目录
前言
python版本 >3.6 【我的是3.9】
pip换源:【方便后续库的安装】记录pip问题(解决下载慢的问题、升级失败问题)_pip升级太慢_Pan_peter的博客-CSDN博客每次我都是针对某一个库安装出错,然后去排查问题,十分浪费时间!!!在此记录,引以为戒!不推荐使用pycharm上面的库安装,因为没有明显的报错提示,无法很好的判断问题所在当电脑存在多个版本python的时候,记得使用pip -version查看使用的是哪一个版本!
https://blog.csdn.net/Pan_peter/article/details/129553679
一、使用labelimg制作数据集
1.1、下载labelimg
下载链接:
mirrors / tzutalin / labelimg · GitCodeLabelImg is now part of the Label Studio community. The popular image annotation tool created by Tzutalin is no longer actively being developed, but you can check out… https://gitcode.net/mirrors/tzutalin/labelimg?utm_source=csdn_github_accelerator
https://gitcode.net/mirrors/tzutalin/labelimg?utm_source=csdn_github_accelerator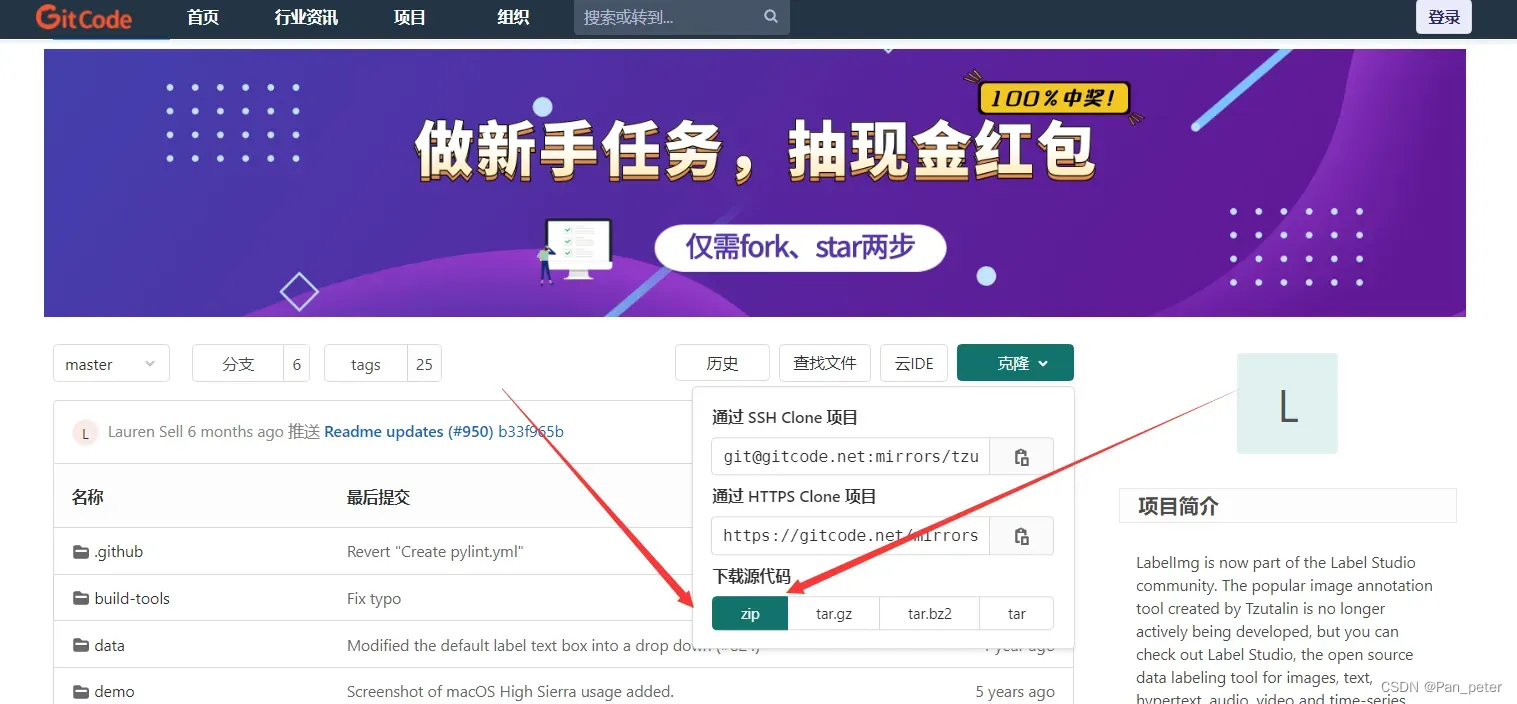
下载压缩包后,解压即可!【解压的路径最好不要有中文!】
我的路径:E:\labelimg
1.2、安装库并启动labelimg
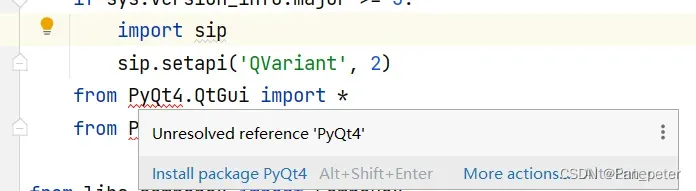
1、根据所需的红线,一个个安装即可!
如果不会用pycharm下载的话,直接打开控制台:
# 记得换源!!! pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple pip config set install.trusted-host mirrors.aliyun.com # 安装lxml pip install lxml # 安装pyqt5 pip install pyqt=5
2、在【命令提示符】中,启动labelimg

C:\Users\PAN>e: E:\>cd labelimg E:\labelimg>pyrcc5 -o libs/resources.py resources.qrc E:\labelimg>python labelimg.py“pyrcc5 -o libs/resources.py resources.qrc” 是一个在终端(命令行界面)中执行的命令。
它的含义是将名为 “resources.qrc” 的文件编译成 Python 代码,并将输出保存到名为 “libs/resources.py” 的文件中。
在这个命令中:
- “pyrcc5” 是用来处理 Qt 资源文件 (.qrc) 的命令行工具,
- “-o libs/resources.py” 指定输出文件的位置和名称,
- “resources.qrc” 是要编译的资源文件的名称。
该命令通常用于将 Qt 的资源文件编译成 Python 代码,便于在 Python 应用程序中使用,例如通过 PyQt 或 PySide 模块进行访问。
启动成功:
1.4、制作YOLO数据集
1、切换为YOLO格式
2、打开目录【那目录中存在我们的目标照片】

3、选择存放目录【用来保存我们标定的数据集】
4、开始标定
- 按w后,按左键进行拖拽
- 详细操作可以跳转,进行学习
- 还有class(类)的自定义
注意:
- 将键盘输入法切换为英文,按“W”键,labelimg中会出现下图中的十字线
- 按住鼠标左键将目标纳入方格区域内,注意方格区域要尽可能的小
- 可以设置为自动保存
快速操作:http://t.csdn.cn/ecW9v
自定义类:打开data/predefined_classes.txt,可以修改默认类别
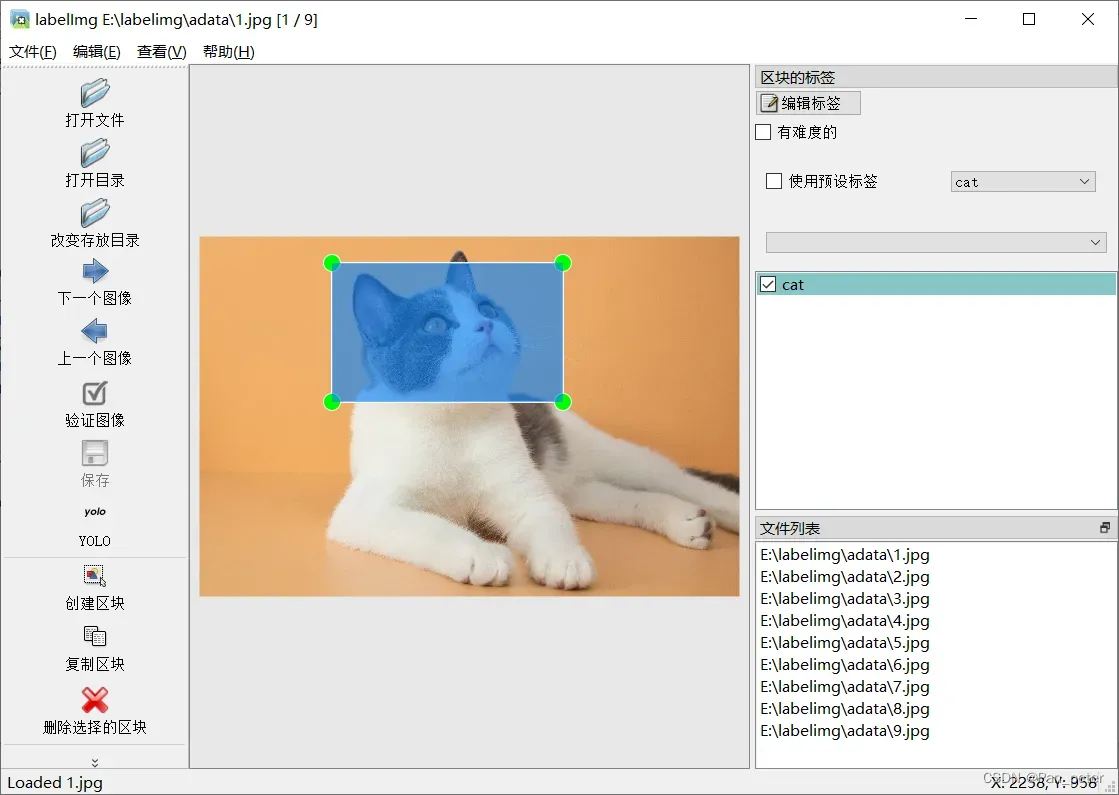

5、检查数据集
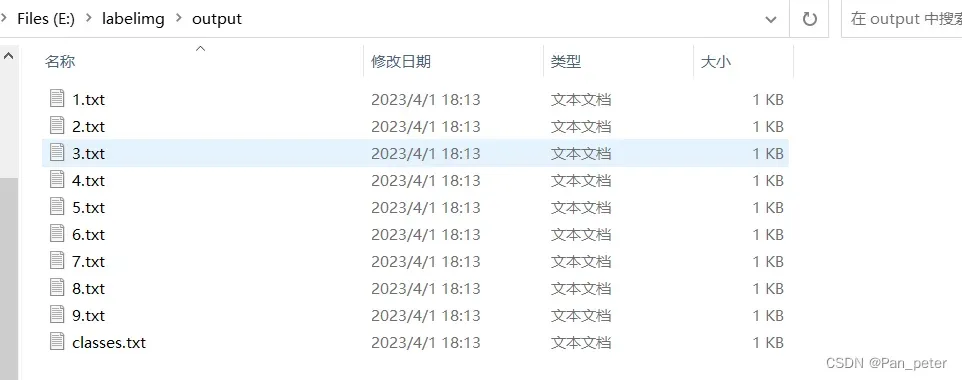
至此,数据集制作完成!
二、使用YOLOv8训练模型
2.1、下载库——ultralytics (记得换源)
记录pip问题(解决下载慢的问题、升级失败问题)_pip升级太慢_Pan_peter的博客-CSDN博客
pip install ultralytics2.2、数据模板下载
yolov8-test.zip – 蓝奏云
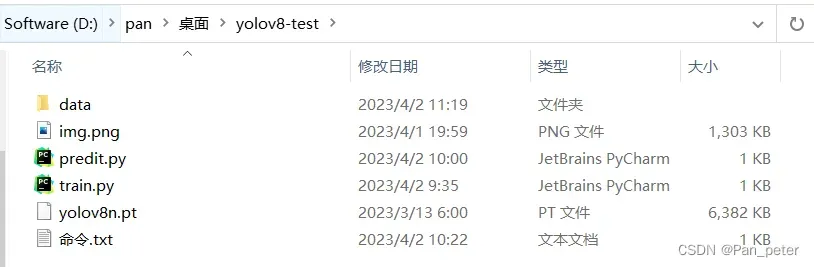
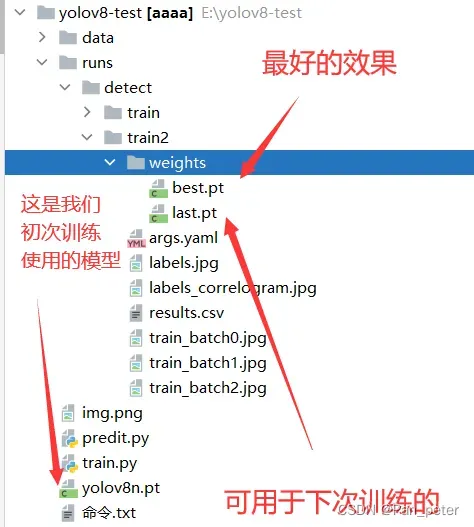
目录结构
E:.
│ img.png
│ predit.py
│ train.py
│ yolov8n.pt
│ 命令.txt
│
└─data
│ cat.yaml
│ yolov8n.yaml
│
├─test
│ ├─images
│ │ 8.jpg
│ │
│ └─labels
│ 8.txt
│
├─train
│ │ labels.cache
│ │
│ ├─images
│ │ 1.jpg
│ │ 2.jpg
│ │ 3.jpg
│ │ 4.jpg
│ │ 5.jpg
│ │ 6.jpg
│ │ 7.jpg
│ │
│ └─labels
│ 1.txt
│ 2.txt
│ 3.txt
│ 4.txt
│ 5.txt
│ 6.txt
│ 7.txt
│
└─val
│ labels.cache
│
├─images
│ 9.jpg
│
└─labels
9.txtcat.yaml的内容 【路径中最好不要有中文!!!】
train: E:/yolov8-test/data/train val: E:/yolov8-test/data/val test: E:/yolov8-test/data/test # number of classes nc: 1 # class names names: ['cat']
这是一份YOLOv8的配置文件,其中包括以下三个配置项:
train: E:/yolov8-test/data/train/images
指定训练数据集的路径,本例中设置为E:/aaaa/data/train。
images包含所有的训练图像,
labels相应的标注文件。val: E:/yolov8-test/data/val/images
指定验证数据集的路径,本例中设置为E:/aaaa/data/val。验证数据集是用来测试训练模型的,它与训练数据集类似。
images包含所有的训练图像,
labels相应的标注文件。test: E:/yolov8-test/data/test/images
指定测试数据集的路径,本例中设置为E:/aaaa/data/test。
测试数据集是在训练结束后用来检测模型精度的数据集。
images包含所有的训练图像,
labels相应的标注文件。nc: 1
指定数据集中的类别数量,本例中设置为1,即一个类别(猫咪)。
names: [‘cat’]
指定类别的名称,本例中只有一个类别,名称为cat。
总之:
images目录下存放数据集的图片文件。
labels目录下存放标注文件。
一般按照7:2:1的比例进行存放,比如:
你有100张图片和100个label,那么
- train中有70张图片和70个label
- val中有20张图片和20个label
- test中有10张图片和10个label
2.3、开始训练
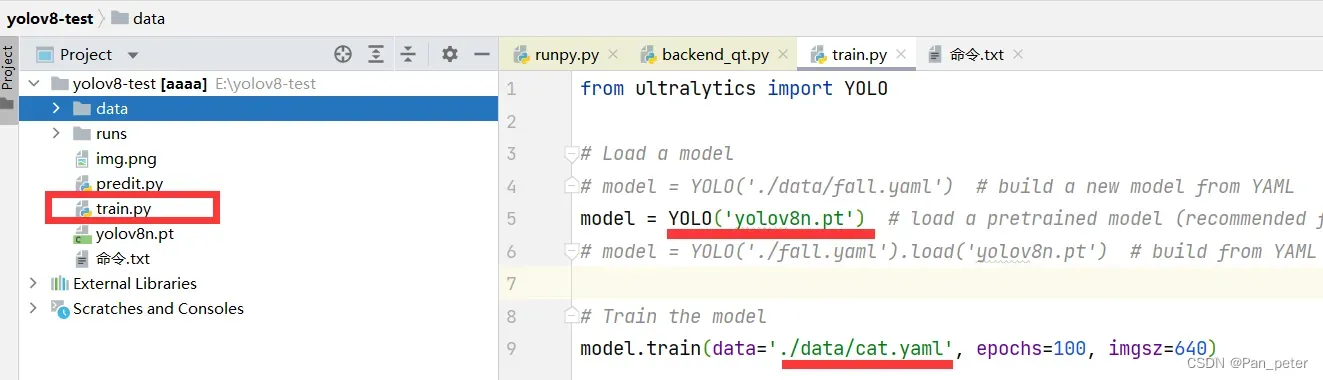
1、启动train.py,进行训练
打开train.py,选择cat.yaml配置文件和yolov8n.pt模型开始训练
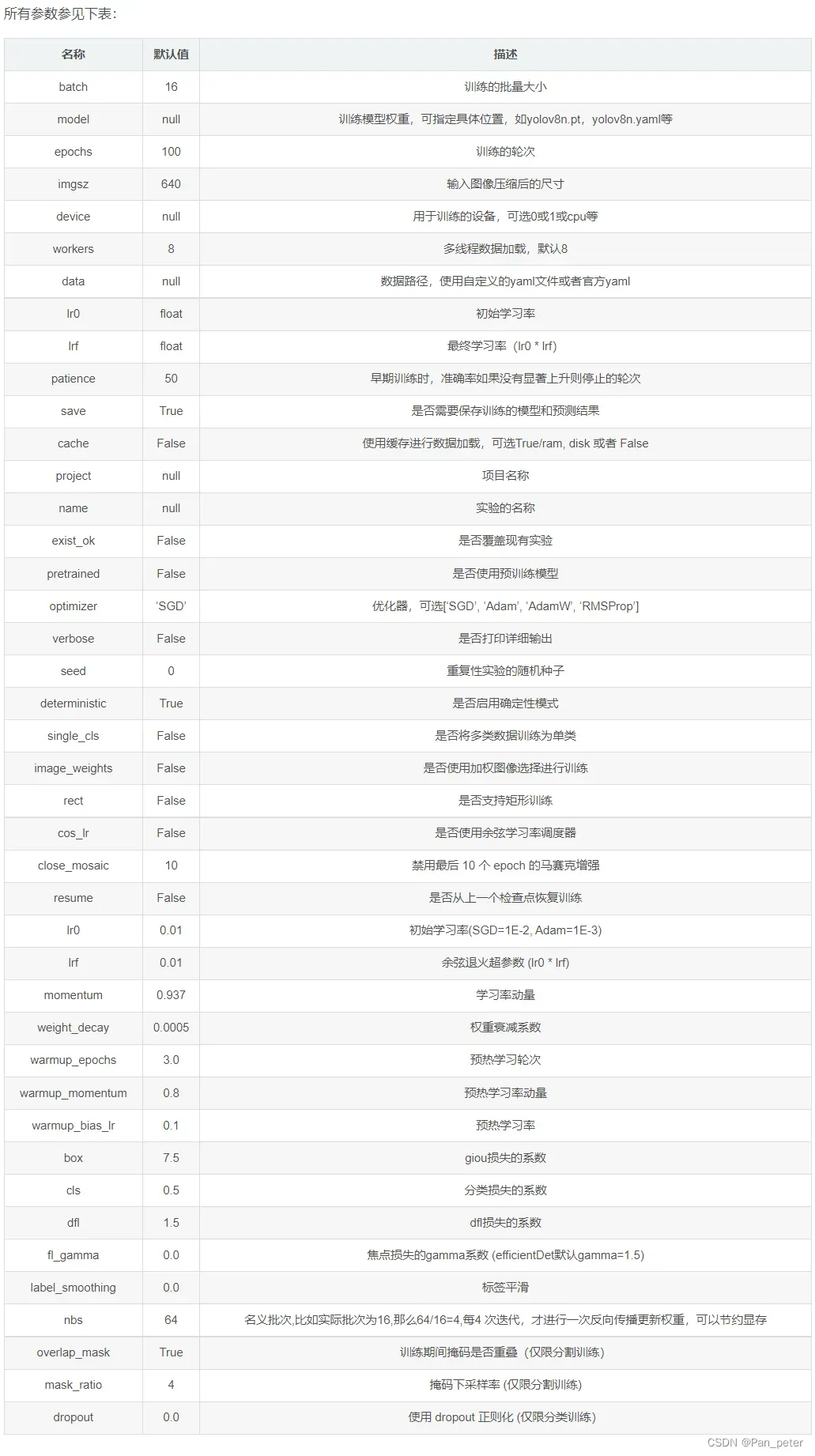
2、我们可以直接使用命令进行训练
# YOLO训练模型 yolo task=detect mode=train model=yolov8n.pt data=./data/cat.yaml epochs=100 imgsz=640 resume=Ture # YOLO断续训练 yolo task=detect mode=train model=run/detect/train2/weights/last.pt data=./data/cat.yaml epochs=100 imgsz=640 resume=Ture

三、其他问题
1、训练时,为什么会生成labels.cache文件?
在YOLOv8中,默认情况下会生成名为”labels.cache”的文件,该文件记录了训练数据集中的图像标签信息,包括图像文件路径和标签信息。
该文件的作用是加速模型训练过程中的数据读取和加载,从而提高训练速度。
在模型训练过程中,需要将训练数据集中的图像文件和标签信息加载到内存中进行训练,而对于大规模的数据集,这个过程可能会非常耗时,影响训练效率。为了避免这个问题,YOLOv8通过生成”labels.cache”文件的方式,将图像文件和标签信息预先读取并缓存到内存中,训练过程中可以直接从缓存中读取数据,减少了训练时的IO操作,从而大幅度缩短了训练时间。
此外,缓存的图像数据和标签信息属于原始训练数据集,不会改变图片的数据和标签信息,这意味着可以在缓存文件中进行快速的训练,而无需频繁地重新读取原始数据集。这种方法可以有效地缩短模型训练的时间,并提高训练效率和精度。
2、YOLOv8的训练图像和相应的标注文件应该放同一个文件夹里吗?还是应该分开放?
YOLOv8的训练需要使用图像文件和相应的标注文件,通常来讲,这些文件的命名对应方式需要相同:
例如图像文件名为”image001.jpg”,那么相应的标注文件应该命名为”image001.txt”。
至于这些文件应该分别放在哪里,是一种较为灵活的安排。通常情况下,它们可以放在同一个文件夹里,以便于管理和处理。这样可以方便地查找图片和对应的标注文件,而且文件夹的名称可以根据具体任务、类别和编号等方式进行命名,便于进行管理和实验效果的观察。
当然,您也可以将图像文件和相应的标注文件分别放在不同的文件夹中,而文件夹的名称可以根据具体任务要求进行命名,例如划分成训练集(training set)和测试集(test set)。一般来讲,这样的做法对于数据管理和处理来说比较繁琐,但对于某些特定任务的处理可能会有帮助。
综上所述,将图像文件和相应的标注文件放在同一个文件夹中是比较常见的做法,但也需要根据实际情况进行具体的安排。
3、yolov8训练自己的模型,大概需要多少图片作为训练集?效果合适?又需要训练多少轮呢?
YoloV8的训练数量并没有一个固定的标准,通常的做法是根据自己的数据量和特定任务的困难程度来设计数据集大小。
一般来说,训练集的大小应该足够覆盖任务中的各种不同场景和对象,以确保模型具备较好的鲁棒性。为了取得较好的训练效果,建议训练集至少要有1000张图片,最好有数万张图片。
同时,训练集中每个类别的数量也需要足够。如果某个类别的样本数量太少,可能导致模型无法很好地学习该类别的特征,从而导致训练不充分而无法取得理想的效果。因此,建议每个类别至少有几百张训练图片。
对于训练次数,一般可以通过观察模型在验证集上的表现来确定。如果模型在验证集上的表现不断提升,那么可以逐渐增加训练轮数,直到模型在验证集上的表现达到一个 稳定的状态。
通常,训练轮数越多,模型的性能会越好,但是过多的训练轮数可能导致过拟合,所以需要在充分训练的同时避免过度拟合。常见的训练轮数通常在50-200轮之间。
4、yolov8训练时会十分浪费电吗
YoloV8是一种非常先进的目标检测算法,因其检测速度快、精度高而被广泛应用于计算机视觉领域。
在训练阶段,YoloV8需要使用大量的计算资源,包括CPU、GPU、Memory等。由于训练需要运算量比较大,因此在计算资源不足的情况下,使用YoloV8训练会十分浪费电。
如果你要使用YoloV8进行训练,建议使用高性能显卡(例如NVIDIA RTX 3090等),这样可以大大减少训练时间,也能降低电能消耗。同时,使用最新的深度学习框架(例如PyTorch、TensorFlow等)也能提升训练效率和准确性,从而避免出现浪费电的情况。
另外,还可以使用电力管理软件来监控计算机的电量消耗并进行一些优化设置,例如关闭不必要的应用程序、降低屏幕亮度等。这样不仅可以节省电力,还可以 prolong电池寿命。
5、在yolov8中,yaml中的文件只指向了图片位置,但程序仍然可以找到同级文件夹中的label标定数据,这是为什么?
在 YOLOv8 中,当你通过指定 YAML 配置文件来指定图像文件的位置时,实际上在执行 YOLOv8 程序时,程序会默认去同级目录下找到与该图像文件同名的 .txt 标注文件。
这是因为 YOLO 系列算法中目标检测任务需要同时标定图像中检测目标的位置、类别和置信度等信息,所以除图像外,还需要提供对应的标注信息。在 YOLOv8 中,.txt 标注文件与对应图像文件同名,其格式也是固定的,每一行表示一个标注框的信息,其中包括车辆类别、中心点坐标、边界框宽高、以及置信度等信息。
因此,无论你通过配置文件指定哪个图像文件,程序在执行时都会去同级目录寻找相同文件名的 .txt 文件作为该图像的标注信息。这种设计简化了数据集的管理和使用,并且减少了用户在制作数据集时的操作繁琐程度。
6、为什么要将.pt模型导出为onnx?
1、平台无关性:ONNX是一种跨平台的深度学习模型交换格式,可以在不同的深度学习框架和硬件平台之间进行方便的转换和部署,提高部署的灵活性。
2、快速预测:ONNX格式的模型具有非常快的推理速度和较低的内存占用,这意味着在运行推理任务时可以更快地完成,可以提高推理速度和性能,并减少计算资源的使用。
3、生态环境:ONNX格式受到了众多深度学习框架以及众多硬件加速平台的支持,可以使用多种语言和平台进行部署,使得训练后的模型可以被更广泛的应用所使用。
因此,将YOLOv8训练得到的模型导出为ONNX格式,有助于更好地部署模型,并在不同的框架和平台之间进行快速交换和移植,提高模型的效用和可用性。
7、如何快速入门 YOLOv5 :
- 准备输入数据:YOLOv5 需要训练数据,以便在其上进行训练。你需要一个包含图像及其注释的数据集。YOLOv5 接受 COCO 格式或自定义格式的注释。你可以通过在 ImageNet 或 COCO 数据集上进行预训练来加快训练速度。
- 安装 YOLOv5:YOLOv5 可以通过 Clone GitHub 存储库或使用 pip 安装在本地计算机上。
- 配置超参数:通过更改 YAML 配置文件中的超参数,对 YOLOv5 进行各种设置,例如网络架构、训练和预测设置以及优化器参数等。
- 训练模型:运行
train.py脚本开始训练模型。你可以通过设置训练时间来控制模型在数据集上的训练次数。- 转换模型: 在训练完成后使用
export.py脚本将模型转换为 ONNX、TensorFlow Lite、TorchScript 等格式,以便在设备上部署模型。- 运行模型:在部署后,你可以使用
detect.py脚本来运行模型。除了以上步骤外,你还需要了解 YOLOv5 的原始论文和代码、深度学习基础知识、Python 编程等。确定你已具备这些基础知识后,可以通过逐步完成上述步骤来快速入门 YOLOv5。
四、推荐视频与文章
1、视频
【yolov8】3分钟安装yolov8?yolov8安装补充与yolo8简单实现对桌面进行实时捕捉画面推理实现。_哔哩哔哩_bilibili上期视频有很多朋友问我一些关于yolov8的问题,其实我也是跟大家一样的小白,很多问题我也无法帮助大家解决。就像我录的两期视频里出现了很多我知道或不知道的问题,也恰恰证明了我不是什么大神,而是和大伙一样的学习者罢了。视频有很多讲的不对的地方,请多多包涵。, 视频播放量 2853、弹幕量 6、点赞数 42、投硬币枚数 34、收藏人数 101、转发人数 9, 视频作者 奥怪, 作者简介 无人关注,只好扮酷,相关视频:【yolov8】从0开始搭建部署YOLOv8,环境安装+推理+自定义数据集搭建与训练,一小时掌握,YOLOV8保姆级教学视频.,【新】YOLOv8 YOLOv5 NCNN 安卓Android 部署运行【上一个视频发错了没录全】,YOLOV8环境安装教程.,YOLOV8推理教程-要修改yolov8代码的小伙伴必看!不看会踩坑!,YOLOv8实时推理原神画面,使用 YOLOv8+ByteTrack 进行目标跟踪+计数,YOLOv8 vs YOLOv7 vs YOLOv6 vs YOLOv5实时对比,YOLOV8手把手实战!实时训练和部署基于YOLOv8的通用实例分割,2023年最新!YOLO家族又添新成员,从零开始掌握YOLOv8原理及实战,精准度剧增!!! https://www.bilibili.com/video/BV1js4y1Y77w
https://www.bilibili.com/video/BV1js4y1Y77w
2、文章
YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等_Zhijun.li@Studio的博客-CSDN博客YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等https://blog.csdn.net/weixin_45921929/article/details/128673338
文章出处登录后可见!