啤酒和纸尿裤的故事大多数人都听说过,纸尿裤的售卖提升了啤酒的销售额。
关联分析就是这样的作用,可以研究某种商品的售卖对另外的商品的销售起促进还是抑制的作用。
案例背景
本次案例背景是超市的零售数据,研究商品之间的关联规则。使用的自然是最经典的apriori算法。
数据展示,数据是一个excel表:
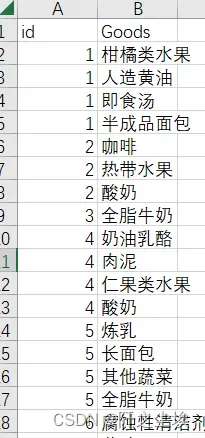
id表示订单编号,id=1表示第一个订单的销售的商品,如图就是第一个订单卖出了柑橘类水果,人造黄油,即食汤,半成品面包四个商品,其他以此类推。
数据读取
导入包,设置
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
pd.options.display.float_format = '{:,.4f}'.format #设置小数显示4位
np.set_printoptions(precision=4)
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号读取案例数据
inputfile = '../data/GoodsOrder.csv' # 输入的数据文件
data = pd.read_csv(inputfile,encoding = 'gbk') # 读取数据
data.info()
可以看到是43367条样本。
对商品进行分类汇总,计算每类商品的销售数量,得到前10 的商品
group = data.groupby(['Goods']).count().sort_values('id',ascending=False) # 对商品进行分类汇总
group.head(10) 
画柱状图展示;
plt.figure(figsize=(6,3),dpi=128)
sns.barplot(y=group.index[:10],x=group['id'][:10],orient="h")
plt.xlabel('商品订单量')
plt.ylabel('商品名称')
plt.xticks(fontsize=10,rotation=45)
plt.title("销售量前十商品订单数量")
plt.show() 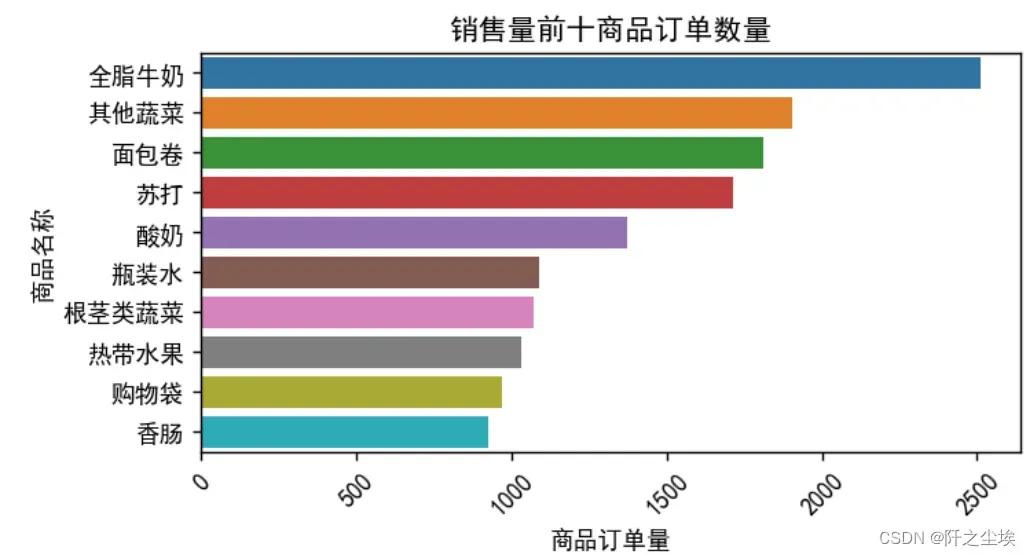
可以看到卖得最多的是全脂牛奶,蔬菜等。
类别分析
读取每种商品对应的类别:
types = pd.read_csv('../data/GoodsTypes.csv',encoding = 'gbk') # 读入数据
types.head()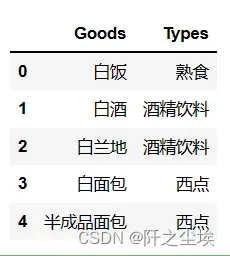
可以看到这个表格包含了所有商品对应的食物的总类别
这个表对上面分类汇总后的订单表进行合并:(放在excel里面实现这一步就是vlookup函数)
sort_links = pd.merge(group.reset_index(),types,on='Goods') # 合并两个datafreame
sort_links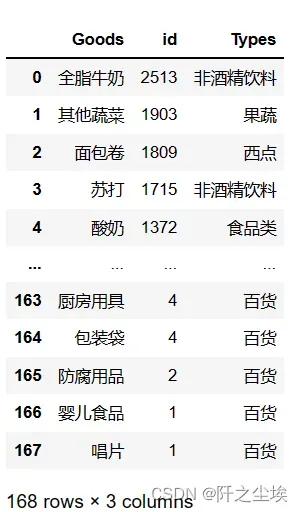
然后我们画出所有大类别商品的销售数量和的比例图:
(sort_links.groupby(['Types']).sum().reset_index() #分组聚合
.sort_values('id',ascending = False) #排序
.assign(ratio=lambda d:d['id']/d['id'].sum())[['Types','ratio']] #计算比例
.set_index('Types').plot #画图
.pie(subplots=True,figsize=(8,8),autopct="%.2f%%",legend=False)
)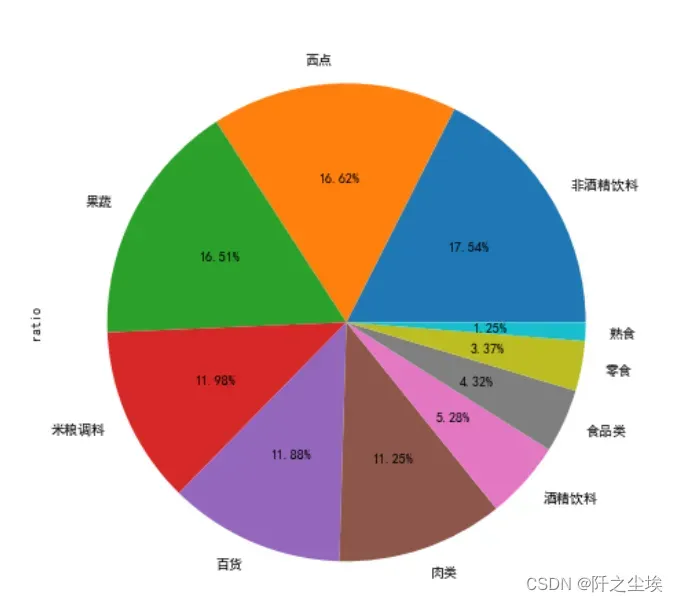
可以看到每种大类商品的销售数量比例。
预处理
将原始数据进行合并,每个订单的商品都弄在一起
data['Goods'] = data['Goods'].apply(lambda x:','+x)
data = data.groupby('id').sum().reset_index()
data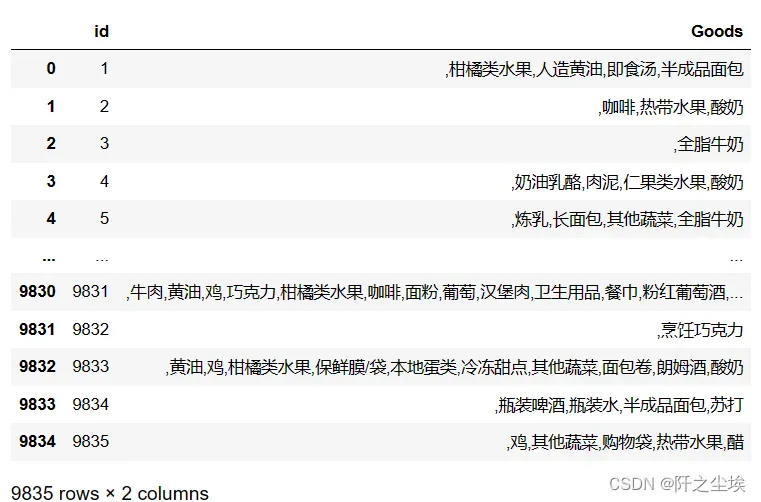
可以看到总共有9835个订单,每个订单里面的商品数量名称都不尽相同。
将上面的订单都变为列表,查看前五个
data['Goods'] = data['Goods'].apply(lambda x :x[1:].split(','))
data_list = list(data['Goods'])
data_list[:5]
每个订单都是一个列表,装着所有的商品名称,数据准备完成,下面进行关联分析
关联分析
导入包,计算模型,得到结果。这里模型的最小支持度选为0.03,最小置信度选为0.4.
# 导入 apyori 模块下的 apriori 函数
from apyori import apriori
results = apriori(data_list, min_support=0.03, min_confidence=0.4)打印结果,并装入数据框方便下面画图:
df=pd.DataFrame()
# 遍历结果数据
lis1=[];lis2=[];lis3=[];lis4=[]
for result in results:
# 获取支持度,并保留3位小数
support = round(result.support, 3)
# 遍历ordered_statistics对象
for rule in result.ordered_statistics:
# 获取前件和后件并转成列表
head_set = list(rule.items_base)
tail_set = list(rule.items_add)
# 跳过前件为空的数据
if head_set == []:
continue
# 将前件、后件拼接成关联规则的形式
related_catogory = str(head_set)+'→'+str(tail_set)
# 提取置信度,并保留3位小数
confidence = round(rule.confidence, 3)
# 提取提升度,并保留3位小数
lift = round(rule.lift, 3)
# 查看强关联规则,支持度,置信度,提升度
print(related_catogory, support, confidence, lift)
lis1.append(related_catogory);lis2.append(support)
lis3.append(confidence);lis4.append(lift)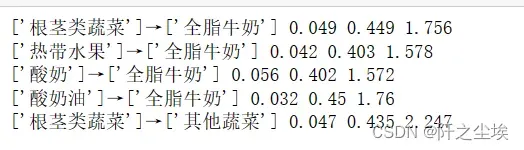
可以看到最终得到了5个关联规则。
变成数据框
df['related_catogory']=lis1
df['support']=lis2
df['confidence']=lis3
df['lift']=lis4
df=df.sort_values('lift',ascending = False)
df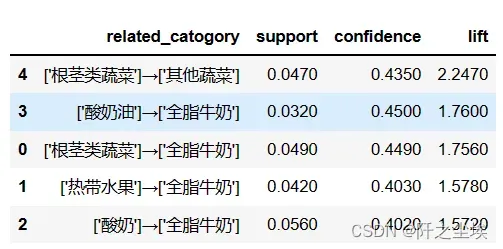
画图之前要对数据做一点变形,使用数据融合
df_bar=pd.melt(df,id_vars=['related_catogory'],var_name='变量名称',value_name='变量值')
df_bar
或者数据堆叠方法,也是一样的效果:
#或者
df.set_index('related_catogory').stack().reset_index()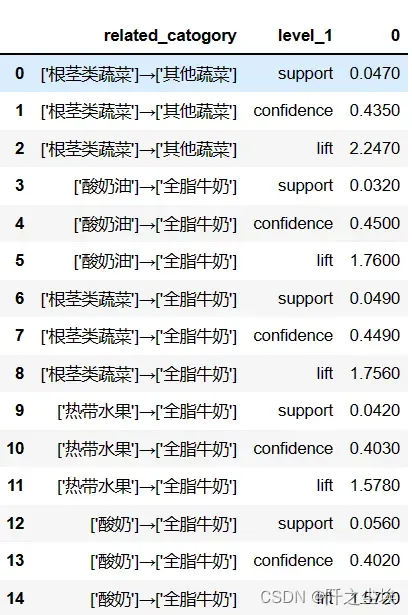
画柱状图:(不喜欢这个颜色可以改palette这个参数。)
plt.figure(figsize=(9,3),dpi=128)
sns.barplot(x=df_bar.related_catogory,y=df_bar.变量值,hue=df_bar.变量名称,palette = "twilight")
plt.xticks(fontsize=8,rotation=10)
plt.xlabel('关联规则')
plt.show()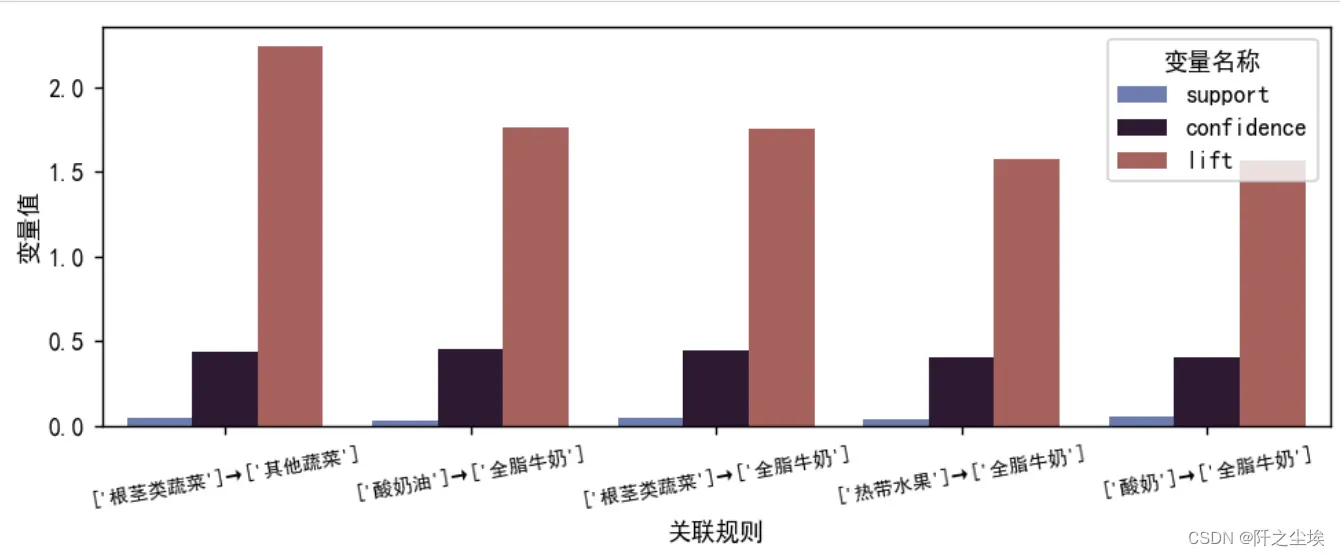
5个关联规则对应的支持度,置信度,提升度都在这个图上了。
结论
本次分析得到,买根‘’茎类蔬菜’ 会促进[‘其他蔬菜’]的销售量,其提升度最大,为2.247。
同样买[‘酸奶’]会促进[‘全脂牛奶’]的销售量。
买[‘根茎类蔬菜’]促进[‘全脂牛奶’]的销售量。
[‘热带水果’]→[‘全脂牛奶’]
[‘酸奶’]→[‘全脂牛奶’]
文章出处登录后可见!