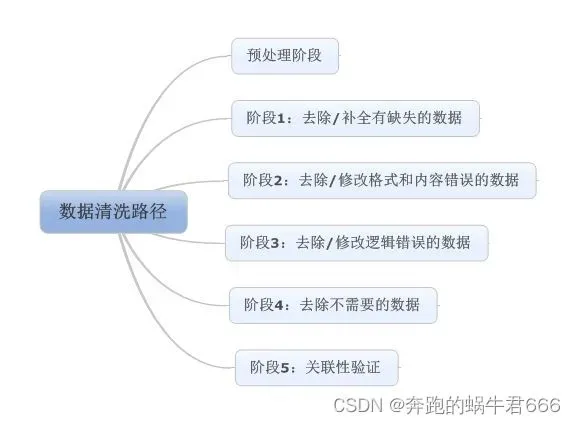
一.预处理阶段
预处理阶段主要做两件事情:
一是将数据导入处理工具。通常来说,建议使用数据库,单机跑数搭建MySQL环境即可。如果数据量大(千万级以上),可以使用文本文件存储+python操作的方式
而是看数据。这里包含两个部分:一是看元数据,包括字段解释,数据来源,代码表等等一切描述数据的信息;二是抽取一部分数据,使用人工查看方式,对数据本身有一个直观的了解,并且初步发现一些问题,为之后处理做准备
第一步:缺失值清洗
缺失值是最常见的数据问题,处理缺失值也有很多方法,我建议按照以下四个步骤进行:
1.确定缺失值范围:对每个字段都计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定侧列,可用下图表示:
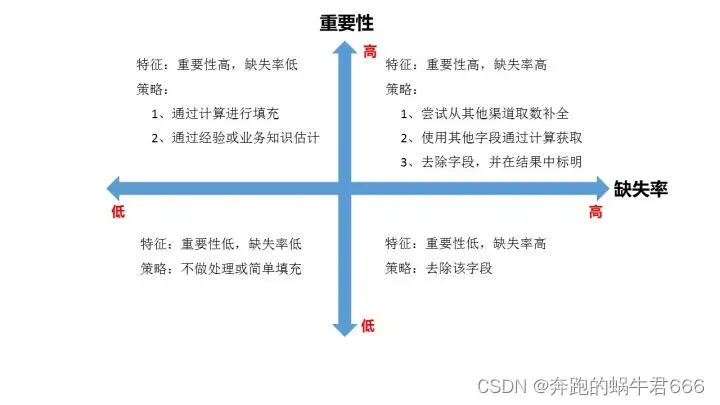
2.去除不需要的字段:这一步很简单,直接删掉即可,但强烈建议清洗每做一步都备份一下,或者在小规模数据上试验成功在处理全量数据,不然删错了会追悔莫及(写SQL的时候delete一定要配where)
3.填充缺失内容:某些缺失值可以进行填充,方法有以下三种:
以业务知识或经验推测填充缺失值
以同一指标的计算结果(均值,中位数,众数等)填充缺失值
以不同指标的计算结果填充缺失值
前两种方法比较好理解,第三种方法,举个最简单的例子:年龄字段确实,但是有屏蔽后六位的身份证号
4.重新取数:如果某些指标非常重要又缺失率高,那就需要和取数人数或业务人员了解,是否有其他渠道可以取到相关数据
第二步:格式内容清洗
如果数据是由系统日志而来,那么通常在格式和内容方面,会与元数据的描述一致。而如果数据是由人工收集或用户填写而来,则有很大可能性在格式和内容上存在一些问题,简单来说,格式内容问题有以下几类:
1.时间,日期,数值,全半角等显示格式不一致
这种问题通常与输入端有关,在整合多来源数据时也有可能遇到,将其处理成一致的某种格式即可
2.内容中有不该存在的字符
某些内容可能只包括一部分字符,比如身份证号是数字+字母,中国人姓名是汉字。最典型的就是头,尾,中间的空格,也可能出现姓名中存在数字符号,身份证号中出现汉字等问题。这种情况下,需要以半自动校验半人工方式来找出可能存在的问题,并去除不需要的字符
3.内容与该字段应有内容不符
姓名写了性别,身份证号写了手机号等等,均属这种问题。但该问题特殊性在于:并不能简单地以删除来处理,因为成因有可能是人工填写错误,也有可能是前段没有校验,还有可能是导入数据时部分或全部存在列没有对齐的问题,因此要详细识别问题类型
格式内容问题是比较细节的问题,但很多分析失误都是栽在这个坑上,比如跨表关联或vlookup失败(多个空格导致工具认为“陈丹怡”和“陈 丹怡”不是一个人),统计值不全(数字里掺个字母当然求和时结果有问题),模型输出失败或效果不好(数据对错列了,把日期和年龄混了)因此,请各位务必注意这部分清晰工作,尤其是在处理的数据是人工收集而来,或者你确定产品前端校验设计不太好的时候
第三步:逻辑错误清晰
这部分的工作是去掉一些使用简单逻辑推理就可以直接发现问题的数据,防止分析结果走偏。主要包含以下几个步骤:
1.去重
有的分析师喜欢把去重放在第一步,但我强烈建议把去重放在格式内容清洗之后,原因已经说过了(多个空格导致工具认为“陈丹怡”和“陈 丹怡”不是一个人,去重失败)而且,并不是所有重复都能这么简单的去掉
我曾经做过电话销售相关的数据分析,发现销售们为了抢单剑指无所不用其极。举例,一家公司叫做“ABC管家有限公司”,在销售A手里,然后销售B为了抢这个客户,在系统里录入一个“ ABC管家有限公司”。你看,不仔细看你都看不出两者的区别,而且就算看出来了,你能保证没有“ABC管家有限公司 ”这种东西存在么?这种时候,要么去抱RD大腿,要么要求人家给你写模糊匹配算法,要么肉眼看吧
2.去除不合理值
一句话就能说清楚:有人填表的时候瞎填,年龄200岁,年收入1000000万,这种的就要么删掉,要么按缺失值处理。这种值如何发现?提示:可用但不限于箱型图
3.修正矛盾内容
有些字段是可以互相验证的,举例:身份证号是1101031980XXXXXXXX,然后年龄填18岁,我们虽然理解人家永远18的想法,但得知真实年龄可以给用户提供更好的服务。在这种时候,需要根据字段的数据来源,来判断哪个字段提供的信息更为可靠,去除或重构不可靠的字段
逻辑错误除了以上列举的情况,还有很多未列举的情况,在实际操作中要酌情处理。另外,这一步骤在之后的数据分析建模过程中有可能重复,因为即时问题很简单,也并非所有问题都能够一次找出,我们能做的是使用工具和方法,尽量减少问题出现的可能性,使分析过程更为高效
第四步:非需求数据清洗
这一步说起来非常简单:把不要的字段删了
但实际操作起来,有很多问题,例如:
- 把看上去不需要但实际上对业务很重要的字段删了
- 某个字段觉得有用,但又没想好怎么用,不知道是否该删
- 一时看走眼,删错字段了
前两种情况我给的建议是:如果数据量没有大到不删字段就没办法处理的程度,那么能不删的字段尽量不删。第三种情况,请勤备份数据
第五步:关联性验证
如果你的数据有多个来源,那么有必要进行关联性验证。例如,你有汽车的线下购买信息,也有电话客服问卷信息,两者通过姓名和手机号关联,那么要看一下,同一个人线下登记的车辆信息和线上问卷出来的车辆信息是不是同一辆,如果不是(别笑,业务流程设计不好是有可能出现这种问题的)那么需要调整或去除数据
严格意义上来说,这已经脱离数据清洗的范畴了,而且关联数据变动在数据库模型中就应该涉及。但我还是希望提醒大家,多个来源的数据整合是非常复杂的工作,一定要注意数据之间的关联性,尽量在分析过程中不要出现数据之间互相矛盾,而你却毫无觉察的情况
二.准备工作
拿到数据表之后,先做这些准备工作,方便之后的数据清洗
1.给每一个sheet页命名,方便寻找
2.给每一个工作表加一列行号,方便后面改为原顺序
3.检验每一列的格式,做到每一列格式统一
4.做数据源备份,防止处理错误需要参考原数据
5.删除不必要的空行,空列
三.步骤
1.统一数值口径
例如我们统计销售任务指标,有时用合同金额有时用回款金额,口径经常不统一。统计起来就很麻烦。所以将不规范的数值改为规范这一步不可或缺
2.删掉多余的空格
原始数据如果夹杂着大量的空格,可能会在我们筛选数据或统计时带来一定麻烦。如何去掉多余的空格,仅在字符间保留一个空格
- 手动删除。如果只有三五个空格,这可能是最快的方式
- 函数法
在做数据清洗时,经常要去除数据两端的空格,那么TRIM, LIRIM, RTRIM这三个函数就可以帮到你了
TRIM函数:主要是用来去除单元格内容前后的空格,但不会去除字符之间的空格。表达式:=TRIM(文本)
LIRIM函数:用来去除单元格内容左边的空格
RTRIM函数:用来去除单元格内容右边的空格
3.字段去重
强烈建议把去重放在去除空格之后,因为多个空格导致工具认为“顾纳”和“顾 纳”不是一个人,去重失败
按照“数据”-“删除重复项”-选择重复列步骤执行即可(单选一列表示此列数据重复即删除,多选表示多个字段都重复才删除)
4.填补缺失值
由于人工录入或者数据爬虫等多方面的原因,会出现缺失值的情况,这就需要我们寻找漏网之“数据”,填充空缺值
如何统计有多少缺失值?
先看ID唯一列有多少行数据,参考Excel右下角的计数功能,对比就可以知道其他列缺失了多少数据
如何定位到所有缺失值?
Ctrl+G,选择定位条件,然后选择空值
缺失值处理方法:
- 人工补全。适合数据量少的情况
- 删除。适用于样本较大的情况,样本较小时,可能会影响最终的分析结果
- 根据数据的分布情况,可以采用均值,中位数,或者众数进行数据填充
数据均匀,均值法填充;数据分布倾斜,中位数填充
- 用模型计算值来代替缺失值
回归:基于完整的数据集,建立回归方程。将已知属性值代入方程来估计未知属性值,以估计值来进行空值的填充
极大似然估计:基于缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,通过观测数据的边际分布可以对缺失数据进行极大似然估计
随机插补法:从总体中随机抽取某几个样本代替缺失样本
多重填补法:包含m个插补值的向量代替每一个缺失值的过程,要求m大于等于20.m个完整数据集合能从插补向量中创建
5.异常值处理
异常值:指一组测定值中与平均值的偏差超过两倍标准差的测定值
对于异常值处理,需要具体情况具体分析,一般而言,异常值的处理方法常用以下3种:
- 不处理
- 用平均值替代:利用平均值来代替异常值,损失信息小,简单高效
- 视为缺失值:将异常值视为缺失值来处理,采用处理缺失值的方法来处理异常值
文章出处登录后可见!