1. 机器学习
1.1 基本术语
- 模型世界:
1. 机器学习就是从现实世界到信息世界,中间还有个模型世界。
- 例如:西瓜模型
收集了一批关于西瓜的数据,例如:
(色泽=青绿;根蒂=蜷缩;敲声=浊响),
(色泽=乌黑;根蒂:稍蜷;敲声=沉闷),
(色泽=浅自;根蒂 硬挺;敲声=清脆),
… …,
- 记录:
1. 每对括号内是一条记录。
2. "=" 意思是 "取值为"。
- 数据集:
1. 这组记录的集合称为一个"数据集" (data set)。
- 示例或示例:
1. 每条记录是关于一个事件或对象(这里是一个西瓜)的描述,
2. 称为一个"示例" (instance) 或"样本" (**sample**)。
- 属性、属性值、维度:
1. 反映事件或对象在某方面的表现或性质的事项,
2. 例如"色泽","根蒂","敲声",称为"属性" (**attribute**) 或"特征" (feature)。
3. 属性上的取值,例如"青绿" "乌黑",称为"**属性值**" (**attribute value**)。
4. 一个样本的属性个数称为"维数"。
- 特征向量:
1. 例如我们把"色泽" "根蒂" "敲声"作为三个坐标轴,
2. 则它们张成一个用于描述西瓜的三维空间,
3. 每个西瓜都可在这个空间中找到自己的坐标位置,
4. 由于空间中的每个点对应一个坐标向量,
5. 因此我们也把一个示例或样本称为一个"特征向量" (feature vector)。
- 数学公式:D = { X1, X2, … … , Xm }
1. D 为数据集
2. Xi 为示例或样本
3. Xi = (Xi1, Xi2, ..., Xid)
4. Xi1为示例的Xi的第1个属性值
5. 一个样本d个属性
6. 一个数据集m个样本或示例。
- 训练,训练集,假设:
1. 从数据中学得模型的过程称为"学习" (learning) 或"训练" (training),
2. 这个过程通过执行某个学习算法来完成。
3. 其中每个样本称为一个"训练样本"(training samp1e)。
4. 训练样本组成的集合称为"训练集" (training set)。
5. "训练集 = 假设"
6. 训练集可以对照"数据集"来理解。
7. 有时将模型称为"学习器" (learner) 。
- 示例,标记:
1. 如果希望学得一个能帮助我们判断没剖开的是不是"好瓜"的模型。
2. 要建立这样的关于"预测" (prediction)模型。
3. 例如((色泽=青绿; 根蒂=蜷缩; 敲声=浊响),好瓜)。
4. 例如"好瓜",称为"标记" (label)。
5. 拥有了标记信息的示例,则称为"样例" (example)。
6. 若将标记看作对象本身的一部分,则"样例"有
时也称为"样本"。
- 培训类型:
1. 分类训练
若我们欲预测的是离散值,
例如"好瓜" "坏瓜",
此类学习任务称为"分类" (classification)。
2. 回归训练
若欲预测的是连续值,
例如西瓜成熟度 0.95 0.37,
此类学习任务称为"回归" (regression)。
3. 二分类训练
对只涉及两个类别的"二分类" (binary cl sification) 任务,
通常称其中一个类为 "正类" (positive classd),
另一个类为"反类" (negative class)。
4. 多分类训练
涉及多个类别时,
则称为"多分类" (multi-class classificatio)任务。
- 集群,集群:
什么是聚类:
1. 即将训练集中的西瓜分成若干组,每组称为一个"簇" (cluster)。
2. 这些自动形成的簇可能对应一些潜在的概念划分,例如"浅色瓜" "深色瓜"。
- 监督学习(supervised learning) 和无监督学习(unsupervised learning):
1. "标志":根据训练数据是否拥有标记信息
2. 分类和回归是监督学习的代表
3. 而聚类则是无监督学习的代表
- 泛化:机器学习的目的
1. 机器学习的"目标"是使学得的模型能很好地适用于"新样本"。
2. 而不是仅仅在训练样本上工作得很好。
3. 学得的模型适用于新样本的能力,称为"泛化" (generalization) 能力。
1.2 假设空间
- 假设空间定义:
1. 我们可以把学习过程,
2. 看作一个在所有假设(hypothesis) 组成的空间中
3. 进行搜索的过程
4. 假设的表示一旦确定,假设空间及其规模大小就确定了。
- 版本空间:
1. 需注意的是,现实问题中我们常面临很大的假设空间。
2. 但学习过程是基于有限样本训练集进行的,
3. 因此,可能有多个"假设"与"训练集"一致,
4. 即存在着一个与"训练集"一致的"假设集合",我们称之为"版本空间" (version space)。
5. "版本空间是特殊的假设空间"。
1.3 归纳偏好
- 归纳学习:
- 归纳、演绎、一般归纳、狭义归纳、概念学习
1. "归纳"(induction) 与"演绎"(deduction)是科学推理的两大基本手段。
2. "归纳:"从特殊到一般的"泛化"(generalization) 过程。
3. "演绎:"是从一般到特殊的"特化"(specialization)叫过程。
4. 显然,"从样例中学习"是"归纳学习" (inductive learning)。
5. "归纳学习有狭义与广义之分:"
6. "广义"的归纳学习大体相当于从样例中学习,
7. "狭义"的归纳学习则要求从训练数据中学得概念
8. 狭义归纳学习亦称为"概念学习"或"概念形成"。
- 为什么要设置归纳偏好:
1. 通过学习得到的模型对应了假设空间中的一个假设。
2. 相同的训练集,不同应的模型在面临新样本的时候,却会产生"不同"的输出。
3. 例如:侧重色泽是好瓜,但侧重根蒂却是不好的瓜,... ...
4. 那么,应该采用哪一个模型(或假设)昵?
5. "所以:"
6. 机器学习算法在学习过程中对某种类型假设的偏好,
7. 称为"归纳偏好" (inductive bias) , 或简称为"偏好"。
2. 绪论课后习题
- 1.1
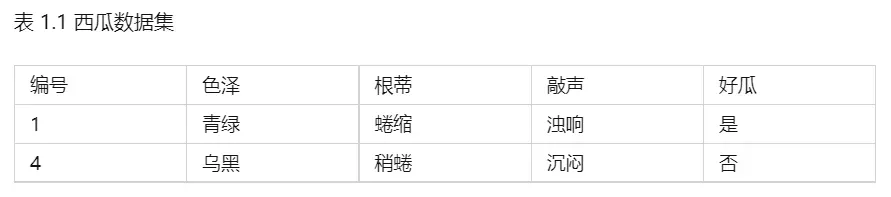
1.1 表1.1中若只包含编号为1和4的两个样例,试给出相应的版本空间.
思路1:先看版本空间定义
"版本空间":存在着一个与"训练集"一致的"假设集合",我们称之为"版本空间" (version space)。
思路2:
1. 所给两条数据是样例(有标记:好,坏)。
2. 删除与正例1不一致的假设,或与反例4一致的假设。
3. 版本空间就是得到好瓜。
解:
版本空间:
- 保留与正例一样的:
1.(色泽=青绿)∧(根蒂=蜷缩)∧(敲声=浊响)
- 变一个:
2.(色泽=青绿)∧(根蒂=蜷缩)∧(敲声= ∗ )
3.(色泽=青绿)∧(根蒂= ∗ )∧(敲声=浊响)
4.(色泽= ∗ )∧(根蒂=蜷缩)∧(敲声=浊响)
- 变两个:
4.(色泽=青绿)∧(根蒂= ∗ )∧(敲声= ∗ )
5.(色泽= ∗ )∧(根蒂= ∗ )∧(敲声=浊响)
6.(色泽= ∗ )∧(根蒂=蜷缩)∧(敲声= ∗ )
- 1.3
1.3 若数据包含噪声,则假设空间中有可能不存在与所有训练样本都一致的假设。
在此情形下,"设计一种归纳偏好"用于假设选择。
思路:选择好的假设。
解:
1. 在训练过程中选择满足最多样本的假设/训练集。
2. 对每个假设,求得其准确率。
3. 准确率=(符合假设的条件且为好瓜的样例数量)/(符合假设的条件的样例数量)。
4. 选择准确率最高的假设。
- 1.5
1.5 试述机器学习能在互联网搜索的哪曲环节起什么作用.
解:
1.在向搜索引擎提交信息的阶段,能够从提交文本中进行信息提取,进行语义分析。
2.在搜索引擎进行信息匹配的阶段,能够提高问题与各个信息的匹配程度。
3.在向用户展示搜索结果的阶段,能够根据用户对结果感兴趣的程度进行排序。
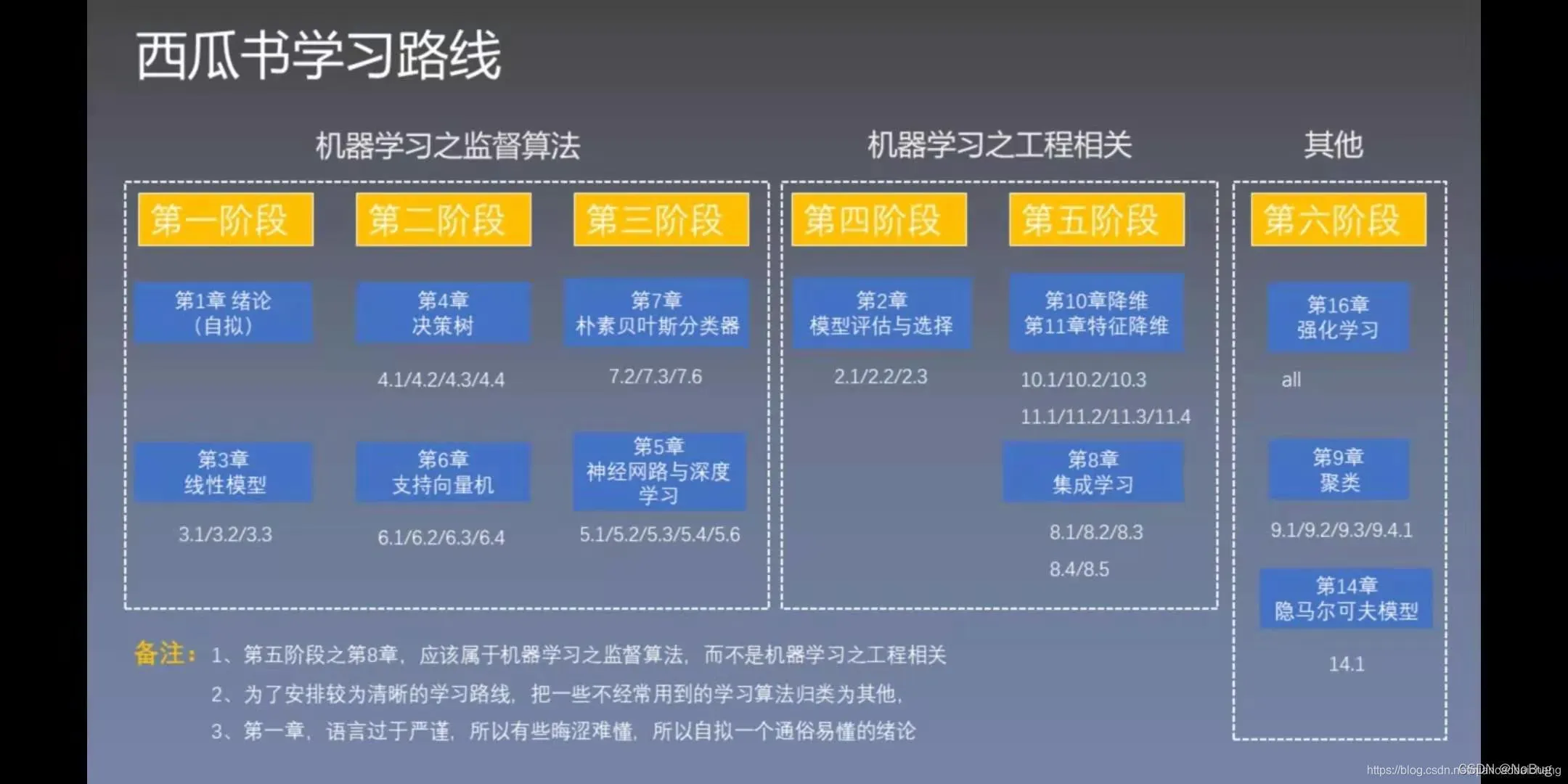
3. 西瓜书学习计划参考
版权声明:本文为博主NoBug ㅤ原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_51184516/article/details/123329740