗过判别器(关注点偏)。
2)Diffusion网络方式更简单,GAN不好观察损失。
2.变微分自编码器(VAE)
3.流模型(Flow-based model)
五、原理:扩散现象
物理:物质分子从高浓度向低浓度区域转移,直到均匀分布。
AI:由熵增定律驱动,先给一幅图片增加噪声,让其变得极其混乱,再训练AI把混乱的照片变回有序(实现图片生成)。
六、实现方式

1.前向过程(加噪)
1)不断往输入数据中增加噪声,最后变为纯噪声(#噪声(Noise):是真实标记与数据集中的实际标记间的偏差。)。
2)每一个时刻都要增加高斯噪声,后一时刻都是前一时刻增加噪声得到。
3)这个过程可以看做不断构建标签的过程。

使用马尔科夫链进行的前向扩散过程,通过每次加入一点噪声生成一个样本

高斯分布:
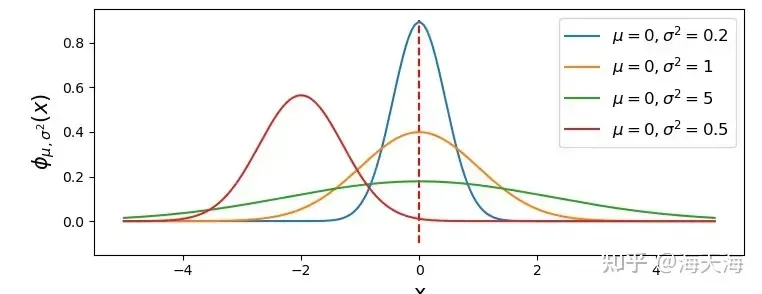
前向过程是不断加噪的过程,加入的噪声随着时间步增加增多,根据马尔可夫定理,加噪后的这一时刻与前一时刻的相关性最高也与要加的噪音有关(是与上一时刻的影响大还是要加的噪音影响大,当前向时刻越往后,噪音影响的权重越来越大了,因为刚开始加一点噪声就有效果,之后要加噪声越来越多 )

2.反向过程(去噪)
从一个随机噪声开始,逐步还原成不带噪音的原始图片——去噪过程,逆向过程其实时生成数据的过程。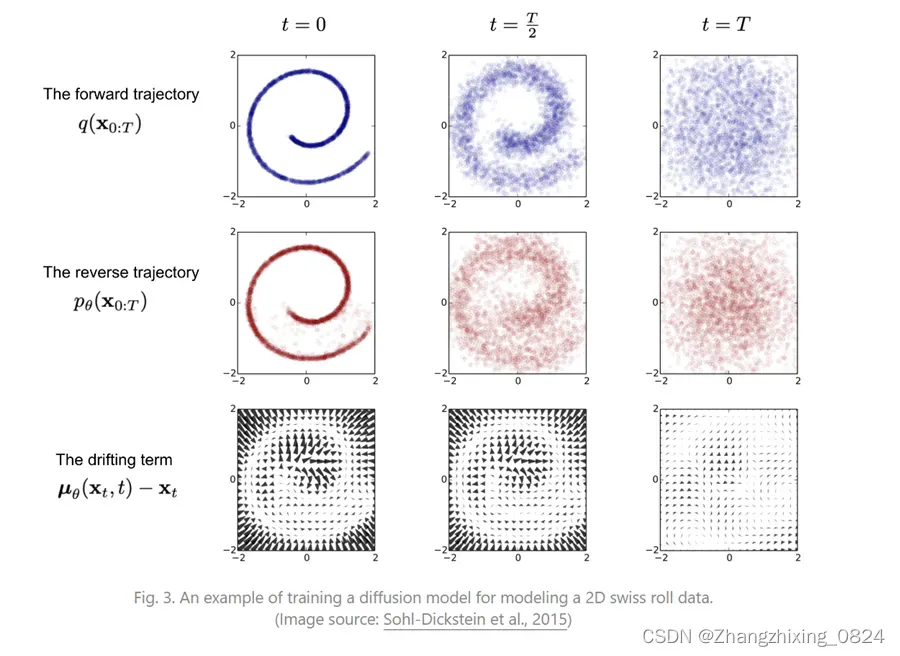
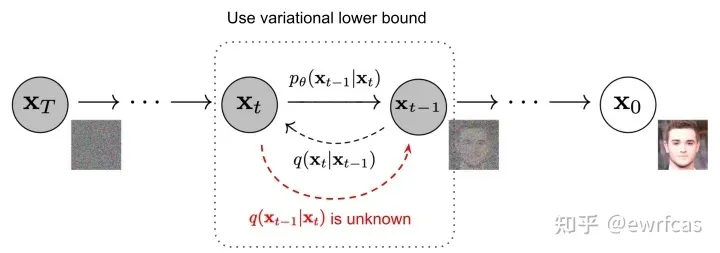



ZT其实就是我们要估计的每个时刻的噪声:
1)无法直接求解,需要训练一个模型计算
2)模型输入参数有2个,分别为当前时刻的分布和时刻t

七、参考
What are Diffusion Models? | Lil’Log
https://openreview.net/attachment?id=2LdBqxc1Yv&name=supplementary_material
https://arxiv.org/abs/2204.00227
Variational Diffusion Models | OpenReview
Diffusion model—扩散模型_原来如此-的博客-CSDN博客_扩散模型
【Diffusion模型】由浅入深了解Diffusion,不仅仅是震撼,感受它带给我们的无限可能!!(超详细的保姆级入门教程)_哔哩哔哩_bilibili
文章出处登录后可见!