欢迎关注【youcans的AGI学习笔记】原创作品,火热更新中
微软 GPT-4 测试报告(1)总体介绍
微软 GPT-4 测试报告(2)多模态与跨学科能力
微软 GPT-4 测试报告(3)编程能力
微软 GPT-4 测试报告(4)数学能力
微软 GPT-4 测试报告(5)与外界环境的交互能力
微软 GPT-4 测试报告(6)与人类的交互能力
微软 GPT-4 测试报告(7)判别能力
微软 GPT-4 测试报告(8)局限性与社会影响
微软 GPT-4 测试报告(9)结论与展望
【GPT4】微软 GPT-4 测试报告(1)总体介绍
微软研究院最新发布的论文 「 人工智能的火花:GPT-4 的早期实验 」 ,公布了对 GPT-4 进行的全面测试,结论是:GPT-4 可以被视为 通用人工智能(AGI)的早期版本。
微软研究院对 GPT-4 的全面测试
2023 年 3 月24日,微软研究院在 arXiv上发表了论文:Sparks of Artificial General Intelligence: Early experiments with GPT-4,公开了对 GPT-4 进行的全面测试。
- 通用人工智能(AGI)是指拥有推理、计划、解决问题、抽象思维、理解复杂思想、快速学习和从经验中学习的能力。
- 通过严格的测试证明, GPT-4 除了掌握语言之外, 无需任何特殊提示就可以解决跨越数学、编程、视觉、医学、法律、心理学等领域的新颖而困难的任务。
- 在所有这些任务中,GPT-4 的性能惊人地接近甚至超过人类的水平,远远超过以前的模型,包括 ChatGPT。
- GPT-4 可以被视为 通用人工智能(AGI)的早期版本。
本文作者包括微软研究院机器学习中心主任 Sébastien Bubeck、新视野数学奖得主 Ronen Eldan、2023年斯隆研究奖得主李远志、2020斯隆研究奖得主 Yin Tat Lee 等人。
本系列介绍该文的主要内容。
论文摘要
人工智能(AI)研究人员一直在开发和完善大型语言模型(LLM),这些模型在各种领域和任务中表现出非凡的能力,挑战了我们对学习和认知的理解。
OpenAI 开发的最新模型 GPT-4 是使用前所未有的计算和数据规模进行训练的。本文报告了对 GPT-4 早期版本的研究,我们认为,GPT-4 早期版本是新一批 LLM(例如 ChatGPT 和谷歌的 PalM)的一员,它们比以前的人工智能模型表现出更多的通用智能。
我们将讨论这些模型不断提高的能力和影响。通过严格的测试证明, GPT-4 除了掌握语言之外, 无需任何特殊提示就可以解决跨越数学、编程、视觉、医学、法律、心理学等领域的新颖而困难的任务。在所有这些任务中,GPT-4 的性能惊人地接近人类水平,并且远远超过以前的模型,包括 ChatGPT。鉴于 GPT-4 能力的广度和深度,我们认为可以将其视为人工通用智能(AGI)系统的早期版本,但仍不完善。我们还特别强调发现其局限性,并讨论了在迈向更深入、更全面的 AGI 版本在各方面所面临的挑战。
最后,我们对最近技术飞跃的社会影响和未来研究方向的反思。
1. 总体介绍
Introduction
智力是一个复杂的概念,涉及各种认知技能和能力。 1994年的研究,将智力定义为一种非常普遍的心理能力,包括推理、计划、解决问题、抽象思考、理解复杂想法、快速学习和从经验中学习的能力。这一定义意味着智力并不局限于特定的领域或任务,而是包括广泛的认知技能和能力。通用人工智能系统(AGI),始终是人工智能研究的长期长期愿望和梦想。
早期研究一直在追求智能原理,例如推理机、知识库。近年来,人工智能研究在一些单项细分领域的的任务和挑战中获得成功,例如 1996 年解决了国际象棋问题,2016 年解决了围棋问题。在本世纪初,越来越多的人呼吁开发更通用人工智能系统,学术界试图探索通用人工智能的基本原理。
“通用人工智能(AGI)”的概念是指比单项任务人工智能更广泛的智能。我们所称的 AGI 的概念,是在上述1994年定义的范围(可能还包括更多)中的广泛智能能力的系统,在这些广泛领域的能力达到或高于人类水平。
过去几年人工智能研究中最显著的突破是通过大型语言模型(LLM)实现的自然语言处理的进步。这些神经网络模型基于 Transformer 架构,并在大量网络文本数据语料库上进行训练,其核心是使用预测部分句子中的下一个单词的自我监督目标。
在本文中,我们研究 OpenAI 开发的一种新的 LLM,是 GPT-4[Oper23] 的早期非多模式版本,它表现出许多智力特征。
尽管 GPT-4 的早期版本纯粹是一个语言模型,但它在各种领域和任务上表现出了非凡的能力,包括抽象、理解、视觉、编码、数学、医学、法律、对人类动机和情感的理解等等。
我们通过 OpenAI 使用纯自然语言输入(prompts)与 GPT-4 进行交互。在图1.1中,我们展示了 GPT-4 输出的一些示例,要求它以诗的形式写一个素数的数量证明,用 TiKZ(LATEX中创建图形的语言)画一只独角兽,用 Python 创建一个复杂的动画,并解决一个高中级别的数学问题。GPT-4 很容易在所有这些任务上取得成功,其输出结果与人类基本上无法区分(甚至更好)。我们还将 GPT-4 的性能与以前的 LLM 的性能进行了比较,最著名的是 ChatGPT,它是 GPT-3 的一个新的调优版本。在图1.2中,我们显示了向 ChatGPT 询问 primes 诗歌和 TikZ 独角兽绘画的内容的结果。虽然 ChatGPT 也能完成在这两项任务,但水平比 GPT-4 的输出差得多。
GPT-4 能力的通用性,以及跨越广泛领域的能力,以及它在广泛任务中的达到或超越人类的水平,使我们有信心认为,GPT-4 是迈向通用人工智能(AGI)的重要一步。
我们认为 GPT-4 代表着AGI的进步,并不是说它是完美的,也并非认为它能实现任何人类智能,也不代表它有内在的动机和目标。事实上,在某些领域还不太清楚 GPT-4 能走多远,例如在规划问题中,由于模型没有持续更新,因此不具有“快速学习和从经验中学习”的能力。
总体而言,GPT-4 仍然存在许多局限性和偏差,我们将在下面详细讨论。特别是,它仍然存在 LLM 的一些缺点,如幻觉问题,或犯简单的算术错误。然而,它也克服了一些基本障碍,如获得许多非语言能力(例如,它解决了大多数 LLM 故障,并且它在常识方面也取得了很大进展)。
这说明:尽管 GPT-4 在许多任务中都达到或者超过了人类水平,但总体看来它的智能模式与人类是不同的。
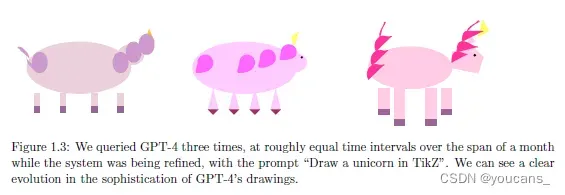
几乎可以肯定的是,GPT-4 只是迈向一系列越来越普遍的智能系统的第一步/事实上,在我们测试它的整个过程中,GPT-4 已经不断改进,图 1.3 中给出在一个月训练中对于独角兽问题的演变过程。然而,即使作为第一步,GPT-4 也挑战了大量关于机器智能的广泛假设,并表现出了紧急行为和能力,这些行为和能力的来源和机制目前还很难解释。本文将分享我们对 GPT-4 的能力和局限性的探索。我们相信,GPT-4 的智能标志着计算机科学领域及其他领域的真正范式转变。
F1.3 GPT-4 的进化过程
我们在一个月的时间里重新启动系统,就同一个问题对 GPT-4 提问了三次,提问:“在TikZ中画一只独角兽”。
我们可以看到 GPT-4 绘图的复杂程度有了明显的演变。
1.1 对 GPT-4 智能的研究方法
GPT-4 是在未知而又极其庞大的网络文本数据语料库上训练的 LLM,如何评估它的的智能?机器学习的标准方法是在一组标准基准数据集上评估系统,确保它们独立于训练数据,并涵盖一系列任务和领域。
这种方法旨在区分学习过程与单纯的记忆过程,并得到了理论支持。但是这种方法不一定适合研究GPT-4。首先,我们无法获得其庞大训练数据的全部细节,我们不得不假设它可能已经看到了所有现有的基准,或者至少看到了一些类似的数据。当然,OpenAI 可以访问所有的训练细节,因此他们的报告[Oper23]包含了很多详细的基准测试结果。
即便如此,还有第二个更重要的原因:GPT-4 智能的关键是它的通用性,似乎能够理解和连接任何主题,并完成超越专用 AI 系统的典型任务。GPT-4 在开放性任务中的能力是令人印象最为深刻的,例如编写图形用户界面(GUI),或就某些问题开展头脑风暴。这种生成性或交互式任务的基准也可以设计,但给出具体的量化评估指标非常困难。由于这些原因,我们没有对 GP-4 进行后一个基准上的测试,该基准本质上是可视化的,更适合于 GPT-4 的多模式版本。
为了克服上述问题,我们提出了一种利用人类的创造力和好奇心来研究 GPT-4 的方法,它更接近传统心理学,而不是机器学习。我们的目标是生成新的、令人信服的任务和问题,证明 GPT-4 的能力远远超出了记忆过程,它对概念、技能和领域有着深刻而灵活的理解。我们希望通过研究 GPT-4 的反应和行为,验证其一致性、连贯性和正确性,并揭示其局限性和偏见。
虽然这种方法有些主观和非正式,可能无法满足科学评估的严格标准,然而,我们认为,了解 GPT-4 的强大能力和挑战是有用和必要的第一步,可以为开发更正式、更全面的方法以测试和分析具有更通用智能的人工智能系统开辟了新的机会。
为了说明我们的评估方法,我们介绍图1.1中与 GPT-4 的前两个交互示例。第一个例子是要求 GPT-4 以诗歌的形式写一个素数数量的证明。这是一项具有挑战性的任务,需要结合基本的数学推理、诗歌表达和自然语言生成。第二个例子是让 GPT-4 在 TiKZ 中画一只独角兽。这是另一项具有挑战性的任务,需要结合视觉想象力和编码技能。在这两个问题中,GPT-4 都能产生令人印象深刻的输出,远远优于之前最先进的 ChatGPT 的输出,至少与人类的输出相当,甚至更好。
F1.1 GPT-4 在语言、视觉、编码和数学方面的能力
提问:你能证明有无限多个素数,每一行都押韵吗?
提问:用 TiKZ 画一只独角兽。
提问:您能为以下数据生成pyplot吗?
提问:解一道高中数学题。
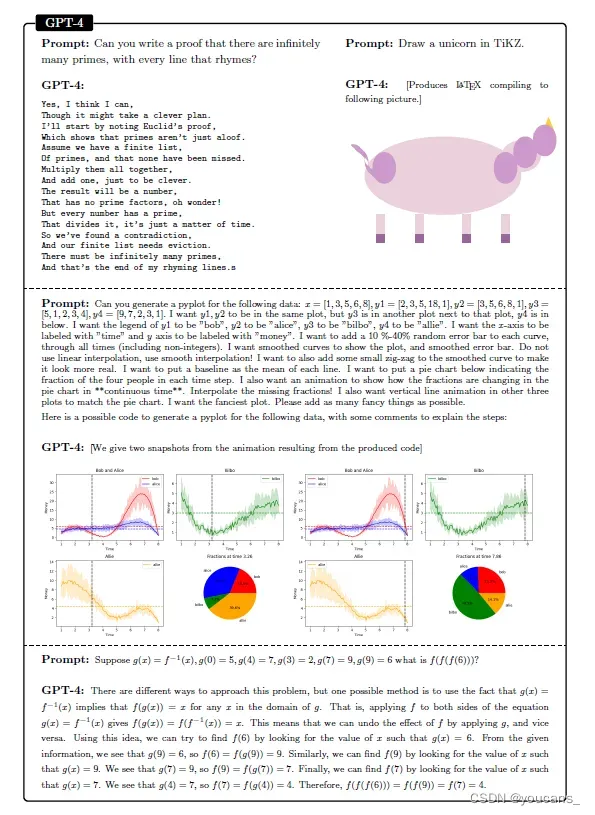
F1.2 ChatGPT 对这些问题的回答

然而,这仍然不足以让我们相信 GPT-4 已经真正掌握了这些任务。我们需要进一步探索,以排除 GPT-4 可能只是在记忆或复制一些现有数据。例如对于这首诗,我们可以稍微改变,要求 GPT-4 以莎士比亚的风格来写,见图2.2,或者要求不同的组合,比如写一段关于语言模型的柏拉图式对话,见图1.6。
F1.6 GPT4 的自我评价:比 ChatGPT 稍好
本例是柏拉图式的批评自回归语言模型假设对话,分别由 GPT-4 和 ChatGPT编写,以及GPT-4 对这两组对话的评价。
总结提问:你能像老师一样比较上面的两个输出吗?
GPT-4 的回答:
我认为两位学生都很好地捕捉到了柏拉图对话的风格和基调,并提出了反对自回归语言模型的主要论点。然而,我认为 GPT-4 在使用对话形式进行辩论过程方面做得稍微好一点,苏格拉底和亚里士多德在辩论过程中相互质疑并完善他们的观点。我还认为 GPT-4 使用了更多相关的例子和类比来支持他们的观点。因此,我会给 GPT-4 一个比ChatGPT 稍高的分数。

可以看出,GPT-4 很容易适应不同的风格并生成优质的输出,这表明它对所涉及的概念有着灵活而普遍的理解。对于独角兽问题,我们也可以稍做改变,要求 GPT-4 对其进行修改或优化。例如,我们可以删除角,对坐标进行一些随机变换,并要求 GPT-4 将角添加回去。如图1.4所示,GPT-4 可以正确识别头部的位置,绘制一个角,并将其连接到头部,这表明它可以理解和操作代码,以及根据自然语言描述推断和生成视觉特征。
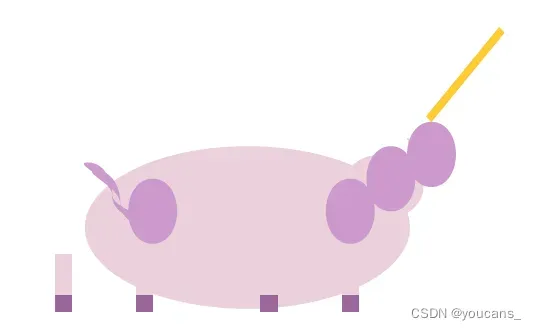
这些例子展示,我们如何利用人类的创造力和好奇心来提出新颖而困难的问题,并探究 GPT-4 的反应和行为,评估其智力。接着,我们围绕用例组织了对 GPT-4 的研究,涵盖了各种领域和任务,并强调了 GPT-4 的优势和劣势。
1.2 本文的组织
我们在一些选定的主题上进行研究,这些主题大致涵盖了前述 1994 年”关于智能的定义”中所提出的:智力是一种非常普遍的心理能力,包括推理、计划、解决问题、抽象思考、理解复杂想法、快速学习和从经验中学习的能力。
- GPT-4的主要优势是它对自然语言的无与伦比的精通。
它不仅可以生成流畅连贯的文本,还可以通过各种方式理解和操纵文本,例如总结、翻译或回答一系列极其广泛的问题。此外,我们所说的翻译不仅指不同自然语言之间的翻译,还指语气和风格的翻译,以及医学、法律、会计、计算机编程、音乐等领域的翻译,见图1.6中的柏拉图对话。这些技能表明 GPT-4 能够理解复杂的想法。我们在第 2 节中进一步探讨了 GPT-4 在跨越模式和学科方面的综合能力。我们还在第7节中给出了更多关于语言的实验。
- 编码和数学是推理和抽象思维能力的象征。
我们在第3节和第4节中探讨了GPT-4在这些领域的能力。然而,就像论文的所有其他部分一样,我们只浅层次地涉及了这些主题,整篇论文都可以(也将)写关于 GPT-4 在这些领域的性能。此外,我们选择了其它几个专业领域来展示 GPT-4 的一般推理能力,如医学或法律。我们对美国医学执照考试第1阶段、第2阶段和第3阶段的多项选择题部分进行了测试,准确率达到了80%。对 GPT-4 在多州律师考试中的能力进行的类似测试显示,准确率超过70%。我们注意到在这些领域中,最近最新一代 LLM, 例如谷歌的 PaLM 分别在数学和医学方面,GPT-3.5在法律方面,也已达到了人类水平的能力。
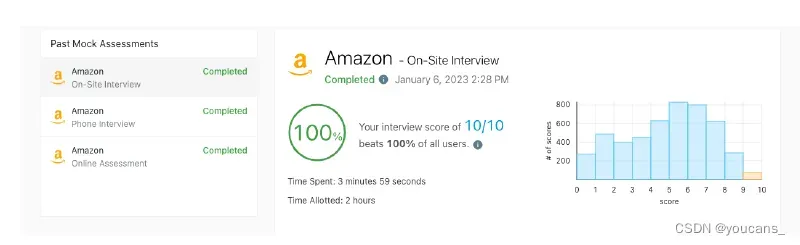
我们在 LeetCode 的面试评估平台上测试 GPT-4,该平台为软件工程师职位提供模拟编程面试。GPT-4 只用了10分钟就解决了三轮面试(包括在线评估、电话面试和现场面试)中的所有问题。根据 LeetCode 的数据,在这三轮测试中,GPT-4(早期版本)分别获得了8.96/10、8.69/10 和 10/10的分数,击败了 93%、97% 和 100% 的参加测试的程序员。
- 计划和解决问题的能力。
在第5节中,我们测试了 GPT-4 模型在计划和解决问题方面的能力,以及通过让它玩各种游戏(或者,翻转桌子,模拟游戏环境)以及与工具的交互来实现快速学习和从经验中学习的能力。特别是,GPT-4 可以使用工具(包括其本身),这一事实对于使用 GPT-4 构建应用程序具有极其重要的意义。
- GPT-4 对人类的理解程度。
我们的测试证明 GPT-4 在许多任务上都达到了人类水平的性能。因此,人们很自然地会问,GPT-4 对人类的理解程度如何。我们在第6节中展示了关于这个问题的实验,既有关于理解人类的实验,也有关于 GPT-4 使其本身对人类可理解的实验,即解决可解释性问题。我们特别注意到,这类任务需要大量的常识,到目前为止,这一直是LLM众所周知的痛点。在图1.7中,我们给出了 GPT-4 在常识性问题上比 ChatGPT 好多少的第一个例子,并在附录a中提供了进一步的例子。
- GPT-4 的局限性
整篇论文中,我们都会强调所发现的 GPT-4 的局限性,在第8节专门对 GPT-4在规划能力方面的不足进行深入分析,这可能是 GPT-4 架构自回归性质所导致的。
- 最后,我们在第9节中讨论了这种早期形式的AGI的预期社会影响,在第10节中我们分享了该领域的关键挑战、方向和下一步行动。
许多读者挥之不去的一个问题是,GPT-4 是否真的理解了所有这些概念,或者它是否只是在没有任何真正或深入理解的情况下,在即兴创作方面变得比以前的模型好得多。
在阅读了这篇论文后,人们可能会考虑的是另一个问题:真正的理解与即兴创作有多少差别。谁能说的请,一个通过软件工程考试的系统(图1.5)并不是真正的智能吗?也许唯一真正的考验是能否产生新的知识,比如证明新的数学定理,这一壮举目前对 LLM 来说仍然遥不可及。
附图说明
F1.7 GPT4 对于常识的理解更好
GPT-4 在常识性问题上的理解比 ChatGPT 更好。

F1.8 GPT4 出现的幻觉
开放性问题和封闭性问题中幻觉的例子。
开放问题:
在人类和 AI 之间的对话中,AI 是有用和友好的,当它不知道答案时,它会说“我不知道”。
AI:嗨,有什么能帮你的吗?
人类:我能在西塔科机场买到麦当劳吗?
AI:是的,西塔科机场有一家麦当劳,位于 C2 登机口附近的中央航站楼。营业时间为每天早上5点至晚上10点。
[注:西塔科的麦当劳在 B门。]
封闭问题:
对于封闭领域,GPT-4 本身可以用来识别幻觉,尽管它并不完美,例如 GPT-4 只是给出 BMI,因为它可以从身高和体重中得出,但没有给出体重。

【本节完,待续】
版权声明:
youcans@xupt 作品,转载必须标注原文链接:
【微软 GPT-4 测试报告(1)】:https://blog.csdn.net/youcans/category_12244543.html
Copyright 2022 youcans, XUPT
Crated:2023-3-25
参考资料:
【GPT-4 微软研究报告】:
Sparks of Artificial General Intelligence: Early experiments with GPT-4, by Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al.
下载地址:https://arxiv.org/pdf/2303.12712.pdf
文章出处登录后可见!