DL_class
学堂在线《深度学习》实验课代码+报告(其中实验1和实验6有配套PPT),授课老师为胡晓林老师。课程链接:https://www.xuetangx.com/training/DP080910033751/619488?channel=i.area.manual_search。
持续更新中。
所有代码为作者所写,并非最后的“标准答案”,只有实验6被扣了1分,其余皆是满分。仓库链接:https://github.com/W-caner/DL_classs。 此外,欢迎关注我的CSDN:https://blog.csdn.net/Can__er?type=blog。
部分数据集由于过大无法上传,我会在博客中给出下载链接。如果对代码有疑问,有更好的思路等,也非常欢迎在评论区与我交流~
实验1:Softmax实现手写数字识别
实现代码
本次实现过程中为了代码的执行效率,没有使用 for 循环。下面就实现内容进行简要讲解。
forward
前向传播部分利用矩阵乘法,整体模型如下图所示,此处为一张图片的变化过程:
- Input
(1,784)经过线性变化(1,784)*(784,10)为(1,10) (1,10)的线性结果记为中间变量z,对z实施softmax,变成0~1之间的概率分布,记作中间变量y_,此变量将会用于梯度计算,所以设置为类成员- 最后经过交叉熵函数计算损失,得出
L损失值
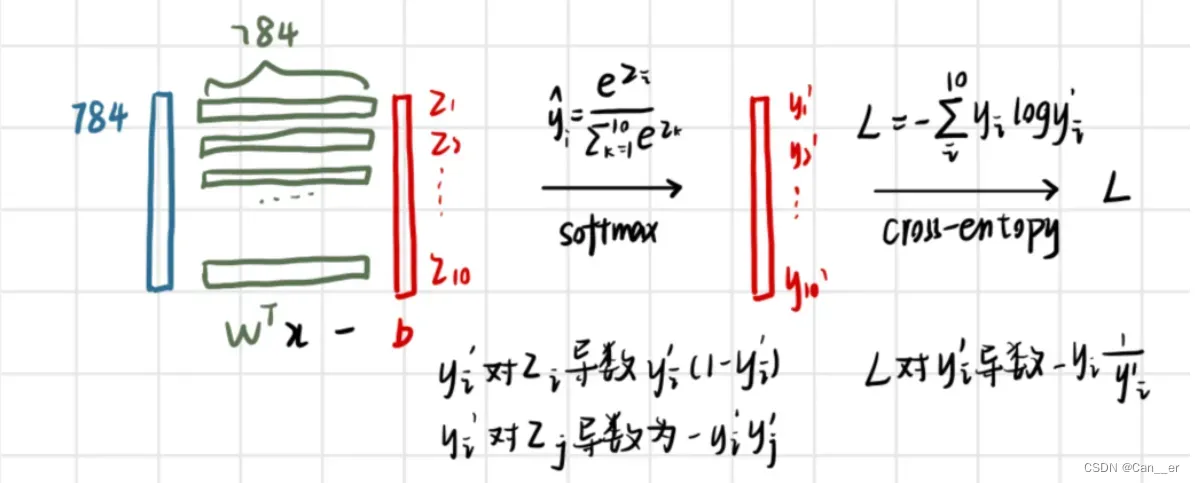
将上述过程扩展为一个批量大小的数据集即可,代码和维度变化如下:
# z: (batch_size, 10)
z = np.dot(Input, self.W) + self.b
# self.y_: (batch_size, 10)
self.y_ = self.softmax(z)
# L: (batch_size, 1)
L = -np.sum(self.y_*self.y, axis=1)
loss = np.average(L)
# pre: (batch_size, )
pre = np.argmax(self.y_, axis=1)
acc = accuracy_score(labels, pre)
注意,因为原数据集标签为0~9的数字,所以需要使用独热编码进行转化,此时经过softmax后的结果可以直接使用 * 与之相乘,对应的操作是 矩阵中对应位置的每个元素单独相乘,也就是交叉熵中的每一项,再进行求和即可。
计算loss时候进行平均,计算acc时候采用 argmax 函数获取最大值下标,记作中间变量 pre,直接使用库函数 accuracy_score 计算准确率。
gradient_computing
梯度的推导比较麻烦,但最后形式很简单,softmax和cross_entropy的梯度得到了很巧妙的融合。推导过程如下图所示:

可以 把上式记作反向传播中的 ”误差“,代码中使用 e 来表示。
再对于线性变换中的w和b分别进行求导(矩阵导数,这里不放具体推导过程了),可以推出:
因为w的计算公式中涉及了多个样本(一个批量大小),在矩阵计算时直接在对应位置对应累加了,所以需要除以batch_size,代码如下:
# e: (batch_size, 10)-(batch_size, 10)->(batch_size, 10)
e = self.y_-self.y
# grad_W: (784, batch_size)*(batch_size, 10) -> (784, 10)
self.grad_W = np.dot(self.Input.T, e)/self.batch_zise
# grad_b: (batch_size, 10) -> (1, 10)
self.grad_b = np.average(e, axis=0)
momentum
根据公式添加两个成员变量:self.W_velocity 和 self.b_velocity,用于加权累加各自的梯度,每次使用这两个变量而不是当次的梯度来进行更新参数即可。
if self.momentum:
self.W_velocity = self.momentum * self.W_velocity + self.learning_rate*layer.grad_W
self.b_velocity = self.momentum * self.b_velocity + self.learning_rate*layer.grad_b
layer.W += -self.W_velocity
layer.b += -self.b_velocity
return
报告问题
Q1
记录训练和测试的准确率。画出训练损失和准确率曲线;下图是使用原始参数进行训练时的结果:
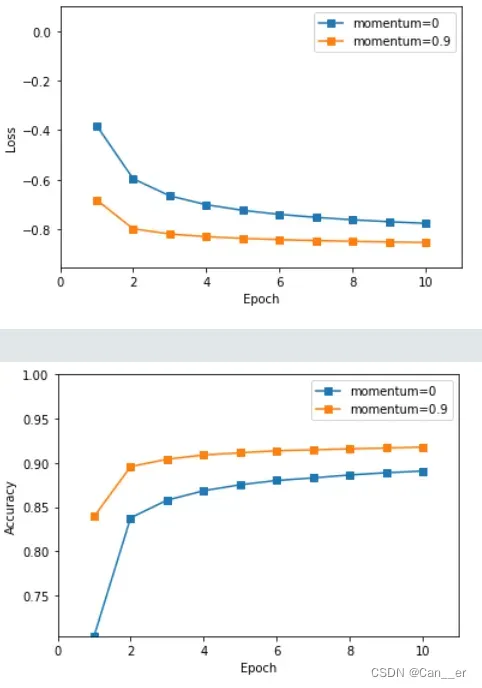
Q2
比较使用和不使用 momentum 结果的不同,可以从训练时间,收敛性和准确率等方面讨论差异;
-
训练时间:到达相同的准确度的情况下,因其收敛速度快,使用动量使用的训练时间更短。尤其是累加的梯度,在前期有着明显的快速收敛特征,第一周期能够迅速跨过 ”非极值点“ 的位置。
-
收敛性:无论是否使用动量,只要模型正确,在足够的周期下都可以收敛,但是使用动量收敛更快。
-
准确率:在每个周期纵向对比,使用动量准确率更高。后期训练了30个周期,来判断这种差异是由于不使用动量容易陷入局部最优,还是由于收敛较慢而带来的,如下图所示,后期基本趋于持平的周期内不适用动量依然距离使用动量具有一段差距,说明是由于使用动量可以更好的跳出局部最优。
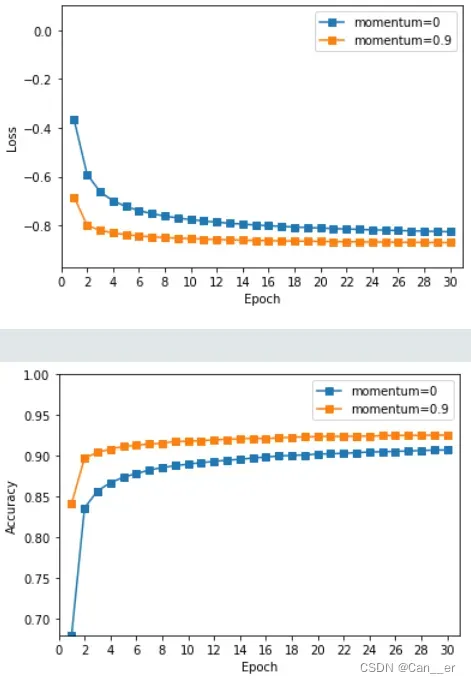
Q3
调整其他超参数,如学习率,Batchsize 等,观察这些超参数如何影响分类性能。写下观察结果并将这些新结果记录在报告中。
规定使用动量为0.9,下面对其它可调节参数根据顺序做出如下尝试:
- batch_size批量数。最先确定的参数,batch size的大小决定了两个方面,一是深度学习训练过程中的完成每个epoch所需的时间和每次迭代(iteration)之间梯度的平滑程度,二是其正确选择是为了在内存效率和内存容量之间寻找最佳平衡。即batchsize越小 ,速度越快,权值更新越频繁,泛化越好;而适当增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但蓄力时间长。因为收敛较快,这里训练5个周期:
- 在批大小为10时,训练速度较慢。最开始我尝试了小数据集上的训练批大小为1,也就是不使用批量更新,发现初期波动性较大,说明随机取样对梯度下降的方向把握并不明确。
- 在批大小为1000和5000时,准确率上升较慢,推测是每一周期梯度更新的次数太少所致。
- 而在批大小为100时,训练已经和10呈现相同的上升趋势,说明其已经能很好的预测梯度下降的方向,无须再舍弃内存负荷增加批大小,故选取batch size参数大小为100,即每一周期将进行500次正向传播与反向更新 。
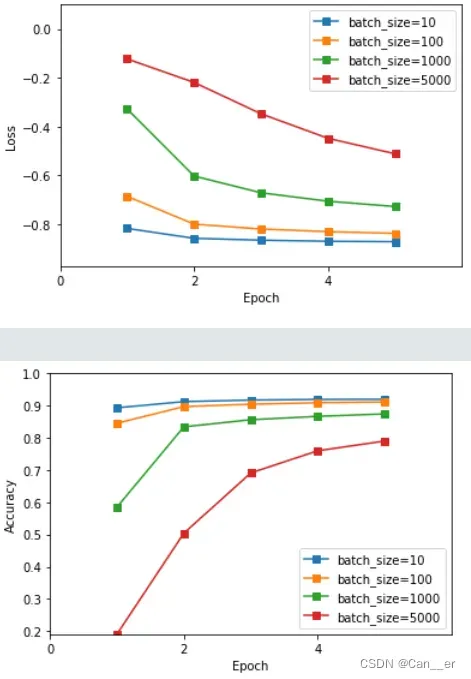
-
learning_rate学习率。在批量数确定后,一定有一个与之匹配的学习率使得梯度下降的效果最好,通过调节参数实验,观察前3周期的起始准确率,以确保梯度以最快的速度下降。而为了在训练后期逼近最优解时不震荡,将使用学习率衰减的思想,使之每一周期缩小指定比例即可防止其震荡(自己添加的额外处理)。
-
在学习率为0.01时,具较快的收敛速度,但训练初期的准确率不高,说明存在欠拟合现象,梯度下降幅度偏小。因为使用学习率衰减,所以可以大胆选择更大的学习率。
-
在学习率为0.1,0.5时,呈现几乎相同趋势(从88%左右开始逐步上升 ),训练集准确率表现不错。最终也选取了0.1作为起始学习率。
-
在学习率为1和3时,第一周期的准确率呈现了不和谐现象,推测是学习率过大,导致的容易震荡问题。
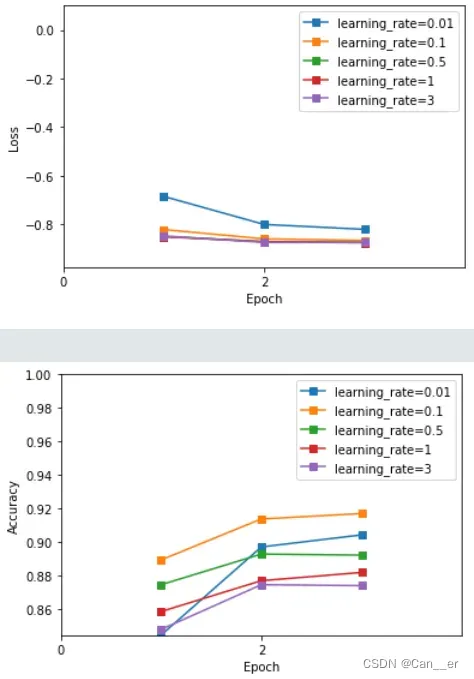
-
-
max_epoch周期。在所有超参数确定后,将通过调节周期大小来控制网络的训练程度,避免欠拟合或过拟合。从上面的训练10个和30个周期可以看出,训练周期过少欠拟合,过多过拟合。在本实验中,使用早停法(自己添加的额外处理,在solver.py中),将以上上周期和上一周期的正确率作为评定的标准 ,规定连续两周期正确率率差值均不超过0.02%时,训练已经足够充足,此时停止训练即可。代码和训练结果如下:
# early-stop flag2 = acc - last last = acc best = max(best,acc) if abs(flag1) < 0.02 and abs(flag2) < 0.02: print("Stop training at {0} epoch! The best accurancy:{1:.2f}% !".format(epoch,best)) break flag1 = flag2
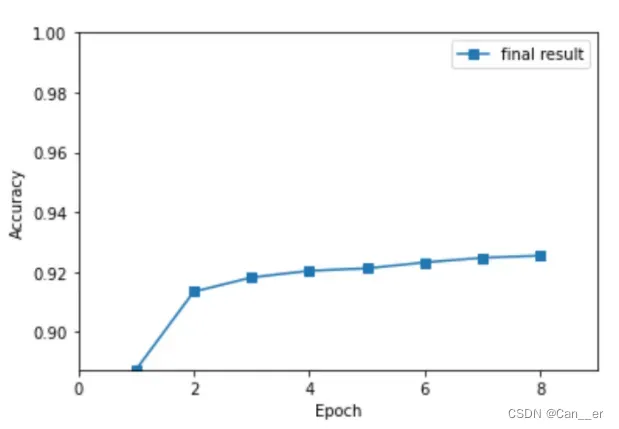
可以发现,在该参数下,训练起步准确率高且收敛迅速,第7个周期已经趋于完全拟合,自动停止了训练,训练过程中训练集的最高准确率(批次)为98%。此时测试模型,最终得到测试集上准确率为92.34%。
补充
框架问题
可能是比较古老的框架,存在一些问题,下面指出:
- 数据集加载部分,官网已经更新文件名由 ”t10k-images-idx3-ubyte“ 变为 “t10k-images.idx3-ubyte”,对应“dataloader.py
中line13, line 14`。 solver.py中line90, line101存在未定义变量logits,应修改为loss。.ipynb文件调用.py文件时,对被调用文件修改无法实时同步,需要重新加载,给调试带来不便。建议更换主文件runner.ipynb为.py格式。
一些收获
-
图片类问题通过减去均值的方法能够去除自身无关特征带来的影响。
-
随机参数的初始化非常有趣,我之前一直直接使用(0,1)正态分布,然而这份代码中使用
(2 / (self.num_input + self.num_output))**0.5作为标准差,我没有想明白这背后的原理,还请助教解答。 -
处理756个像素点运算复杂度较高,将采取网格划分和主成分提取两种方式进行数据的预处理,我尝试了这两种方法,PCA主成分提取有着很不错的效果并且对准确率的损失较小,为保持代码的干净优雅,提交的版本中没有给出。
-
数据集的处理,在模型和超参数规定了的情况下,我在阅读有关该数据集中的论文的过程中,发现了几个比较好的方法, ”图片的矫正处理“ ,”池化和卷积“ ,”去噪“ 都是可以拿来练习的不错思路。
提取两种方式进行数据的预处理,我尝试了这两种方法,PCA主成分提取有着很不错的效果并且对准确率的损失较小,为保持代码的干净优雅,提交的版本中没有给出。
- 数据集的处理,在模型和超参数规定了的情况下,我在阅读有关该数据集中的论文的过程中,发现了几个比较好的方法, ”图片的矫正处理“ ,”池化和卷积“ ,”去噪“ 都是可以拿来练习的不错思路。
文章出处登录后可见!