毕业设计项目二——“无忧未来”招聘结构化数据预处理
操作系统:Win 10
操作环境:Jupyter Notebook (Anaconda)
存储路径:电脑D盘,csv格式
处理文件名:招聘.csv
语言:python 3.8
需求:数据来源于上一篇博客爬取的“数据分析”职位招聘数据。本博客将对这些数据进行预处理,为下一次数据分析做准备。
1、导入数据处理需要的模块
import pandas as pd
import numpy as np
import re
import string
import warnings
warnings.filterwarnings('ignore')
2、将薪资万/月,千/月,元/天等单位统一换算为千/月
# 读取文件
df = pd.read_csv('招聘.csv')
# 薪资单位转换
# 添加“salary”一列,以k为单位
df['salary'] = ''
for i in range(len(df['薪资'])) :
df['薪资'][i] = str(df['薪资'][i])
if re.findall(r'(.*)\-(.*)\万\/\月',df['薪资'][i]) :
s = re.findall(r'(.*)\-(.*)\万\/\月',df['薪资'][i])[0]
df['salary'][i] = (float(s[0])+float(s[1]))/2*10
elif re.findall(r'(.*)\-(.*)\万\/\年',df['薪资'][i]) :
s = re.findall(r'(.*)\-(.*)\万\/\年',df['薪资'][i])[0]
df['salary'][i] = (float(s[0])+float(s[1]))/2*10/12
elif re.findall(r'(.*)\-(.*)\千\/\月',df['薪资'][i]) :
s = re.findall(r'(.*)\-(.*)\千\/\月',df['薪资'][i])[0]
df['salary'][i] = (float(s[0])+float(s[1]))/2
print(df['salary'])
elif re.findall(r'(.*)\千\以\下\/\月',df['薪资'][i]) :
s = re.findall(r'(.*)\千\以\下\/\月',df['薪资'][i])[0]
df['salary'][i] = float(s)
elif re.findall(r'(.*)\元\/\天',df['薪资'][i]) :
s = re.findall(r'(.*)\元\/\天',df['薪资'][i])[0]
df['salary'][i] = float(s)*30/1000
else :
df['salary'][i] = 0
df.to_csv('招聘.csv')
运行结果显示:
3、将所处行业进行统一处理,便于后续进行可视化分析
# 添加行业一列,进行行业预处理
df['industry'] = ''
for i in range(len(df['所处行业'])) :
df.loc[i,'所处行业'] = str(df.loc[i,'所处行业'])
if re.match(r'^\互\联\网.*|^\计\算\机.*|^\通\信.*|^\网\络\游\戏.*|^\电\子\技\术.*|^\仪\器\仪\表.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '互联网/计算机/通信/电子'
elif re.match(r'^\农.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '农/林/牧/渔'
elif re.match(r'^\保\险.*|^\会\计.*|^\金\融.*|^\银\行.*|^\信\托.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '会计/金融/银行/保险'
elif re.match(r'^\贸\易.*|^\办\公\用\品\及\设\备.*|^\服\装.*|^\批\发.*|^\机\械.*|^\家\具.*|^\快\速\消\费\品.*|^\汽\车\及\零\配\件.*|^\奢\侈\品.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '贸易/消费/制造/营运'
elif re.match(r'^\制\药$|.*\医\疗\设\备$',df['所处行业'][i]) :
df.loc[i,'industry'] = '制药/医疗'
elif re.match(r'^\广\告.*|^\公\关.*|^\印\刷.*|^\文\字\媒\体$|\影\视.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '广告/媒体'
elif re.match(r'^\房地产$|.*\家\居$|.*\物\业\管\理$|.*\建\筑$',df['所处行业'][i]) :
df.loc[i,'industry'] = '房地产/建筑'
elif re.match(r'^\法\律.*\专\业\服\务\(\咨\询\、\人\力\资\源\、\财\会\)$|\检\测.*|\中\介.*|\学\术.*|\租\赁.*|\外\包\服\务$|.*|\教\育$',df['所处行业'][i]) :
df.loc[i,'industry'] = '专业服务/教育/培训'
elif re.match(r'^\餐\饮\业.*|\酒\店.*|.*\娱\乐$|\美容.*|.*\生\活\服\务$',df['所处行业'][i]) :
df.loc[i,'industry'] = '服务业'
elif re.match(r'^\交\通.*|^\航\天.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '物流/运输'
elif re.match(r'^石\油.*|^\采\掘\业.*|^\电\气.*|^\新\能\源.*|^\原\材\料.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '能源/原材料'
elif re.match(r'^\非\营\利\组\织.*|^\政\府.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '政府/非益利组织'
elif re.match(r'^\环\保.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '环保'
elif re.match(r'^\多\元\化\业\务\集\团\公\司.*',df['所处行业'][i]) :
if re.match(r'.*\互\联\网$|.*\计\算\机\服\务(系\统\、\数\据\服\务\、\维\修\)$|\通\信.*|.*\网\络\游\戏$|\电\子\技\术.*|\仪\器\仪\表.*|.*\计\算\机\软\件$', df['所处行业'][i]) :
df.loc[i,'industry'] = '互联网/计算机/通信/电子'
elif re.match(r'\保\险.*|\会\计.*|.*\金\融$|\银\行.*|\信\托.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '会计/金融/银行/保险'
elif re.match(r'.*\贸\易$|\办\用\品\及\设\备.*|.*\服\装$|\批\发.*|.*\机\械$|.*\家\具$|.*\快\速\消\费\品\(\食\品\、\饮\料\、\化\妆\品\)$|\汽\车\及\零\配\件.*|\奢\侈\品.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '贸易/消费/制造/营运'
elif re.match(r'^\制\药$|.*\医\疗\设\备$',df['所处行业'][i]) :
df.loc[i,'industry'] = '制药/医疗'
elif re.match(r'^\广\告.*|^\公\关.*|^\印\刷.*|^\文\字\媒\体$|\影\视.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '广告/媒体'
elif re.match(r'^\房地产$|.*\家\居$|.*\物\业\管\理$|.*\建\筑$',df['所处行业'][i]) :
df.loc[i,'industry'] = '房地产/建筑'
elif re.match(r'^\法\律.*\专\业\服\务\(\咨\询\、\人\力\资\源\、\财\会\)$|\检\测.*|\中\介.*|\学\术.*|\租\赁.*|\外\包\服\务$|.*|\教\育$',df['所处行业'][i]) :
df.loc[i,'industry'] = '专业服务/教育/培训'
elif re.match(r'^\餐\饮\业.*|\酒\店.*|.*\娱\乐$|\美容.*|.*\生\活\服\务$',df['所处行业'][i]) :
df.loc[i,'industry'] = '服务业'
else :
df.loc[i,'industry'] = '其他'
elif re.match(r'^\外\包\服\务.+',df['所处行业'][i]) :
if re.match(r'.*\互\联\网$|.*\计\算\机\服\务(系\统\、\数\据\服\务\、\维\修\)$|\通\信.*|.*\网\络\游\戏$|\电\子\技\术.*|\仪\器\仪\表.*|.*\计\算\机\软\件$', df['所处行业'][i]) :
df.loc[i,'industry'] = '互联网/计算机/通信/电子'
elif re.match(r'\保\险.*|\会\计.*|.*\金\融$|\银\行.*|\信\托.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '会计/金融/银行/保险'
elif re.match(r'.*\贸\易$|\办\用\品\及\设\备.*|.*\服\装$|\批\发.*|.*\机\械$|.*\家\具$|.*\快\速\消\费\品\(\食\品\、\饮\料\、\化\妆\品\)$|\汽\车\及\零\配\件.*|\奢\侈\品.*',df['所处行业'][i]) :
df.loc[i,'industry'] = '贸易/消费/制造/营运'
elif re.match(r'^\制\药$|.*\医\疗\设\备$',df['所处行业'][i]) :
df.loc[i,'industry'] = '制药/医疗'
elif re.match(r'^\法\律.*\专\业\服\务\(\咨\询\、\人\力\资\源\、\财\会\)$|\检\测.*|\中\介.*|\学\术.*|\租\赁.*|\外\包\服\务$|.*|\教\育$',df['所处行业'][i]) :
df.loc[i,'industry'] = '专业服务/教育/培训'
else :
df.loc[i,'industry'] = '其他'
else :
df.loc[i,'industry'] = '其他'
df.to_csv('招聘.csv')
运行结果显示:
4、salary的缺失值处理,用均值填充
# 使用列salary的均值对NA进行填充
df['salary'].fillna(df['salary'].mean())
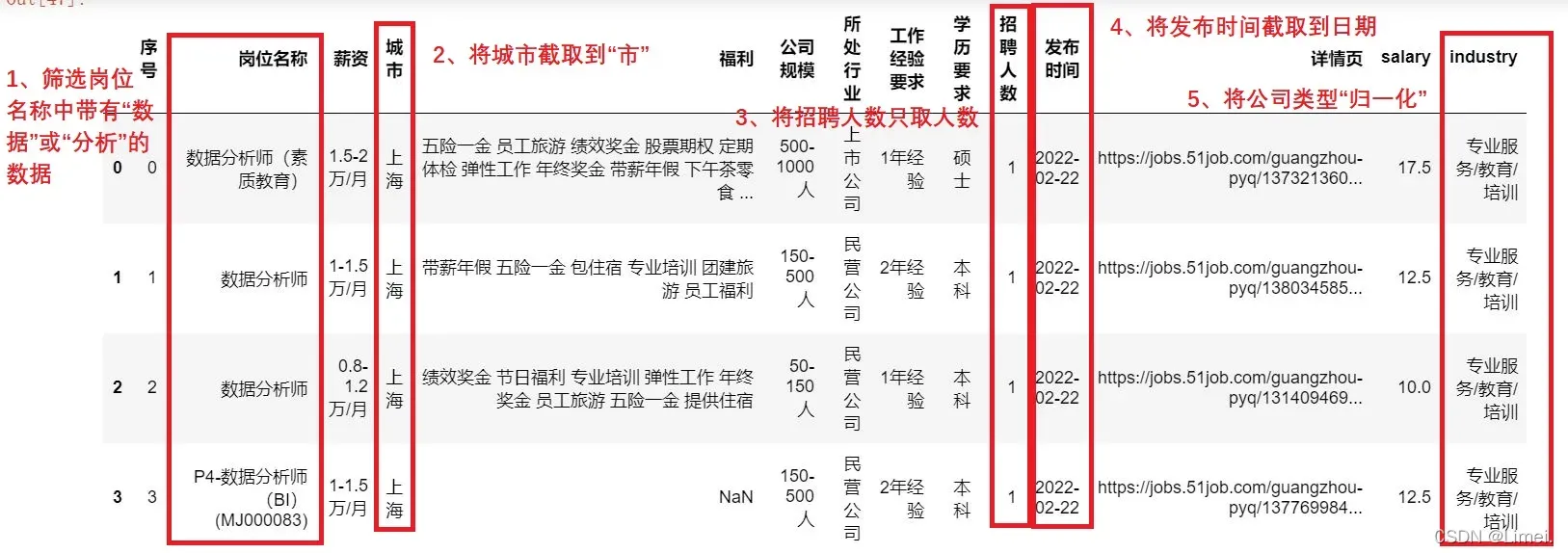
5、提取包含“数据”或者“分析”的岗位
df = df[df.岗位名称.str.contains(r'.*?数据.*?|.*?分析.*?')]
6、去除完全相同的行
df.drop_duplicates(inplace=True)
7、去敏(去除公司名那一列)
df = df.drop(["公司名称"],axis=1)
8、使用公司规模的众数替换缺失公司规模
df.fillna(value = {'公司规模': df['公司规模'].mode()[0]},inplace = True) # 原地修改数据
9、将城市清洗到 市
df['城市'] = df['城市'].str.split('-', expand=True)[0]
10、将发布时间清洗到 日期
df['发布时间'] = df['发布时间'].str.split(' ', expand=True)[0]
11、将“招X人”改为“X”人
df['招聘人数'] = df['招聘人数'].str.split('', expand=True)[2]
12、查看经过预处理后的数据
df.head()
13、保存预处理后的数据
df.to_csv('招聘.csv')
以上就是招聘信息结构化数据的预处理,就是这样。接下来介绍招聘信息非结构化数据的处理,敬请期待^_^
版权声明:本文为博主Limei.原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_46951551/article/details/123337361