参考
[Sun, X., Yin, S., Peng, X., Liu, R., Seo, J。S., & Yu, S。(2018)。XNOR-RRAM: A scalable and parallel resistive synaptic architecture for binary neural networks。Proceedings of the 2018 Design, Automation and Test in Europe Conference and Exhibition, DATE 2018, 2018-Janua, 1423–1428。https://doi.org/10.23919/DATE.2018.8342235]
《Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or −1》
【深度学习——BNN】:二值神经网络BNN——学习与总结
深度学习【6】二值网络(Binarized Neural Networks)学习与理解
读书笔记一:RRAM (ReRAM)
Background:BNN与XNOR operation
BNN binarized neural network,是在CNN的基础上,对权值和激活值(特征值)做二值化处理,即取值是+1或-1。跟CNN结构是相似的。梯度下降,权值更新,卷积运算都还是在,各有优化。
xb=sign(x)
if x>=0 xb=+1
else xb=-1
前向传播
二值网络训练时的权值参数W,必须包含实数型的参数。
- 将真实权重参数二值化,得到二值权重参数。
- 然后利用二值化后的参数计算得到实数型的中间向量,该向量再通过Batch Normalization操作,得到实数型的隐藏层激活向量。
- 如果不是输出层,则向量被二值化。
反向传播
由于Sign(x)函数的梯度,几乎处处为0,这显然不利于反向传播。于是采用HTanh(x)代替Sign(x)。此处略。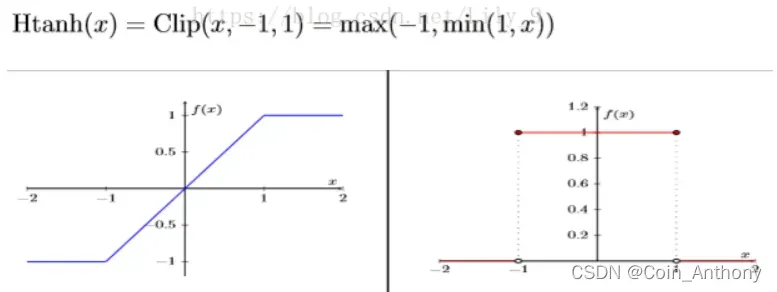
左图表示HTanh(x)函数,右图表示HTanh(x)梯度。
XNOR
二值网络中最重要的乘法优化,是前向传播中隐藏层的输出 乘以权值W的乘法优化,也就是卷积操作的优化。
对于二值网络的卷积运算,只是+1与-1之间的乘累加运算。根据+1与-1的乘法运算真值表的特点,Bengio提出了“XNOR”代替“乘法”的优化方式。
可以说是绝对的。
输入层数据是8位二进制,而激活向量和权值矩阵中的元素全都是1位二进制表示。
为什么可以用“Xnor”代替乘法?如下图为+1,-1的乘法运算真值表,和Xnor(同或)真值表: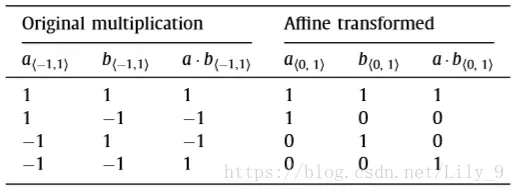
不难发现将-1替换为0后,真值表完全一致。
例如,
a=[1,-1, 1, 1, -1]
W=[-1,1,1,-1,-1]
正常乘法:
a1·w1+a2·w2+a3·w3+a4·w4+a5·w5=1·-1 + -1·1 + 1·1 + 1 ·-1 + -1· -1 = -1
Xnor的计算方式:
a=[1,0,1,1,0]
W=[0,1,1,0,0]
a·W=[1·0,0·1,1·1,1·0,0·0]=[1,1,0,1,0]
popcount(a·w)=3
popcount(x)这一操作,表示统计向量x中1的个数。
故a·W的异或求和结果为:
popcount-(5-popcount) = 2*popcount(a·W)-5 = 1
再加上非运算为-1,即a·W 全元素的XNOR结果为-1
概括
总的来说,BNN有以下几个特点:
①减小内存占用:显然,权值和激活值二值化后,只需1bit即可表示,大幅度地降低了内存的占用。
②降低功耗:因为二值化,原来32位浮点数,只需要1bit表示,存取内存的操作量降低了;其实,存取内存的功耗远大于计算的功耗,所以相比于32-bit DNN,BNN的内存占用和存取操作量缩小了32倍,极大地降低了功耗。
③减小硬件面积开销:XNOR代替乘法,用1-bit的XNOR-gate代替了原来的32-bit浮点数乘法,对面向深度学习的硬件来说有很大影响。譬如,FPGA原来完成一个32-bit的浮点数乘法需要大约200个Slices,而1-bit 的Xnor-gate 只需要1个Slice,硬件面积开销,直接缩小了200倍。
④速度快:作者专门写了一个二值乘法矩阵的GPU核,可以保证在准确率无损失的前提下,运行速度提高7倍。
RRAM
还不如看看涛涛的文章,不好意思,我的博客真是一坨屎……
读书笔记一:RRAM (ReRAM)
Circuit design
在RRAM的cross array上怎么实现XNOR操作。
这篇讲Shimeng Yu提出的方案:
也比较好理解,感觉后面2022年三星的MRAM的nature上的存算电路架构跟这个挺相似的,两个结加两个管子一组合当一个单元使,管子的通断和结的高低阻排列组合,搞出一个真值逻辑来。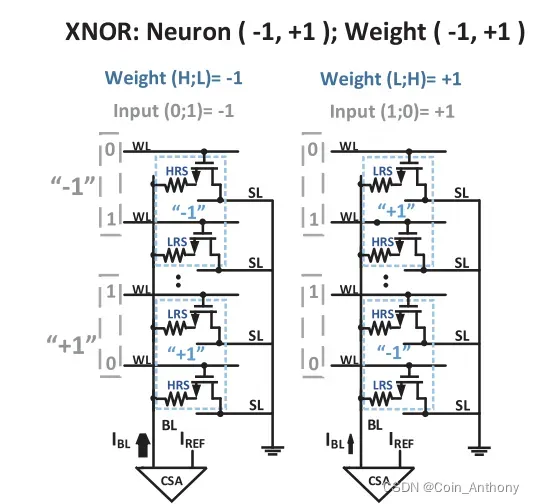
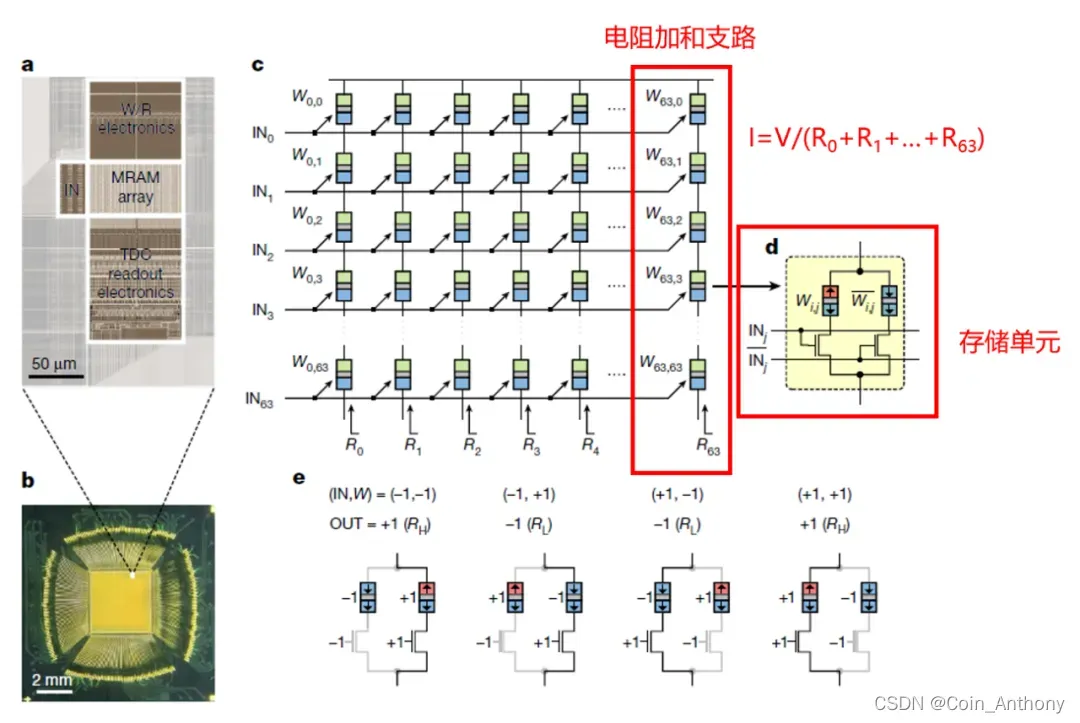
A crossbar array of magnetoresistive memory devices for in-memory computing
那这么来看,Shimeng Yu的XNOR-RRAM 这套架构,如果电路实现了,不只是仿真的层次,那妥妥的nature的水准,人家可是2017年就提出来了这种架构。不过三星还是厉害,说做啥就做啥,我一个更基础的架构搞了两年了也没出电路… …
Peripheral circuit
SA
这个方案做过调研,2010年之后大多数新型阻变存储器的SA都是这一路了,latch式curent-mode SA,上电快,容错率高,电路结构更简洁。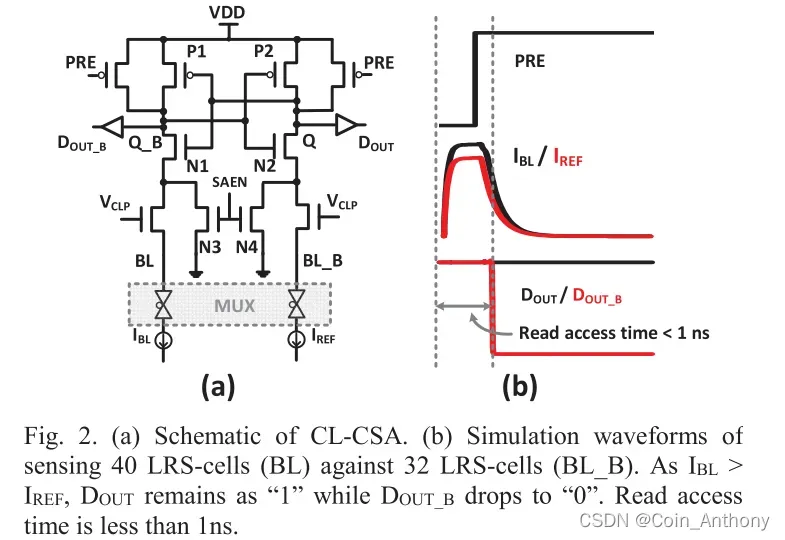
mux & decoder
本文电路设计上的一大亮点就是采用并行的weight电流累加操作,每次选通一根WL和所有的BL,一次标定出一列上所有的+1/-1权重的Icell,来跟总的Iref作对比。
以往的方案是先对一列上的单元的WL选通,然后逐根选通BL,row by row的逐个单元的送至列底部的CSA,标定出weight为+1/-1,然后送到累加器进行寄存,最终得出一列的权重之和。
但是我没懂的地方是,你这样做的话,你的Iref不得划分得很细很多level吗,不能拿一个Iref就区分出一列上所有权重值之和了吧,比如一列有64个bit,其中10个为+1(LRS)/54个为-1(HRS),那么HRS的电流可以忽略不计,电流之和就是10I_LRS_bit,那换一种情况,13个为+1(LRS)/51个为-1(HRS),电流之和就是13I_LRS_bit,那有多少张情况不得设置多少种Iref吗?这个文中所说的Multi-level sense amplifier好像不是这么回事啊???有大佬给我讲讲吗… …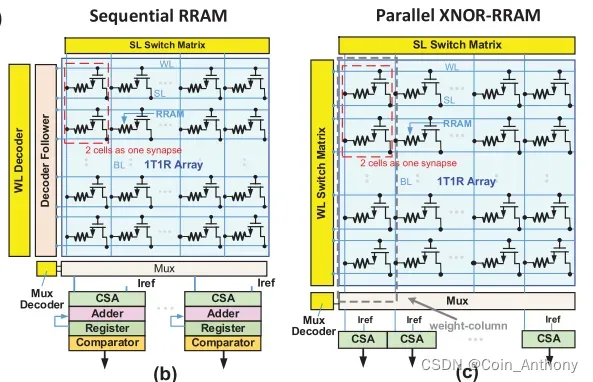
在后面就是介绍这个方案下,怎样划分sub-array和MLSA的level数来优化accuracy的过程了,就是纯仿真了。
多层感知机/CNN on MNIST/CIFAR-10
platform:Theano
但这里我又有疑问了:电路设计只到array以及SA/MUX/Decoder这些就结束了不说下去了,后面仿真结果是base什么来仿的呢,是拿array做XNOR然后把neuron output送到哪里去再继续执行呢?软件端吗?没看明白。有点云里雾里的,比如backward propagation怎么做的?pooling怎么做的?电路只给了个框架图,然后就仿真了,感觉确实看得有些懵逼。
文章出处登录后可见!