各位同学好,今天和大家分享一下如何使用 mediapipe+opencv 实现眨眼计数器。先放张图看效果。
下图左侧为视频图像,右侧为平滑后的人眼开合比曲线。以左眼为例,若眼眶上下边界的距离与左右边界的距离的比值小于26%,就认为是眨眼。当眨眼成功计数一次后,接下来的10帧不再计算眨眼次数,防止重复。
不闪烁时:
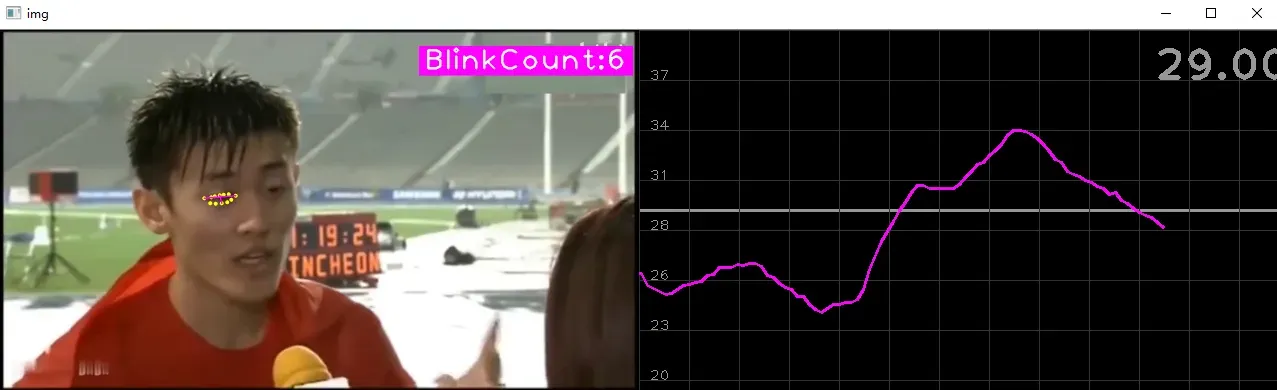
闪烁时:
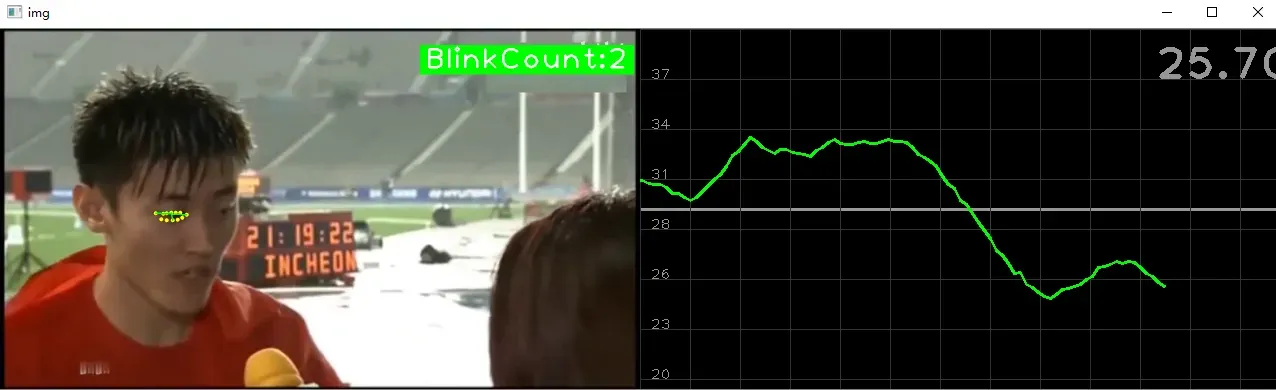
1. 安装工具包
pip install opencv_python==4.2.0.34 # 安装opencv
pip install mediapipe # 安装mediapipe
# pip install mediapipe --user #有user报错的话试试这个
pip install cvzone # 安装cvzone
# 导入工具包
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector # 导入脸部关键点检测方法
from cvzone.PlotModule import LivePlot # 导入实时绘图模块2. 脸部关键点检测
(1) cvzone.FaceMeshModule.FaceMeshDetector() 人脸关键点检测方法
范围:
staticMode:默认为 False ,将输入图像视为视频流。它将尝试在第一个输入图像中检测人脸,并在成功检测后进一步定位468个关键点的坐标。在随后的图像中,一旦检测到所有 maxFaces 张脸并定位了相应的关键点的坐标,它就会跟踪这些坐标,而不会调用另一个检测,直到它失去对任何一张脸的跟踪。这减少了延迟,非常适合处理视频帧。如果设置为 True ,则在每个输入图像上运行脸部检测,用于处理一批静态的、可能不相关的图像。
maxFaces:最多检测几张脸,默认为 2
minDetectionCon=0.5:脸部关键点检测模型的最小置信值(0-1之间),超过阈值则检测成功。默认为 0.5
minTrackCon=0.5:关键点坐标跟踪模型的最小置信值 (0-1之间),用于将手部坐标视为成功跟踪,不成功则在下一个输入图像上自动调用手部检测。将其设置为更高的值可以提高解决方案的稳健性,但代价是更高的延迟。如果mode 为 True,则忽略这个参数,手部检测将在每个图像上运行。默认为 0.5
(2) cvzone.FaceMeshModule.FaceMeshDetector.findFaceMesh() 人脸关键点检测方法
范围:
img: 需要检测关键点的帧图像,格式为BGR
draw:是否需要在原图像上绘制关键点及连线
返回值:
img: 返回绘制了关键点及连线后的图像
faces: 检测到的脸部信息,三维列表,包含每张脸的468个关键点。
代码显示如下:
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector # 导入脸部关键点检测方法
#(1)读取视频文件
filepath = 'D:/deeplearning/video/eyes.mp4'
cap = cv2.VideoCapture(filepath)
#(2)配置
# 接收脸部检测方法,设置参数
detector = FaceMeshDetector(maxFaces=1) # 最多只检测一张脸
#(3)图像处理
while True:
# 原视频较短,循环播放
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT): # 如果当前帧等于总帧数,即视频播放到了结尾
cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # 让当前帧为0,重置视频从头开始
# 返回帧图像是否读取成功success,读取的帧图像img
success, img = cap.read()
#(4)关键点检测,绘制人脸网状检测结果
img, faces = detector.findFaceMesh(img) # img为绘制关键点后的图像,faces为关键点坐标
# 查看结果
print(faces) # faces是三维数组,包含每张脸所有关键点的坐标[[[mark1],[mark2],..,[markn]], [face2], [face3]...]
#(5)显示图像
cv2.imshow('img', img) # 传入窗口名和帧图像
# 每帧图像滞留10毫秒后消失,按下键盘上的ESC键退出程序
if cv2.waitKey(10) & 0xFF == 27:
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()
效果图如下,只检测一张人脸的468个关键点,并在输出栏中打印各个关键点的坐标。

2. 判断是否眨眼
(1)计算人眼开合比
首先考虑人脸到相机的距离对上下轨道和左右边界的距离有影响。人脸离相机越近,轨道之间的距离就越小。因此,单纯通过计算轨道上下边界的距离是无法判断是否眨眼的。
以左眼的开闭来判断是否眨眼,先根据人脸关键点坐标编号找出左眼关键点的编号。运用 cvzone.FaceMeshModule.FaceMeshDetector.findDistance() 来计算两个关键点之间的距离,等同于勾股定理计算两点间的距离。参数,两个点的坐标;返回值,两点之间的线段长度 length,线段信息 info包括(两个端点的坐标,以及连线中点的坐标)
计算得到左眼上下框之间的距离 lengthver ,以及左眼左右框之间的距离 lengthhor 。计算上下框距离除以左右框的距离,得到开合比 ratio
(2)实时绘图
cvzone.PlotModule LivePlot()实时绘图方法
范围:
w:绘图框的宽,默认为 640
h:绘图框的高,默认为 480
yLimit:y坐标的刻度范围,默认为 [0, 100]
interval:图像上每个点的间隔,默认为 0.001
invert:曲线图上下翻转,默认为 False
cvzone.PlotModule LivePlot.update()在图像上实时添加新的坐标点
范围:
y:新的坐标点的y轴坐标(x轴坐标为实时的时间点)
color:图像上的坐标点的颜色,默认是(255, 0, 255)
返回值:绘制坐标点的当前帧的图像
cvzone.stackImages()合并两张图像
范围:
imgList:列表形式,需要合并的图片,如:[img1, img2, …]
cols:列方向排序,图片合并后排几列
scale:改变合并后的图像的size,图像大小是原来的几倍。
返回值:合并图像
然后添加上面的代码:
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector # 导入脸部关键点检测方法
from cvzone.PlotModule import LivePlot # 导入实时绘图模块
#(1)读取视频文件
filepath = 'D:/deeplearning/video/eyes1.mp4'
cap = cv2.VideoCapture(filepath)
#(2)配置
# 接收脸部检测方法,设置参数
detector = FaceMeshDetector(maxFaces=1) # 最多只检测一张脸
# 人眼关键点所在的索引
idList = [22, 23, 24, 26, 110, 130, 157, 158, 159, 160, 161, 243] # 左眼
# 接收实时绘图方法,图宽640高360,y轴刻度范围,间隔默认0.01,上下翻转默认False
plotY = LivePlot(640, 360, [20,40], invert=True)
#(3)图像处理
while True:
# 原视频较短,循环播放
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT): # 如果当前帧等于总帧数,即视频播放到了结尾
cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # 让当前帧为0,重置视频从头开始
# 返回帧图像是否读取成功success,读取的帧图像img
success, img = cap.read()
#(4)关键点检测,不绘制关键点及连线
img, faces = detector.findFaceMesh(img, draw=False) # img为绘制关键点后的图像,faces为关键点坐标
# 如果检测到关键点了就接下去处理
if faces:
face = faces[0] # face接收一张脸的所有关键点信息,且faces是三维列表
# 遍历所有的眼部关键点
for id in idList:
cv2.circle(img, tuple(face[id]), 4, (0,255,255), cv2.FILLED) # 以关键点为圆心半径为5画圆
# 由于人脸距离摄像机的距离的远近会影响眼部上下边界之间的距离,因此通过开合比例来判断是否眨眼
leftUp = tuple(face[159]) # 左眼最上边界的关键点坐标
leftDown = tuple(face[23]) # 左眼最下边界的关键点坐标
leftLeft = tuple(face[130]) # 左眼最左边界的关键点坐标
leftRight = tuple(face[243]) # 左眼最右边界的关键点坐标
# 计算上下边界以及左右边界的距离,函数返回距离length,以及线段两端点和中点坐标,这里用不到
lengthver, __ = detector.findDistance(leftUp, leftDown) # 上下边界距离
lengthhor, __ = detector.findDistance(leftLeft, leftRight) # 左右边界距离
# 在上下及左右关键点之间各画一条线段,端点坐标是元组
cv2.line(img, leftUp, leftDown, (255,0,255), 2)
cv2.line(img, leftLeft, leftRight, (255,0,255), 2)
# 计算竖直距离与水平距离的比值
ratio = 100*lengthver/lengthhor
print('水平距离:', lengthhor, '垂直距离:', lengthver, '百分比%:', ratio)
# 以时间为x轴,百分比为y轴,绘制实时变化曲线
imgPlot = plotY.update(ratio, (0,0,255)) # 参数:每个时刻的y值,线条颜色
#(5)眨眼计数器
# 重塑图像的宽和高,保证图像size和曲线图size一致
img = cv2.resize(img, (640,360))
# 将变化曲线和原图像组合起来,2代表排成两列,最后一个1代表比例不变
imgStack = cvzone.stackImages([img, imgPlot], 2, 1)
#(6)显示图像
cv2.imshow('img', imgStack) # 传入窗口名和帧图像
# 每帧图像滞留20毫秒后消失,按下键盘上的ESC键退出程序
if cv2.waitKey(20) & 0xFF == 27:
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()效果图如下,右侧为每一帧人眼开合百分比,下方输出列打印每帧眼窝的横纵距离和比例。

3. 眨眼计数器
(1)平滑曲线
由于每一帧计算一次人眼开合比,曲线变化幅度较大,不宜判断。因此对曲线进行平滑操作,如果帧数小于10帧,更新的坐标是每帧的人眼闭合比;如果帧数大于10帧,那就每10帧求一次均值,将这个均值更新到图像上。例如,第11帧图像的人眼闭合比为,第2至第11帧的人眼闭合比的均值。
如下面代码中的第(5)步,变量 ratioList 中总是存放10帧的人眼闭合比值。如,计算第12帧图像的闭合比时,就将列表中第2帧的闭合比值删除,计算第3帧到第12帧的均值
(2)避免重复计数
如下面代码中的第(6)步,如果判断了一次眨眼之后,那么接下来的10帧都是属于该次眨眼的过程,只有10帧过后才能进行下次一眨眼计数。
代码显示如下:
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector # 导入脸部关键点检测方法
from cvzone.PlotModule import LivePlot # 导入实时绘图模块
#(1)读取视频文件
filepath = 'D:/deeplearning/video/eyes1.mp4'
cap = cv2.VideoCapture(filepath)
#(2)配置
# 接收脸部检测方法,设置参数
detector = FaceMeshDetector(maxFaces=1) # 最多只检测一张脸
# 人眼关键点所在的索引
idList = [22, 23, 24, 26, 110, 130, 157, 158, 159, 160, 161, 243] # 左眼
# 接收实时绘图方法,图宽640高360,y轴刻度范围,间隔默认0.01,上下翻转默认False
plotY = LivePlot(640, 360, [20,40], invert=True)
ratioList = [] # 存放实时的人眼开合百分比
blinkCounter = 0 # 眨眼计数器默认=0
counter = 0 # 代表当前帧没计算过眨眼次数
colorblink = (255,0,255) # 不眨眼时计数器的颜色
#(3)图像处理
while True:
# 原视频较短,循环播放
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT): # 如果当前帧等于总帧数,即视频播放到了结尾
cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # 让当前帧为0,重置视频从头开始
# 返回帧图像是否读取成功success,读取的帧图像img
success, img = cap.read()
#(4)关键点检测,不绘制关键点及连线
img, faces = detector.findFaceMesh(img, draw=False) # img为绘制关键点后的图像,faces为关键点坐标
# 如果检测到关键点了就接下去处理
if faces:
face = faces[0] # face接收一张脸的所有关键点信息,且faces是三维列表
# 遍历所有的眼部关键点
for id in idList:
cv2.circle(img, tuple(face[id]), 4, (0,255,255), cv2.FILLED) # 以关键点为圆心半径为5画圆
# 由于人脸距离摄像机的距离的远近会影响眼部上下边界之间的距离,因此通过开合比例来判断是否眨眼
leftUp = tuple(face[159]) # 左眼最上边界的关键点坐标
leftDown = tuple(face[23]) # 左眼最下边界的关键点坐标
leftLeft = tuple(face[130]) # 左眼最左边界的关键点坐标
leftRight = tuple(face[243]) # 左眼最右边界的关键点坐标
# 计算上下边界以及左右边界的距离,函数返回距离length,以及线段两端点和中点坐标,这里用不到
lengthver, __ = detector.findDistance(leftUp, leftDown) # 上下边界距离
lengthhor, __ = detector.findDistance(leftLeft, leftRight) # 左右边界距离
# 在上下及左右关键点之间各画一条线段,端点坐标是元组
cv2.line(img, leftUp, leftDown, colorblink, 2)
cv2.line(img, leftLeft, leftRight, colorblink, 2)
# 计算竖直距离与水平距离的比值
ratio = 100*lengthver/lengthhor
ratioList.append(ratio) # 存放每帧图像的人眼开合比
#(5)平滑实时变化曲线
# 每10帧图像的人眼开合百分比取平均值,在图像上更新一个值
if len(ratioList) > 10:
ratioList.pop(0) # 删除最前面一个元素
ratioAvg = sum(ratioList)/len(ratioList) # 超过10帧后,保证每10个元素取平均
print(ratioAvg)
#(6)眨眼计数器
# 当开合比低于26%并且距前一次计算眨眼已超过10帧时,认为是眨眼
if ratioAvg < 26 and counter == 0:
blinkCounter += 1 # 眨眼次数加1
colorblink = (0,255,0) # 眨眼时改变当前帧的颜色
counter = 1 # 当前帧计算了一次眨眼
# 保证在一次眨眼期间只在10帧中计算一次,不再多余的计算眨眼次数
if counter != 0: # 代表前面某10帧已经计算过一次眨眼
counter += 1 # 累计不计算眨眼次数的帧数+1
if counter > 10: # 如果距前一次计算眨眼次数超过10帧了,那么下一次可以计算眨眼
counter = 0
colorblink = (255,0,255) # 不眨眼时计数器颜色回到原颜色
# 以时间为x轴,百分比为y轴,绘制实时变化曲线
imgPlot = plotY.update(ratioAvg, colorblink) # 参数:每个时刻的y值,线条颜色
# 将计数显示在图上
cvzone.putTextRect(img, f'BlinkCount:{blinkCounter}', # 显示内容是字符串类型
(850,80), 4, 3, colorR=colorblink) # 设置文本显示位置、颜色、线条
# 重塑图像的宽和高,保证图像size和曲线图size一致
img = cv2.resize(img, (640,360))
# 将变化曲线和原图像组合起来,2代表排成两列,最后一个1代表比例不变
imgStack = cvzone.stackImages([img, imgPlot], 2, 1)
#(7)显示图像
cv2.imshow('img', imgStack) # 传入窗口名和帧图像
# 每帧图像滞留20毫秒后消失,按下键盘上的ESC键退出程序
if cv2.waitKey(20) & 0xFF == 27:
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()效果图如下:闪烁时曲线和计数器变为绿色
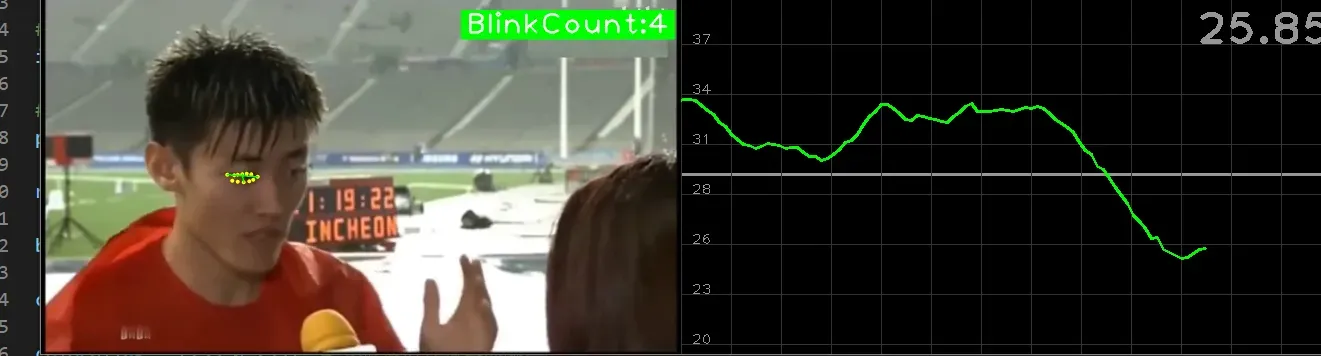
版权声明:本文为博主立Sir原创文章,版权归属原作者,如果侵权,请联系我们删除!