一点就分享系列(理解篇5)Meta 出品 Segment Anything 通俗解读——主打一个”Zero shot“是贡献,CV依然在!
文章目录
- 一点就分享系列(理解篇5)Meta 出品 Segment Anything 通俗解读——主打一个”Zero shot“是贡献,CV依然在!
- 前言
- META最近很活跃。先提出了LLAMA去对标GPT3,这几天又来了CV的大模型SAM给我们惊喜,今天来整理分析一波。 另外最重要的一定要致敬谷歌,没有transformer就没有现在的大模型,多模态AI领域的这么多研究成果。
- 一、Segment Anything
- 1. 大模型的前置需求——宝贵的大规模数据集
- 2.基础任务的泛化方式
- 3.模型结构设计
- 3.0 语义多样性问题
- 3.1 图像编码器
- 3.2 提示编码器
- 3.3 掩码编码器
- 4.训练部分和损失函数
- 5. 零样本的迁移验证
- 6.应用拓展
- 6.1 自动生成prompot的方式
前言
Meta开源了Segment Anything项目和官网展现了非常令人印象深刻的分割Demo,其SAM模型给CV研究领域,个人简要理解有以下贡献:
1.Openset形式的分割任务的模型
2.超大的分割数据集
3.更好的应用思路,提示和组合可以派生很多有趣的应用
4.促进CV及多模态以及多任务一统趋势
META最近很活跃。先提出了LLAMA去对标GPT3,这几天又来了CV的大模型SAM给我们惊喜,今天来整理分析一波。
另外最重要的一定要致敬谷歌,没有transformer就没有现在的大模型,多模态AI领域的这么多研究成果。

源码地址:https://github.com/facebookresearch/segment-anything
一、Segment Anything
SAM这波问世,很多人对CV统一的趋势无限看好,我们先不论这个,因为我觉得CV方向的工程应用点就决定了,毕竟现实问题都是具体情况具体分析 ,不单单只考虑研究层面,我觉得更多的意义是带来促进基础研究,就像你用GPT3更多只是辅助你编程,而不是取代!CV依然在,该干嘛干嘛。
大模型正在冲击AI领域,而其重要的特点是 Zero-shot(零样本迁移性), 从OPENADI的CLIP的那一年开始我们所见的多模态研究早已层出不穷,(还是那句话我一直都看好多模态,从几年前我就在念了),SAM加剧了这个趋势,但还远远不够,对从业者来说大模型的出现其实是利大于弊,这使得我们再也不需要定制化成熟的视觉模型任务和解放了微调训练等过程成为了可能,那么下面来看一下meta是怎么设计出的。经过代码初步阅读,目前text的输入clip还不支持,但是其实也不难实现。
1. 大模型的前置需求——宝贵的大规模数据集
SAM是在1100万的图像数据集上训练出来的:一个强大的大模型是需要多样化的海量数据去喂养出来的,但是目前没有用于分割的超大规模数据集素材,因此Meta首先解决的数据集构建问题,他们提供了一个名为SA-1B的数据集(1亿掩码、1100万张图像),思路就是在线循环获取思路,为了获取更多的掩码,建立“数据引擎”,就是我们常用的训练模型标注数据再训练的“循环逻辑”,具体分为三个阶段:
1.SAM模型去辅助人员标记MASK,类似于交互分割;
2.SAM模型经过prompt的提示可能性的去标注部分对象自动标注,其余标注对象由人工完成;
3.SAN模型最后使用前景信息去使得SAM自动标注。
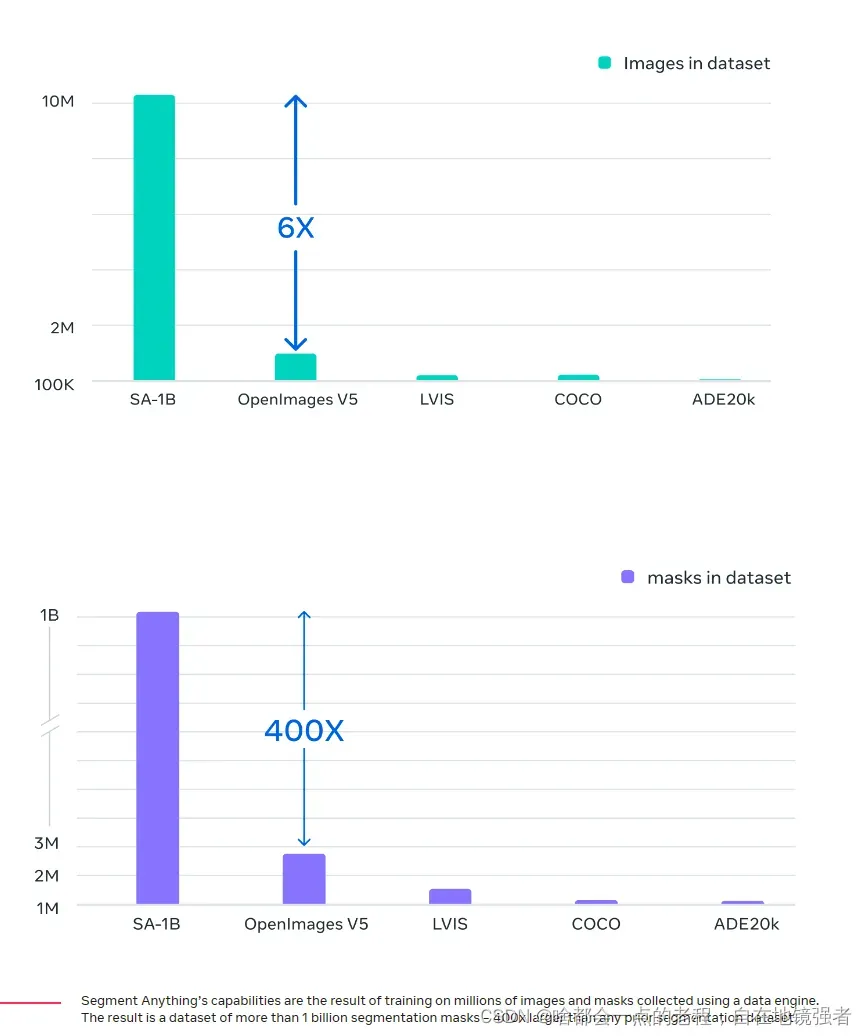
如下图展示,高效的数据量制作结果比对,比 COCO 完全手动基于多边形的掩码注释快 6.5 倍,比之前最大的数据注释工作快 2 倍,后者也是模型辅助的。
2.基础任务的泛化方式
SAM的简单描述,是交互式分割和自动分割的统一,如下图展示,提供点坐标(前后景)、BOX、文本使用prompt的形式去实时输出分割掩码,该掩码应该是有效高质量的,因为真实场景中即使通过promopt也往往存在歧义性,输出应该有至少一个对象的合理结果,比如衣服上的一块像素可能描述衣服也可以是穿衣服的人,那么具备 prompt的分割是的特点:
1. 可以当作预训练模型的,即使这个是歧义的,但是它必须是有效正确的;
2. 通过提示去改善并完成通用的下游分割任务,其实最大的特点那就是:Zero-shot以及其prompt的灵活性,交互性只是一个偏向应用上的需求。如何展示其特性?具体例子如,你实际需要解决A的分割,但是你需要自动化的流程,如果当你有一个A的训练好的检测器,你不再需要从新定制训练,只需要将问题转化为制作prompt上。
由此可见,整体的模型并不那么复杂,且会更利于工程上的部署集成。
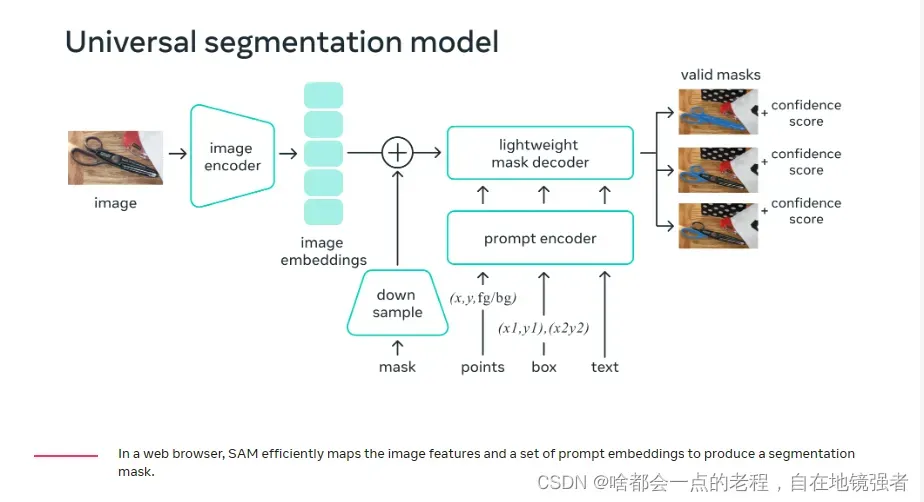
3.模型结构设计
SAM如上图所示,主要由一个图像的encoder和提示的encoder通过一个轻量的掩码deocoder去完成最终的预测,并且考虑到上述的目标语义的歧义性问题,使得模型具备歧义性,研究人员对一个提示会预测多种掩码,如上图中“剪刀”的三个结果。
3.0 语义多样性问题
如上述,作者使用了对一个PROMPT尽可能的来表示多个语义,最终总结出对于掩码表示三个程度:整体、局部、子部分,依旧如官方图例。
3.1 图像编码器
顺便提一下目前使用比较多的几个Base on transformer的CV主干,SWIN系列/VIT系列/DETR系列,这里主要以体系backbone构建为基准,当然还有很多改进的算子,这里不提了。
输入图像进行embedding,这步很简单,从代码中看出,这个编码器是源于meta的vitdet,VITDET是何凯明的工作,其实也是MAE 和ViT-based Mask R-CNN[的衍生,这里简单普及一下,可以理解为是对标swintransformer的另一设计思路,解决的问题:
在这项工作中,何恺明等研究者追求的是一个不同的方向:探索仅使用普通、非分层主干的目标检测器。如果这一方向取得成功,仅使用原始 ViT
主干进行目标检测将成为可能。在这一方向上,预训练设计将与微调需求解耦,上游与下游任务的独立性将保持,就像基于 ConvNet
的研究一样。这一方向也在一定程度上遵循了 ViT
的理念,即在追求通用特征的过程中减少归纳偏置。由于非局部自注意力计算可以学习平移不变特征,它们也可以从某种形式的监督或自我监督预训练中学习尺度等变特征。
下面简单概述下VITDET:
研究者表示,在这项研究中,他们的目标不是开发新的组件,而是通过最小的调整克服上述挑战。具体来说,他们的检测器仅从一个普通 ViT 主干的最后一个特征图构建一个简单的特征金字塔。这一方案放弃了 FPN 设计和分层主干的要求。为了有效地从高分辨率图像中提取特征,他们的检测器使用简单的非重叠窗口注意力,少量的跨窗口块来传播信息,这些块可以是全局注意力或卷积。这些调整只在微调过程中进行,不会改变预训练,总结要点,基于VIT系列的设计,
- MAE特点:CV中transformer的应用瓶颈,CV应用Transformer是有监督的方式,而NLP大部分用的是自监督的方式,如何能在Transformer的方法中使用自监督的方法,就是MAE提出的背景,MAE相当于CV的“BERT”(非对称的编解码器结构,非对称的意思是编码器只能看到可见的块(这样也可以极大的减少计算量),解码器可以看到全部,比如图像在分块后,随机盖住,encoder收到的是其余未遮盖的图片,然后我们补上缺失的序列,再送到decoder中去,得到就是”补全“,这样减少了图像的冗余,因为语言是单一的token序列,而图像分块的PATCH信息并不唯一,因此要遮盖75%+的像素,通过插值回复)。
- 通过viT构建,不使用窗口化的和FPN的结构设计,它的好处可以通过由大步幅、单一尺度图构建的简单金字塔来有效地获得,只要信息能在少量的层中很好地跨窗口传播,仅仅使用主干的最后一的特征层输出,因为它应该具有最强大的特征,这样窗口注意力就够用了。
代码比较冗长,就是常规的模型Block定义,比较常见,源码在这,有兴趣的自行阅读和论文,SAM的VITDET图像编码器代码定义
3.2 提示编码器
接受sparse的输入:point pair /boxes/text ,dense 输入:mask掩码。该decoder通过位置编码和每个提示输入的embedding相加来表示输入的特征,同时使用CLIP的文本编码器来表示特征文本。MASK则通过卷积才采样后和图像编码器的embedding相加。其输出作为maskdeocer的输入。
这里对代码做了简化,简单分析下代码,
class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
"""
Encodes prompts for input to SAM's mask decoder.
Arguments:
embed_dim (int): The prompts' embedding dimension
image_embedding_size (tuple(int, int)): The spatial size of the
image embedding, as (H, W).
input_image_size (int): The padded size of the image as input
to the image encoder, as (H, W).
mask_in_chans (int): The number of hidden channels used for
encoding input masks.
activation (nn.Module): The activation to use when encoding
input masks.
"""
super().__init__()
self.embed_dim = embed_dim
self.input_image_size = input_image_size
self.image_embedding_size = image_embedding_size
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2) #随机位置编码初始化
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners 对点的emdding数量
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
self.point_embeddings = nn.ModuleList(point_embeddings)
self.not_a_point_embed = nn.Embedding(1, embed_dim)
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
## 对掩码输入设计一个CNN下采样模块
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
self.no_mask_embed = nn.Embedding(1, embed_dim) #初始化一个emdding,在没有mask输入到prompt的情况下
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Embeds different types of prompts, returning both sparse and dense
embeddings.
Arguments:
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
and labels to embed.
boxes (torch.Tensor or none): boxes to embed
masks (torch.Tensor or none): masks to embed
Returns:
torch.Tensor: sparse embeddings for the points and boxes, with shape
BxNx(embed_dim), where N is determined by the number of input points
and boxes.
torch.Tensor: dense embeddings for the masks, in the shape
Bx(embed_dim)x(embed_H)x(embed_W)
"""
bs = self._get_batch_size(points, boxes, masks)
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device()) #点、文本的稀疏embeddings
if points is not None:
coords, labels = points
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None: #boxes embedding
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
if masks is not None:
dense_embeddings = self._embed_masks(masks) #掩码embedding
else:
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
)
return sparse_embeddings, dense_embedding
最终会输出一个密集embeds一个稀疏embeds(由存在的点、框拼接),然后你会发现并没有官方给出的clip的文本输入处理功能,应该是没释放出来,其实大体逻辑:无非就是将CLIP作为特征embeddings,适配到掩码解码器中。
3.3 掩码编码器
仍然基于transfromer设计,只不过这个maskdecoder,作为最终的解码器,使用了self-attention和cross-attention的组合来处理以上编码器输入的embedding,通过上采样和MLP线性分类,最终计算每个像素的前景概率。这里如果对交叉注意力机制不理解的,简单概述下其设计原理:
1.Cross attention概念 可以输入两个序列,必须具有相同的维度,两个序列可以是不同的模式形态(如:文本、声音、图像) 一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
2.Cross-attention将两个相同维度的嵌入序列不对称地组合在一起,而其中一个序列用作查询Q输入,而另一个序列用作键K和值V输入。当然也存在个别情况,他们的QKV是来自两种输入,而SELF-attention来自同一个输入,这种交叉的注意力更适合多模态输入。
具体而言,我们简要看看代码,代码的定义很规范,首先我们看一下上述我们替的注意力组合模块代码,这里我还是挑最核心的说,概述下这个模块的流程:
“TwoWayAttention”就是cross-att和self-att的组合,一个Block由四层构成,如下注释,
- 第一层的自注意力收到的embeds的sparse的输入:输入一个Query,和其sparse类位置编码query_pe相加后得到新的Query,经过self-attention
会判断是否为第一层,不是的话会进行残差操作,再norm输出 ; - 第二层的交叉注意力层,spare to dense—text2image.将token到image特征,上一层的输出加上spare类的位置编码query_pe和该层的位置编码向量key_pe,其实该层是处理图像的位置特征编码,相加后经过cross-attention输出后还是残差+norm.
- 第三层是MLP+残差后Norm,没什么好说的
- 最后一层依然是交叉注意力,计算流程是一样的,image2text,dense图像emd 嵌入到token中,和第二层反向,且都是2倍采样。
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
A transformer block with four layers: (1) self-attention of sparse
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
block on sparse inputs, and (4) cross attention of dense inputs to sparse
inputs.
Arguments:
embedding_dim (int): the channel dimension of the embeddings
num_heads (int): the number of heads in the attention layers
mlp_dim (int): the hidden dimension of the mlp block
activation (nn.Module): the activation of the mlp block
skip_first_layer_pe (bool): skip the PE on the first layer
"""
super().__init__()
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# Self attention block
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
下面还是文字叙述把,通过多个TwoWayAttentionBlock和一个LN层,我们可以得到输出的Tensor:queries, keys,然后经过一个Cross注意力层和LN层
# Apply the final attenion layer from the points to the image
q = queries + point_embedding
k = keys + image_pe
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm_final_attn(queries)
最后,我们再看Maskdecoder ,简要看下代码:
接受各个编码器的输入embeddings,输出low_res_masks, iou_prediction,后处理取到最终masks
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
4.训练部分和损失函数
由于官方没有公开训练代码,损失函数只是论文中提到了使用了DETR的DICE作分割LOSS和Focal LOSS。
5. 零样本的迁移验证
从前景点、边缘信息、BOX、文本CLIP等方式进行实验验证,这里就多过多介绍了。
总的来说,其实全篇核心就是展示:ZERO-SHOT
6.应用拓展
6.1 自动生成prompot的方式
目前看来自动实现的PROMPT主要依赖于视觉任务模型和语言模型,其CLIP部分代码还没release,故这里其实目前有两种最直接的拓展:
- 自己调用CLIP集成到该项目中
- 在开源项目中(https://github.com/IDEA-Research/Grounded-Segment-Anything),在CVPR2023的开源项目和论文Grounded-DINO中介绍了同样作为zero-shoT泛化模型是一个多模态的融合模型(这个后续会另起文章,下篇预告),论文中模型设计如下:
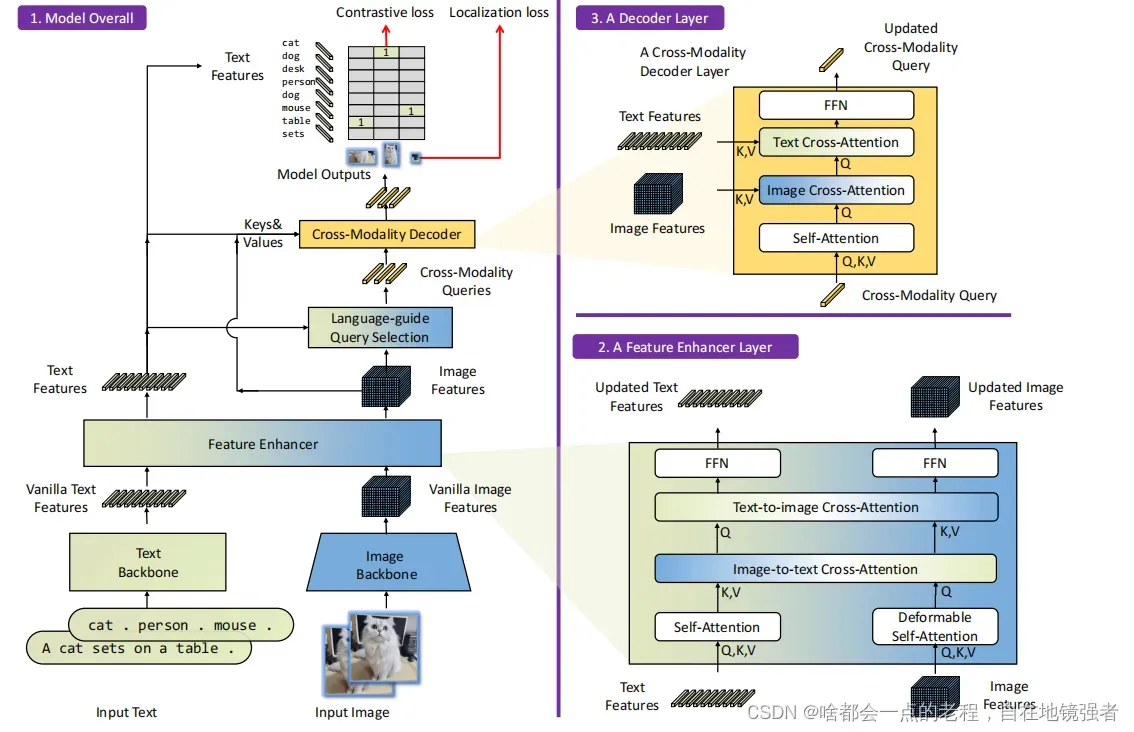 可以看到底层的算子出现了我们之前说的cross-att, 看来基本多模态的注意力这算是一个“标配”了,通过text提供图像的检测,并且作为Prompt来提供SAM作为下游任务去使用,并且也集合Stabel diffusion去作prompt类似于controlnet去控制的机制一样。4. 以上结合GPT、SD等可玩性十足,总之只要是类似PROMPT机制的都可以进行结合,下篇ZERO-SHOT模型预告准备中!该篇如果开源项目中有补充更新同步更新!搬砖不易,希望我3个小时的奋笔疾书能换你的点赞关注~
可以看到底层的算子出现了我们之前说的cross-att, 看来基本多模态的注意力这算是一个“标配”了,通过text提供图像的检测,并且作为Prompt来提供SAM作为下游任务去使用,并且也集合Stabel diffusion去作prompt类似于controlnet去控制的机制一样。4. 以上结合GPT、SD等可玩性十足,总之只要是类似PROMPT机制的都可以进行结合,下篇ZERO-SHOT模型预告准备中!该篇如果开源项目中有补充更新同步更新!搬砖不易,希望我3个小时的奋笔疾书能换你的点赞关注~
文章出处登录后可见!