1.降维方法
机器学习中会用到降维方法,常用的降维方法有两种:PCA(主成分分析)和SVD(奇异值分解)
SVD奇异值分解作为一个很基本的算法,在很多机器学习算法中都有它的身影。SVD奇异值分解是线性代数中一种重要的矩阵分解,是矩阵分析中正规矩阵酉对角化的推广。只需要线性代数知识就可以理解SVD算法,简单实用,分解出的矩阵解释性不强,但不影响它的使用,因此值得研究。
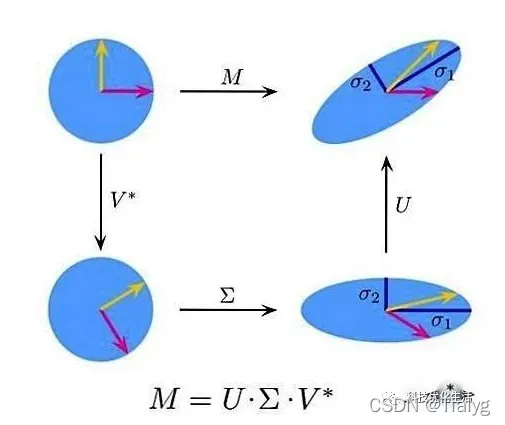
SVD算法本质是:将一个比较复杂的矩阵用更小更简单的3个子矩阵的相乘来表示,这3个小矩阵描述了大矩阵重要的特性。
SVD算法描述:
假设矩阵M是一个m×n阶矩阵,其中的元素全部属于域 K,也就是实数域或复数域。存在这样一个分解使得: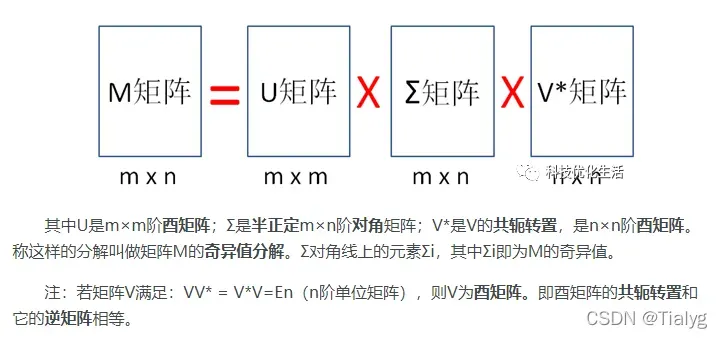
2.回声状态网络(ESN)
1、概念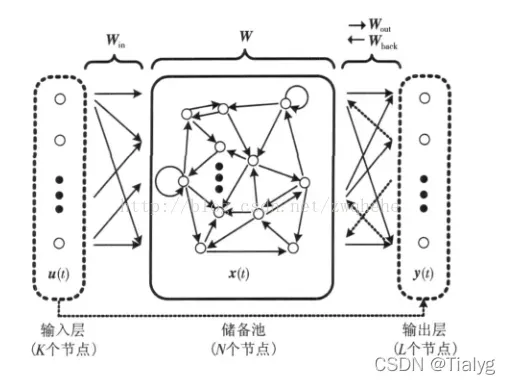
回声状态网络作为一种新型的递归神经网络(如上图),也由输入层、隐藏层(即储备池)、输出层组成。其将隐藏层设计成一个具有很多神经元组成的稀疏网络,通过调整网络内部权值的特性达到记忆数据的功能,其内部的动态储备池(DR)包含了大量稀疏连接的神经元,蕴含系统的运行状态,并具有短期训记忆功能。ESN训练的过程,就是训练隐藏层到输出层的连接权值(Wout)的过程。总结如下三个特点:
(1)核心结构是一个随机生成且保持不变的储备池(Reservoir)
(2)其输出权值是唯一需要调整的部分
(3)简单的线性回归就可完成网络的训练
推荐博客
3.LSTM网络
长短期记忆网络——通常被称为 LSTM,是一种特殊的 RNN,能够学习长期依赖性。
LSTM 被明确设计用来避免长期依赖性问题。长时间记住信息实际上是 LSTM 的默认行为,而不是需要努力学习的东西!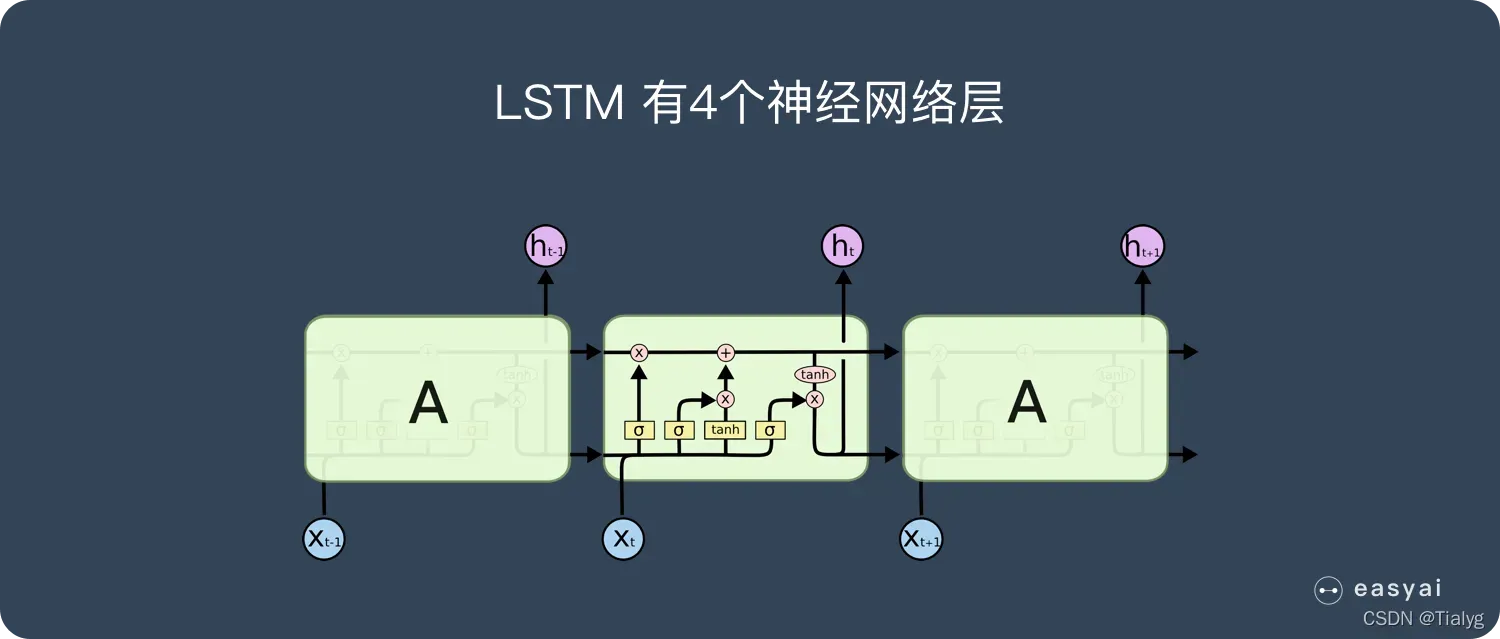
LSTM网络非常适合基于时间序列数据进行分类,处理和预测,因为在时间序列中的重要事件之间可能存在未知持续时间的滞后。开发LSTM是为了处理在训练传统RNN时可能遇到的爆炸和消失的梯度问题。对于间隙长度的相对不敏感性是LSTM相对于RNN,隐马尔可夫模型和其他序列学习方法在许多应用中的优势。
4.PSO算法(粒子群优化算法)过程
粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由Eberhart 博士和kennedy 博士提出,源于对鸟群捕食的行为研究 。**该算法最初是受到飞鸟集群活动的规律性启发,进而利用群体智能建立的一个简化模型。**粒子群算法在对动物集群活动行为观察基础上,利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得最优解。
PSO 算法属于进化算法的一种,和模拟退火算法相似,它也是从随机解出发,通过迭代寻找最优解,它也是通过适应度来评价解的品质,但它比遗传算法规则更为简单,它没有遗传算法的“交叉”(Crossover) 和“变异”(Mutation) 操作,它通过追随当前搜索到的最优值来寻找全局最优。这种算法以其实现容易、精度高、收敛快等优点引起了学术界的重视,并且在解决实际问题中展示了其优越性。粒子群算法是一种并行算法。
PSO 初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个”极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pBest。另一个极值是整个种群目前找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分作为粒子的邻居,那么在所有邻居中的极值就是局部极值。
粒子群优化的基本思想是通过群体中个体之间的合作和信息共享来寻找最优解
优秀的博客推荐
5.Adam算法
Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
- Adam 是一种在深度学习模型中用来替代随机梯度下降的优化算法。
- Adam 结合了 AdaGrad 和 RMSProp 算法最优的性能,它还是能提供解决稀疏梯度和噪声问题的优化方法。
- Adam 的调参相对简单,默认参数就可以处理绝大部分的问题。
推荐博客
6.RMSprop算法-优化算法
深度学习的优化算法主要有GD,SGD,Momentum,RMSProp和Adam算法
RMSProp优化算法是AdaGrad算法的一种改进。

可以看出RMSProp优化算法和AdaGrad算法唯一的不同,就在于累积平方梯度的求法不同。
7.迁移学习中特征向量提取以及微调
迁移学习是将预训练模型迁移到新任务。
在神经网络迁移学习中,有两种应用场景:特征提取和微调
特征提取:冻结除全连接层外的左右网络的权重。最后一个全连接层被替换为具有随机权重的新层,并且只训练该层。
在特征提取中,可以在预训练的网络结构之后修改或添加一个简单的分类器,源任务上的预训练网络可以作为另一个目标任务的特征提取器,只有最后添加的分类的参数预训练的网络不会被修改或冻结。
微调:使用预训练网络而不是随机初始化来初始化网络,用新数据训练部分或整个网络。
微调的一般过程:在预训练的网络中加入一个新的随机初始化层,此外,预训练的网络参数也会更新,但是使用较小的学习率来防止预训练的参数出现更大的品种。
常用的方法是固定底层的参数,调整一些顶层或特定层的参数。好处:减少训练参数的数量,有助于克服过拟合。
具体实现见博客PyTorch 预训练模型,保存,读取和更新模型参数以及多 GPU 训练模型(转载 极市平台).
8.FdeAVG算法
FL主要瓶颈 :
- 通信速率不稳定,可能不可靠
- 聚合服务器的容量有限,同时与server通信的client的数量受限
解决方案:
在FL的每一步考虑:
1. 减少client数量
2. 减少通信带宽
FedAvg算法采取策略:
增加客户端计算,限制通信频率(在上传更新的梯度之前执行多次局部梯度下降迭代)
FedAvg算法:
随机选择m个客户端采样,对这m个客户端的梯度更新进行平均以形成全局更新,同时用当前全局模型替换未采样的客户端
优点:相对于FedSGD在相同效果情况下,通讯成本大大降低
缺点:最终模型有偏差,与预期的每个客户端确定性聚合模型不同。
推荐博客
文章出处登录后可见!