目前,关于自动驾驶数据集,你想知道的都应该在这里了。这是“整数智能”自动驾驶数据集八系列分享中的第一篇:
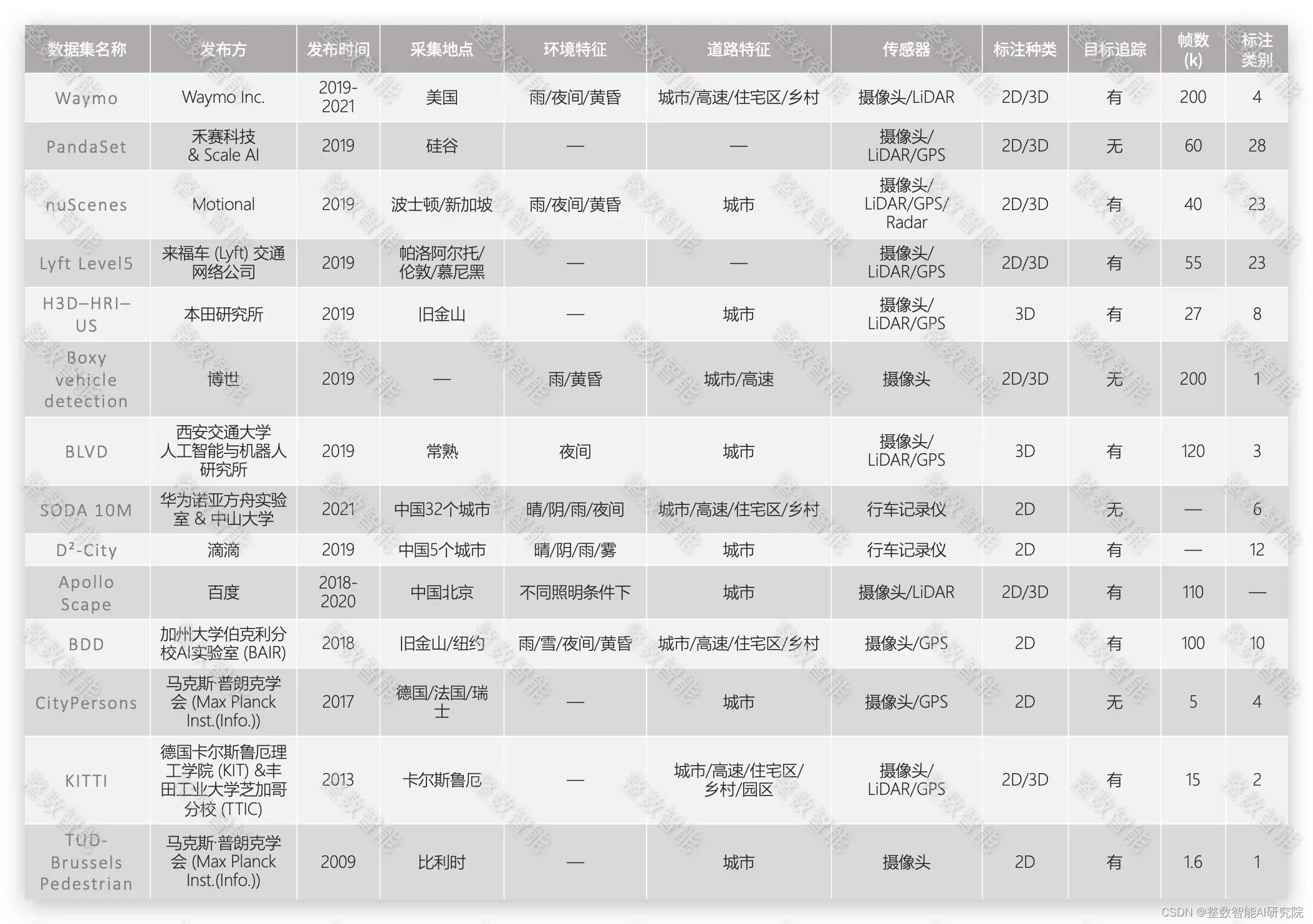
内容
《八辑概论》
01 「Waymo数据集」
02「PandaSet」
03「nuScenes」
04「Lyft Level 5」
05「H3D – HRI-US」
06「Boxy vehicle detection数据集」
07「BLVD」
08「SODA10M 数据集」
09「D²-City数据集」
10「Apollo Scape数据集」
11「BDD100K」
12「KITTI」
13「CityPersons 」
14「TUD-Brussels Pedestrian &TUD-MotionPairs 」
“联系我们”
《八辑概论》
自动驾驶数据集共享是整数智能推出的全新共享系列。在本系列中,我们将介绍迄今为止各大科研机构和企业发布的所有公共自动驾驶数据集。数据集主要分为八个系列:
- 系列一:物体检测数据集
- 系列 2:语义分割数据集
- 系列 3:车道线检测数据集
- 系列 4:光流数据集
- 系列五:Stereo Dataset
- 系列 6:定位和地图数据集
- 系列 7:驾驶行为数据集
- 系列 8:仿真数据集
本文为
过去,研究人员创建和发布的数据集相对较小,这些数据集的数据来源也比较有限,通常仅限于摄像头数据。随着采集设备的升级, 自动驾驶数据集也在不断升级。以谷歌自动驾驶汽车为例,谷歌自动驾驶汽车在外部车顶上装置了64束激光测距仪,能够使自动驾驶汽车把激光测的数据和高分辨率的地图相结合,使得做出不同类型的数据场景,以便在自动驾驶中躲避障碍物及遵循交通规则。除此之外,Pandset、nuScenes、BLVD等均采用了激光雷达传感器。
除了国外的一些知名数据集,百度、华为、滴滴和西安交大研究所也先后推出了国内的自动驾驶数据集,如Apollo Scape数据集、SODA10M 数据集、D²-City数据集和BLVD数据集,为国内自动驾驶技术的进展提供了重要的研究材料。
下面共包括14个数据集:
01 「Waymo数据集」
- 发布方:Waymo
- 下载地址:https://waymo.com/open/
- 发布时间:2019年发布感知数据集,2021年发布运动数据集
- 大小:1.82TB
- 简介:Waymo数据集是到目前为止最大、最多样化的数据集,相比于以往的数据集,Waymo在传感器质量和数据集大小等方面都有较大提升,场景数量是nuScenes数据集的三倍
- Perception Dataset
- 1950个自动驾驶视频片段,每段视频包括20s的连续驾驶画面
- 汽车、行人、自行车、交通标志的四类标签
- 1260万个3D框,1180万个2D框
- 传感器数据:1 个中程激光雷达、4 个短程激光雷达、5个摄像头
- 收藏范围覆盖美国加利福尼亚州凤凰城、柯克兰、山景城、旧金山等城市中心和郊区。它还涉及各种驾驶条件下的数据,包括白天、夜晚、黎明、黄昏、雨天、晴天

- Motion Dataset
- 包括574 小时的数据,103,354个带地图数据片段
- 汽车、行人、自行车三类标签,每个对象都带有2D框标注
- 用于行为预测研究的挖掘行为和场景,包括转弯、并道、变道和交叉路口
- 地点包括:旧金山、凤凰城、山景城、洛杉矶、底特律和西雅图
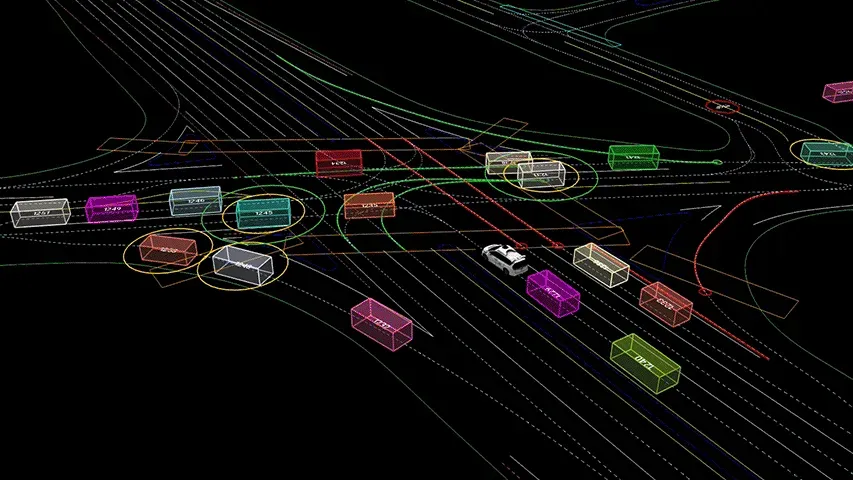
02「PandaSet」
- 发布方:禾赛科技&Scale AI
- 下载地址:https://scale.com/resources/download/pandaset
- 发布时间:2019
- 大小:16.0 GB
- 简介:Pandaset面向科研及商业应用公开。首次同时使用了机械旋转式和图像级前向两类激光雷达进行数据采集,输出点云分割结果
- 特征
- 48000多个摄像头图像
- 16000个激光雷达扫描点云图像(超过100个8秒场景)
- 每个场景的28个注释
- 大多数场景的37个语义分割标签
- 传感器:1个机械LiDAR,1个固态LiDAR,5个广角摄像头,1个长焦摄像头,板载GPS / IMU
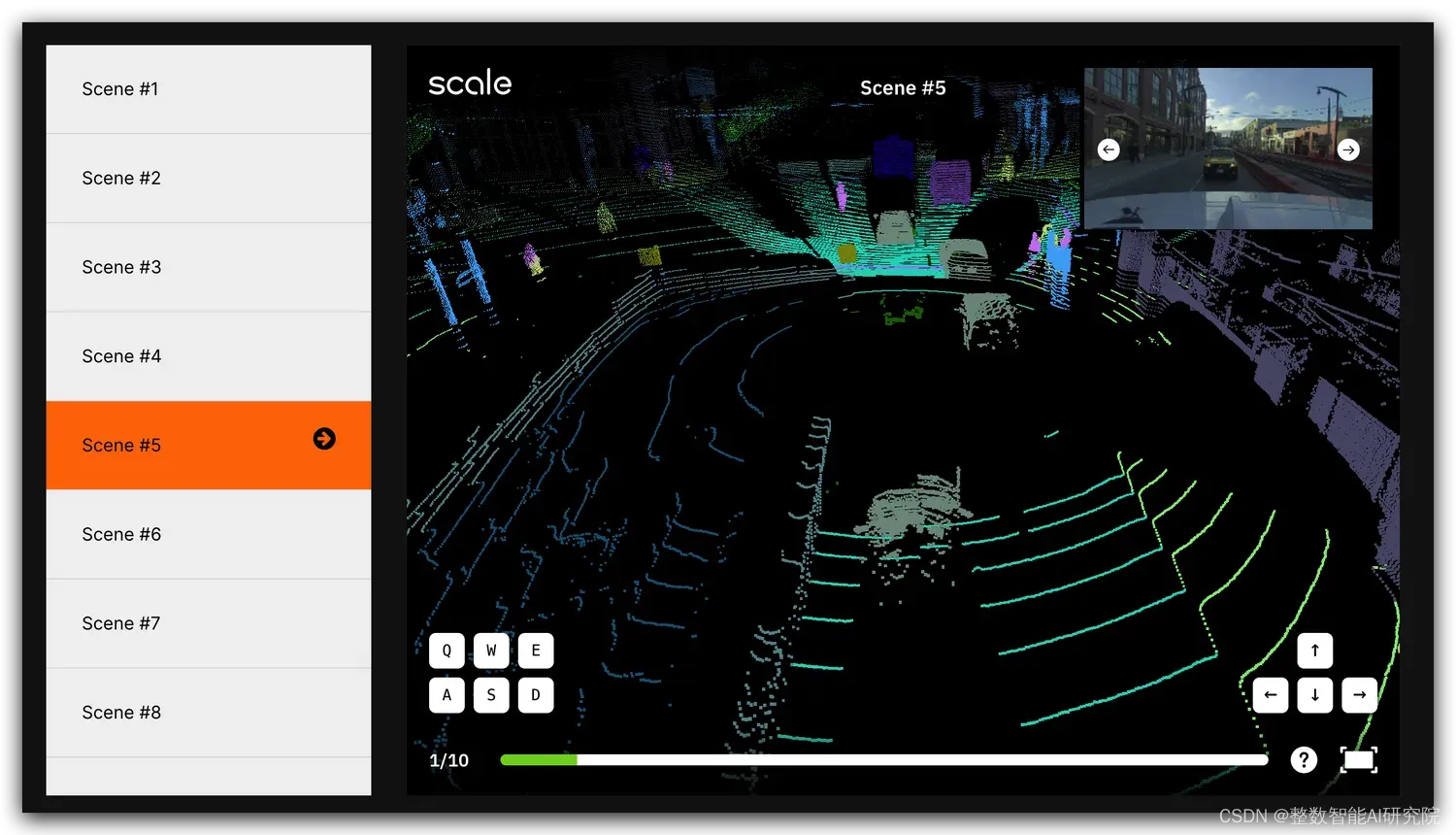
03「nuScenes」
- 发布方:无人驾驶技术公司Motional
- 下载地址:https://scale.com/open-datasets/nuscenes/tutorial
- 论文地址:https://arxiv.org/abs/1903.11027
- 发布时间:2019
- 大小:547.98GB
- 简介:nuScenes 数据集是自动驾驶领域使用最广泛的公开数据集之一,也是目前最权威的自动驾驶纯视觉 3D 目标检测评测集。nuScenes数据集灵感来源于kitti,是首个包含全传感器套件的数据集。其中包含波士顿和新加坡的 1000 个复杂的驾驶场景。该数据集禁止商用
- 特征
- 全传感器套件:1个激光雷达、5个雷达、6个摄像头、GPS 、 IMU
- 1000个场景,每个场景20秒(850个用于模型训练,150个用于模型测试)
- 40万个关键帧,140万张相机图片,39万个激光雷达扫描点云图像,140 万个雷达扫描点云图像
- 为23个对象类标注的1400万个3D标注框

04「Lyft Level 5」
- 发布方:来福车(Lyft)交通网络公司
- 下载地址:https://level-5.global/register/
- 论文地址:https://arxiv.org/pdf/2006.14480v2.pdf
- 发布时间:2019年发布Lyft-perception数据集,2020年发布Lyft-prediction数据集
- Lyft-perception
- 简介:Lyft 的自动驾驶汽车配备了一个内部传感器套件,可从其他汽车、行人、交通信号灯等处收集原始传感器数据
- 特征
- 超过 55,000 帧,由人工进行3D标注
- 130万3D标注
- 3万激光雷达点云数据
- 350个60-90分钟的场景

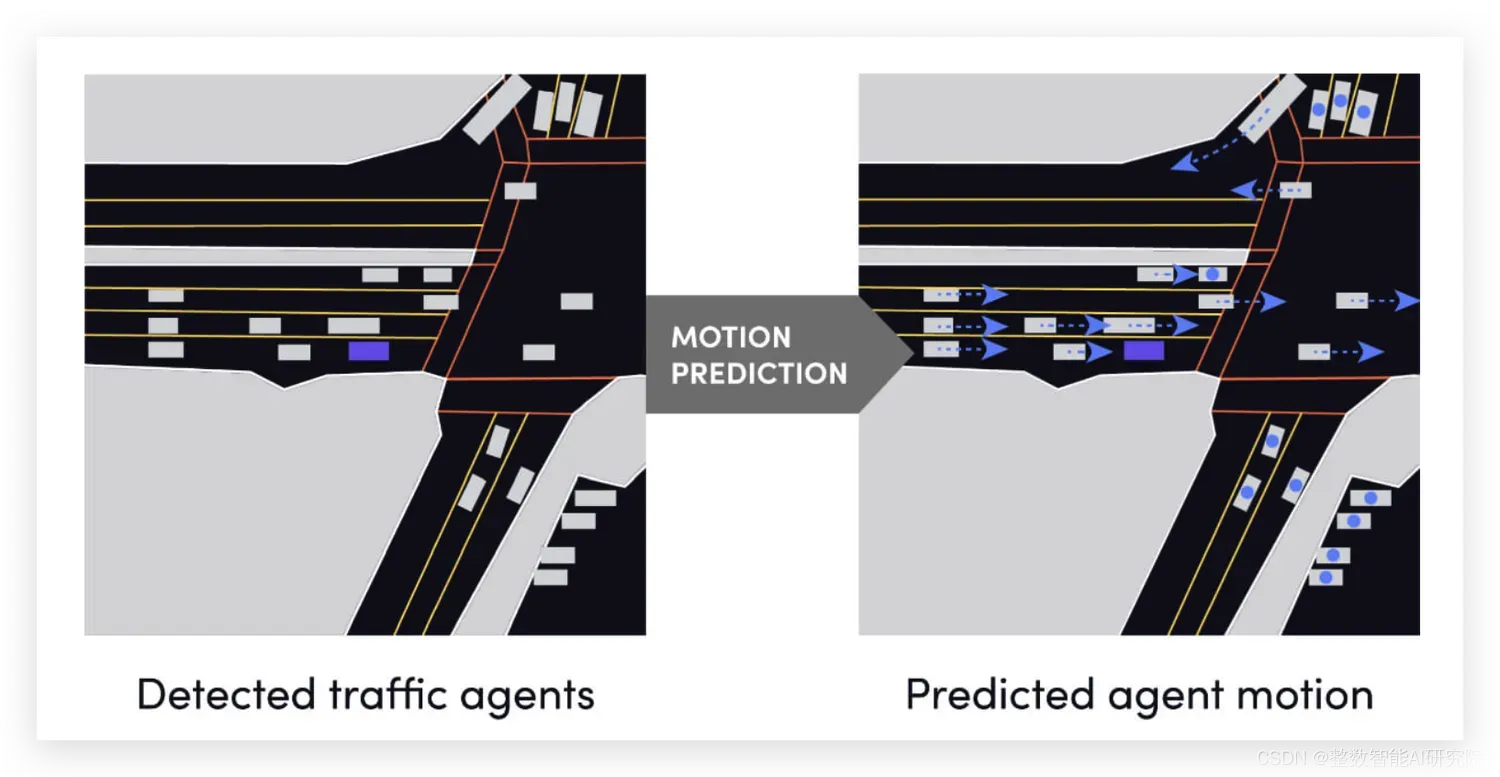
- Lyft-prediction
- 简介:该数据集包括无人驾驶车队遇到的汽车、骑自行车者、行人和其他交通参与者的运动记录。这些记录来自原始激光雷达、相机和雷达数据,非常适合训练运动预测模型
- 特征
- 1000 个小时的驾驶记录
- 17 万个场景:每个场景持续约 25 秒,包括交通信号灯、航拍地图、人行道等
- 2575 公里:来自公共道路的 2575 公里数据
- 15242 张标注图片:包括高清语义分割图以及该区域的高清鸟瞰图
05「H3D – HRI-US」
- 出版商:本田研究所
- 下载地址:https://usa.honda-ri.com//H3D
- 论文地址:https://arxiv.org/abs/1903.01568
- 发布时间:2019
- 简介:使用3D LiDAR扫描仪收集、大型全环绕3D多目标检测和跟踪数据集,该数据集仅供大学研究人员使用
- 特征
- 360 度 LiDAR 数据集
- 160个拥挤且复杂的交通场景
- 27,721帧,1,071,302个3D标注框
- 自动驾驶场景中8类常见对象的人工标注
- 传感器:3个高清摄像头,1个激光雷达,GPS / IMU
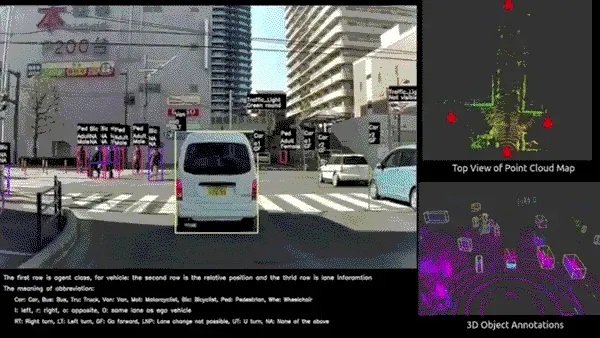
06「Boxy vehicle detection数据集」
- 出版商:博世
- 下载地址:https://boxy-dataset.com/boxy/
- 论文地址:https://openaccess.thecvf.com/content_ICCVW_2019/papers/CVRSUAD/Behrendt_Boxy_Vehicle_Detection_in_Large_Images_ICCVW_2019_paper.pdf
- 发布时间:2019
- 大小:1.1TB
- 简介:大型车辆检测数据集,该数据集的亮点在于其500万像素的高分辨率,但不提供3D点云数据以及城市道路交通数据
- 特征
- 220万张、共1.1TB的高分辨率图像
- 500万像素分辨率
- 1,990,806个车辆标注,包括2D框标注和2.5D标注
- 包括晴天、雨天、黎明、白天、傍晚等场景
- 涵盖交通拥堵和畅通的高速公路场景
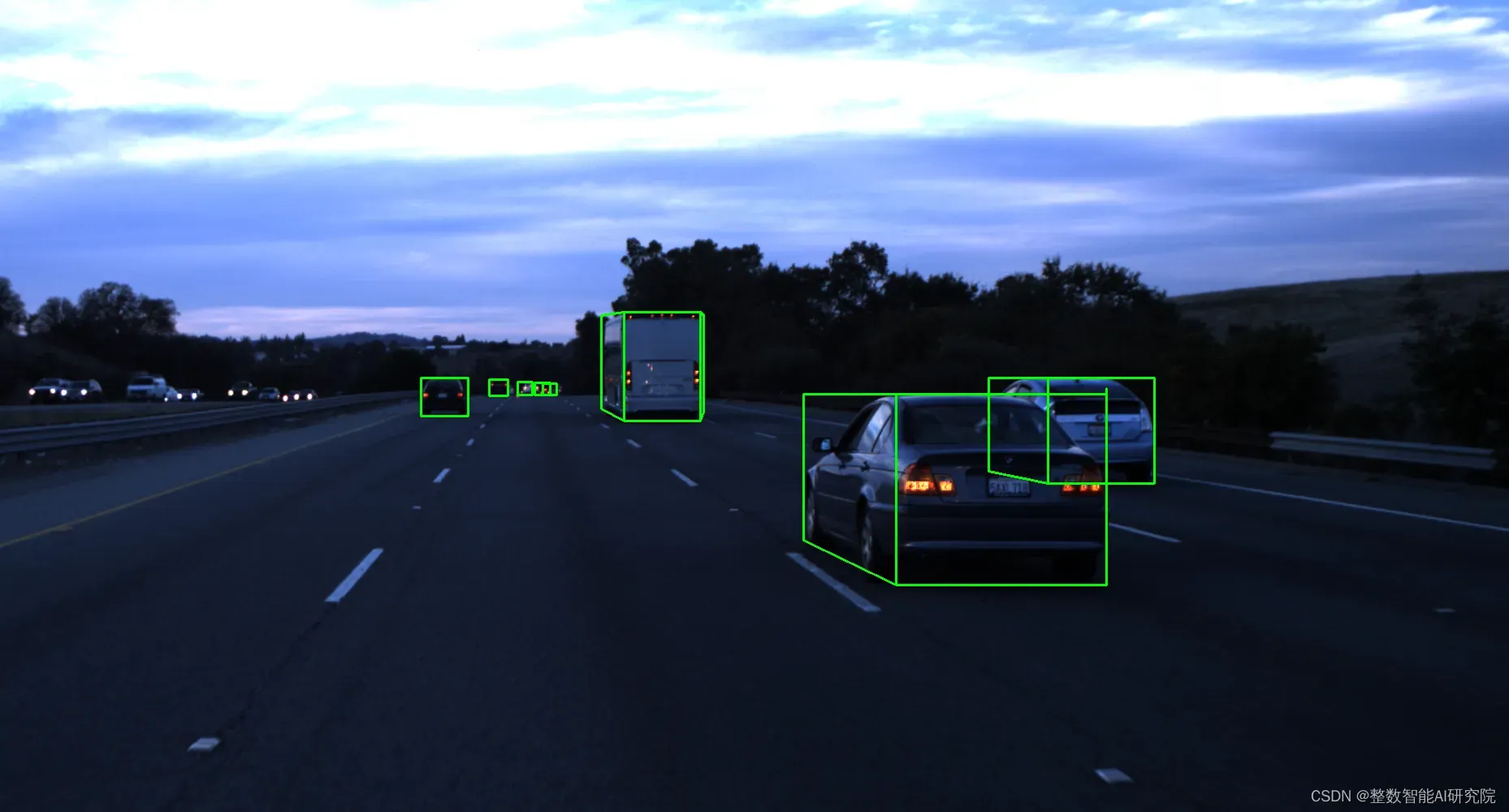
07「BLVD」
- 发布者:西安交通大学人工智能与机器人研究所
- 下载地址:https://github.com/VCCIV/BLVD/
- 论文地址:https://arxiv.org/pdf/1903.06405.pdf
- 发布时间:2019
- 简介:全球首个五维驾驶场景理解数据集。BLVD旨在为动态4D跟踪(速度、距离、水平角度和垂直角度)、5D交互事件识别(4D+交互行为)和意图预测等任务提供一个统一的验证平台。由西安交通大学夸父号无人车采集
- 特征
- 标注654个包含12万帧的序列,全序列5D语义注释
- 249129条3D目标框,4902个有效可跟踪的独立个体
- 总长度约214900个跟踪点
- 6004个用于5D交互事件识别的有效片段,4900个可以进行5D意图预测的目标
- 丰富的场景:城市和高速公路,白天和黑夜
- 多物体:行人、车辆、骑自行车的人(包括骑自行车的人和摩托车的人)
- 传感器:一个Velodyne HDL-64E三维激光雷达、GPS / IMU、两个高分辨率多视点相机

08「SODA10M 数据集」
- 发布者:华为诺亚方舟实验室&中山大学
- 下载地址:https://soda-2d.github.io/download.html
- 论文地址:https://arxiv.org/pdf/2106.11118.pdf
- 发布时间:2021
- 大小:5.6GB(带标记的数据),2TB(未标记的数据)
- 简介:半/自监督的2D基准数据集,其主要包含从32个城市采集的一千万张多样性丰富的无标签道路场景图片以及两万张带标签图片
- 特征
- 1000万张无标签图片以及2万张有标签图片,由手机或行车记录仪(1080P+)每10秒获取一帧图像
- 6种主要的人车场景类别:行人、自行车、汽车、卡车、电车、三轮车
- 覆盖中国32个城市
- 场景的多样性覆盖:晴天/阴天/雨天;城市街道/高速公路/乡村道路/住宅区;白天/夜间/黎明/黄昏
- 地平线保持在图像的中心,车内的遮挡不超过整个图像的15%

09「D²-City数据集」
- 发布者:滴滴
- 下载地址:https://www.scidb.cn/en/detail?dataSetId=804399692560465920
- 发布时间:2019年
- 大小:131.21 GB
- 简介:D²-City是一个大规模行车视频数据集。与现有的数据集相比,D²-City胜在其数据集的多样性,数据集采集自运行在中国五个城市的滴滴运营车辆,并且涵盖不同的天气、道路和交通状况
- 特征
- 10,000 多个视频,所有视频均以高清(720P)或超高清(1080P)分辨率录制,所提供的原始数据均存储为帧率25fps、时长30秒的短视频
- 其中大约有1000个视频对12类对象都进行2D框标注以及跟踪标注,包括汽车、货车、公共汽车、卡车、行人、摩托车、自行车、开放式和封闭式三轮车、叉车以及障碍物
- 所提供的原始数据均存储为帧率25fps、时长30秒的短视频
- 场景丰富:涵盖不同天气、道路、交通状况,尤其是极其复杂多样的交通场景,如光线不足、雨雾天气、道路拥堵、图像清晰度低等。
10「Apollo Scape数据集」
- Publisher: Baidu
- 下载地址:http://apolloscape.auto/scene.html
- 发布时间:2018-2020年
- 简介:百度阿波罗数据集包括轨迹预测、3D 激光雷达目标检测和跟踪、场景解析、车道语义分割、3D 汽车实例分割、立体和修复数据集等
- 特征
- 场景分割数据:ApolloScape发布的整个数据集包含数十万帧逐像素语义分割标注的3384 x 2710高分辨率图像数据
- 车道语义分割:110,000多帧的高质量的像素级语义分割数据
- 3D物体检测和追踪数据集:在中国北京的各种照明条件和交通密度下收集

11「BDD100K」
- 发布方:加州大学伯克利分校AI实验室(BAIR)
- 下载地址:https://bdd-data.berkeley.edu/
- 论文地址:https://arxiv.org/pdf/1805.04687.pdf
- 发布时间:2018
- 大小:57.45GB
- 简介:BDD100K凭借其数据集的多样性赢得了很大关注,该数据集通过众包的方式由数万名司机进行采集,涵盖的城市包括纽约、旧金山湾区和其他地区。BAIR 研究者在视频上采样关键帧,并为这些关键帧提供标注
- 特征
- 100,000个高清视频,超过1,100小时的驾驶记录,每个视频大约40秒长,清晰度为720p,帧率为30
- 视频还包含GPS位置信息、IMU数据和时间戳
- 涵盖晴天、阴天、雨天、雪天、多雾天气、多云6种天气;白天、夜晚;城市道路、隧道、高速公路、居民区、停车场和加油站等不同驾驶场景
- 研究者为每个视频的第10秒采样关键帧
- 它包括以下类型的标注:图像标注、车道线标注、可行驶区域标注、道路目标检测、语义分割、实例分割、多目标检测与跟踪等。

12「KITTI」
- 发布方:德国卡尔斯鲁厄理工学院(KIT)、丰田工业大学芝加哥分校(TTIC)
- 下载地址:http://www.cvlibs.net/datasets/kitti/
- 论文地址:https://arxiv.org/abs/1803.09719
- 发布时间:2011
- 简介:KITTI是自动驾驶领域最重要的数据集之一,KITTI主要是针对自动驾驶领域的图像处理技术,主要应用在自动驾驶感知和预测方面,其中也涉及定位和SLAM技术。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能
- 特征
- 包括KITTI-stereo、KITTI-flow、KITTI-sceneflow、KITTI-depth、KITTI-odometry、KITTI-object、KITTI-tracking、KITTI-road、KITTI-semantics等数据集
- 立体图像和光流图:389对
- 39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成 ,以10Hz的频率采样及同步
- 3D物体检测类别:汽车、货车、卡车、行人、自行车、电车、其他
- 包括的场景:城市道路、乡村和高速公路
- 传感器:1个64线3D激光雷达,2个灰度摄像机,2个彩色摄像机,以及4个光学镜头
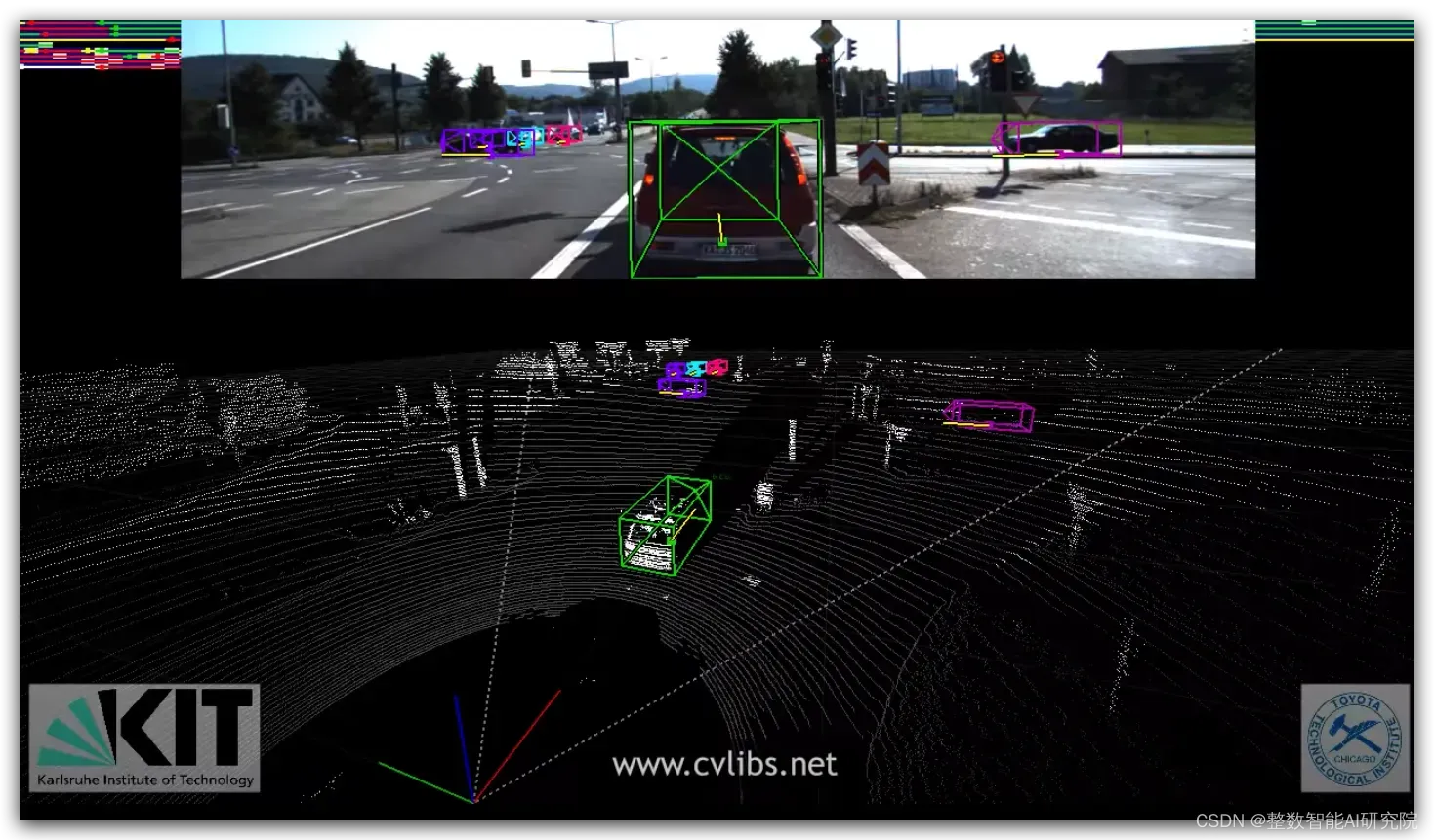
13「CityPersons 」
- 发布方:马克斯·普朗克学会 (Max Planck Inst.(Info.))
- 下载地址:https://www.cityscapes-dataset.com/login/
- 论文地址:https://arxiv.org/abs/1702.05693
- 发布时间:2017
- 简介:CityPersons是Cityscapes的一个子集,对Cityperscapes中的行人进行2D框标注。该行人数据集比以往的数据集如INRIA 、ETH、TudBrussels和Daimler等更具多样性和丰富性,涵盖的范围包括法国、德国和瑞士
- 特征
- 更细粒度的标签:行人(走路、跑步、站立)、骑自行车的人(骑自行车的人、骑摩托车的人)、坐着的、其他人(不寻常的人体姿势,如伸展等)
- 除了真人,海报上的人、雕塑上的人、镜子或窗户上人的倒影等。
- 数据集涵盖27个不同城市、3个不同季节以及不同的天气状况
- 数据集共包含35000个行人,平均每张图包含7个人的标注

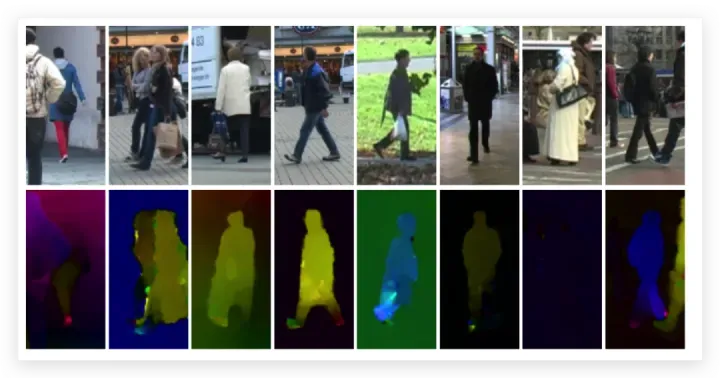
14「TUD-Brussels Pedestrian &TUD-MotionPairs 」
- 发布方:马克斯·普朗克学会 (Max Planck Inst.(Info.))
- 下载地址:https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/research/people-detection-pose-estimation-and-tracking/multi-cue-onboard-pedestrian-detection
- 论文地址:https://www.mpi-inf.mpg.de/fileadmin/inf/d2/wojek/wojek09cvpr.pdf
- 发布时间:2010
- 简介:马克斯·普朗克学会于2010年早期推出行人数据集,马克斯·普朗克学会通过这个数据集实现了当时一项具有挑战性的任务——即在汽车行驶过程中,通过样貌特征和运动特征来实现多视角的行人检测
- TUD-Brussels Pedestrian
- 从布鲁塞尔市中心驾驶汽车收集的数据
- 508对分辨率为640×480的图像
- 包含1326个行人标注

- TUD- MotionPairs
- 1092对图像,带有1776个行人标注的图像
- 192对包含正负片的图像
- 在城市步行区记录的多视图图像
“联系我们”
我们希望通过我们在数据处理领域的专业能力,在未来三年,能够赋能1000+以上的AI企业,成为这些企业的「数据合伙人」,因此我们非常期待能与正在阅读这篇文章的您,有进一步的沟通交流,所以非常欢迎您来联系我们,一起探索合作的可能性,我们的联系方式如下:
联系人:祁先生 13456872274
更多详情可访问我们的官网:www.molardata.com
版权声明:本文为博主整数智能AI研究院原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/molardata/article/details/123406244