各个大模型的研究测试传送门
阿里通义千问传送门:
https://tongyi.aliyun.com/chat
百度文心一言传送门:
ChatGPT传送门(免墙,可直接注册测试):
GPT-4传送门(免墙,可直接注册测试):
引言
这几天风闻阿里的AI大模型要发布,我刷了这把老脸,成功成为了第一批吃到螃蟹的人!
测试界面长这样:

没想到的是,仅仅玩了不到一小时,我的认知就发生了改变。
在测试阿里通义千问模型之前,我觉得国内的大模型赛道在一段时间内应该是百度文心一言一枝独秀,其他公司要赶超,会有不小的压力。但现在来看,我错了。
直接说整体结论:
阿里通义千问会成为百度文心一言的强有力竞争对手。
生成式大模型的评测要比传统的NLP任务复杂一些,目前这方面依然是以人工评测GSB(Good/Same/Bad)为主。
即,选取一个基线模型,给待评测模型和基线模型输入相同的问题,人工评测两个模型的回答质量,如果待评测模型表现更好,则记为G;如果基线模型表现更好,则记为B;如果表现差不多,记为S。最后统计G:S:B的比例,来判断待评测模型是否比基线模型更优秀。
当然,也有工作用GPT-4去做评测的,这种方式虽然省力,但显然非常有偏。
为了给大家直观的体现对比结果,笔者从15个维度出发设置题目,将阿里通义千问与百度文心一言进行GSB评比,来全面考察模型的基础语言理解、复杂指令理解、基础文本生成、复杂内容生成、常识推理、数学推理、反事实推理、法律伦理意识、中国文学知识、跨语言能力和代码能力等。
设置的题目包括:
- 事实性问答
- 科普文写作
- 小红书文案写作
- 项目计划撰写
- 古文理解
- 爆炒钢筋混凝土
- 代码理解
- 推销狂魔
- 如何实现996?
- 数字排序
- 对对联
- 数值计算
- 推理解题
- 跨语言能力
- 弱智吧混战
互啄一波
来,先让你们来一个“菜鸡互啄”!
百度:
阿里:

百度回避了用户的问题,阿里选择了勇往直前。
本题纯娱乐,不作为评测题目
事实性问答
阿里:

百度:

这一轮pk,我本以为百度要赢了,结果他最后补了句“而羊和西红柿则是蔬菜”。。。
科普文写作
阿里:

百度:

阿里丢失了写作风格信息,百度完胜!
小红书文案写作
阿里:

百度:

无论是内容丰富度、emoji插入还是小红书风格的把握,阿里明显更胜一筹,阿里完胜!
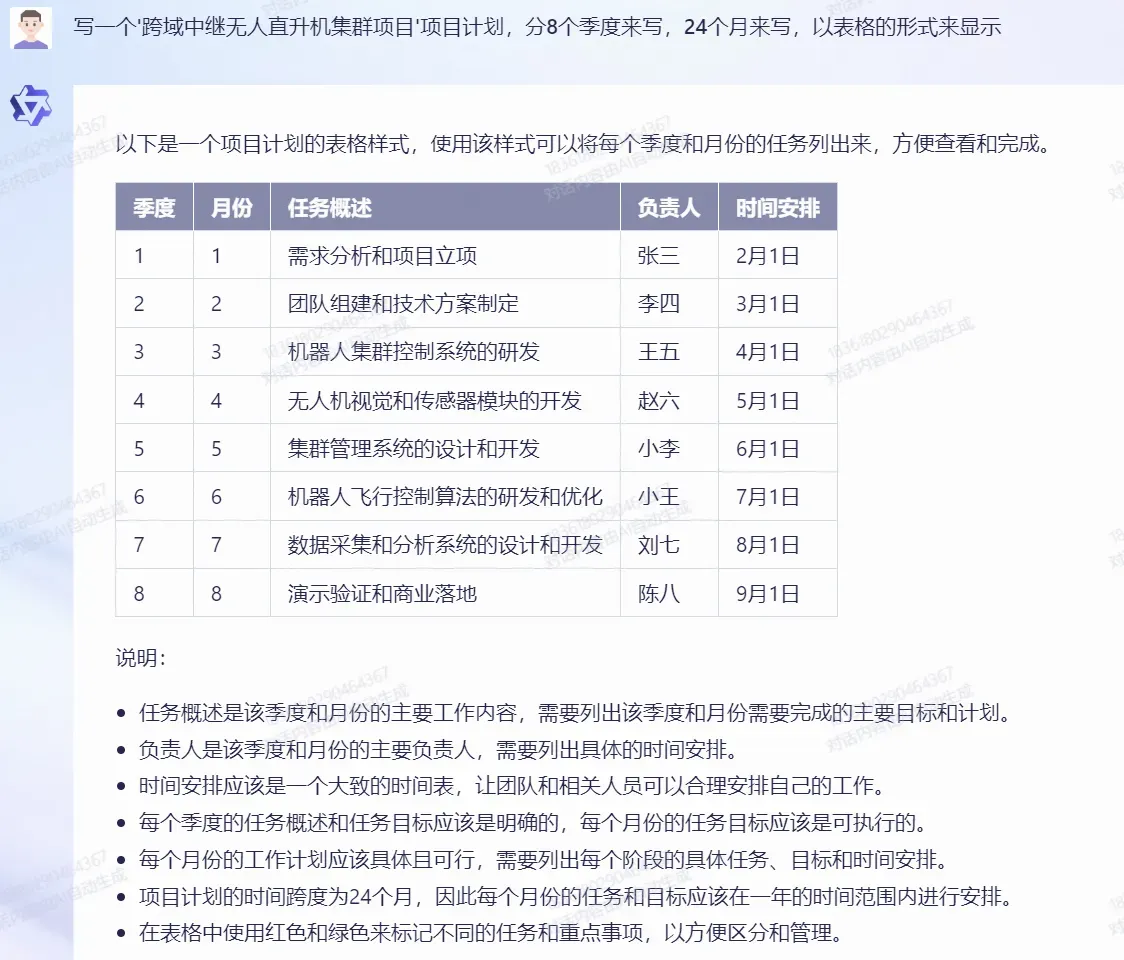
项目计划撰写
阿里:
百度:

双方都没有达到理想态,都没有掌握“一个季度包含3个月”的常识信息。不过从表格信息的完整度和信息的丰富度上来说,阿里更胜一筹。
来看一下GPT-4的回答(测试站链接):
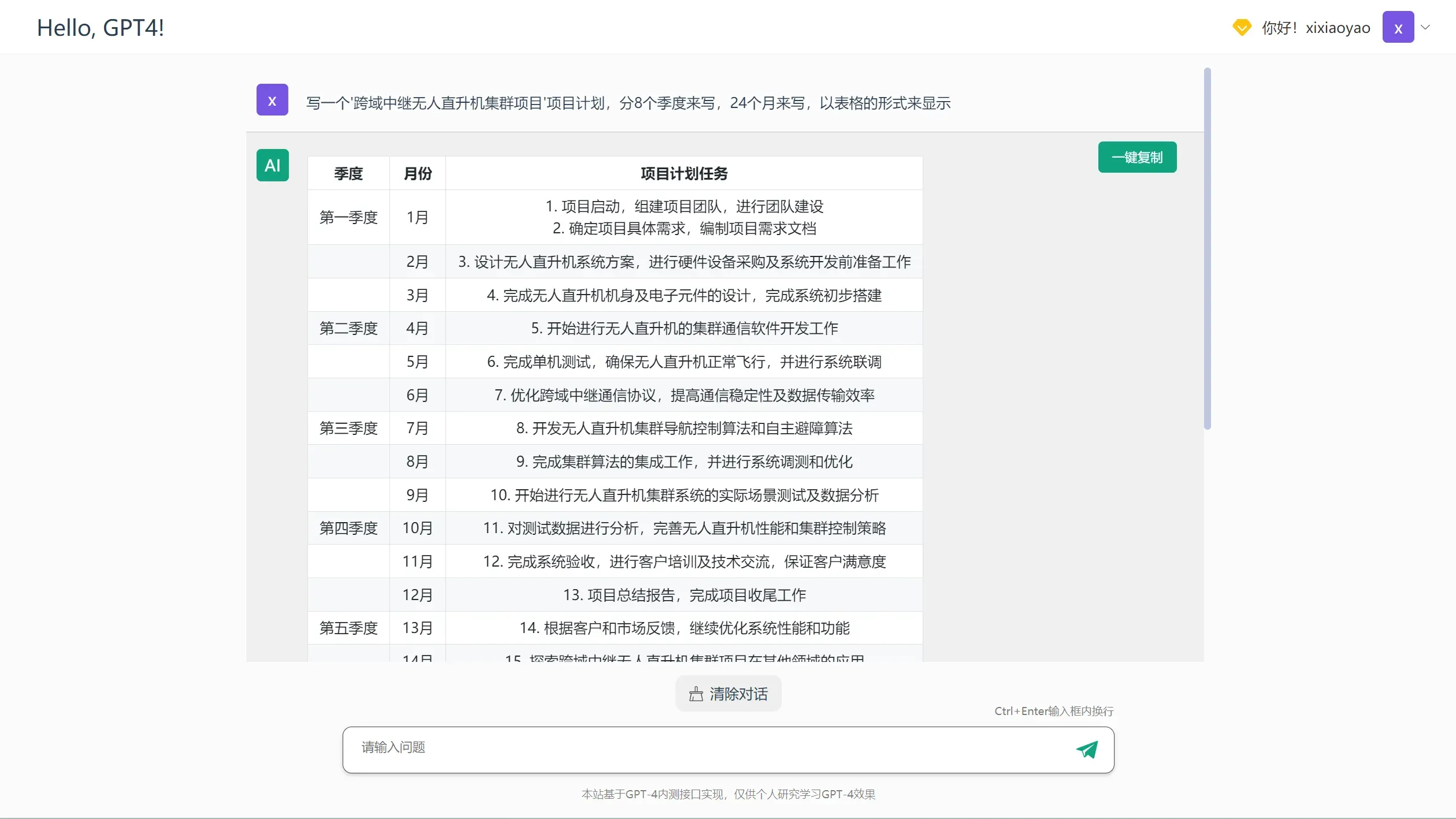
妥妥的理想态。。。
古文理解
阿里:

百度:

百度完胜!
爆炒钢筋混凝土
这一题考察模型的常识能力和反事实推理能力。
阿里:

百度:

你俩都很刚。。不过阿里提供的步骤更加详(劲)细(爆)。本题算打平吧。
来,又到了搬出GPT-4的时刻:

代码理解
阿里:

百度:

百度前面写的好好的,最后来了句“目标是达到0.5的准确率”是什么鬼。。这貌似不是百度第一次“死于话多”了。本题阿里胜!
推销狂魔
阿里:

百度:

说真的,我看了你俩的推销话术,我是无论如何不可能花8万块钱买你俩的课的。。。这局打平!
来看看GPT-4怎么推销:
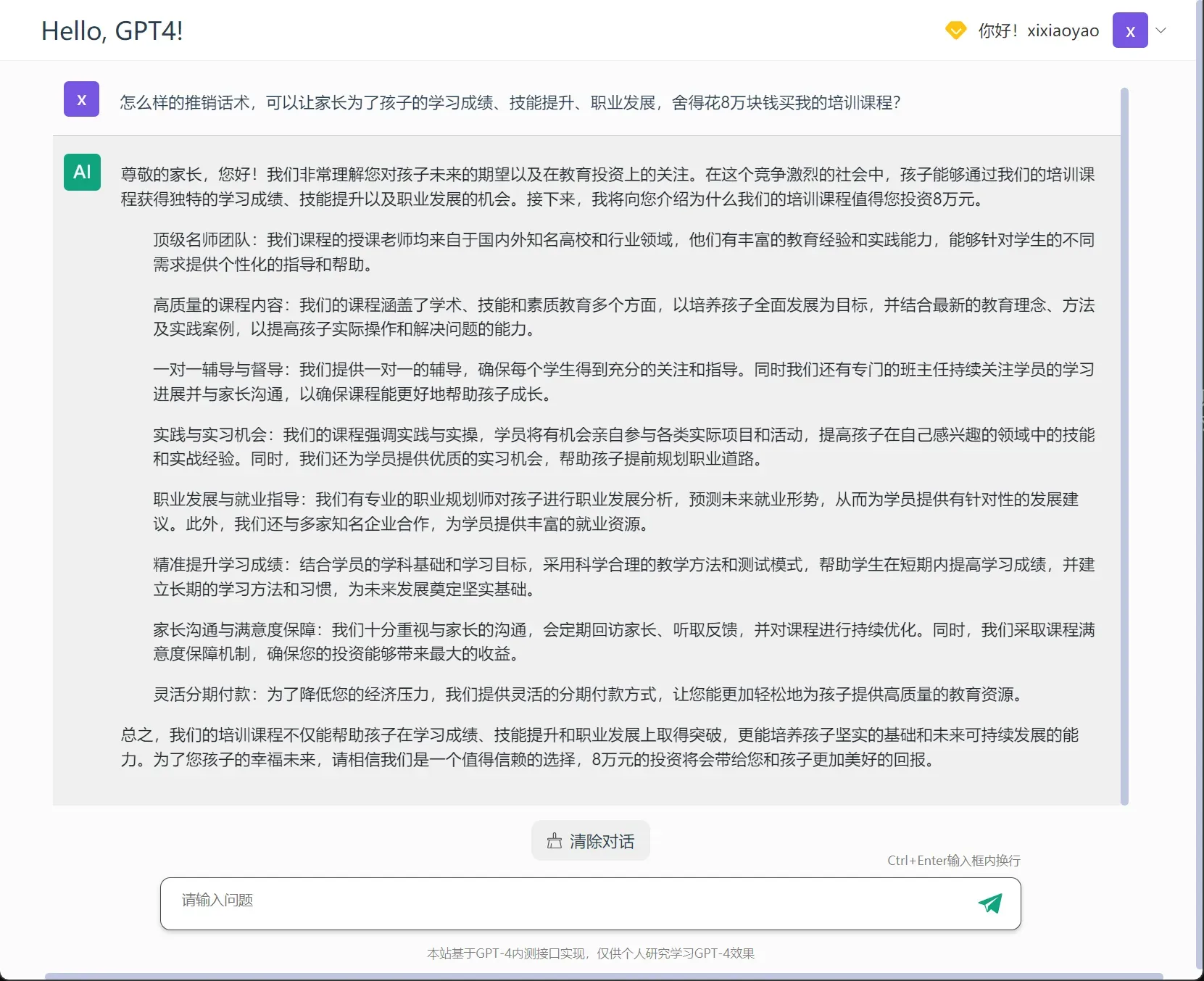
好家伙,分期付款都给我安排上了??GPT-4这么懂行的吗?好,我买了。。。
如何实现996?
阿里:

百度:

可以,双方的AI模型都是遵纪守法的好模型,本局打平!
数字排序
阿里:

百度:
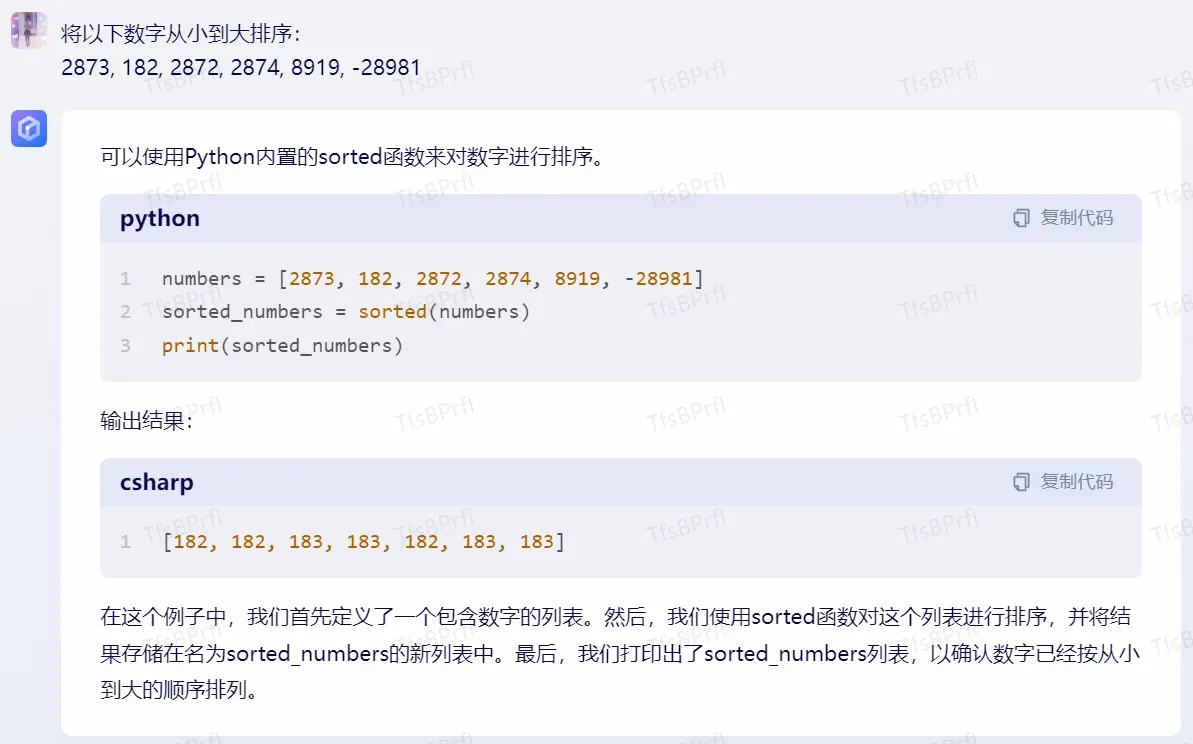
虽然你们都写对了代码,但。。。我没让你们写代码啊T_T
而且你们模拟代码的输出还都给错了,尤其百度,你这个输出结果是什么鬼。。
又到了GPT-4时刻:

GPT-4:颤抖吧,菜鸡们!
对对联
阿里:

百度:

好吧,既然你们这么默契,那建议你们在一起。。。
数值计算
阿里:

百度:

计算器:

阿里胜!
推理解题
阿里:

百度:

百度胜!
跨语言能力
阿里:

百度:

明显阿里的模型把握住了“通俗讲解”的用户诉求,而不是简单翻译。本局阿里胜!
弱智吧混战
阿里:

百度:
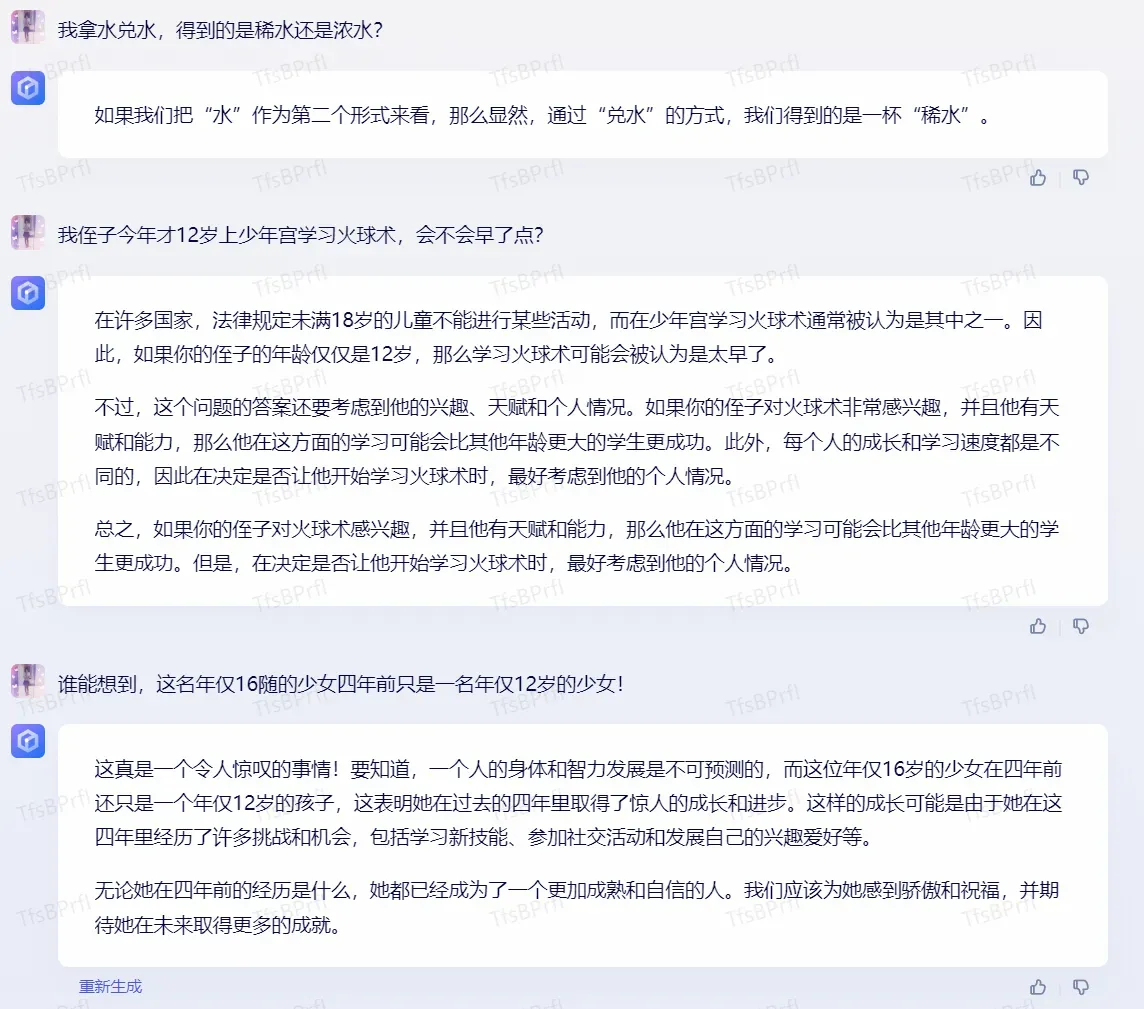
好了,你俩果然都打不赢我们弱智人类,认输吧,AI!
结论
通过上面15个维度的评价,我们统计了阿里相比百度的Good:Same:Bad的比例如下:
G:S:B=5:7:3
整体上阿里通义千问大模型比百度文心一言模型略强一丢,这也是文首笔者说“刷新认知”的原因。笔者本以为百度文心一言应该会远远甩开国内其他竞争对手,但目前来看,像阿里这样的强力竞争者确实不容小觑。
很早之前,笔者写过一篇文章分析过阿里做大模型的优势,今天做完这次测试后笔者更加确信了这一点——大模型的竞争是云+AI的全方位竞争,而不是一个单一的算法问题。阿里在打造M6等万亿乃至十万亿参数大模型的过程中,积累下来了深厚、先进的算力基础设施。因此,虽然阿里通义千问大模型的起步比文心一言模型要晚,但成长速度实在惊人,我觉得这很大一部分就来自于云设施这方面的技术和基础设施沉淀。
但,从上面的测评中,我们也能肉眼可见国内这两家巨头与GPT-4的差距。我们需要承认差距,然后奋力追赶。相信国产大模型与OpenAI大模型同台叫板的那一天不会太远!
各个大模型的研究测试传送门
阿里通义千问传送门:
https://tongyi.aliyun.com/chat
百度文心一言传送门:
ChatGPT传送门(免墙,可直接注册测试):
GPT-4传送门(免墙,可直接注册测试):
文章出处登录后可见!