- Support Vector Machines
1. 介绍
SVM 是支持向量机(Support Vector Machine)的简称。简单来说 支持向量机所做的就是去寻找两类数据之间的分隔线,或者通常称为超平面(hyperplane)。
所以,假设我们有两种类型的数据,支持向量机是一种将这些点作为输入数据的算法。如果可能,输出一行来对数据进行分类。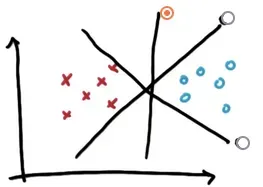
很明显,图中的三条线都将不同类别的数据点分开,一边是十字,另一边是圆圈。但是选择的线是最好的分割线,为什么?
它最大化了到最近点的距离,并且对于左右两个类别都是如此。这是一条在每个分类里均最大化了到最近点的距离的线,而这个距离通常被称之为间隔(margin)。间隔就是线与两个分类中最近点之间的距离。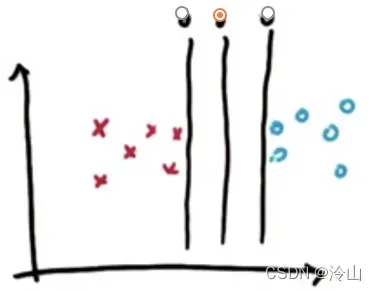 在上面的例子中,中间的分割线的间隔也是最大的。最左边的线对于蓝色数据集来说确实很大,但相对于另一边的叉子来说非常小。所以它并没有真正最大化两个数据集之间的分离,它只是最大化其中一个。右边的线也有同样的问题,所以选择中间的分割线——它看起来最稳定,不容易出现分类错误。如果选择与已有数据非常接近的线,弱噪声也会使这些数据的分类结果出现错误,使其显得不太稳定——–所以支持向量机的核心是最大限度地提高结果的稳定性。支持向量机首先保证分类正确,然后在这个前提下最大化区间。
在上面的例子中,中间的分割线的间隔也是最大的。最左边的线对于蓝色数据集来说确实很大,但相对于另一边的叉子来说非常小。所以它并没有真正最大化两个数据集之间的分离,它只是最大化其中一个。右边的线也有同样的问题,所以选择中间的分割线——它看起来最稳定,不容易出现分类错误。如果选择与已有数据非常接近的线,弱噪声也会使这些数据的分类结果出现错误,使其显得不太稳定——–所以支持向量机的核心是最大限度地提高结果的稳定性。支持向量机首先保证分类正确,然后在这个前提下最大化区间。
1.1 SVM 响应离群点
有时候,似乎支持向量机无法对某些问题进行正确分类。 例如,可能有这样的一个数据集,很显然,将两个类分割的决策面是不存在的,可以将下面的这个点当作 outlier。所以问题是,这时候希望支持向量机怎么做?
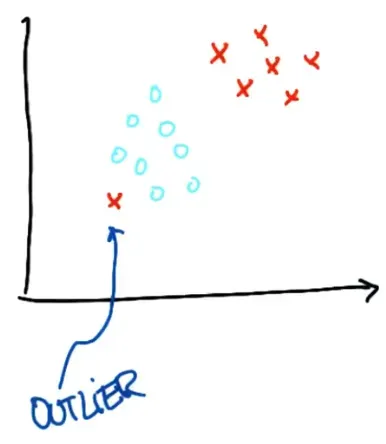
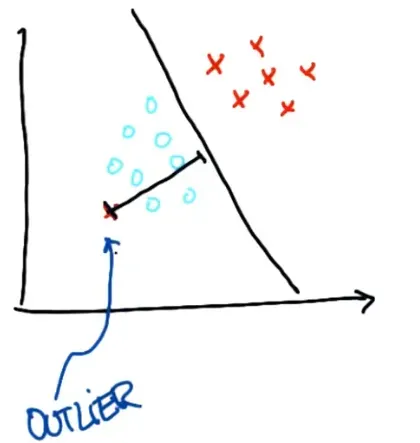
最好的情况是做一个像下面这样的决策边界,把错误分类的点直接放在另一边—–支持向量机可以做到这一点,它们往往可以找到一个决策边界,使两者相互分离数据集在容忍单个异常值的同时最大化,如此处所示。
1.2 非线性数据
现在给定一个更复杂的数据集,它由许多围绕 和
坐标系的原点聚集的红十字和大部分位于红十字周围的蓝色圆圈组成。根据上面提到的支持向量机的内容,不可能对这组数据给出一个理想的分类结果——两个类之间没有明显的线性超平面(没有线性分隔符来区分这两个类) ,即很难在两个类之间划清界限)。但实际上,支持向量机可以对此类数据进行分类。
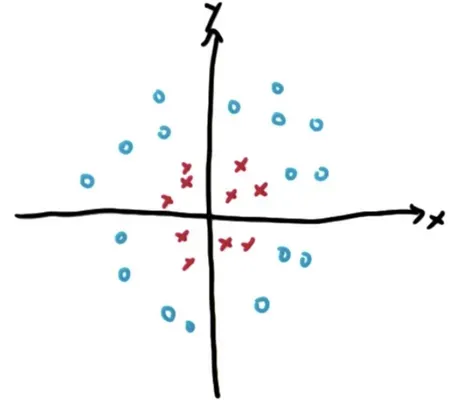
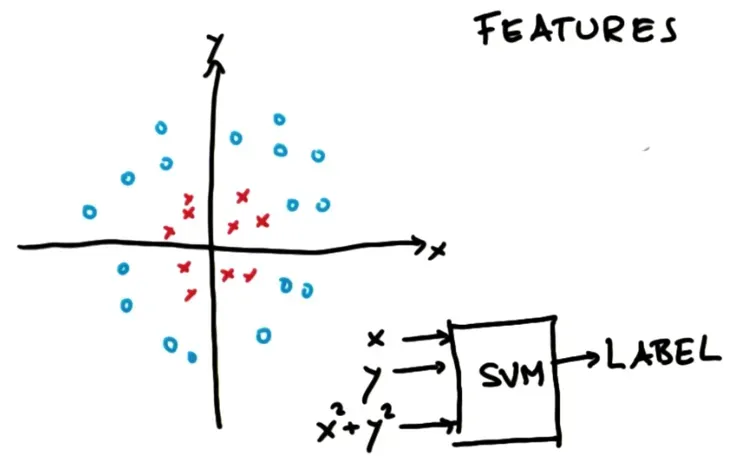
我们认为我们将数据特征和
输入到一个神奇的大盒子中,这是一个支持向量机,输出是一个标签,标签是一个蓝色的圆圈或一个红色的十字。现在选择一个对这组数据有帮助的特征,即
。现在有一个三维输入空间。
我们称这个新的特征为
。这里
的超平面和原点之间的距离
总是非负的。神奇的是所有的红十字都离原点很近;所有的蓝色圆圈都离原点很远。
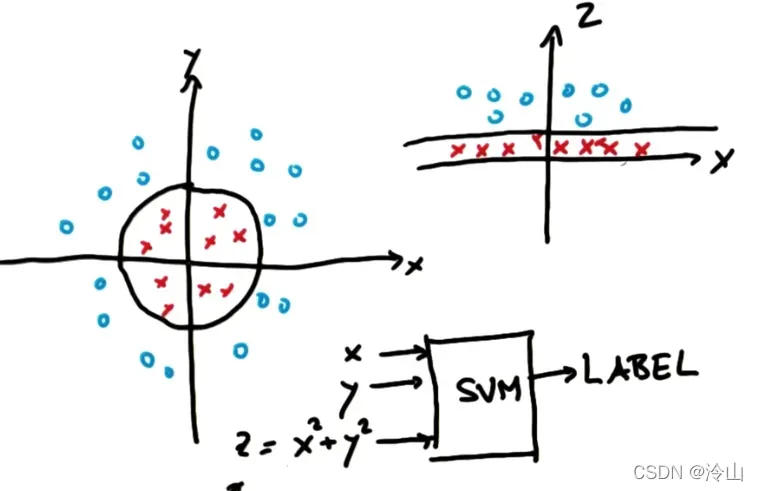
此时,图中坐标系中的数据可以进行线性分割。更有趣的是,图中的线性可分线对应于原始数据中的圆,它由坐标系中与原点等距的一系列点组成。因此,选择更合适的新特征可以让支持向量机学习圆形非线性决策面,非常神奇。
1.3 核技巧
上面的方法看起来真的很有用,但它真的很难,并且需要编写一些新功能,而 SVM 的优点在于它们不需要。
有一种函数,它们接收低纬度的输入空间或特征空间,并将其映射到高维度空间。所以,过去不可线性分隔的内容变为可分隔——–这些函数被称为核函数。该方法被称为核技巧(kernel trick)。
这些不仅是具有特征空间的函数,而且是具有两个以上输入的函数。应用核函数技术将输入空间从变换到更大的输入空间后,使用支持向量机对数据点进行分类,得到解后返回原空间,这样就可以得到一个非线性分离.这就是支持向量机。一个重要的优势。
很容易找到最佳的线性分类器或不同类之间的线性分隔线,而在高维空间中应用所谓的核技巧可以实现极其强大的功能——这是机器学习中最重要的事情。技巧之一。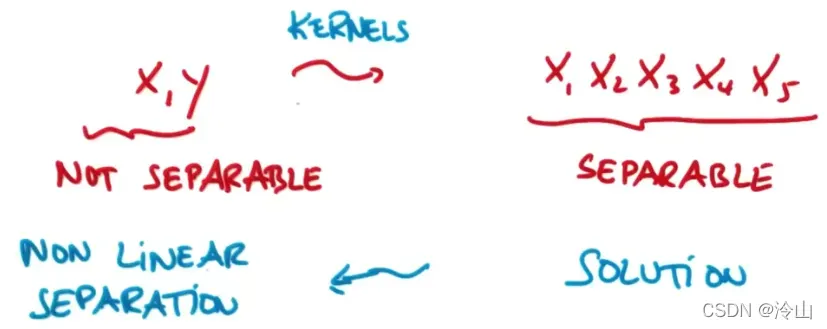
1.4 参数
创建分类器时要传递到形参的自变量称为实参。在 SVM 中,参数就是 核 和即将要讨论的另外连个参数:和
。下图中的两个 SVM 有不同的核函数,其中左侧的那个是线性函数(linear),右侧的那个是径向基函数(rbf):
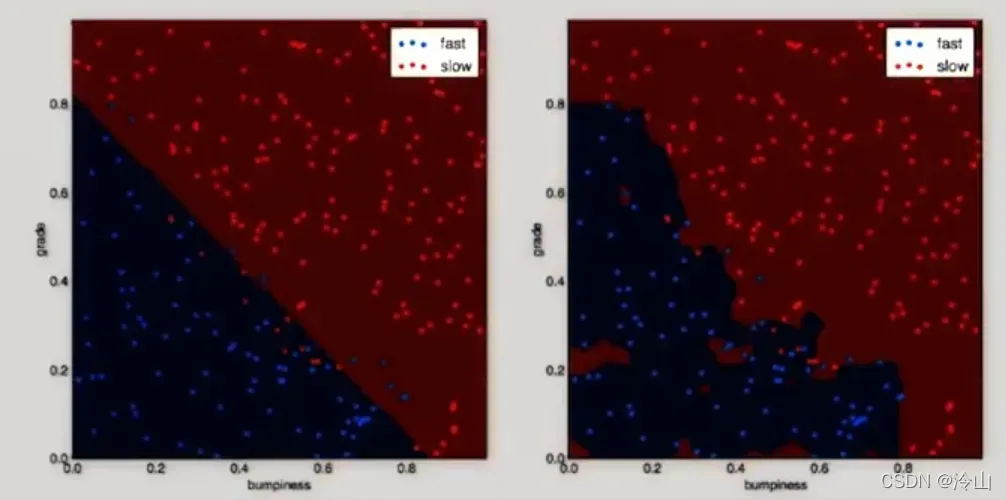
1.4.1 SVM C Parameter
SVM 的一个重要参数是参数,它会在光滑的决策边界以及尽可能正确分类所有训练点两者之间进行平衡。假设我们的数据如下图:
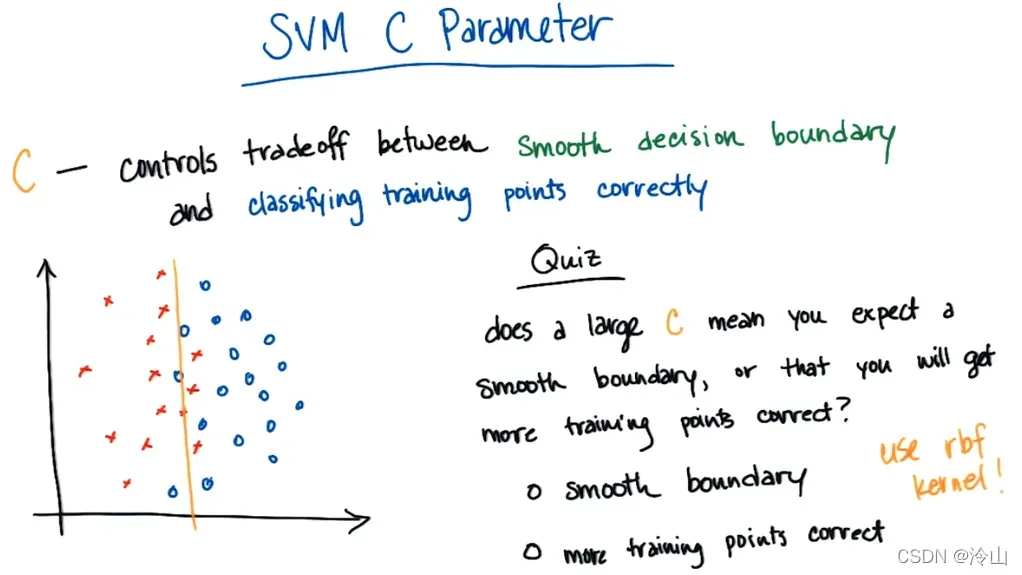 可以画出可能很直的线,代价是错误分类了几个点;也可以画出比较曲折的线,基本上所有的训练点都分类正确。然而,选择一个复杂的模型是有代价的——一个如此复杂的模型,在一定程度上可能无法很好地概括到测试集。有些会更直接,更直接,并且在开始查看测试集准确性时实际上可能是更好的选择。
可以画出可能很直的线,代价是错误分类了几个点;也可以画出比较曲折的线,基本上所有的训练点都分类正确。然而,选择一个复杂的模型是有代价的——一个如此复杂的模型,在一定程度上可能无法很好地概括到测试集。有些会更直接,更直接,并且在开始查看测试集准确性时实际上可能是更好的选择。
值越大,表示正确分类的训练点越多。事实上,其含义是
的值越大,可以获得越复杂的决策边界。它可以尽可能地围绕单个数据点弯曲,以使所有经过训练的分类正确。但代价是,它可能比预期的结果要复杂一些。您希望决策边界的形状有多接近直线,以及您希望如何平衡平滑的决策边界与训练点的正确分类,是机器学习的关键灵活部分。
1.4.2 SVM Gamma Parameter
定义单个训练样本对结果的影响程度。
值小表示每个点都可能对最终结果产生影响;反之,
值越大,表示训练样本只影响距离较短的决策边界。影响。
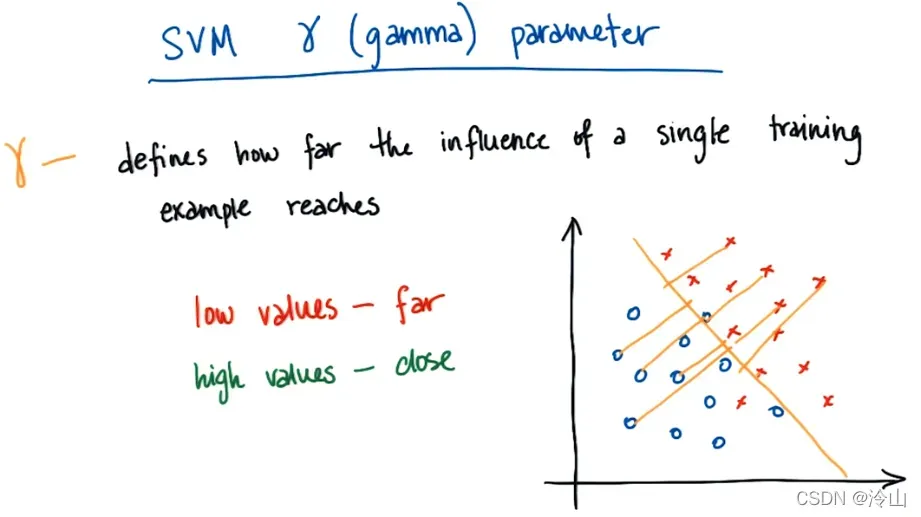
如下图所示,如果的值很大,那么决策边界的具体细节将取决于离边界很近的点。这些影响结果的数据点非常接近边界,在某种程度上,离决策边界较远的点被忽略了。如果
的值很小,那么即使是远离决策边界的点也会对决策边界的具体形状产生影响。这样做的效果是,特别是当
很大时,给出了一个相当曲折的决策边界。
也就是说,当的值很大时,闭合点极大地改变了决策边界的方向,使得该点最终在边界的正确一侧;如果
的值较小,则这些靠近决策边界的点的重要性会相对降低。此时,在下面的示例中,最终的决策边界更加线性和平滑,曲折更少。
1.5 Overfitting
在下面的示例中,决策边界非常复杂,这样的情况称为过拟合。这在机器学习中很常见。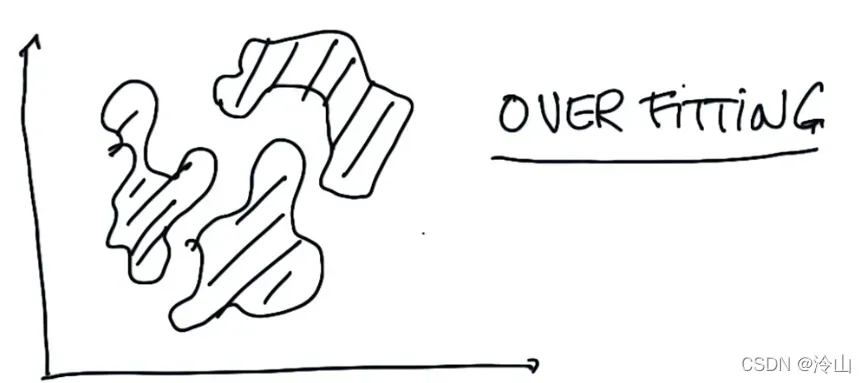
例如,在下面的一组数据中,看起来可以用图中的绿线分隔。虽然红色和蓝色之间有一个黑色的决策面,红色和蓝色的数据被正确分类,但是决策面上的许多其他位置看起来很奇怪。如果机器学习算法只是复制原始数据进行分类,就会产生类似的复杂结果,而不是像直线这样的简单结果,这意味着过度拟合。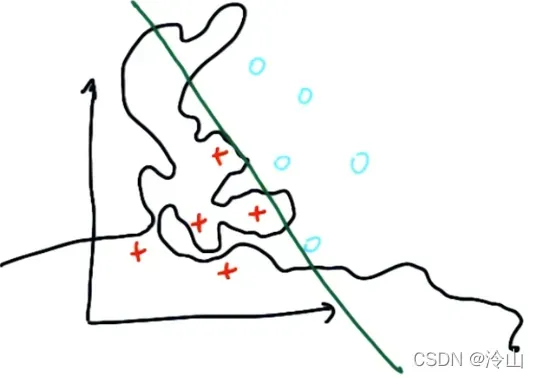 在机器学习中,应避免过拟合。控制过拟合的方法之一是通过调整算法中的参数
在机器学习中,应避免过拟合。控制过拟合的方法之一是通过调整算法中的参数、
和核函数。
1.6 总结
支持向量机在具有清晰分离边界的复杂数据上表现得非常好;它们在大量数据上表现不佳 ————- 因为在这种大小的数据集中,训练时间与数据量的立方成正比。对于噪声太大的数据集,支持向量机也不能很好地工作。
因此,如果类之间有很多重叠,并且需要将不同的类分开,那么朴素贝叶斯分类器会更有效。
因此,在数据集和可用特征方面,如果有海量数据集,特征很多,现成的支持向量机程序可能运行速度很慢,数据中的一些噪声也可能导致过拟合。因此,您需要在测试数据集上对其进行测试以查看其性能,然后训练好的模型就可以使用了。
2. SK Learn
支持向量机(SVMs)是一套用于分类、回归和异常值检测的监督学习方法。
支持向量机的优点是:
- 在高维空间有效;
- 当维度大于样本数时仍然有效;
- 在决策函数中使用训练点的子集(称为支持向量),因此它也是内存高效的;
- 通用性:可以为决策函数指定不同的核函数。提供了通用内核,但也可以指定自定义内核函数。
支持向量机的缺点是:
- 当特征数远大于样本数时,正则化项在选择核函数时避免过拟合非常重要;
- 支持向量机不直接提供概率估计,这些是使用代价较大的5倍交叉验证法来计算的。
2.1 分类
SVC、NuSVC和LinearSVC是能够对数据集进行二分类和多分类的类。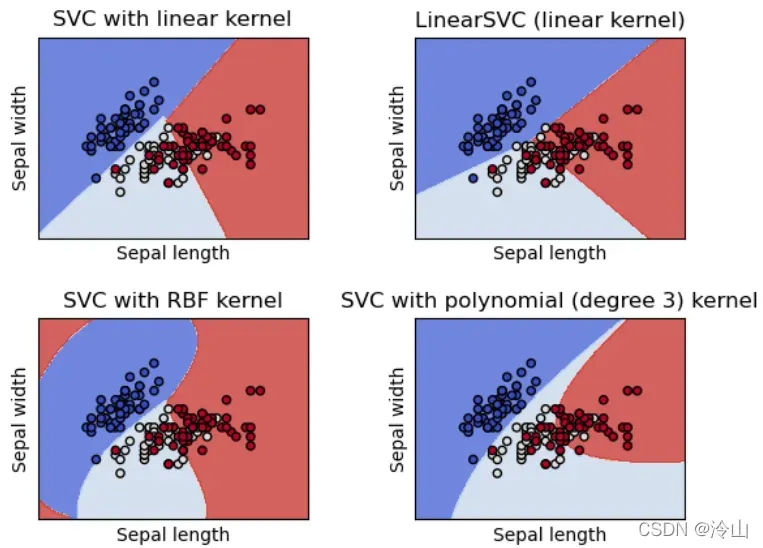
SVC和NuSVC是类似的方法,但接受的参数集略有不同,且有不同的数学公式(见数学公式部分)。而LinearSVC是支持向量分类在线性核的情况下的另一个(更快的)实现。请注意,LinearSVC 不接受参数kernel,因为它被认为是线性的。它也缺少 SVC 和 NuSVC 的一些属性,比如support_。
与其他分类器一样,SVC、NuSVC和LinearSVC使用两个数组作为输入:一个数组X(n_samples,n_features) 包含训练样本,一个数组y(n_samples) 包含类标签(字符串或整数):
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC()
拟合后,该模型可用于预测新值:
>>> clf.predict([[2., 2.]])
array([1])
支持向量机的决策函数依赖于训练数据的某个子集,称为支持向量。这些支持向量的一些性质可以在属性support_vectors_、support_和n_support_中找到。
>>> # get support vectors
>>> clf.support_vectors_
array([[0., 0.],
[1., 1.]])
>>> # get indices of support vectors
>>> clf.support_
array([0, 1]...)
>>> # get number of support vectors for each class
>>> clf.n_support_
array([1, 1]...)
2.1.1 多类别分类
SVC和NuSVC实现了“一对一”的多类分类方法。总共构造了n_classes * (n_classes – 1) / 2个分类器,每个分类器从两个类中训练数据。为了提供与其他分类器一致的接口,decision_function_shape选项允许将“一对一”分类器的结果单调地转换为“一对其余”的形状(n_samples, n_classes) 决策函数。
>>> X = [[0], [1], [2], [3]]
>>> Y = [0, 1, 2, 3]
>>> clf = svm.SVC(decision_function_shape='ovo')
>>> clf.fit(X, Y)
SVC(decision_function_shape='ovo')
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes: 4*3/2 = 6
6
>>> clf.decision_function_shape = "ovr"
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes
4
LinearSVC实现的“一对其余”的多类策略,也训练了n_classes模型。
>>> lin_clf = svm.LinearSVC()
>>> lin_clf.fit(X, Y)
LinearSVC()
>>> dec = lin_clf.decision_function([[1]])
>>> dec.shape[1]
4
文章跳转:
机器学习一:朴素贝叶斯(Naive Bayes)
机器学习 3:决策树
文章出处登录后可见!