初学者应该知道的 10 大机器学习算法
来源:https://builtin.com/data-science/tour-top-10-algorithms-machine-learning-newbies
机器学习算法被描述为学习一个目标函数 (f),它最好地将输入变量 (X) 映射到输出变量 (Y):Y = f(X)
最常见的机器学习类型是学习映射 Y = f(X) 以针对新 X 预测 Y。这称为预测建模或预测分析,目标就是要做出最准确的预测。
线性回归
线性回归是统计和机器算法中最容易理解的一种。
线性回归的表示是一个方程,它通过找到称为系数 (B) 的输入变量的特定权重来描述最适合输入变量 (x) 和输出变量 (y) 之间关系的直线。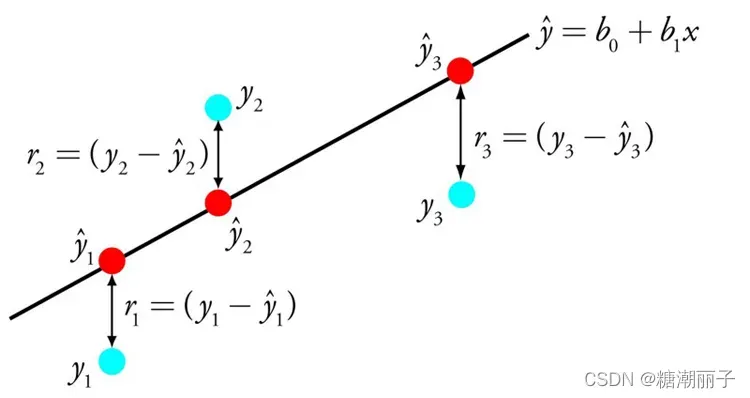
例如:y = B0 + B1 * x
我们将在给定输入 x 的情况下预测 y,线性回归学习算法的目标是找到系数 B0 和 B1 的值。
线性回归模型可以使用不同的技术从数据中学习,例如普通最小二乘的线性代数解和梯度下降优化。
逻辑回归
逻辑回归是机器学习从统计学领域借用的另一种技术。它是二元分类问题(具有两个类值的问题)的首选方法。
逻辑回归类似于线性回归,其目标是找到对每个输入变量加权的系数值。与线性回归不同,输出的预测使用称为逻辑函数的非线性函数进行转换。
逻辑函数看起来像一个大 S,会将任何值转换为 0 到 1 的范围。这很有用,因为我们可以将规则应用于逻辑函数的输出以将值捕捉到 0 和 1(例如,如果小于 0.5 则输出 1) 并预测一个类值。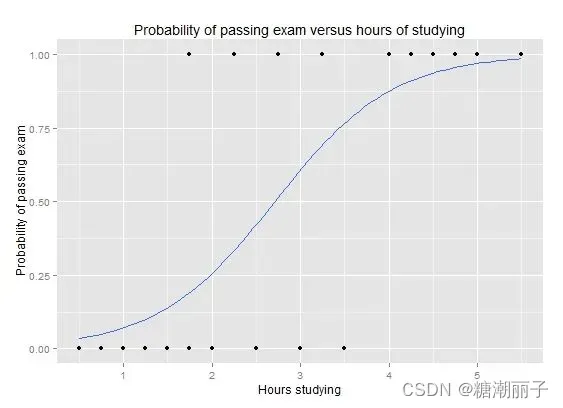
由于模型的学习方式,逻辑回归所做的预测也可以用作给定数据实例属于 0 类或 1 类的概率。这对于需要给出更多理由的问题是很有用一个预测。
与线性回归一样,当您删除与输出变量无关的属性和彼此非常相似(相关)的属性时,逻辑回归效果更好。这是一个快速学习模型,适用于二元分类问题。
线性判别分析
逻辑回归是一种传统上仅限于两类分类问题的分类算法。如果您有两个以上的类别,则线性判别分析算法是首选的线性分类技术。
LDA 的表示非常简单。它由您的数据的统计属性组成,为每个类计算。对于单个输入变量,这包括:
- 每个类别的平均值。
- 跨所有类计算的方差。
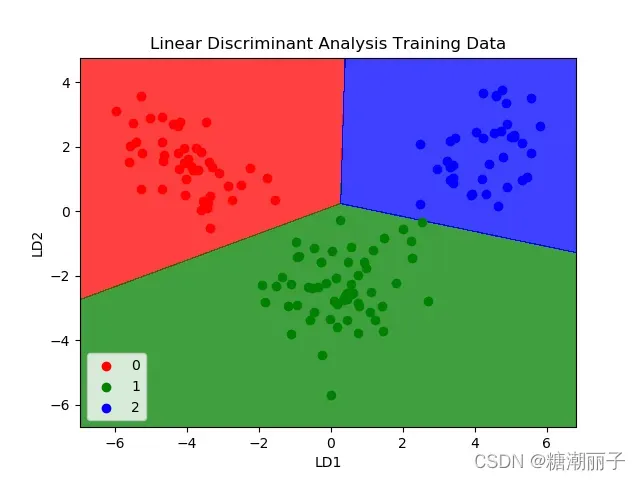
通过计算每个类的判别值并对具有最大值的类进行预测。假设数据具有高斯分布(钟形曲线),因此最好事先从数据中去除异常值。它是一种对预测建模问题进行分类的简单而强大的方法。
分类和回归树
决策树是预测建模机器学习的重要算法。
决策树模型的表示是二叉树。这是来自算法和数据结构的二叉树,没什么花哨的。每个节点代表一个输入变量 (x) 和该变量上的一个分割点(假设变量是数字)。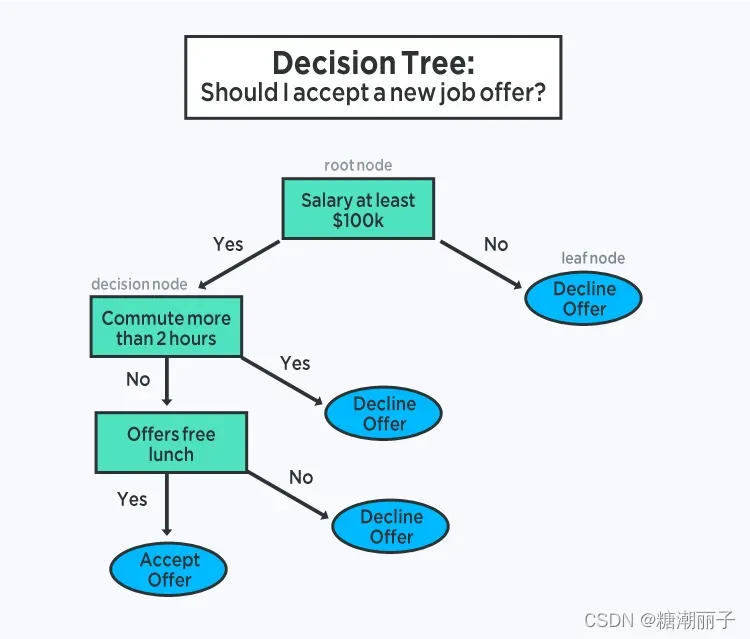
树的叶节点包含一个输出变量 (y),用于进行预测。通过遍历树的分裂直到到达叶节点并在该叶节点处输出类值来进行预测。
树预测也很快。它们对于广泛的问题通常也是准确的,并且不需要任何特殊的数据准备。
朴素贝叶斯
朴素贝叶斯是一种简单但功能强大的预测建模算法。
该模型由两种类型的概率组成,可以直接从您的训练数据中计算得出:
1)每个类别的概率;
2)给定每个 x 值的每个类的条件概率。
计算后,概率模型可用于使用贝叶斯定理对新数据进行预测。当数据是实值时,通常假设高斯分布(钟形曲线),以便可以轻松估计这些概率。
朴素贝叶斯被称为朴素,因为它假设每个输入变量都是独立的。这是一个强有力的假设,对于真实数据是不现实的,但是,该技术在处理大量复杂问题时非常有效。
K-最近邻 (KNN)
KNN算法非常简单,非常有效。KNN 的模型表示是整个训练数据集。
通过在整个训练集中搜索 K 个最相似的实例(邻居)并汇总这些 K 个实例的输出变量,对新数据点进行预测。
对于回归问题,这可能是平均输出变量,对于分类问题,这可能是模式(或最常见的)类值。
诀窍是如何确定数据实例之间的相似性。 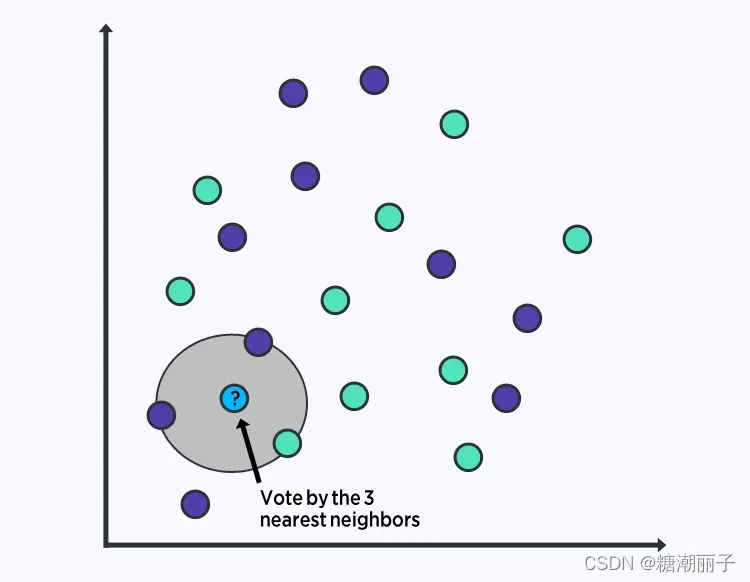
KNN 可能需要大量内存或空间来存储所有数据,但仅在需要预测时才及时执行计算(或学习)。这个期间你可以随着时间的推移更新和管理训练实例,以保持预测的准确性。
学习向量量化 (LVQ)
K-Nearest Neighbors 的一个缺点是需要保留整个训练数据集。
学习向量量化算法(或简称 LVQ)是一种人工神经网络算法,它允许选择要挂起的训练实例数量并准确了解这些实例的外观。
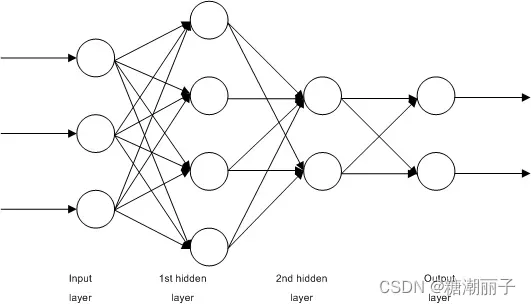
LVQ 的表示是码本向量的集合。这些是在开始时随机选择的,并适合在学习算法的多次迭代中最好地总结训练数据集。学习后,码本向量可以像 K-Nearest Neighbors 一样用于进行预测。通过计算每个码本向量与新数据实例之间的距离,找到最相似的邻居(最佳匹配码本向量)。然后返回最佳匹配单元的类值或(回归情况下的实际值)作为预测。
如果重新调整数据以具有相同的范围,例如在 0 和 1 之间,则可以获得最佳结果。
如果发现 KNN 在你的数据集上提供了良好的结果,可以尝试使用 LVQ 来减少存储整个训练数据集的内存需求。
支持向量机 (SVM)
支持向量机可能是最受欢迎和谈论最多的机器学习算法之一。
超平面是分割输入变量空间的线。
在 SVM 中,选择一个超平面来最好地将输入变量空间中的点按它们的类(类 0 或类 1)分开。在二维中,你可以将其可视化为一条线,假设我们所有的输入点都可以被这条线完全隔开。SVM 学习算法通过超平面找到导致类的最佳分离的系数。
超平面和最近数据点之间的距离称为边距。
可以分离这两个类的最佳或最优超平面是具有最大边距的线。
只有这些点与定义超平面和构建分类器相关。这些点称为支持向量。它们支持或定义超平面。在实践中,会使用一种优化算法来寻找最大化margin的系数值。
Bagging 和随机森林
随机森林是最流行和最强大的机器学习算法之一。它是一种集成机器学习算法。称为 Bootstrap Aggregation 或 bagging。
Bootstrap是一种强大的统计方法,用于从数据样本中估计数量。
在 bagging 中,使用相同的方法,但用于估计整个统计模型,最常见的是决策树。
获取多个训练数据样本,并为每个数据样本建立一个模型。当您需要对新数据进行预测时,每个模型都会进行预测,并对预测进行平均以更好地估计真实输出值。
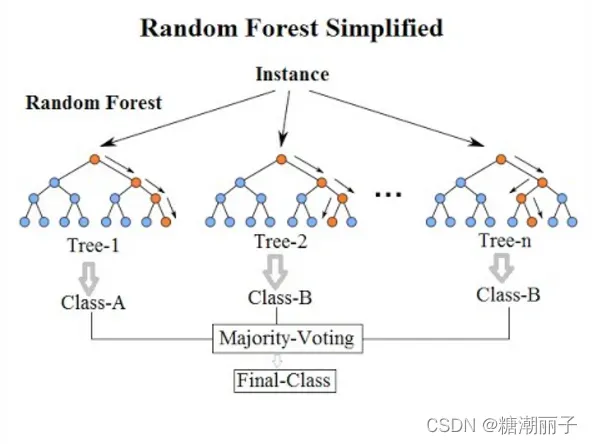
随机森林是这种方法的一种改进,其中创建决策树,因此不是选择最佳分割点,而是通过引入随机性进行次优分割。
因此,为每个数据样本创建的模型比其他模型更加不同,但仍然以其独特和不同的方式准确。结合他们的预测可以更好地估计真实的潜在输出值。
Boosting 和 AdaBoost
Boosting 是一种集成技术,它试图从多个弱分类器中创建一个强分类器。
这是通过从训练数据构建模型然后创建第二个模型来尝试纠正第一个模型中的错误来完成的。添加模型直到训练集被完美预测或添加最大数量的模型。
AdaBoost 是为二进制分类开发的第一个真正成功的提升算法。这是理解 boosting 的最佳起点。
AdaBoost 与短决策树一起使用。
创建第一棵树后,该树在每个训练实例上的性能用于衡量创建的下一棵树应该对每个训练实例给予多少关注。难以预测的训练数据被赋予更高的权重,而易于预测的实例被赋予更少的权重。
模型一个接一个地按顺序创建,每个模型都会更新训练实例的权重,这会影响序列中下一棵树执行的学习。
在构建所有树之后,对新数据进行预测,每棵树的性能取决于它在训练数据上的准确程度。
由于算法非常重视纠正错误,因此拥有干净的数据并删除异常值非常重要。
版权声明:本文为博主糖潮丽子原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_39783601/article/details/123365469