入门机器学习(西瓜书+南瓜书)聚类总结(python代码实现)
一、聚类
1.1 通俗理解
聚类,顾名思义就是把数据特征相似的数据聚为一类。属于无监督学习的范畴。没有标签值的监督,因此不同的聚类算法,聚类的结果也不同。
俗话说物以类聚。聚类就是按照某一个特定的标准(比如距离),把一个数据集分割成不同的类或簇(cluster),使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇内的数据对象的差异性也尽可能的大。聚类可以作为一个单独过程,用于寻找数据内在分布结构,也可以作为其他学习任务前驱过程。聚类和分类的区别在于聚类是无监督学习任务,不知道真实的样本标记,只是把相似度搞得样本聚合在一起;分类是有监督学习任务,利用已知的样本标记训练出一个模型,利用改模性预测未知样本的类别。
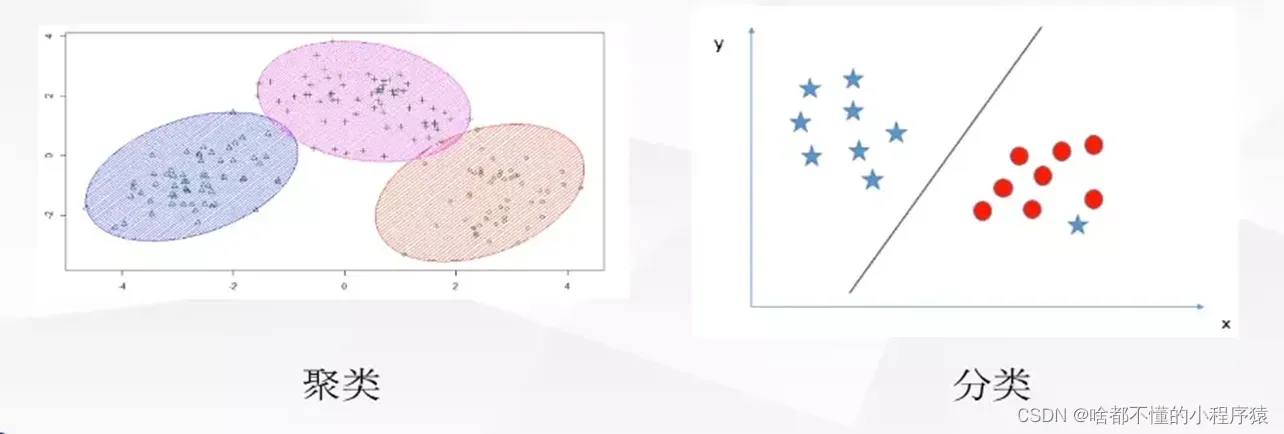
1.2 理论分析
聚类:按照某一个特定的标准(比如距离),把一个数据集分割成不同的类或簇,也就是说将相似高的数据聚集在一起。
评价标准:类内相似度大,类间的差异性大(相似度小)。
距离公式:刻画相似度,距离越大,相似度越小,反之,相似度越大。
常用的聚类算法有,
(密度聚类),层次聚类.
1.3 K-Means聚类算法
首先来看第一个算法:K均值聚类。给定m个样本集.给定划分的k个簇为
最小化平方误差为:
其中是簇
的均值向量。
K-Means算法得到的聚类结果会最小化平方误差,即每个样本到其类别中心的距离值和最小。类别中心用该类别中所有样本的均值来表示,这在一定程度上刻画了类内样本围绕均值向量的紧密程度,值越小类内样本的相似度越高。
K均值算法采用贪心策略,通过不断迭代找到最优的类别中心,进而完成聚类任务。
下面具体来看一下算法的流程:
(1)输入为m个样本集D,聚类的个数K,首先从D中随机选择k个样本作为初始的均值向量,即类别中心。
(2)利用第一个for循环完成m个样本的划分,分别计算每一个样本xj到各个类别中心ui的距离,选择距离最近的类别作为样本xj的类别标记,当完成岩本的划分后,重新计算每个类别的均值向量,即类别中心.
(3)比较前后两次均值向量是否发生改变,如果发生改变,根据新的类别中心再次对样本进行划分,直到类别中心不发生改变为止,最终得到聚类结果。
K均值聚类算法最终的聚类结果会受到聚类个数K以及初始的类别中心的影响。
1.4 密度聚类
密度聚类也称为基于密度的聚类,此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。
DBSCAN是一种著名的密度聚类算法,它基于一组“邻域”参数来刻画样本分布的紧密程度,给定数据集,定义以下几个概念。

如图所示,上图中的虚线即为 -邻域,设是核心对象,则
由
密度直达,
由
密度可达,
与
密度相连。因此
与核心对象
为一类。即采用该原则可以使得聚类算法表达出传递性。
密度聚类对簇的定义:由密度可达关系导出的最大密度相连样本集合,将这些点作为同一个簇。DBSCAN算法任意选取一个核心对象作为“种子”,然后从“种子”出发寻找所有密度可达的其他核心对象,并且包含每个核心对象的邻域的非核心对象,将这些核心对象和非核心对象作为一个簇。当寻找完一个簇后,选择还没有簇标记的其他核心对象,得到一个新的簇,反复执行这个过程,直到所有的核心对象都属于某一个簇为止。
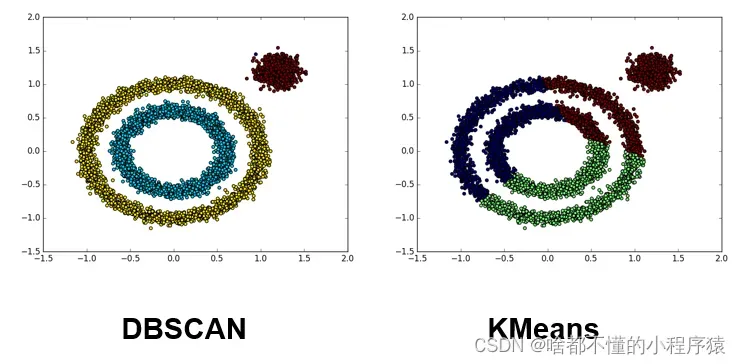
K-Means算法和DBSCAN算法结果对比:
1.5 层次聚类
层次聚类试图在不同层次对数据进行划分,从而形成树形的聚类结构。数据集的划分可采用自底向上的聚合策略,也可采用自顶向下的分拆策略。
AGNES是一种采用自底向上的聚合策略的层次聚类方法,它先将每一个样本看成初始聚类簇,然后在算法的每一步找出距离最近的聚类簇进行合并,该过程不断反复,直到达到预设的聚类簇。聚类簇之间的距离可以用以下公式进行计算:
单链接:
全链接:
均链接:
下面来看一下该算法的流程:
(1)输入为m个样本集合D,距离度量函数d,可以是最小距离,最大距离或平均距离,这里以最小距离为例,聚类的类别数k。
(2)初始情况下,将每个样本单独看成一个类别,共有m个类别,同时构造一个mm的距离矩阵M,元素值Mij等于类别ci与cj之间的距离,很显然矩阵M为对称矩阵,接着找出距离最近的两个类别Ci与Cj,进行合,这里将Cj中的样本和合并到Ci中,记作Ci,类别数减1.这时需要修改距离矩阵M,一是删除矩阵M的第j行和第j列,二是重新计算新类别Ci*与其他类别Ck之间的距离,以最近距离为例,它的值等于ck与合并前的类别Ci和Cj距离中的最小值。
(3)重复执行,直到达到预定的聚类的类别数。

二、代码实现
from sklearn.cluster import KMeans
KMeans(n_clusters=2)
n_clusters: 类别数
from sklearn.cluster import DBSCAN
DBSCAN(eps=0.1,min_samples = 5)
eps: 邻域半径
min_samples:阈值,邻域内最少的样本数
from sklearn.cluster import AgglomerativeClustering
AgglomerativeClustering(n_clusters, affinity, linkage)
n_clusters:类别数
affinity:距离公式
linkage:‘ward’(single),‘complete’,‘average’
三、代码文件
小程序员将代码文件和相关素材整理到了百度网盘里,因为文件大小基本不大,大家也不用担心限速问题。后期小程序员有能力的话,将在gitee或者github上上传相关素材。
链接:https://pan.baidu.com/s/1Ce14ZQYEYWJxhpNEP1ERhg?pwd=7mvf
提取码:7mvf
文章出处登录后可见!