背景
python 有自己的多进程包 multiprocessing 去实现并行计算,但在 pandas 处理数据中,使用 multiprocessing 并不好使,只听见风扇转啊转,就不见运行完毕。
找到一个 pandas 多进程的方法,pandarallel 库,做一下测试。
小数据集(先试过了 5w)可能多进程还没单进程快,因为进程开启关闭也要一点时间;于是我弄了 100w 数据来测试:
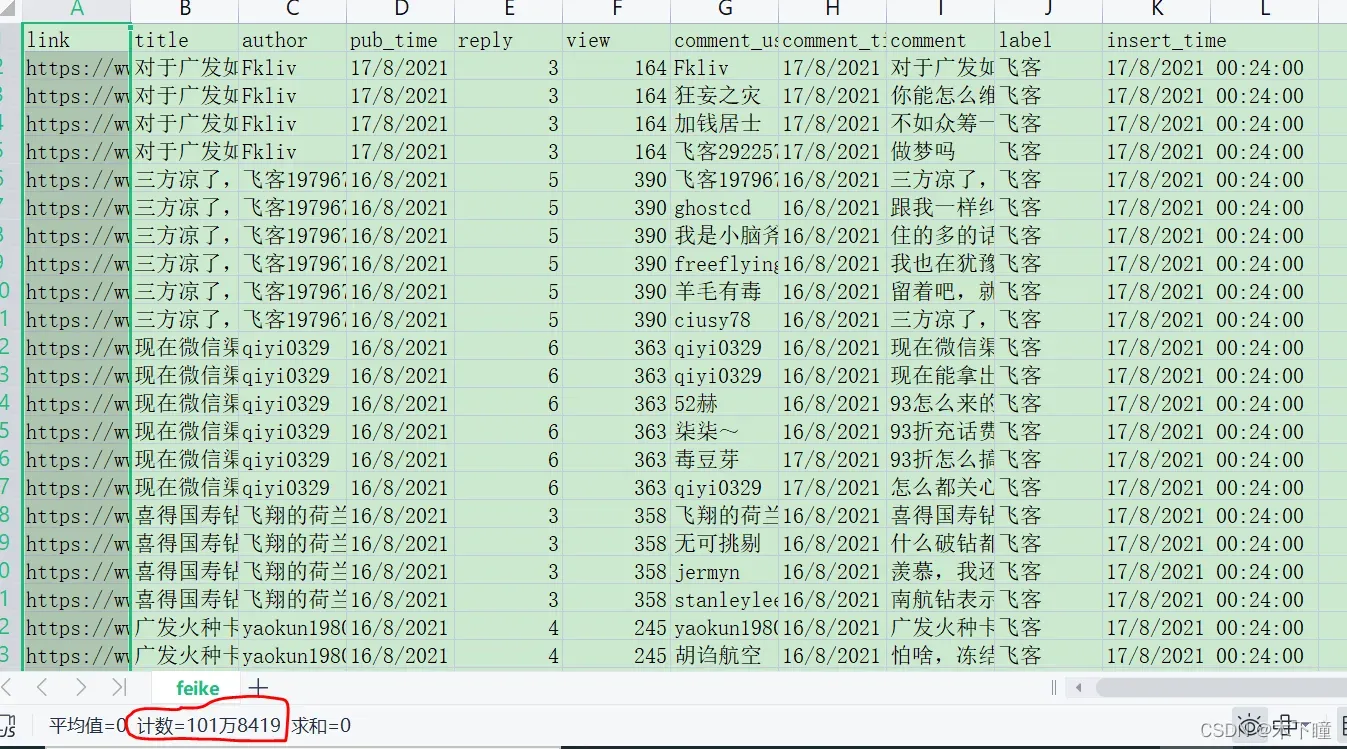
数据处理
使用以上数据做如下处理:
1.剔除 titile,comment 两列文本中的表情符号
2.title,comment 两列做一个分词处理,覆盖原来的列
总共有四个步骤。
单一进程
'''单进程'''
import jieba
import re
import time
import pandas as pd
def filter_emoji(desstr, restr=''):
if (desstr is None) or str(desstr) == 'nan':
return ''
# 过滤表情
try:
co = re.compile(u'[\U00010000-\U0010ffff]')
except:
co = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]')
return co.sub(restr, desstr)
if __name__ == '__main__':
start = time.time()
data = pd.read_csv('feike.csv',encoding='gbk')
data['comment'] = data['comment'].map(filter_emoji)
data['title'] = data['title'].map(filter_emoji)
data['comment'] = data['comment'].map(lambda s: jieba.lcut(s))
data['title'] = data['title'].map(lambda s: jieba.lcut(s))
end = time.time()
print(end - start)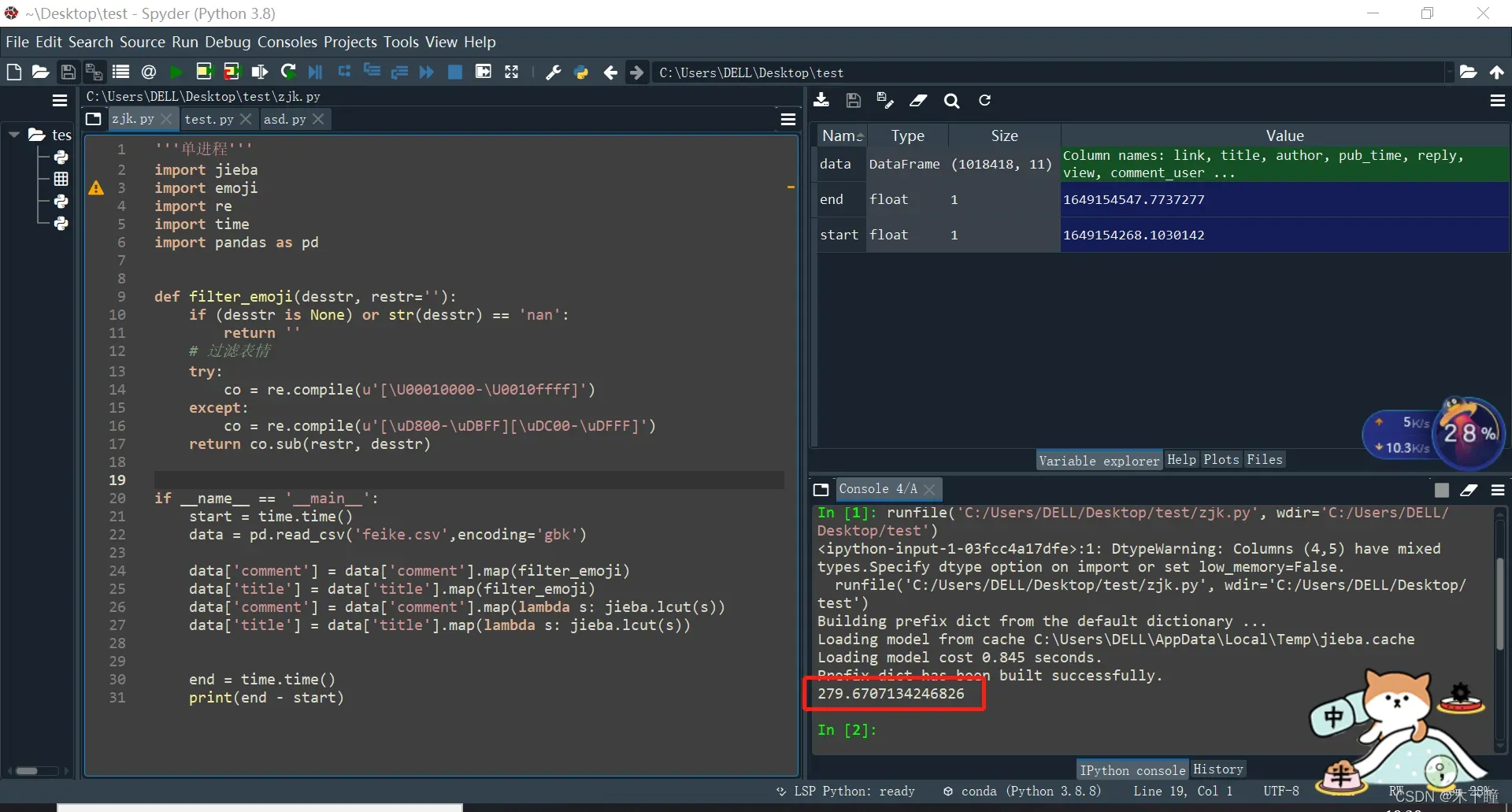
multiprocessing 多进程写法
这种写法网上一搜一大把,代码没有错,多进程任务可以执行,例如 run_task 函数中的任务是爬虫代码时,没有什么问题,但如果是数据清洗的代码,我测试就很久都跑不出来,所以以下写法不适用 pandas 多进程。
from multiprocessing import Pool
import os,time,random
import pandas as pd
import jieba
def filter_emoji(desstr, restr=''):
if (desstr is None) or str(desstr) == 'nan':
return ''
# 过滤表情
try:
co = re.compile(u'[\U00010000-\U0010ffff]')
except:
co = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]')
return co.sub(restr, desstr)
def run_task(row):
row['comment'] = row['comment'].map(filter_emoji)
row['title'] = row['title'].map(filter_emoji)
row['comment'] = row['comment'].map(lambda s: jieba.lcut(s))
row['title'] = row['title'].map(lambda s: jieba.lcut(s))
if __name__ == '__main__':
start = time.time()
data = data = pd.read_csv('feike.csv',encoding='gbk')
p = Pool()
for index,row in data.iterrows():
p.apply_async(run_task,args=(row,)) #添加进程任务,i 为传进去的进程任务的参数
p.close() #不再添加新进程
p.join() #等待所有子进程执行完毕,调用之前必须先调用 close(),针对 Pool 对象
end = time.time()
print(end - start)pandas 多进程 pandarallel
'''pandarallel 多进程'''
import jieba
import re
import time
import pandas as pd
from pandarallel import pandarallel
pandarallel.initialize(nb_workers=4)
def filter_emoji(desstr, restr=''):
if (desstr is None) or str(desstr) == 'nan':
return ''
# 过滤表情
try:
co = re.compile(u'[\U00010000-\U0010ffff]')
except:
co = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]')
return co.sub(restr, desstr)
if __name__ == '__main__':
start = time.time()
data = data = pd.read_csv('feike.csv',encoding='gbk')
data['comment'] = data['comment'].parallel_apply(filter_emoji)
data['title'] = data['title'].parallel_apply(filter_emoji)
data['comment'] = data['comment'].parallel_apply(lambda s: jieba.lcut(s))
data['title'] = data['title'].parallel_apply(lambda s: jieba.lcut(s))
end = time.time()
print(end - start)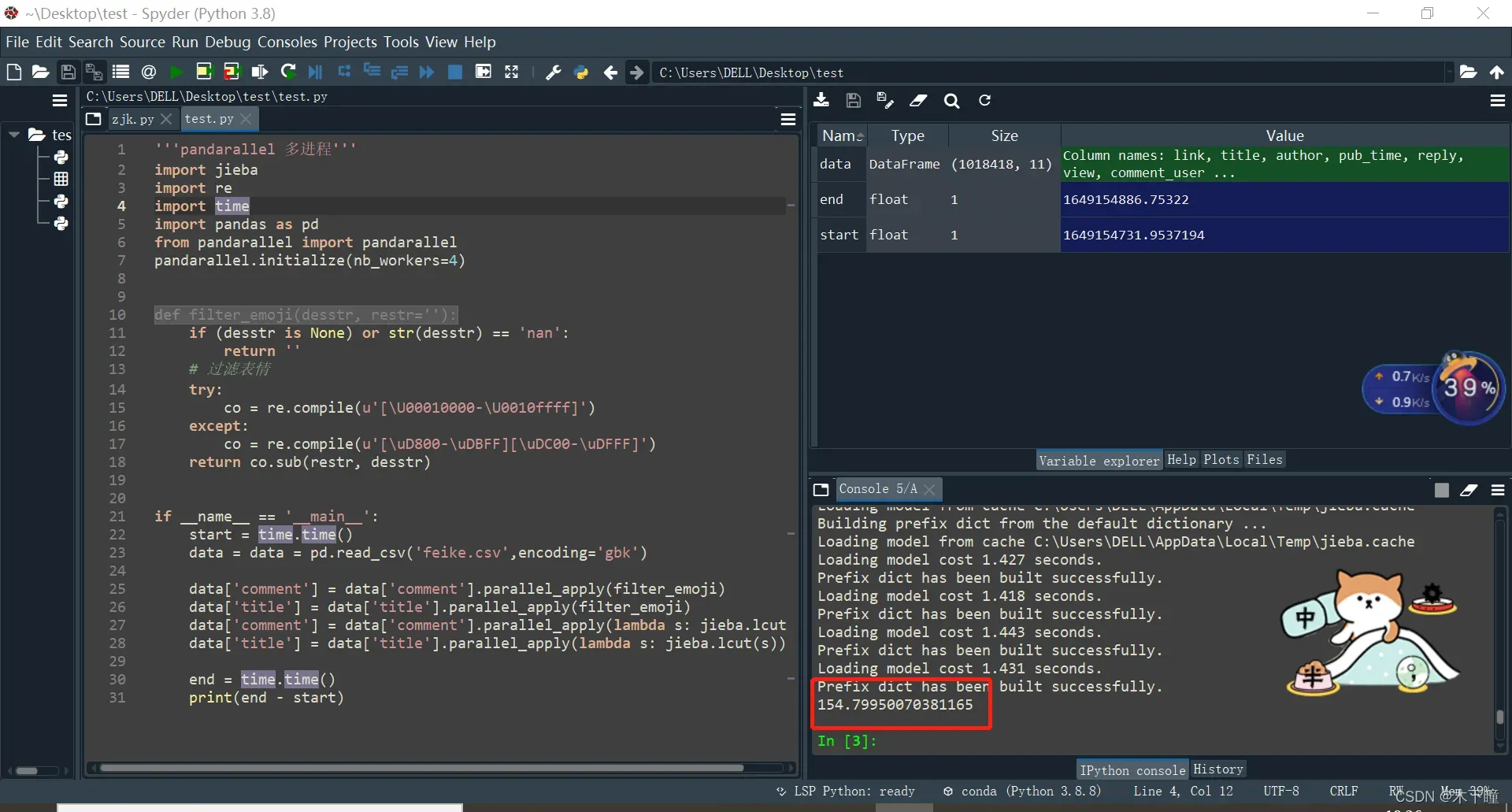
可以看到对比单进程效率提高了将近 1 倍 ;pandarallel 文档:
GitHub – nalepae/pandarallel at v1.5.2
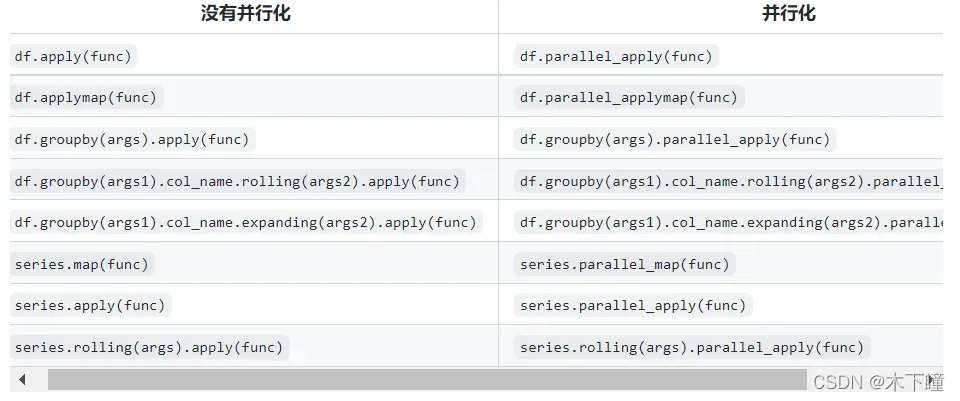
对应的多进程写法函数对照表,但值得注意的是 pandas 中的 apply,applymap,map 三个函数的区别,写对应的代码,别写错了;具体区别可参考:
Pandas 中map, applymap and apply的区别_小强的呼呼呼的博客-CSDN博客
文章出处登录后可见!
已经登录?立即刷新